手把手带你阅读Mybatis源码(二)执行篇
前言
上一篇文章提到了MyBatis是如何构建配置类的,也说了MyBatis在运行过程中主要分为两个阶段,第一是构建,第二就是执行,所以这篇文章会带大家来了解一下MyBatis是如何从构建完毕,到执行我们的第一条SQL语句的。之后这部分内容会归置到公众号菜单栏:连载中…-框架分析中,欢迎探讨!
入口(代理对象的生成)
public static void main(String[] args) throws Exception {
/******************************构造******************************/
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
//创建SqlSessionFacory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
/******************************分割线******************************/
/******************************执行******************************/
//SqlSession是帮我们操作数据库的对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//获取Mapper
DemoMapper mapper = sqlSession.getMapper(DemoMapper.class);
Map<String,Object> map = new HashMap<>();
map.put("id","123");
System.out.println(mapper.selectAll(map));
sqlSession.close();
sqlSession.commit();
}
首先在没看源码之前希望大家可以回忆起来,我们在使用原生MyBatis的时候(不与Spring进行整合),操作SQL的只需要一个对象,那就是SqlSession对象,这个对象就是专门与数据库进行交互的。
我们在构造篇有提到,Configuration对象是在SqlSessionFactoryBuilder中的build方法中调用了XMLConfigBuilder的parse方法进行解析的,但是我们没有提到这个Configuration最终的去向。讲这个之前我们可以思考一下,这个Configuration生成之后,会在哪个环节被使用?毋庸置疑,它作为一个配置文件的整合,里面包含了数据库连接相关的信息,SQL语句相关信息等,在查询的整个流程中必不可少,而刚才我们又说过,SqlSession实际上是我们操作数据库的一个真实对象,所以可以得出这个结论:Configuration必然和SqlSession有所联系。
源码:
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
//解析config.xml(mybatis解析xml是用的 java dom) dom4j sax...
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
//parse(): 解析config.xml里面的节点
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
public SqlSessionFactory build(Configuration config) {
//注入到SqlSessionFactory
return new DefaultSqlSessionFactory(config);
}
public DefaultSqlSessionFactory(Configuration configuration) {
this.configuration = configuration;
}
实际上我们从源码中可以看到,Configuration是SqlSessionFactory的一个属性,而SqlSessionFactoryBuilder在build方法中实际上就是调用XMLConfigBuilder对xml文件进行解析,然后注入到SqlSessionFactory中。

明确了这一点我们就接着往下看。
根据主线我们现在得到了一个SqlSessionFactory对象,下一步就是要去获取SqlSession对象,这里会调用SqlSessionFactory.openSession()方法来获取,而openSession中实际上就是对SqlSession做了进一步的加工封装,包括增加了事务、执行器等。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//对SqlSession对象进行进一步加工封装
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
//构建SqlSession对象
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
到这里可以得出的小结论是,SqlSessionFactory对象中由于存在Configuration对象,所以它保存了全局配置信息,以及初始化环境和DataSource,而DataSource的作用就是用来开辟链接,当我们调用openSession方法时,就会开辟一个连接对象并传给SqlSession对象,交给SqlSession来对数据库做相关操作。
接着往下,现在我们获取到了一个SqlSession对象,而执行过程就是从这里开始的。
我们可以开始回忆了,平时我们使用MyBatis的时候,我们写的DAO层应该长这样:
public interface DemoMapper {
public List<Map<String,Object>> selectAll(Map<String,Object> map);
}
实际上它是一个接口,而且并没有实现类,而我们却可以直接对它进行调用,如下:
DemoMapper mapper = sqlSession.getMapper(DemoMapper.class);
Map<String,Object> map = new HashMap();
map.put("id","123");
System.out.println(mapper.selectAll(map));
可以猜测了,MyBatis底层一定使用了动态代理,来对这个接口进行代理,我们实际上调用的是MyBatis为我们生成的代理对象。
我们在获取Mapper的时候,需要调用SqlSession的getMapper()方法,那么就从这里深入。
//getMapper方法最终会调用到这里,这个是MapperRegistry的getMapper方法
@SuppressWarnings("unchecked")
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
//MapperProxyFactory 在解析的时候会生成一个map map中会有我们的DemoMapper的Class
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
可以看到这里mapperProxyFactory对象会从一个叫做knownMappers的对象中以type为key取出值,这个knownMappers是一个HashMap,存放了我们的DemoMapper对象,而这里的type,就是我们上面写的Mapper接口。那么就有人会问了,这个knownMappers是在什么时候生成的呢?实际上这是我上一篇漏讲的一个地方,在解析的时候,会调用parse()方法,相信大家都还记得,这个方法内部有一个bindMapperForNamespace方法,而就是这个方法帮我们完成了knownMappers的生成,并且将我们的Mapper接口put进去。
public void parse() {
//判断文件是否之前解析过
if (!configuration.isResourceLoaded(resource)) {
//解析mapper文件
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
//这里:绑定Namespace里面的Class对象*
bindMapperForNamespace();
}
//重新解析之前解析不了的节点
parsePendingResultMaps();
parsePendingCacheRefs();
parsePendingStatements();
}
private void bindMapperForNamespace() {
String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class<?> boundType = null;
try {
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
}
if (boundType != null) {
if (!configuration.hasMapper(boundType)) {
configuration.addLoadedResource("namespace:" + namespace);
//这里将接口class传入
configuration.addMapper(boundType);
}
}
}
}
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
//这里将接口信息put进konwMappers。
knownMappers.put(type, new MapperProxyFactory<>(type));
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
所以我们在getMapper之后,获取到的是一个Class,之后的代码就简单了,就是生成标准的代理类了,调用newInstance()方法。
public T newInstance(SqlSession sqlSession) {
//首先会调用这个newInstance方法
//动态代理逻辑在MapperProxy里面
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
//通过这里调用下面的newInstance方法
return newInstance(mapperProxy);
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
//jdk自带的动态代理
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
到这里,就完成了代理对象(MapperProxy)的创建,很明显的,MyBatis的底层就是对我们的接口进行代理类的实例化,从而操作数据库。
但是,我们好像就得到了一个空荡荡的对象,调用方法的逻辑呢?好像根本就没有看到,所以这也是比较考验Java功底的地方。
我们知道,一个类如果要称为代理对象,那么一定需要实现InvocationHandler接口,并且实现其中的invoke方法,进行一波推测,逻辑一定在invoke方法中。
于是就可以点进MapperProxy类,发现其的确实现了InvocationHandler接口,这里我将一些用不到的代码先删除了,只留下有用的代码,便于分析
/**
* @author Clinton Begin
* @author Eduardo Macarron
*/
public class MapperProxy<T> implements InvocationHandler, Serializable { public MapperProxy(SqlSession sqlSession, Class<T> mapperInterface, Map<Method, MapperMethod> methodCache) {
//构造
this.sqlSession = sqlSession;
this.mapperInterface = mapperInterface;
this.methodCache = methodCache;
} @Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//这就是一个很标准的JDK动态代理了
//执行的时候会调用invoke方法
try {
if (Object.class.equals(method.getDeclaringClass())) {
//判断方法所属的类
//是不是调用的Object默认的方法
//如果是 则不代理,不改变原先方法的行为
return method.invoke(this, args);
} else if (method.isDefault()) {
//对于默认方法的处理
//判断是否为default方法,即接口中定义的默认方法。
//如果是接口中的默认方法则把方法绑定到代理对象中然后调用。
//这里不详细说
if (privateLookupInMethod == null) {
return invokeDefaultMethodJava8(proxy, method, args);
} else {
return invokeDefaultMethodJava9(proxy, method, args);
}
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
//如果不是默认方法,则真正开始执行MyBatis代理逻辑。
//获取MapperMethod代理对象
final MapperMethod mapperMethod = cachedMapperMethod(method);
//执行
return mapperMethod.execute(sqlSession, args);
} private MapperMethod cachedMapperMethod(Method method) {
//动态代理会有缓存,computeIfAbsent 如果缓存中有则直接从缓存中拿
//如果缓存中没有,则new一个然后放入缓存中
//因为动态代理是很耗资源的
return methodCache.computeIfAbsent(method,
k -> new MapperMethod(mapperInterface, method, sqlSession.getConfiguration()));
}
}
在方法开始代理之前,首先会先判断是否调用了Object类的方法,如果是,那么MyBatis不会去改变其行为,直接返回,如果是默认方法,则绑定到代理对象中然后调用(不是本文的重点),如果都不是,那么就是我们定义的mapper接口方法了,那么就开始执行。
执行方法需要一个MapperMethod对象,这个对象是MyBatis执行方法逻辑使用的,MyBatis这里获取MapperMethod对象的方式是,首先去方法缓存中看看是否已经存在了,如果不存在则new一个然后存入缓存中,因为创建代理对象是十分消耗资源的操作。总而言之,这里会得到一个MapperMethod对象,然后通过MapperMethod的excute()方法,来真正地执行逻辑。
执行逻辑
语句类型判断
这里首先会判断SQL的类型:SELECT|DELETE|UPDATE|INSERT,我们这里举的例子是SELECT,其它的其实都差不多,感兴趣的同学可以自己去看看。判断SQL类型为SELECT之后,就开始判断返回值类型,根据不同的情况做不同的操作。然后开始获取参数--》执行SQL。
//execute() 这里是真正执行SQL的地方
public Object execute(SqlSession sqlSession, Object[] args) {
//判断是哪一种SQL语句
Object result;
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
//我们的例子是查询 //判断是否有返回值
if (method.returnsVoid() && method.hasResultHandler()) {
//无返回值
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
//返回值多行 这里调用这个方法
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
//返回Map
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
//返回Cursor
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
} //返回值多行 这里调用这个方法
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {
//返回值多行时执行的方法
List<E> result;
//param是我们传入的参数,如果传入的是Map,那么这个实际上就是Map对象
Object param = method.convertArgsToSqlCommandParam(args);
if (method.hasRowBounds()) {
//如果有分页
RowBounds rowBounds = method.extractRowBounds(args);
//执行SQL的位置
result = sqlSession.selectList(command.getName(), param, rowBounds);
} else {
//如果没有
//执行SQL的位置
result = sqlSession.selectList(command.getName(), param);
}
// issue #510 Collections & arrays support
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
if (method.getReturnType().isArray()) {
return convertToArray(result);
} else {
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
}
return result;
} /**
* 获取参数名的方法
*/
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
if (args == null || paramCount == 0) {
//如果传过来的参数是空
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
//如果参数上没有加注解例如@Param,且参数只有一个,则直接返回参数
return args[names.firstKey()];
} else {
//如果参数上加了注解,或者参数有多个。
//那么MyBatis会封装参数为一个Map,但是要注意,由于jdk的原因,我们只能获取到参数下标和参数名,但是参数名会变成arg0,arg1.
//所以传入多个参数的时候,最好加@Param,否则假设传入多个String,会造成#{}获取不到值的情况
final Map<String, Object> param = new ParamMap<>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
//entry.getValue 就是参数名称
param.put(entry.getValue(), args[entry.getKey()]);
//如果传很多个String,也可以使用param1,param2.。。
// add generic param names (param1, param2, ...)
final String genericParamName = GENERIC_NAME_PREFIX + String.valueOf(i + 1);
// ensure not to overwrite parameter named with @Param
if (!names.containsValue(genericParamName)) {
param.put(genericParamName, args[entry.getKey()]);
}
i++;
}
return param;
}
}
SQL执行(二级缓存)
执行SQL的核心方法就是selectList,即使是selectOne,底层实际上也是调用了selectList方法,然后取第一个而已。
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//MappedStatement:解析XML时生成的对象, 解析某一个SQL 会封装成MappedStatement,里面存放了我们所有执行SQL所需要的信息
MappedStatement ms = configuration.getMappedStatement(statement);
//查询,通过executor
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
在这里我们又看到了上一篇构造的时候提到的,MappedStatement对象,这个对象是解析Mapper.xml配置而产生的,用于存储SQL信息,执行SQL需要这个对象中保存的关于SQL的信息,而selectList内部调用了Executor对象执行SQL语句,这个对象作为MyBatis四大对象之一,一会会说。
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//获取sql语句
BoundSql boundSql = ms.getBoundSql(parameterObject);
//生成一个缓存的key
//这里是-1181735286:4652640444:com.DemoMapper.selectAll:0:2147483647:select * from test WHERE id =?:2121:development
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
//二级缓存查询
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//二级缓存的Cache
Cache cache = ms.getCache();
if (cache != null) {
//如果Cache不为空则进入
//如果有需要的话,就刷新缓存(有些缓存是定时刷新的,需要用到这个)
flushCacheIfRequired(ms);
//如果这个statement用到了缓存(二级缓存的作用域是namespace,也可以理解为这里的ms)
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
//先从缓存拿
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//如果缓存的数据等于空,那么查询数据库
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//查询完毕后将数据放入二级缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
//返回
return list;
}
}
//如果cache根本就不存在,那么直接查询一级缓存
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
首先MyBatis在查询时,不会直接查询数据库,而是会进行二级缓存的查询,由于二级缓存的作用域是namespace,也可以理解为一个mapper,所以还会判断一下这个mapper是否开启了二级缓存,如果没有开启,则进入一级缓存继续查询。
SQL查询(一级缓存)
//一级缓存查询
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
//查询栈+1
queryStack++;
//一级缓存
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//对于存储过程有输出资源的处理
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//如果缓存为空,则从数据库拿
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
//查询栈-1
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
//结果返回
return list;
}
如果一级缓存查到了,那么直接就返回结果了,如果一级缓存没有查到结果,那么最终会进入数据库进行查询。
SQL执行(数据库查询)
//数据库查询
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//先往一级缓存中put一个占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//调用doQuery方法查询数据库
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//往缓存中put真实数据
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
//真实数据库查询
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//封装,StatementHandler也是MyBatis四大对象之一
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//#{} -> ? 的SQL在这里初始化
stmt = prepareStatement(handler, ms.getStatementLog());
//参数赋值完毕之后,才会真正地查询。
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
在真正的数据库查询之前,我们的语句还是这样的:select * from test where id = ?,所以要先将占位符换成真实的参数值,所以接下来会进行参数的赋值。
参数赋值
因为MyBatis底层封装的就是java最基本的jdbc,所以赋值一定也是调用jdbc的putString()方法。
/********************************参数赋值部分*******************************/
//由于是#{},所以使用的是prepareStatement,预编译SQL
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
//拿连接对象
Connection connection = getConnection(statementLog);
//初始化prepareStatement
stmt = handler.prepare(connection, transaction.getTimeout());
//获取了PrepareStatement之后,这里给#{}赋值
handler.parameterize(stmt);
return stmt;
} /**
* 预编译SQL进行put值
*/
@Override
public void setParameters(PreparedStatement ps) {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
//参数列表
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
//拿到xml中#{} 参数的名字 例如 #{id} propertyName==id
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
//metaObject存储了参数名和参数值的对应关系
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
jdbcType = configuration.getJdbcTypeForNull();
}
try {
//在这里给preparedStatement赋值,通过typeHandler,setParameter最终会调用一个叫做setNonNullParameter的方法。代码贴在下面了。
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException | SQLException e) {
throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e);
}
}
}
}
}
//jdbc赋值
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType)
throws SQLException {
//这里就是最最原生的jdbc的赋值了
ps.setString(i, parameter);
}
/********************************参数赋值部分*******************************/
正式执行
当参数赋值完毕后,SQL就可以执行了,在上文中的代码可以看到当参数赋值完毕后,直接通过hanler.query()方法进行数据库查询
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
//通过jdbc进行数据库查询。
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
//处理结果集 resultSetHandler 也是MyBatis的四大对象之一
return resultSetHandler.handleResultSets(ps);
}
可以很明显看到,这里实际上也就是调用我们熟悉的原生jdbc对数据库进行查询。
执行阶段总结
到这里,MyBatis的执行阶段从宏观角度看,一共完成了两件事:
代理对象的生成
SQL的执行
而SQL的执行用了大量的篇幅来进行分析,虽然是根据一条查询语句的主线来进行分析的,但是这么看下来一定很乱,所以这里我会话一个流程图来帮助大家理解:

结果集处理
在SQL执行阶段,MyBatis已经完成了对数据的查询,那么现在还存在最后一个问题,那就是结果集处理,换句话来说,就是将结果集封装成对象。在不用框架的时候我们是使用循环获取结果集,然后通过getXXXX()方法一列一列地获取,这种方法劳动强度太大,看看MyBatis是如何解决的。
@Override
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
//resultMap可以通过多个标签指定多个值,所以存在多个结果集
final List<Object> multipleResults = new ArrayList<>(); int resultSetCount = 0;
//拿到当前第一个结果集
ResultSetWrapper rsw = getFirstResultSet(stmt); //拿到所有的resultMap
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
//resultMap的数量
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
//循环处理每一个结果集
while (rsw != null && resultMapCount > resultSetCount) {
//开始封装结果集 list.get(index) 获取结果集
ResultMap resultMap = resultMaps.get(resultSetCount);
//传入resultMap处理结果集 rsw 当前结果集(主线)
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
} String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
//如果只有一个结果集,那么从多结果集中取出第一个
return collapseSingleResultList(multipleResults);
}
//处理结果集
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap, List<Object> multipleResults, ResultMapping parentMapping) throws SQLException {
//处理结果集
try {
if (parentMapping != null) {
handleRowValues(rsw, resultMap, null, RowBounds.DEFAULT, parentMapping);
} else {
if (resultHandler == null) {
//判断resultHandler是否为空,如果为空建立一个默认的。
//结果集处理器
DefaultResultHandler defaultResultHandler = new DefaultResultHandler(objectFactory);
//处理行数据
handleRowValues(rsw, resultMap, defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
handleRowValues(rsw, resultMap, resultHandler, rowBounds, null);
}
}
} finally {
// issue #228 (close resultsets)
//关闭结果集
closeResultSet(rsw.getResultSet());
}
}
上文的代码,会创建一个处理结果集的对象,最终调用handleRwoValues()方法进行行数据的处理。
//处理行数据
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
//是否存在内嵌的结果集
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
//不存在内嵌的结果集
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
}
//没有内嵌结果集时调用
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext<Object> resultContext = new DefaultResultContext<>();
//获取当前结果集
ResultSet resultSet = rsw.getResultSet();
skipRows(resultSet, rowBounds);
while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) {
//遍历结果集
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null);
//拿到行数据,将行数据包装成一个Object
Object rowValue = getRowValue(rsw, discriminatedResultMap, null);
storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet);
}
}
这里的代码主要是通过每行的结果集,然后将其直接封装成一个Object对象,那么关键就是在于getRowValue()方法,如何让行数据变为Object对象的。
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException {
//创建一个空的Map存值
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
//创建一个空对象装行数据
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);
if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())){
//通过反射操作返回值
//此时metaObject.originalObject = rowValue
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
if (shouldApplyAutomaticMappings(resultMap, false)) {
//判断是否需要自动映射,默认自动映射,也可以通过resultMap节点上的autoMapping配置是否自动映射
//这里是自动映射的操作。
foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues;
}
foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null;
}
return rowValue;
}
在getRowValue中会判断是否是自动映射的,我们这里没有使用ResultMap,所以是自动映射(默认),那么就进入applyAutomaticMappings()方法,而这个方法就会完成对象的封装。
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String columnPrefix) throws SQLException {
//自动映射参数列表
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(rsw, resultMap, metaObject, columnPrefix);
//是否找到了该列
boolean foundValues = false;
if (!autoMapping.isEmpty()) {
//遍历
for (UnMappedColumnAutoMapping mapping : autoMapping) {
//通过列名获取值
final Object value = mapping.typeHandler.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
//如果值不为空,说明找到了该列
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() && !mapping.primitive)) {
// gcode issue #377, call setter on nulls (value is not 'found')
//在这里赋值
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues;
}
我们可以看到这个方法会通过遍历参数列表从而通过metaObject.setValue(mapping.property, value);对返回对象进行赋值,但是返回对象有可能是Map,有可能是我们自定义的对象,会有什么区别呢?
实际上,所有的赋值操作在内部都是通过一个叫ObjectWrapper的对象完成的,我们可以进去看看它对于Map和自定义对象赋值的实现有什么区别,问题就迎刃而解了。
先看看上文中代码的metaObject.setValue()方法
public void setValue(String name, Object value) {
PropertyTokenizer prop = new PropertyTokenizer(name);
if (prop.hasNext()) {
MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
if (value == null) {
// don't instantiate child path if value is null
return;
} else {
metaValue = objectWrapper.instantiatePropertyValue(name, prop, objectFactory);
}
}
metaValue.setValue(prop.getChildren(), value);
} else {
//这个方法最终会调用objectWrapper.set()对结果进行赋值
objectWrapper.set(prop, value);
}
}
我们可以看看objectWrapper的实现类:
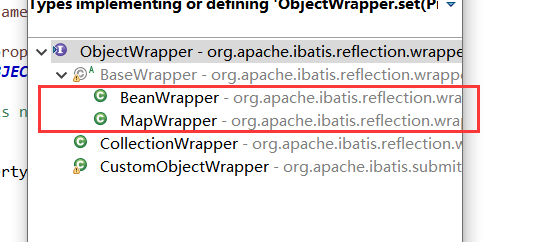
而我们今天举的例子,DemoMapper的返回值是Map,所以objectWrapper会调用MapWrapper的set方法,如果是自定义类型,那么就会调用BeanWrapper的set方法,下面看看两个类中的set方法有什么区别:
//MapWrapper的set方法
public void set(PropertyTokenizer prop, Object value) {
if (prop.getIndex() != null) {
Object collection = resolveCollection(prop, map);
setCollectionValue(prop, collection, value);
} else {
//实际上就是调用了Map的put方法将属性名和属性值放入map中
map.put(prop.getName(), value);
}
} //BeanWrapper的set方法
public void set(PropertyTokenizer prop, Object value) {
if (prop.getIndex() != null) {
Object collection = resolveCollection(prop, object);
setCollectionValue(prop, collection, value);
} else {
//在这里赋值,通过反射赋值,调用setXX()方法赋值
setBeanProperty(prop, object, value);
}
}
private void setBeanProperty(PropertyTokenizer prop, Object object, Object value) {
try {
Invoker method = metaClass.getSetInvoker(prop.getName());
Object[] params = {value};
try {
method.invoke(object, params);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
} catch (Throwable t) {
throw new ReflectionException("Could not set property '" + prop.getName() + "' of '" + object.getClass() + "' with value '" + value + "' Cause: " + t.toString(), t);
}
}
上面两个set方法分别是MapWrapper和BeanWrapper的不同实现,MapWrapper的set方法实际上就是将属性名和属性值放到map的key和value中,而BeanWrapper则是使用了反射,调用了Bean的set方法,将值注入。

结语
至此,MyBatis的执行流程就为止了,本篇主要聊了从构建配置对象后,MyBatis是如何执行一条查询语句的,一级查询语句结束后是如何进行对结果集进行处理,映射为我们定义的数据类型的。
由于是源码分析文章,所以如果只是粗略的看,会显得有些乱,所以我还是再提供一张流程图,会比较好理解一些。

当然这张流程图里并没有涉及到关于回写缓存的内容,关于MyBatis的一级缓存、二级缓存相关的内容,我会在第三篇源码解析中阐述。
手把手带你阅读Mybatis源码(二)执行篇的更多相关文章
- 手把手带你阅读Mybatis源码(三)缓存篇
前言 大家好,这一篇文章是MyBatis系列的最后一篇文章,前面两篇文章:手把手带你阅读Mybatis源码(一)构造篇 和 手把手带你阅读Mybatis源码(二)执行篇,主要说明了MyBatis是如何 ...
- 手把手带你阅读Mybatis源码(一)构造篇
前言 今天会给大家分享我们常用的持久层框架——MyBatis的工作原理和源码解析,后续会围绕Mybatis框架做一些比较深入的讲解,之后这部分内容会归置到公众号菜单栏:连载中…-框架分析中,欢迎探讨! ...
- 学不懂Netty?看不懂源码?不存在的,这篇文章手把手带你阅读Netty源码!
阅读这篇文章之前,建议先阅读和这篇文章关联的内容. 1. 详细剖析分布式微服务架构下网络通信的底层实现原理(图解) 2. (年薪60W的技巧)工作了5年,你真的理解Netty以及为什么要用吗?(深度干 ...
- myBatis源码解析-日志篇(1)
上半年在进行知识储备,下半年争取写一点好的博客来记录自己源码之路.在学习源码的路上也掌握了一些设计模式,可所谓一举两得.本次打算写Mybatis的源码解读. 准备工作 1. 下载mybatis源码 下 ...
- myBatis源码解析-缓存篇(2)
上一章分析了mybatis的源码的日志模块,像我们经常说的mybatis一级缓存,二级缓存,缓存究竟在底层是怎样实现的.此次开始分析缓存模块 1. 源码位置,mybatis源码包位于org.apach ...
- myBatis源码解析-类型转换篇(5)
前言 开始分析Type包前,说明下使用场景.数据构建语句使用PreparedStatement,需要输入的是jdbc类型,但我们一般写的是java类型.同理,数据库结果集返回的是jdbc类型,而我们需 ...
- myBatis源码解析-数据源篇(3)
前言:我们使用mybatis时,关于数据源的配置多使用如c3p0,druid等第三方的数据源.其实mybatis内置了数据源的实现,提供了连接数据库,池的功能.在分析了缓存和日志包的源码后,接下来分析 ...
- myBatis源码解析-反射篇(4)
前沿 前文分析了mybatis的日志包,缓存包,数据源包.源码实在有点难顶,在分析反射包时,花费了较多时间.废话不多说,开始源码之路. 反射包feflection在mybatis路径如下: 源码解析 ...
- Mybatis源码系列 执行流程(一)
1.Mybatis的使用 public static void main(String[] args) throws IOException { //1.获取配置文件流 InputStream is ...
随机推荐
- 【转】面向GC的Java编程
Java程序员在编码过程中通常不需要考虑内存问题,JVM经过高度优化的GC机制大部分情况下都能够很好地处理堆(Heap)的清理问题.以至于许多Java程序员认为,我只需要关心何时创建对象,而回收对象, ...
- 原生javascript实现仿QQ延时菜单
一.实现原理 定时器和排他思想 二.代码 <!DOCTYPE html> <html> <head> <title></title> < ...
- 第一篇博客-- 走上IT路
首先介绍一下本人,我是一名在校大学生,在一次学长分享学习经验时了解到,写博客可以帮助复习.所以这就是我要写博客的原因. 我是非常喜欢网络安全技术,因此我选择了我这个专业.在接下来的一段时间我会在这里记 ...
- [C++]最小生成树
1. 最小生成树定义 树是指没有环路的图,生成树就是指一个图上面删除一些边,使它没有环路. 最小生成树就是指生成树中边权之和最小的那一种. 上图的最小生成树就是这样: 2. Prim 算法 2.1. ...
- django count(*) 慢查询优化
分页显示是web开发常见需求,随着表数据增加,200万以上时,翻页越到后面越慢,这个时候慢查询成为一个痛点,关于count(*)慢的原因,简单说会进行全表扫描,再排序,导致查询变慢.这里介绍postg ...
- auth.User.groups: (fields.E304) Reverse accessor for 'User.groups'
创建表,运行下面命令,出错 makemigrations 原因:继承auth_user 解决方案 在settings.py文件添加 AUTH_USER_MODEL = "app名称.类名&q ...
- 1.HelloWorld 仪式感
HelloWorld: 1.随便新建一个文件夹,存放代码. 2.新建一个java文件 文件后缀改为 .java Hello.java 系统可能没显示文件后缀名,我们需要手动打开 3.编写代码 publ ...
- 最近面试 有人问 sqlite 用过么 sqlite 不是 嵌入式的 开发 么 难道最近还 web开发 了?
找了一个 sqlite expert 安装了一下
- ImportError: Failed to import pydot. You must install pydot and graphviz for `pydotprint` to work.
用了pip install pydot; pip install graphviz都不行 去网上查了才发现window下要去https://graphviz.gitlab.io/下载windows版本 ...
- 什么是 Trait
Trait 是从 PHP 5.4 加入的一种细粒度代码复用的语法.以下是官方手册对 Trait 的描述: Trait 是为类似 PHP 的单继承语言而准备的一种代码复用机制.Trait 为了减少单继承 ...