【Detection】物体识别-制作PASCAL VOC数据集
PASCAL VOC数据集
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge
默认为20类物体

1 数据集结构

①JPEGImages
JPEGImages文件夹中包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片。
②Annotations
Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
xml文件的具体格式如下:(对于2007_000392.jpg)
<annotation><folder>VOC2012</folder><filename>2007_000392.jpg</filename> //文件名<source> //图像来源(不重要)<database>The VOC2007 Database</database><annotation>PASCAL VOC2007</annotation><image>flickr</image></source><size> //图像尺寸(长宽以及通道数)<width>500</width><height>332</height><depth>3</depth></size><segmented>1</segmented> //是否用于分割(在图像物体识别中01无所谓)<object> //检测到的物体<name>horse</name> //物体类别<pose>Right</pose> //拍摄角度<truncated>0</truncated> //是否被截断(0表示完整)<difficult>0</difficult> //目标是否难以识别(0表示容易识别)<bndbox> //bounding-box(包含左下角和右上角xy坐标)<xmin>100</xmin><ymin>96</ymin><xmax>355</xmax><ymax>324</ymax></bndbox></object><object> //检测到多个物体<name>person</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox> //检测矩形框坐标<xmin>198</xmin><ymin>58</ymin><xmax>286</xmax><ymax>197</ymax></bndbox></object></annotation>
对应的图片为:

③ImageSets
ImageSets存放的是每一种类型的challenge对应的图像数据。
在ImageSets下有四个文件夹:
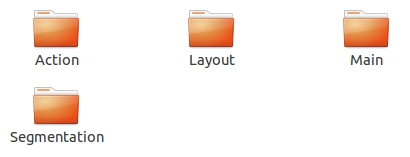
其中Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分)
Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)
Main下存放的是图像物体识别的数据,总共分为20类。
Segmentation下存放的是可用于分割的数据。
在这里主要考察Main文件夹。
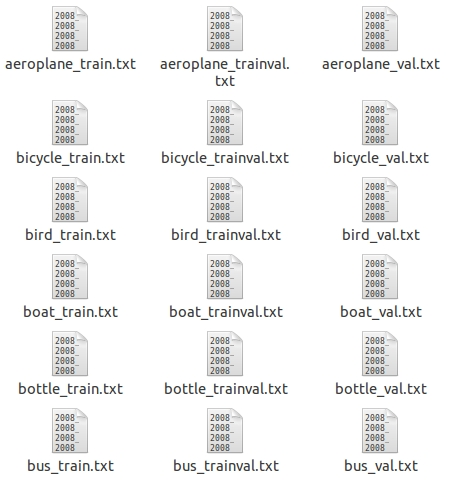
Main文件夹下包含了20个分类的_train.txt、_val.txt和***_trainval.txt。
这些txt中的内容都差不多如下:

前面的表示图像的name,后面的1代表正样本,-1代表负样本。
_train中存放的是训练使用的数据,每一个class的train数据都有5717个。
_val中存放的是验证结果使用的数据,每一个class的val数据都有5823个。
_trainval将上面两个进行了合并,每一个class有11540个。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据的时候 ,也应该是随机产生的。
2 生成/创建 PASCAL VOC 数据集
2.1 利用现有数据集 - Openimages
900万张标注图像,谷歌发布Open Images最新V3版
该数据集包含一个训练集(9011219张图像)、一个验证集(41620张图像)和一个测试集(125436张图像)。V1 版本里的验证集在 V2 版本中被划分为验证集和测试集,这样做是为了更好地进行评估。Open Images 中的所有图像都标注有图像级标签和边界框
600余物体类别在线浏览
分类标签示例:

2.1.1 下载openimages
到官网下载的时候要一次性下载所有的部分,不仅文件很大,而且下载的也不大快,更重要的是自己训练要用到的类别并不多。
我采用的是工具箱的方法(https://github.com/EscVM/OIDv4_ToolKit),实际操作起来也挺顺利的。
Open Images V4 下载自己需要的特定类别
Step1:Install the required packages
pip install -r requirements.txt
Step2:
python main.py downloader --classes ./classes.txt --type_csv all --limit 3000
用法:main.py [-h] [--Dataset/path/to/OID/csv/] [-y][ - 类列表[类列表...]][--type_csv'train'或'validation'或'test'或'all'][--sub 子人验证图像的子集或机器生成的h或m)][--image_IsOccluded 1或0] [ - image_IsTruncated 1或0][--image_IsGroupOf 1或0] [ - image_IsDepiction 1或0][--image_IsInside 1或0] [--multiclasses 0(默认值或1)[--n_threads [默认20]] [--noLabels][--limit integer number]<command>'downloader','visualizer'或'ill_downloader'。Open Image Dataset Downloader打开图像数据集下载程序位置参数:<command>'downloader','visualizer'或'ill_downloader'。'downloader','visualizer'或'ill_downloader'。可选参数:-h, --help 显示此帮助消息并退出--Dataset /path/to/OID/csv/OID数据集文件夹的目录-y, --yes 是和是可以下载丢失的文件- 类列表[类列表...]所需类的“字符串”序列--type_csv'train'或'validation'或'test'或'all'从什么csv搜索图像--sub 人工验证图像或机器生成的子集(h或m)从人类验证的数据集或从机器生成一个。--image_IsOccluded 1或0图像的可选特征。表示对象被图像中的另一个对象遮挡。--image_IsTruncated 1或0图像的可选特征。表示对象超出图像的边界。--image_IsGroupOf 1或0图像的可选特征。表示盒子跨越一组物体(分钟5)。--image_IsDepiction 1或0图像的可选特征。表示对象是一个描述。--image_IsInside 1或0图像的可选特征。表示a从对象内部拍摄的照片。--multiclasses 0(默认值)或1分别(0)或一起下载不同的类(1)--n_threads [默认20]要使用的线程数--noLabels 没有标签创作--limit integer number要下载的图像数量的可选限制
下载完成后得到 OID Folder
2.1.2 csv生成.xml(以Google openimage为例)
Step1:Get VOC.xml - csv2voc.py
Openimage.csv to Anotation/XXX.xml
- Input : OPEN_IMAGES_DIR = folder of csv file
eg. where the validation-annotations-bbox.csv is.
- Output = Anotation/XXX.xml +
test.txt、train.txt、val.txt、trainval.txt
生成后得到VOCify Folder
Note: 此时无需直接操作图片
test.txt、train.txt、val.txt、trainval.txt 后期训练时可再次生成,代码如下
# -*- coding:utf-8 -*-# -*- python3.5import osimport randomtrainval_percent = 0.7 #可以自己设置train_percent = 0.8 #可以自己设置xmlfilepath = 'Annotations' #地址填自己的txtsavepath = 'ImageSets/Main'total_xml = os.listdir(xmlfilepath)num = len(total_xml)list = range(num)tv = int(num*trainval_percent)tr = int(tv*train_percent)trainval = random.sample(list,tv)train = random.sample(trainval,tr)ftrainval = open(txtsavepath+'/trainval.txt', 'w')ftest = open(txtsavepath+'/test.txt', 'w')ftrain = open(txtsavepath+'/train.txt', 'w')fval = open(txtsavepath+'/val.txt', 'w')for i in list:name = total_xml[i][:-4]+'\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else: fval.write(name)else:ftest.write(name)ftrainval.close()ftrain.close()fval.close()ftest .close()print('Well finshed')
Step2:Save images to JPEGImages folder - By hand
cp -r Dataset/images_file* VOCify/JPEGImages
Source : Dataset/images_file
Destination : VOCify/JPEGImages
Step3:Set same name - my_same_name.py
Set Anotation/XXX.xml as JPEGImages/XXX.jpg
Make XXX the same
2.2 手工标注
推荐:使用labelImg工具给图片上标签,并生成.xml文件
【Detection】物体识别-制作PASCAL VOC数据集的更多相关文章
- 自动化工具制作PASCAL VOC 数据集
自动化工具制作PASCAL VOC 数据集 1. VOC的格式 VOC主要有三个重要的文件夹:Annotations.ImageSets和JPEGImages JPEGImages 文件夹 该文件 ...
- PASCAL VOC数据集分析(转)
PASCAL VOC数据集分析 PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge. 本文主要分析PASCAL V ...
- 【计算机视觉】PASCAL VOC数据集分析
PASCAL VOC数据集分析 PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge. 本文主要分析PASCAL V ...
- PASCAL VOC数据集The PASCAL Object Recognition Database Collection
The PASCAL Object Recognition Database Collection News 04-Apr-07: The VOC2007 challenge development ...
- 【Tensorflow】 Object_detection之训练PASCAL VOC数据集
参考:Running Locally 1.检查数据.config文件是否配置好 可参考之前博客: Tensorflow Object_detection之配置Training Pipeline Ten ...
- PASCAL VOC数据集分析
http://blog.csdn.net/zhangjunbob/article/details/52769381
- YOLO v3 & Pascal VOC数据集
代码地址:https://github.com/YunYang1994/tensorflow-yolov3 https://hackernoon.com/understanding-yolo-f5a7 ...
- Pascal VOC & COCO数据集介绍 & 转换
目录 Pascal VOC & COCO数据集介绍 Pascal VOC数据集介绍 1. JPEGImages 2. Annotations 3. ImageSets 4. Segmentat ...
- Python生成PASCAL VOC格式的xml标注文件
Python生成PASCAL VOC格式的xml标注文件 PASCAL VOC数据集的标注文件是xml格式的.对于py-faster-rcnn,通常以下示例的字段是合适的: <annotatio ...
随机推荐
- Docker日常常用命令汇总
一.使用docker镜像/容器 (1)创建容器,且进入命令台 docker run --name 容器名 -i -t ubuntu /bin/bash (2)查看/容器 docker ps #查看正在 ...
- PHP 对接 饿了么开放平台 接单
<?php # 一开始使用的是API方式对接,所以我这里是API的方式+SDK的结合 (除了获取token之外都是使用SDK方式,所以看到的朋友还是直接使用纯SDK方式对接最好),因为我这里使用 ...
- linux搭建简单的web服务器
主要想法是:使用虚拟机的Ubuntu系统搭建http服务器,然后在window的浏览器上测试 1.先测试windows和虚拟机上的ubuntu能否相互ping通 2.下载http.tar.gz并拷贝到 ...
- schedule of 2016-10-17~2016-10-23(Monday~Sunday)——1st semester of 2nd Grade
most important things to do 1.joint phd preparations 2.journal paper to write 3.solid fundamental kn ...
- Collection 的子类 List
List集合的一些使用方法: 一. 声明集合: List<String> list = new ArrayList<String>(); 二.往集合里面添加元素 list.ad ...
- PHP高级程序员必看知识点:目录大全(不定期更新)
面试题系列: 分享一波腾讯PHP面试题 2019年PHP最新面试题(含答案) Redis 高级面试题 学会这些还怕进不了大厂? 阿里面试官三年经验PHP程序员知识点汇总,学会你就是下一个阿里人! ph ...
- 浅析PHP类的自动加载和命名空间
php是使用require(require_once)和include(include_once)关键字加载类文件.但是在实际的开发工程中我们基本上不会去使用这些关键字去加载类. 因为这样做会使得代码 ...
- .Net Framework为什么需要联网?
.Net Framework在安装时需要从微软官方网站下载语言包,所以需要联网. 如果想要真正离线安装,需要先把所需的语言包下载下来.
- Java 项目热部署,节省构建时间的正确姿势
上周末,帮杨小邪(我的大学室友)远程调试项目.SpringBoot 构建,没有热部署,改一下就得重启相关模块.小小的 bug ,搞了我一个多小时,大部分时间都还在构建上(特么,下次得收钱才行).我跟他 ...
- DP-Fibonacci
善于发现 DP 中的 Fibonacci 我们在做 DP 题时 , 会发现有一些题 类似于找规律的题 ,观察测试样例 , 要对数据敏感 , 比如输入 2 输出 1 , 输入 3 就输出 2 …… ...