redis源码学习_字典
redis中字典有以下要点:
(1)它就是一个键值对,对于hash冲突的处理采用了头插法的链式存储来解决。
(2)对rehash,扩展就是取第一个大于等于used * 2的2 ^ n的数作为新的hash表大小;缩紧就是取第一个大于等于used的2 ^ n的数作为新的hash表大小。后面会介绍到dict结构体中是有dictht ht[2]这个成员变量的,为什么是2个呢?就是为了做rehash时交替使用的。那么何时扩展,何时缩紧呢?有个负载因子的概念(负载因子 = used / size,注意这里面的used也是包括了链式存储解决冲突时候的元素个数),没有执行BGSAVE或者BGREWRITEAOF时大于1就会扩展,小于0.1就会缩紧。搞的时候会用渐进式rehash的方法来搞,再此过程中对于字典的删、改、查会在2个ht上面进行,而增只会在新的ht上进行。
主要关注dict.c和dici.h。
首先先看一下结构体dictht:
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
//每个具体table[i]中的节点数据类型是dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对:
dictEntry **table; // 哈希表大小
unsigned long size; // 哈希表大小掩码,用于计算索引值,总是等于 size - 1
unsigned long sizemask; // 该哈希表已有节点的数量
unsigned long used; } dictht;
再看结构体dictEntry:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
//next 属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题。
struct dictEntry *next;
} dictEntry;
对于k1和k0值相等的情况下,见下图:
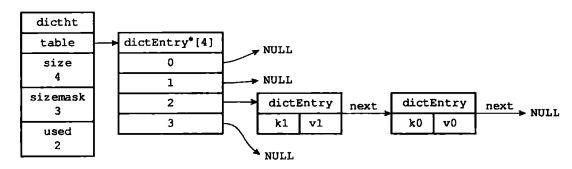
再来看结构体dict:
typedef struct dict {//dictCreate创建和初始化
// 类型特定函数,实现多态
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[];
// rehash 索引
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
再看结构体dictType:
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
里面就是各种函数指针。

dictCreate:创建字典,比较简单,不过多解释
/* Create a new hash table */
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d)); _dictInit(d,type,privDataPtr); return d;
}
_dictInit:初始化操作
/* Initialize the hash table */
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
// 初始化两个哈希表的各项属性值
// 但暂时还不分配内存给哈希表数组
_dictReset(&d->ht[]);
_dictReset(&d->ht[]); // 设置类型特定函数
d->type = type; // 设置私有数据
d->privdata = privDataPtr; // 设置哈希表 rehash 状态
d->rehashidx = -; // 设置字典的安全迭代器数量
d->iterators = ; return DICT_OK;
}
_dictReset:赋初值
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = ;
ht->sizemask = ;
ht->used = ;
}
dictAdd:添加k-v到字典中,调用关系比较乱,我们来看一下
dictAdd
-->dictAddRaw
-->_dictRehashStep
-->dictRehash
-->_dictKeyIndex
-->_dictExpandIfNeeded
-->dictExpand
-->_dictNextPower
-->dictSetKey
-->dictSetVal


有了调用关系就好办了,下面来分别分析以上函数都做了什么。
_dictRehashStep:分步rehash包裹函数
static void _dictRehashStep(dict *d) {
if (d->iterators == ) dictRehash(d,);
}
dictRehash:分步rehash
int dictRehash(dict *d, int n) {
// 只可以在 rehash 进行中时执行
if (!dictIsRehashing(d)) return ;
// 进行 N 步迁移
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// 如果 0 号哈希表为空,那么表示 rehash 执行完毕
if (d->ht[].used == ) {
zfree(d->ht[].table);
d->ht[] = d->ht[];
_dictReset(&d->ht[]);
d->rehashidx = -;
return ;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[].size > (unsigned)d->rehashidx);
// 略过数组中为空的索引,找到下一个非空索引
while(d->ht[].table[d->rehashidx] == NULL) d->rehashidx++;
// 指向该索引的链表表头节点
de = d->ht[].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[].sizemask;
de->next = d->ht[].table[h];
d->ht[].table[h] = de;
// 更新计数器
d->ht[].used--;
d->ht[].used++;
// 继续处理下个节点
de = nextde;
}
// 将刚迁移完的哈希表索引的指针设为空
d->ht[].table[d->rehashidx] = NULL;
// 更新 rehash 索引
d->rehashidx++;
}
return ;
}
dictExpand:扩充函数,是否需要rehash的标志rehashidx也是从这里面搞的,这样它就不为-1了。
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
// 新哈希表
dictht n; /* the new hash table */ unsigned long realsize = _dictNextPower(size); /* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[].used > size)
return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = ; //下面是要区分2种情况的,需要注意了 /* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// 如果 0 号哈希表为空,那么这是一次初始化:
if (d->ht[].table == NULL) {
d->ht[] = n;
return DICT_OK;
} /* Prepare a second hash table for incremental rehashing */
// 如果 0 号哈希表非空,那么这是一次 rehash :
// 程序将新哈希表设置为 1 号哈希表,
// 并将字典的 rehash 标识打开,让程序可以开始对字典进行 rehash
d->ht[] = n;
d->rehashidx = ;
return DICT_OK; }
dictAddRaw:添加新的键到字典
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht; if (dictIsRehashing(d)) _dictRehashStep(d); /* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key)) == -)
return NULL; /* Allocate the memory and store the new entry */
ht = dictIsRehashing(d) ? &d->ht[] : &d->ht[];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++; /* Set the hash entry fields. */
dictSetKey(d, entry, key); return entry;
}
dictAdd:添加新的键值对到字典
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key); // 键已存在,添加失败
if (!entry) return DICT_ERR; // 键不存在,设置节点的值
dictSetVal(d, entry, val); return DICT_OK;
}
dictReplace:更新键值对,原来没有就添加,原来有就更新值
/* Add an element, discarding the old if the key already exists.
* Return 1 if the key was added from scratch, 0 if there was already an element with such key and dictReplace() just performed a value update operation.
*/
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry; /* Try to add the element. If the key
* does not exists dictAdd will suceed. */
if (dictAdd(d, key, val) == DICT_OK)
return ; /* It already exists, get the entry */
entry = dictFind(d, key); auxentry = *entry; dictSetVal(d, entry, val); dictFreeVal(d, &auxentry); return ;
}
dictGenericDelete:删除指定key对应的一个元素
/* Search and remove an element */
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
unsigned int h, idx;
dictEntry *he, *prevHe;
int table; if (d->ht[].size == ) return DICT_ERR; /* d->ht[0].table is NULL */ if (dictIsRehashing(d)) _dictRehashStep(d); // 计算哈希值
h = dictHashKey(d, key); // 遍历哈希表
for (table = ; table <= ; table++) { // 计算索引值
idx = h & d->ht[table].sizemask;
// 指向该索引上的链表,就是链表的第一个元素
he = d->ht[table].table[idx];
prevHe = NULL; while(he) { if (dictCompareKeys(d, key, he->key)) { /* Unlink the element from the list */
// 就是删除一个就得了
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next; if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
} zfree(he); d->ht[table].used--; return DICT_OK;
} prevHe = he;
he = he->next;
} if (!dictIsRehashing(d)) break;
} return DICT_ERR; /* not found */
}
_dictClear:释放hash
/* Destroy an entire dictionary */
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {
unsigned long i; /* Free all the elements */
for (i = ; i < ht->size && ht->used > ; i++) {
dictEntry *he, *nextHe; if (callback && (i & ) == ) callback(d->privdata); // 跳过空索引
if ((he = ht->table[i]) == NULL) continue; // 遍历整个链表
while(he) {
nextHe = he->next;
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he); ht->used--; he = nextHe;
}
} /* Free the table and the allocated cache structure */
zfree(ht->table); /* Re-initialize the table */
_dictReset(ht); return DICT_OK; /* never fails */
}
关于dictGetIterator、dictGetSafeIterator、dictNext、dictReleaseIterator具体应用暂时分析一下:
首先先看用到这几个函数的地方吧
void keysCommand(redisClient *c) {
dictIterator *di;
dictEntry *de;
sds pattern = c->argv[]->ptr;
int plen = sdslen(pattern), allkeys;
unsigned long numkeys = ;
void *replylen = addDeferredMultiBulkLength(c);
/* 首先先搞一个迭代器出来 */
di = dictGetSafeIterator(c->db->dict);
allkeys = (pattern[] == '*' && pattern[] == '\0');
/* 开始遍历迭代器 */
while((de = dictNext(di)) != NULL) {
sds key = dictGetKey(de);
robj *keyobj;
if (allkeys || stringmatchlen(pattern,plen,key,sdslen(key),)) {
keyobj = createStringObject(key,sdslen(key));
if (expireIfNeeded(c->db,keyobj) == ) {
addReplyBulk(c,keyobj);
numkeys++;
}
decrRefCount(keyobj);
}
}
/* 释放迭代器 */
dictReleaseIterator(di);
setDeferredMultiBulkLength(c,replylen,numkeys);
}
有了上面的应用场景,我们再来看上面几个函数的实现就好办了。
先看dictIterator结构体:
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator { // 被迭代的字典
dict *d; // table :正在被迭代的哈希表号码,值可以是 0 或 1 。 dictht ht[2];中的哪一个
// index :迭代器当前所指向的哈希表索引位置。 对应具体的桶槽位号
// safe :标识这个迭代器是否安全
int table, index, safe; // entry :当前迭代到的节点的指针
// nextEntry :当前迭代节点的下一个节点
dictEntry *entry, *nextEntry; long long fingerprint; /* unsafe iterator fingerprint for misuse detection */
} dictIterator;
dictGetIterator:创建迭代器
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter)); iter->d = d;
iter->table = ;
iter->index = -;
iter->safe = ;
iter->entry = NULL;
iter->nextEntry = NULL; return iter;
}
dictNext:迭代,遍历桶中的所有节点,第一次遍历该函数的时候直接获取具体桶首元素,否则使用nextEntry。这个函数比较难理解……
dictEntry *dictNext(dictIterator *iter)
{
while () { // 进入这个循环有两种可能:
// 1) 这是迭代器第一次运行
// 2) 当前索引链表中的节点已经迭代完(NULL 为链表的表尾)
if (iter->entry == NULL) { // 指向被迭代的哈希表
dictht *ht = &iter->d->ht[iter->table]; // 初次迭代时执行
if (iter->index == - && iter->table == ) {
// 如果是安全迭代器,那么更新安全迭代器计数器
if (iter->safe)
iter->d->iterators++;
// 如果是不安全迭代器,那么计算指纹
else
iter->fingerprint = dictFingerprint(iter->d);
}
// 更新索引
iter->index++; //默认值为-1,自加后刚好为0,即第一个桶 // 如果迭代器的当前索引大于当前被迭代的哈希表的大小
// 那么说明这个哈希表已经迭代完毕
if (iter->index >= (signed) ht->size) {
// 如果正在 rehash 的话,那么说明 1 号哈希表也正在使用中
// 那么继续对 1 号哈希表进行迭代
if (dictIsRehashing(iter->d) && iter->table == ) {
iter->table++;
iter->index = ;
ht = &iter->d->ht[];
// 如果没有 rehash ,那么说明迭代已经完成
} else {
break;
}
} // 如果进行到这里,说明这个哈希表并未迭代完
// 更新节点指针,指向下个索引链表的表头节点
iter->entry = ht->table[iter->index];
} else {
// 执行到这里,说明程序正在迭代某个链表
// 将节点指针指向链表的下个节点
iter->entry = iter->nextEntry;
} if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
} // 迭代完毕
return NULL;
}
dictReleaseIterator:释放迭代器,没有什么好说的了
void dictReleaseIterator(dictIterator *iter)
{ if (!(iter->index == - && iter->table == )) {
// 释放安全迭代器时,安全迭代器计数器减一
if (iter->safe)
iter->d->iterators--;
// 释放不安全迭代器时,验证指纹是否有变化
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
关于迭代器里面,安全和非安全迭代器还不是特别明白;另外dictScan暂时没有深入研究,后续再深入研究吧。
redis源码学习_字典的更多相关文章
- redis源码学习_整数集合
redis里面的整数集合保存的都是整数,有int_16.int_32和int_64这3种类型,和C++中的set容器差不多. 同时具备如下特点: 1.set里面的数不重复,均为唯一. 2.set里面的 ...
- redis源码学习_链表
redis的链表是双向链表,该链表不带头结点,具体如下: 主要总结一下adlist.c和adlist.h里面的关键结构体和函数. 链表节点结构如下: /* * 双端链表节点 */ typedef st ...
- redis源码学习_简单动态字符串
SDS相比传统C语言的字符串有以下好处: (1)空间预分配和惰性释放,这就可以减少内存重新分配的次数 (2)O(1)的时间复杂度获取字符串的长度 (3)二进制安全 主要总结一下sds.c和sds.h中 ...
- Redis源码学习:Lua脚本
Redis源码学习:Lua脚本 1.Sublime Text配置 我是在Win7下,用Sublime Text + Cygwin开发的,配置方法请参考<Sublime Text 3下C/C++开 ...
- Redis源码学习:字符串
Redis源码学习:字符串 1.初识SDS 1.1 SDS定义 Redis定义了一个叫做sdshdr(SDS or simple dynamic string)的数据结构.SDS不仅用于 保存字符串, ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- redis源码学习之slowlog
目录 背景 环境说明 redis执行命令流程 记录slowlog源码分析 制造一条slowlog slowlog分析 1.slowlog如何开启 2.slowlog数量限制 3.slowlog中的耗时 ...
- 柔性数组(Redis源码学习)
柔性数组(Redis源码学习) 1. 问题背景 在阅读Redis源码中的字符串有如下结构,在sizeof(struct sdshdr)得到结果为8,在后续内存申请和计算中也用到.其实在工作中有遇到过这 ...
- __sync_fetch_and_add函数(Redis源码学习)
__sync_fetch_and_add函数(Redis源码学习) 在学习redis-3.0源码中的sds文件时,看到里面有如下的C代码,之前从未接触过,所以为了全面学习redis源码,追根溯源,学习 ...
随机推荐
- Ceph源码解析:Scrub故障检测
转载请注明出处 陈小跑 http://www.cnblogs.com/chenxianpao/p/5878159.html 本文只梳理了大致流程,细节部分还没搞的太懂,有时间再看,再补充,有错误请指正 ...
- iOS:详解MJRefresh刷新加载更多数据的第三方库
原文链接:http://www.ios122.com/2015/08/mjrefresh/ 简介 MJRefresh这个第三方库是李明杰老师的杰作,这个框架帮助我们程序员减轻了超级多的麻烦,节约了开发 ...
- PhantomJS + Selenium webdriver 总结-元素定位
webdriver提供了丰富的API,有多种定位策略:id,name,css选择器,xpath等,其中css选择器定位元素效率相比xpath要高些,使用id,name属性定位元素是最可靠,效率最高的一 ...
- c#跟objective-c语言特性的对比
拿c#语言跟objective-c做个对比,记录下自己认为是差不多的东西. 学过objc的人相信对category这个东西肯定不陌生,它可以让我们在没有源码的基础上对原先的类添加额外的一些方法,写到这 ...
- 这里先发布一个,自己写得unityUI的适配的方案(插播)
这个适配是依据坐标系的象限的思想来进项适配的.參考了部分的NGUI的适配方案. 在程序的事实上,来測量UI距离相机边界的像素然后依据比例来进行适配,个人认为还不错. 放码! . 有个前提哦就是你要先定 ...
- win10下JDK安装,配置环境变量后出现error:could not open '...jvm.cfg'
分析: 大多是安装jdk的时候在注册表里注册过,打开注册表查看里面如下三个文件( Java Development Kit,Java Plug-in,Java Runtime Environm ...
- Win7如何修改文件夹的默认视图,如何把详细信息改为平铺视图
先任意进入一个文件夹,右击选择平铺视图. 然后点击左上角的组织,文件夹和搜索选项,在文件夹选项的查看中点击"应用到文件夹",然后点击确定,弹出对话框,再确定. 随后再浏览别 ...
- C/C++中传值和传地址(引用)
C/C++中参数传递有两种方式,传值或传地址(传引用),通常我们要在被调用函数中改变一个变量的值就需要传地址调用方式,例如: void swap_by_value(int a, int b) { in ...
- js调试工具console方法详解
一.显示信息的方法 最常用的console.log(),一般用来调试. console.log('hello'); console.info('信息'); console.error('错误'); c ...
- 算法笔记_081:蓝桥杯练习 算法提高 矩阵乘法(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 有n个矩阵,大小分别为a0*a1, a1*a2, a2*a3, ..., a[n-1]*a[n],现要将它们依次相乘,只能使用结合率,求最 ...