mysql(1):简介
typora-root-url: ./
SQL语法顺序和执行顺序
SQL语法顺序
SELECT [DISTINCT] <select_list>
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
SQL执行顺序
(8)SELECT(9)DISTINCT <select_list>
(1)FROM <left_table>
(3)<join_type> JOIN <right_table>
(2)ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)<sum()avg()等聚合函数>
(7)HAVING <having_condition>
(10)ORDER BY <order_by_condition>
(11)LIMIT <limit_number>
第一步:加载from子句的前两个表计算笛卡尔积,生成虚拟表vt1;
第二步:筛选关联表符合on表达式的数据,保留主表,生成虚拟表vt2;
第三步:如果使用的是外连接,执行on的时候,会将主表中不符合on条件的数据也加载进来,做为外部行
【如果from子句中的表数量大于2,则重复第一步到第三步,直至所有的表都加载完毕,更新vt3】
第四步:执行where表达式,筛选掉不符合条件的数据生成vt4;
第五步:执行group by子句。group by 子句执行过后,会对子句组合成唯一值并且对每个唯一值只包含一行,生成vt5。一旦执行group by,后面的所有步骤只能得到vt5中的列(group by的子句包含的列)和聚合函数。
第六步:执行聚合函数,生成vt6;
第七步:执行having表达式,筛选vt6中的数据,生成vt7;
第八步:从vt7中筛选列,生成vt8;
第九步:执行distinct,对vt8去重,生成vt9。其实执行过group by后就没必要再去执行distinct,因为分组后,每组只会有一条数据,并且每条数据都不相同。
第十步:对vt9进行排序,此处返回的不是一个虚拟表,而是一个游标,记录了数据的排序顺序,此处可以使用别名;
第十一步:执行limit语句,将结果返回给客户端
MySQL架构分析和执行流程分析
逻辑架构
连接器
服务管理
连接池
SQL接口
解析器
查询优化器
查询缓存
可插拔存储引擎
MyISAM
InnoDB
Memory
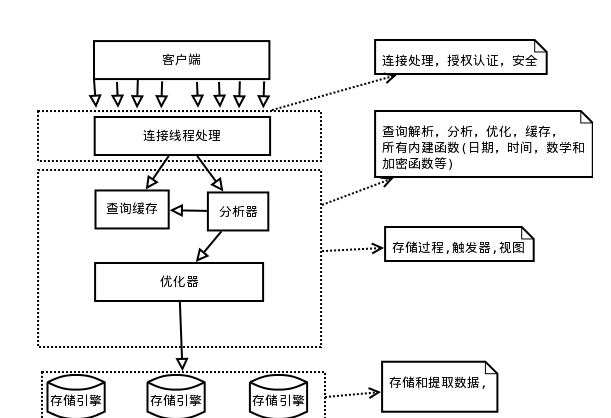
第一层是链接线程处理,这一层并非MySQL独有,在这一层中,主要功能有链接处理,授权验证,安全等操作。
第二层是MySQL主要层,所有的语句解析、分析、优化和缓存都在这一层进行,同时内建函数,如日期、时间等函数也在这一层进行。
第三层中所有的跨存储引擎的功能都在该层完成,例如视图、存储过程、触发器等。
第四层为存储引擎,负责数据的获取和存储。在该层提供了许多API供上层服务层调用,完成数据操作。存储引擎不能解析SQL,互相之间也不能通信。仅仅是简单的响应服务器的请求。
执行流程
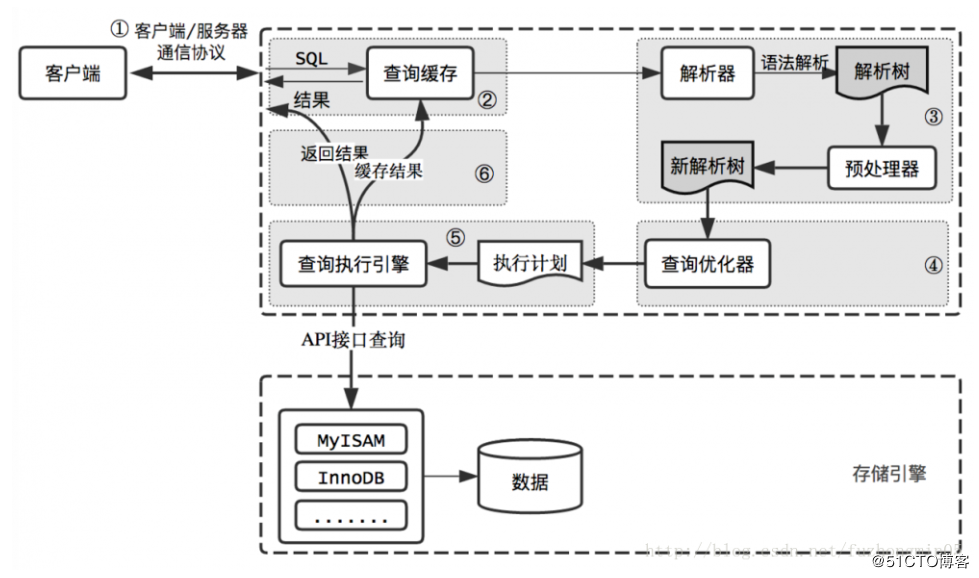
1、客户端/服务器通信协议
该部分为半双工状态,要么是客户端向服务器发送数据,要么是服务器向客户端发送数据,二者不能同时进行。
当客户端向服务器发送数据时,以单独一个数据包的形式发送。若查询太大,服务器会拒绝接收更多的数据,并抛出异常;
当服务器向客户端发送数据时,一般包括多个数据包。客户端必须完整的接收所有的数据,不能拒绝接收部分数据只获取前几条。
在开发过程中应该尽量保持简单和必要的查询,这也是减少select *和加上limit限制的原因。
2、查询缓存
在解析查询语句之前,如果开启了查询缓存,MySQL会检查当前查询是否命中缓存中的数据,如果命中,检查用户权限后会直接将缓存中的数据响应给客户端,否则会执行后面的解析等操作。
MySQL的缓存存放在一个引用表中,以一个哈希值作为索引。该索引包含了一系列与查询有关的信息,例如查询本身、要查询的表等。当查询语句中包含函数、用户变量、临时表时就不会存入缓存。
MySQL的缓存也存在失效的状态,所有会影响查询结果的信息都会糅合进一个哈希值作为索引,所以当某一个表的数据或者结构发生变化时(即对某表执行写操作时),该表所涉及到的所有缓存都会失效。当查询缓存非常大时,这个操作会造成较大的系统消耗。
在读操作时,每一个查询语句执行前都会检查是否命中缓存,执行后都会存入缓存。是否打开缓存应慎之又慎。
3、语法解析及预处理
语法解析会通过关键字将查询语句进行解析,生成一棵解析树,这个过程主要是通过语法进行检查。
预处理会将解析树再次进行解析,会检查查询所包含的表、列等是否存在。
4、查询优化
一条语句有多种实现方式,优化器的作用就是评估执行成本并且选择成本最小的那一个。优化器会对执行顺序进行重新排序并执行,选出MySQL认为的最优解。
MySQL的查询优化器是一个非常复杂的部件,它使用了非常多的优化策略来生成一个最优的执行计划:
重新定义表的关联顺序
优化MIN()和MAX()函数(找某列的最小值,如果该列有索引,只需要查找B+Tree索引最左端,反之则可以找到最大值)
提前终止查询(比如:使用Limit时,查找到满足数量的结果集后会立即终止查询)
优化排序(老版本:两次传输排序,即先读取行指针和需要排序的字段在内存中对其排序,然后再根据排序结果去读取数据行;新版本:单次传输排序,也就是一次读取所有的数据行,然后根据给定的列排序。对于I/O密集型应用,效率会高很多)
5、查询执行引擎
查询执行引擎会根据优化阶段生成的执行计划(一棵指令树),依次执行并给出结果。主要实现方式是通过调用存储引擎的API实现,通过叠加等操作实现查询。
6、响应给客户端
无论是否有查询结果,都会返回给客户端,包括影响到行数、执行时长等。
此时若查询缓存打开,会将查询结果存入缓存。
当有查询结果时,将结果集返回是一个增量过程。mysql可能在生成的第一条结果时就会将结果返回给客户端,客户端不断接收直至完毕。服务端无需存储结果集占用内存,客户端也可以第一时间接收到结果。
物理存储结构
日志文件
错误日志
二进制日志
通用查询日志
慢查询日志
事务日志:重做日志redo log、回滚日志undo log
redo log通常是物理日志,记录的是数据页的物理修改,用来恢复提交后的物理数据页(只能恢复到最后一次提交的位置)。
undo log一般是逻辑日志,根据每行记录进行记录,用来回滚行记录到某个版本。
中继日志
数据文件
InnoDB数据文件
MyISAM数据文件
mysql(1):简介的更多相关文章
- MySql 正则表达式简介及使用
MySql正则表达式简介及使用 by:授客 QQ:1033553122 简介 正则表达式描述了一组字符串,该字符放置于REGEXP工具后面.作用是将一个正则表达式与一个文本串进行比较. 最简单的正则表 ...
- MySQL日志简介
一.MySQL日志简介 二.错误日志 作用: 记录mysql数据库的一般状态信息及报错信息,是我们对于数据库常规报错处理的常用日志. 默认位置: $MYSQL_HOME/data/ 开启方式:(MyS ...
- 数据库----ORACLE和MYSQL数据库简介
一.什么是数据库? 数据库(Database---DB)按照组织.储存和管理数据的仓库.(理解以下三个概念) 数据(Data)用来描述事物的记录都可称数据,如文字音乐图像. 数据库系统(Dat ...
- Linux中Mysql的简介和安装
MySQL 简介 点击查看MySQL官方网站 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,后来被Sun公司收购,Sun公司后来又被Oracle公司收购,目前属于Oracle旗 ...
- MySQL视图简介与操作
1.准备工作 在MySQL数据库中创建两张表balance(余额表)和customer(客户表)并插入数据. create table customer( id int(10) primary key ...
- MySQL从删库到跑路(一)——MySQL数据库简介
作者:天山老妖S 链接:http://blog.51cto.com/9291927 一.MySQL简介 1.MySQL简介 MySQL是一个轻量级关系型数据库管理系统,由瑞典MySQL AB公司开发, ...
- mysql的简介和使用
mysql简介 数据的所有存储,检索,管理和处理实际上是由数据库软件--DBMS(数据库管理系统)完成的 mysql是一种DBMS,即它是一种数据库软件 mysql工具 mysql是一个客户机-服务器 ...
- mysql 存储过程简介
存储过程类似一个存储在数据库的一个数据库脚本.它类似一个方法,可以批量执行一些数据库的操作. 本文编写一个简单的存储过程来快速了解存储过程. 1.因为存储过程类似编程语言的方法,所以方法中可能会用到 ...
- mysql存储过程简介
创建存储过程CREATE PROCEDURE productpricing(OUT pl DECIMAL(8,2),OUT ph DECIMAL(8,2),OUT pa DECIMAL(8,2))BE ...
- MySQL函数简介
//将时间戳长整形数值转换为yyyy-MM-dd HH:mm:ss格式SELECT FROM_UNIXTIME(CREATE_TIME, '%Y-%m-%d %H:%i:%S') FROM TBLS ...
随机推荐
- 我国自主开发的编程语言“木兰”居然是一个披着“洋”皮的Python!
究竟是真“自主”,还是又一个披着“洋”皮的“红芯浏览器”? 作者 | 沉迷单车的追风少年 出品 | CSDN博客 昨天看到新闻: ! 心头一震,看起来很厉害啊!毕竟前几天美国宣布要对中国AI软 ...
- Python之pptx实现添加内容与删除(移动)页操作
问题背景 大量表格数据需要生成指定格式的ppt文件,内容以文字和表格为主,首尾页与内容有固定格式.博主不熟悉VBA操作,希望通过模板用Python完成自动化. 基本思路 使用xlrd模块读取xlsx文 ...
- 常用的一些git命令整合
一.创建一个版本库 1.mkdir xxx 2.git init 使用git init命令将这个目录变成Git可以管理的仓库 这个版本仓库创建好了,xxx目录下有一个隐藏的.git目录(里面有暂存区( ...
- Pwnable.kr
Dragon —— 堆之 uaf 开始堆的学习之旅. uaf漏洞利用到了堆的管理中fastbin的特性,关于堆的各种分配方式参见堆之*bin理解 在SecretLevel函数中,发现了隐藏的syste ...
- 2019-08-21 纪中NOIP模拟A组
T1 [JZOJ6315] 数字 题目描述
- openWRT和LuCI
openwrt是一套集成在板子上的系统,通过ip进入到其页面上 Luci是lua和UCI统一配置接口的合体,实现路由的网页配置界面(相当于一个前端框架)
- AcWing 1049. 大盗阿福
//f[i,j]表示所有走了i步,且当前位于状态j的所有走法 j=1表示选第i个 j=0表示不选 //如果j=0 那么表示不选第i个 那么就可以从f[i-1,0]和f[i-1,1]转移过来 //如果j ...
- 用数学解赌博问题不稀奇,用赌博解数学问题才牛B
有一个经典的概率问题:平均需要抛掷多少次硬币,才会首次出现连续的 n 个正面?它的答案是 2^(n+1) – 2 .取 n=2 的话,我们就有这样的结论:平均要抛掷 6 次硬币,才能得到两个连续的正面 ...
- Vue.js 源码目录设计(二)
Vue.js 的源码都在 src 目录下,其目录结构如下. src ├── compiler # 编译相关 ├── core # 核心代码 ├── platforms # 不同平台的支持 ├── se ...
- redis 列表类型list
列表类型(list)1.插入 左侧插入 :lpush key value1 value2 value3... 右侧插入: lpush key value1 value2 value3... 在指定元素 ...