[19/03/26-星期二] 容器_Map(图、键值对、映射)接口之HashMap(散列映射)&TreeMap(树映射)
一、概念&方法
现实生活中,我们经常需要成对存储某些信息。比如,我们使用的微信,一个手机号只能对应一个微信账户,这就是一种成对存储的关系。
Map就是用来存储“键(key)-值(value) 对”的。 Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
Map 接口的实现类有HashMap(哈希对)、TreeMap、HashTable、Properties等。
【常用方法】

【代码】
1 /*
2 *测试键值对
3 *
4 */
5 package cn.sxt.collection;
6
7 import java.util.HashMap;
8 import java.util.Map;
9
10 public class Test_0326_Map {
11 public static void main(String[] args) {
12 Map<Integer,String> map=new HashMap<Integer,String>(); //Map是个接口 HashMap(哈希)是具体实现类
13 map.put(101, "赵");//put() 存放键值对
14 map.put(102, "钱");
15 map.put(103, "孙");
16
17 Map<Integer,String> map2=new HashMap<Integer,String>();
18 map2.put(104, "li");//put() 存放键值对
19 map2.put(105, "zhou");
20
21
22 System.out.println(map);
23 System.out.println(map.get(101));//get() 通过键对象查找值对象 返回 "赵"
24 map.remove(102);//remove() 通过键对象删除值对象
25 System.out.println(map);
26
27 System.out.println(map.size());// map对象键值对的数量
28 System.out.println(map.isEmpty());//map对象中键值对是否为空
29 System.out.println(map.containsKey(103));//有没有包含103这个键?返回true或false
30 System.out.println(map.containsValue("老白"));//有没有包含"老白"这个键?返回true或false
31
32 map.put(103, "sun");//键值不能重复 如果重复后边的会覆盖前边的值 如(103 "sun") 会输出后边的
33 System.out.println(map);
34 map.putAll(map2);//把map2对象中的全部加到map对象中去
35 System.out.println(map);
36 map2.clear();//清空所以键值对
37
38 }
39
40 }
1、HashMap
HashMap采用哈希算法实现,是Map接口最常用的实现类。 由于底层采用了哈希表存储数据,要求键不能重复,
如果发生重复,新的键值对会替换旧的键值对。 HashMap在查找、删除、修改方面都有非常高的效率。
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashMap与HashTable的区别
1. HashMap: 线程不安全,效率高。允许key或value为null。
2. HashTable: 线程安全,效率低。不允许key或value为null。
HashMap详解
HashMap底层实现采用了哈希表,这是一种非常重要的数据结构。数据结构中由数组和链表来实现对数据的存储,他们各有特点。
(1) 数组:占用空间连续。 寻址容易,查询速度快。但是,增加和删除效率非常低。
(2) 链表:占用空间不连续。 寻址困难,查询速度慢。但是,增加和删除效率非常高。
那么,我们能不能结合数组和链表的优点(即查询快,增删效率也高)呢? 答案就是“哈希表”。 哈希表的本质就是“数组+链表”。
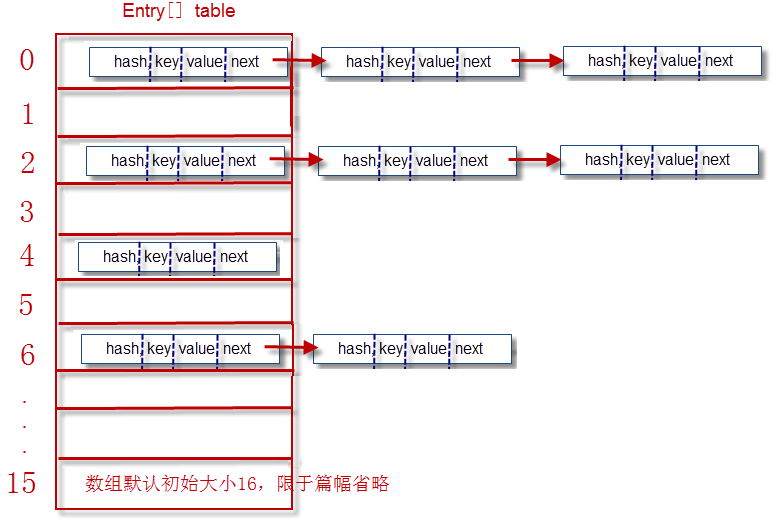
过程:哈希地址模16取余(假设数组大小为16),假设当第1个键值地址取余为6,则存在数组a[6]中,假设第2个取余后为4则存在数组a[4]中
假设第3个取余后为也为6,则还存在数组a[6]中,不过是在存储第1个键值的后继区域存第3个的地址,组成链表(地址不连续)。以此类推,
也就是说,余数相同的键值地址组织成一个链表,但总体是在一个数组中(数组是空间连续的)。类似数据结构中图的邻接表的存储方式。
即散列存储。 (具体是用 获得key对象的hashcode的代替哈希地址模16取余的)
算法中直接取余(h%length)和位运算(h&(length-1))结果是一致的
最差的情况:所有键值的余数相同,这样都存在一个链表中了,查询非常慢。体现不了"数组+链表"的优点。
链接: http://www.sxt.cn/Java_jQuery_in_action/nine-hashmap-bottom.html
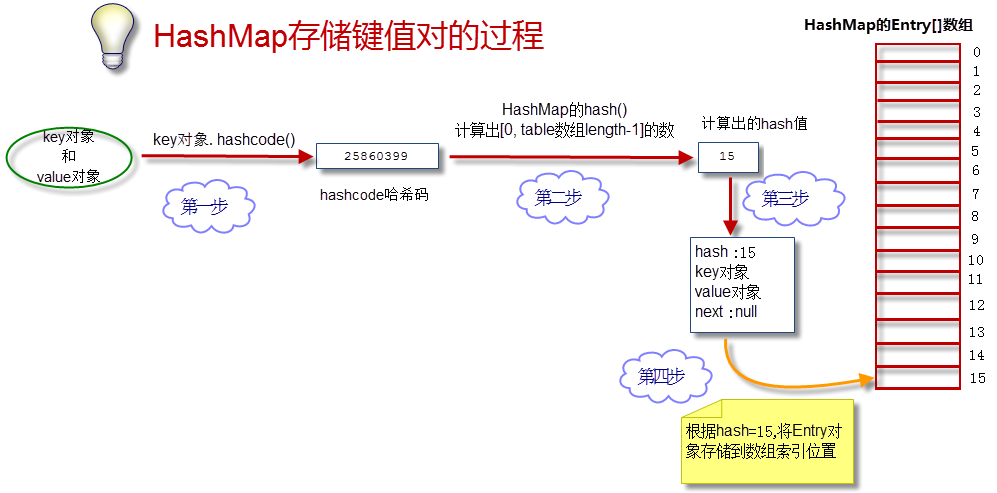
如何取数据?
(1) 获得key的hashcode,通过hash()散列算法得到hash值,进而定位到数组的位置。
(2) 在链表上挨个比较key对象。 调用equals()方法,将key对象和链表上所有节点的key对象进行比较,直到碰到返回true的节点对象为止。
(3) 返回equals()为true的节点对象的value对象。
【扩展】明白了存取数据的过程,我们再来看一下hashcode()和equals方法的关系:
Java中规定,两个内容相同(equals()为true)的对象必须具有相等的hashCode。因为如果equals()为true而两个对象的hashcode不同;
那在整个存储过程中就发生了悖论。
【代码】
/*
*哈希表结构节点
*
*/
package cn.sxt.collection; public class Node2<K,V> {
int hash;
Object key;
Object value;
Node2<K,V> next;
}
/*
*HashMap
*
*/
package cn.sxt.collection; public class Test_0326_HashMap<K,V> {
Node2 table[];//位桶数组
int size; public static void main(String[] args) {
Test_0326_HashMap<Integer,String> map=new Test_0326_HashMap<Integer,String>();
map.put(10, "A");
map.put(20, "B");
map.put(30, "C");
System.out.println(map);
System.out.println(map.get(10));
} public Test_0326_HashMap () {
table=new Node2[16];//构造方法 数组长度一般是2的n次方
}
//往里面添加元素
public void put(K key,V value) { Node2 newNode=new Node2();//hashCode()是Object类自带的方法
newNode.hash=myHash(key.hashCode(), table.length); //hash是int变量,来源于Node2类的属性 table.length数组的大小
newNode.key=key;
newNode.value=value;
newNode.next=null; Node2 temp=table[newNode.hash];
Node2 lastNode=null;//正在遍历最后一个元素 boolean flag=false;
if (temp==null) {//如果数组元素为空,则直接将元素放进去
table[newNode.hash]=newNode;
size++;
}else {//如果数组不为空,则遍历数组
while (temp!=null) {
//判断key值是否重复,若重复则覆盖,不重复在附加在后边
if (temp.key.equals(key)) {
flag=true;
temp.value=value;//只覆盖value,其它不变
break; } else {
lastNode=temp;
temp=temp.next;
}
}
if (flag==false) {//没有反生key重复的情况(flag为假的情况) 则把指针指向下一个节点
lastNode.next=newNode;
size++;
}
}
}
//根据键值取元素
public V get(K key) {
int hash=myHash(key.hashCode(), table.length);
V value=null;
if (table[hash]!=null) {
Node2 temp=table[hash];
while (temp!=null) {
if (temp.key.equals(key)) {
value=(V)temp.value;
break;
}else {
temp=temp.next;
}
}
}
return value; } public int myHash(int v,int length) {
System.out.println("取余后的结果为:"+ (v&(length-1)) );
return v&(length-1);//这里的取余相当于v%length 结果是一样的 ,取余后返回 }
public String toString() {
StringBuilder sb=new StringBuilder("{");
for (int i = 0; i < table.length; i++) {
Node2 temp = table[i];
while (temp!=null) {
sb.append(temp.key+":"+temp.value+",");
temp=temp.next;
}
}
sb.setCharAt(sb.length()-1, '}');
return sb.toString(); } }
2、TreeMap
TreeMap是红黑二叉树的典型实现 。
private transient Entry<K,V> root = null;
root用来存储整个树的根节点。我们继续跟踪Entry(是TreeMap的内部类)的代码:

可以看到里面存储了本身数据、左节点、右节点、父节点、以及节点颜色。
TreeMap的put()/remove()方法大量使用了红黑树的理论。
TreeMap和HashMap实现了同样的接口Map,因此,用法对于调用者来说没有区别。
HashMap效率高于TreeMap;在需要排序的Map时才选用TreeMap。
/*
*测试TreeMap
*
*/
package cn.sxt.collection; import java.awt.RenderingHints.Key;
import java.util.Map;
import java.util.TreeMap; public class Test_0326_TreeMap {
public static void main(String[] args) {
Map<Integer, String> tMap=new TreeMap<Integer, String>();
tMap.put(28, "B");
tMap.put(17, "A");
tMap.put(39, "C");
//首先,set是一个集合,keyset()返回的就是一个set集合,比如map里面的键值对是这样的<1,one>,<2,two><3,three><4,four>
//<5,five><6,six>那么keyset()函数就是把1,2,3,4,5,6放到一个set集合里面,然后返回给调用处。 for (Integer key : tMap.keySet()) {//for-each循环输出 按照key递增的方式排序 输出
System.out.println(key+"--"+tMap.get(key));
} Map<Emp, String> tMap1=new TreeMap<Emp, String>();
tMap1.put(new Emp(102,"小李",26000),"工作努力");
tMap1.put(new Emp(101,"老王",6000),"混吃等死");
tMap1.put(new Emp(104,"张哥",7000),"工作不积极");
tMap1.put(new Emp(103,"老白",7000),"工作还行"); for (Emp key : tMap1.keySet()) {//for-each循环输出 输出结果按工资从小到大排序,若工资相同按id从小到大递增排序
System.out.println(key+"--"+tMap1.get(key));
} }
}
class Emp implements Comparable<Emp>{//雇员类,自定义按工资排序 Comparable:比较接口
int id;
String name;
double salary; public Emp(int id, String name, double salary) {
super();
this.id = id;
this.name = name;
this.salary = salary;
} public int compareTo(Emp o) { //负数:小于 ;0:等于;正数:大于
if (this.salary>o.salary) {
return 1;
}else if (this.salary<o.salary) {
return -1;
}else { //工资相同比较id
if (this.id>o.id) {
return 1;
} else if(this.id<o.id) {
return -1;
}else {
return 0;
}
}
} public String toString() {
return "id:"+id+" name:"+name+" salary:"+salary;
} }
[19/03/26-星期二] 容器_Map(图、键值对、映射)接口之HashMap(散列映射)&TreeMap(树映射)的更多相关文章
- [19/03/24-星期日] 容器_Collection(集合、容器)之List(表,有顺序可重复)
一. 概念&方法 Collection 表示一组对象,它是集中.收集的意思.Collection接口的两个子接口是List.Set接口. 由于List.Set是Collection的子接口,意 ...
- 数据结构(一): 键值对 Map
Map基本介绍 Map 也称为:映射表/关联数组,基本思想就是键值对的关联,可以用键来查找值. Java标准的类库包含了Map的几种基本的实现,包括:HashMap,TreeMap,LinkedHas ...
- Java学习笔记(2)----散列集/线性表/队列/集合/图(Set,List,Queue,Collection,Map)
1. Java集合框架中的所有实例类都实现了Cloneable和Seriablizable接口.所以,它们的实例都是可复制和可序列化的. 2. 规则集存储的是不重复的元素.若要在集合中存储重复的元素, ...
- Django 用散列隐藏数据库中主键ID
最近看到了一篇讲Django性能测试和优化的文章, 文中除了提到了很多有用的优化方法, 演示程序的数据库模型写法我觉得也很值得参考, 在这单独记录下. 原文的演示代码有些问题, 我改进了下, 这里可以 ...
- Oracle复合B*tree索引branch block内是否包含非先导列键值?
好久不碰数据库底层细节的东西,前几天,一个小家伙跑来找我,非要说复合b*tree index branch block中只包含先导列键值信息,并不包含非先导列键值信息,而且还dump了branch b ...
- hashmap可以用null为键值
import java.util.HashMap; import java.util.Map; import java.util.TreeMap; public class TestMain { ...
- Spring 属性注入(四)属性键值对 - PropertyValue
Spring 属性注入(四)属性键值对 - PropertyValue Spring 系列目录(https://www.cnblogs.com/binarylei/p/10117436.html) P ...
- 基于ANDROID平台,U3D对蓝牙手柄键值的获取
对于ANDROID平台,物理蓝牙手柄已被封装,上层应用不可见,也就是说对于上层应用,不区分蓝牙手柄还是其它手柄: 完成蓝牙手柄和ANDROID手机的蓝牙连接后,即可以UNITY3D中获取其键值: 在U ...
- HashMap存储自定义类型键值和LinkedHashMap集合
HashMap存储自定义类型键值 1.当给HashMap中存放自定义对象时,如果自定义对象是键存在,保证键唯一,必须复写对象的hashCode和equals方法. 2.如果要保证map中存放的key和 ...
随机推荐
- [转]使用依赖关系注入在 ASP.NET Core 中编写干净代码
本文转自:http://blog.jobbole.com/101270/ 原文出处: Steve Smith ASP.NET Core 1.0 是 ASP.NET 的完全重新编写,这个新框架的主 ...
- vue.js开发之开关(switch)组件
最近开发组件的时候,自定义开发了开关(switch)组件,现将代码整理如下,方便日后复用. toggle-switch.vue <template> <label role=&quo ...
- redis的持久化方式
redis有两种持久化方式,第一种是基于快照的持久化方式,第二种是基于文件追加的持久化方式 一.基于快照的持久化 1.修改redis.conf配置文件,开启基于快照的持久化方式 2.修改持久化文件存放 ...
- SZU5
A - Couple doubi 这种题不要想复杂,直接找规律.找不出规律就打表找规律 #include <iostream> #include <string> #inclu ...
- 键盘录入(Java)
键盘录入(Java): 1.导包 格式 import java.util.Scanner; 位置 在class上面 2.创建键盘录入对象 格式 Scanner sc = new Scanner(Sys ...
- jQuery的几点笔记
1.jQuery核心选择器 (sizzle.js) http://sizzlejs.com/ 2.jQuery有两个主要特性 ①隐式迭代 //改变页面所有p标签的背景色 $('p').css('bac ...
- chrome中常用的快捷键
ctrl+n 新建窗口ctrl+shift+n 无痕模式新建窗口ctrl+t 打开新标签页ctrl+shift+t 打开最近关闭的标签页ctrl+tab 标签页之间切换ctrl+w/ctrl+F4 关 ...
- ASPF(Application Specific Packet Filter)
ASPF ASPF(Application Specific Packet Filter)是针对应用层的包过滤,其原理是检测通过设备的报文的应用层协议信息,记录临时协商的数据连接,使得某些在安全策略中 ...
- 139.00.005 Git学习-分支管理
@(139 - Environment Settings | 环境配置) 一.Why? 分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交, ...
- 【JAVA语法】01Java-变量与数据类型
数据类型初阶 基本数据类型的包装类 整数类型&浮点类型&字符类型 大小类型转换 通过Scanner从控制台获取数据 变量相关基础算法 Java的错误类型 字符串String 补充-Pa ...