零基础入门python爬虫(一)

✍写在前面:
欢迎加入纯干货技术交流群Disaster Army:317784952
接到5月25日之前要交稿的任务我就一门心思想写一篇爬虫入门的文章,可是我并不会。还好有将近一个月的时间去学习,于是我每天钻在书和视频教程里。其实并不难的,我只是想做到能够很好的理解它并用自己的语言较好的表达出来,也许你将看到的是史上最不专业的技术交流文章,没错这就是我想要的。我力求能让没有编程基础同我一样爱黑客技术却苦于看不到出路的同学们在24小时之内明白爬虫是怎么一回事。我想这才是我加入中国红客联盟太极实验室在红客精神的号召下做的有意义的事。学习技术一定要学会付出、开源、共享、互助,很多大牛似乎不愿意这么做了,我们入门小菜鸟只要够团结,乐于奉献就一定可以达到1+1>2的双赢效果。总之共同努力吧!
☝第一章
0x00 python****的认识、安装
官面上的话自行去百度,这里我只介绍我所掌握到的、最重要的信息。
特点:
(1)跨平台开发
(2)以语法简洁清晰著称
(3)缩进控制严格
至于说爬虫需不需要编程基础,不用多说,君不见本屌在这个月之前的n多个月里是多么苦苦的啃教程,对么下三赖的求指点。其实自学的进步速度太慢了,此文也希望看到的码阔多多提点!
更多信息:
安装也是极易的,只是有python2.7和python3需要纠结选一下。菜菜也不多做建议了,各有所长,python是任性的,不顾及老用户感受强行不兼容更代,足以见得其魄力和自信。2.7的用户较多一点,初学者想用大神的exp不得已会选择它,3的用户逐日增加,人家既然更代自然有好的原因。不必担心,到最后基本上差异在哪里都会知道的。
还是那句话,官面上可以查到的就不多聊,交流文章多写作者的看法,意见不统一的喷过来就是。很多教程会建议一开始的时候用python自带的IDLE写代码,简洁没有代码补全提示,适合初学者!我差点就信了!你会觉得怎么打都有一种好TM业余的感觉有没有?我的观点是:不是武功练到什么程度用什么剑,而是有适合自己的绝世好剑就绝对不用绝世第二剑。所以用了一段时间的IDLE我就决定换一款炫酷的编译器,于是我选择了Atom(这个时候有一个认识上的错误。)然后一个字都没写就安装activate-power-mode插件,开始震屏,冒泡,好不炫酷。
安装好了python,有了编译器,我们开始编程了,打开编译器输入
print (“Hello Word”),保存文件名为1.py,就把它保存在桌面上。然后cmd
cd /d C:\\Users\Administrator\Desktop
python 1.py
如果打印:Hello word,那么恭喜你,你学会编程了!(我的天!)如果打印失败,那么你和兄弟我起初时犯了一样的错误:没有设置环境变量。
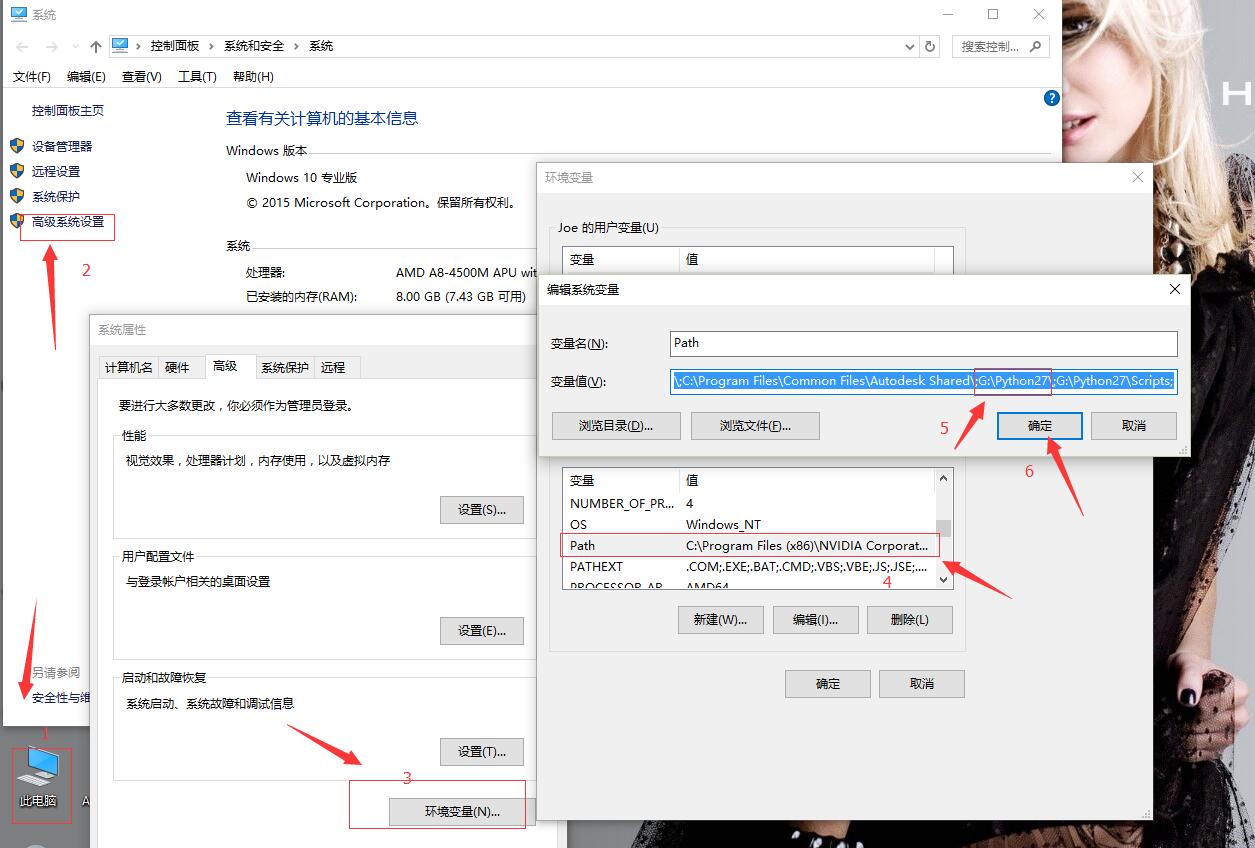
这张图应该可以说明问题了,我的电脑>属性>高级系统设置>环境变量>pach>最后面加;G:\python27(根据自己安装路径来改)。
这回就可以打印了,好吧你也学会编程了!(我天哪!)
**0x001 **将网页下载到本地
我们要用到python的标准模块urllib,具体下面的多种方法可以dir打开查看的,代码如下,供您消遣。大多数同学都会觉得太小儿科的,不太懂得不必细究,只需知道用这么个模块,这么个方法可以干这么个事情!
# -*-coding:utf-8 -*-
# 首先进行编码申明
import urllib
# 导入urllib模块
url = "http://www.xxoo.com/"
# 变量赋值
urllib.urlretrieve(url, "C:\\Users\\用户名\\Desktop\\g00gle.txt")
# urlretrieve方法下载到本地
这样就将网页下载到本地了


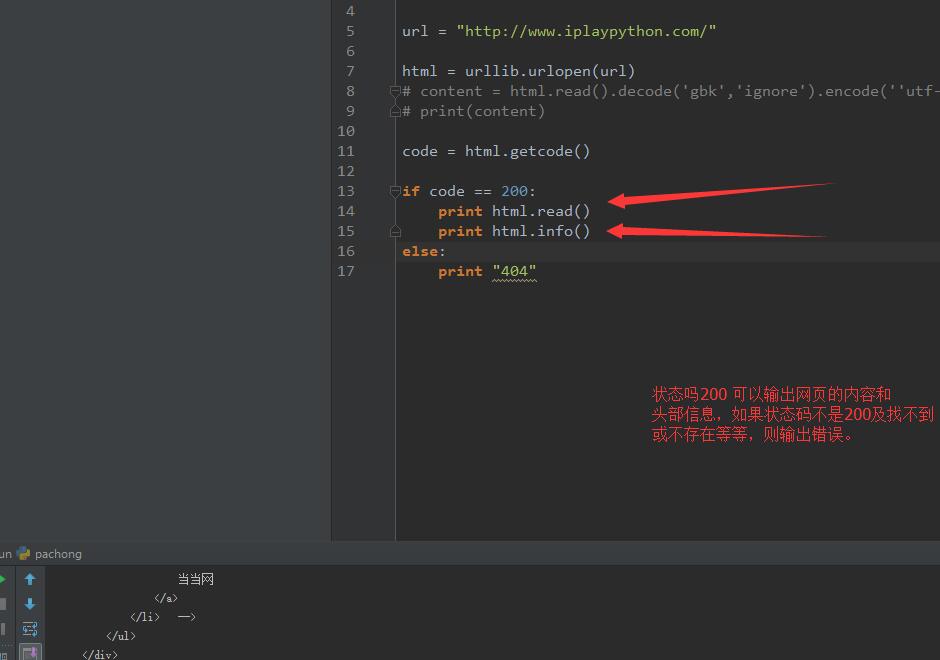
**0x002 **判断网页是否可以抓取以及抓取进度
思路是这样的:我们针对一个网页首先要看它是否可以爬取,如果可以我们抓取他的什么?抓取它的内容、头部信息、状态码、传入网址等,代码如下:
# -*-coding:utf-8 -*-
import urllib
url = "http://www.163.com/"
html = urllib.urlopen(url)
# content = html.read().decode('gbk','ignore').encode(''utf-8)
# print(content)
code = html.getcode()
# 网页状态码,变量code是一个整形
if code == 200:
print html.read()
print html.info()
else:
print "不明飞行物."
# if判断语句判断网页返回是否正常,如果正常返回他的内容、头部信息、状态码、传入网址等
这里,urllib中用的的方法:
# urlopen()
#获取类文件对象
# read()
#读取文件内容
# infor
# 获取头部信息Header
#Getcode
#获取网页状态码
#geturl
#传入网址
举一个例子:
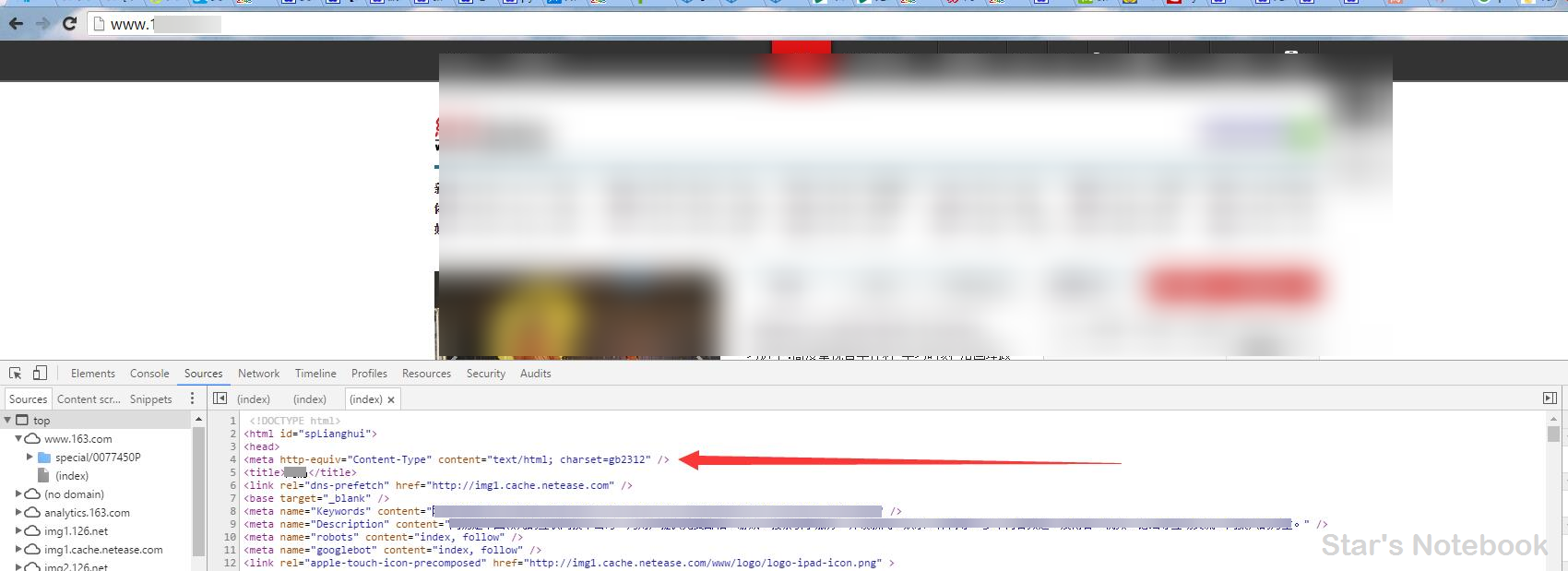
这是某站的Header、Sever、Content-Type、Last-Modified
用上面代码抓取打印的结果:

然后我们用回调函数的方法写一段有读取进度的抓取网页的代码。
# -*-coding:utf-8 -*-
import urllib
def callback(a,b,c):
# 回调函数
# @a:xxx
# @b:xxx
# @c:xxx
down_program = 100.0 * a * b / c
if down_program >100:
down_program =100
print "%.1f%%"% down_program
# 字符串拼接%.4f让输出小数点后1位
print ">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%"
url = "http://tieba.baidu.com/"
local = "C:\\Users\\Joe\\Desktop\\papa2.html"
urllib.urlretrieve(url,local,callback)
# 调用了上面封装的callback函数
技术有限,本来想让它
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>100%这样读取的,懒得弄了,没再深究。
**0x003 **你发现换了编译器
对的,至于是为什么呢?因为到后来我才明白编译器、文本编译器、IDE之间的区别,真是愚笨!我是这样理解的,就像大保健一样,IDE小姐可以提供陪吃、推拿、跳舞、刮痧、n推背等服务,编译器呢晚上进屋白天走人,文本编译器……类似于什么呢?充气娃娃?它们不能对比各有所长。Atom严格上来说属于文本编译器,本身不能断点测试,但加载插件后可以。还有,Atom想Chrorme一样任性,自动强制装在系统盘,其实之前忍了它……现在找到我的绝世好剑了,不能忍,Pycharm取而代之。Sublimetext,人气之高,自然也不错。
**0x004 **本章小结
本章我们安装了Python环境,配置了环境变量,浅尝了编程,抓取了网页内容,并有进度条的下载到了本地。其实都是一些简单的事情。简单区分了一下编译器、文本编译器、IDE之间的区别。这个过程中我肯定有认识上和方法上不当的地方,欢迎大家批过来!预知后事如何,咱们下回分解!
—————— 
未经沟通转载,将追究法律责任,请尊重原创劳动成果!
零基础入门python爬虫(一)的更多相关文章
- 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程
点击了解更多Python课程>>> 零基础入门Python实战:四周实现爬虫网站 Django项目视频教程 适用人群: 即将毕业的大学生,工资低工作重的白领,渴望崭露头角的职场新人, ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- 3个月零基础入门Python+数据分析,详细时间表+计划表分享
大家好,我是白云. 今天想给大家分享的是三个月零基础入门数据分析学习计划.有小伙伴可能会说,英语好像有点不太好,要怎么办?所以今天我给大家分享的资源呢就是对国内的小伙伴很友好,还附赠大家一份三个月学 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- 小甲鱼零基础入门PYTHON
000.愉快的开始 00:17:37 ☆ 001.我和Python的第一次亲密接触 00:13:26 ★ 002.用Python设计第一个游戏 00:24:00 ★ 003.小插曲之变量和字符 ...
- 零基础入门Python数据分析,只需要看懂这一张图,附下载链接!
摘要 在做数据分析的过程中,经常会想数据分析到底是什么?为什么要做数据数据分析?数据分析到底该怎么做?等这些问题.对于这些问题,一开始也只是有个很笼统的认识. 最近这两天,读了一下早就被很多人推荐的& ...
- 零基础入门Python游戏学习笔记(1)
书是车洪于2020年出的,到手已经过去一年多了.现在学来,好多东西不一样了. 作者的GitHub,大家知道的原因,并不好打开. 代码就不搬了,只是为了学习方便,书籍勘误搬一下. 一.开发环境: 1.p ...
- 2017寒假零基础学习Python系列之 印子
今日为2017年2月6日,据在慕课网上学习廖雪峰Python教程也快一周左右了,完全是零基础入门Python,大一上学期粗浅的接触学习了C语言,早就听说过Python语言的大名,又想把Python的爬 ...
- 从零起步 系统入门Python爬虫工程师 ✌✌
从零起步 系统入门Python爬虫工程师 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 大数据时代,python爬虫工程师人才猛增,本课程专为爬虫工程师打造, ...
随机推荐
- 测试并整理的 Airpods Pro 刻字可用的最全特殊符号
天气符号 ☉ 文化符号 卍卐 办公室符号 № ℗ ℡ ℀ ℅ ™ © ® ‰ ¶ § 技术符号 ⇧ 打勾符号 ˇ ∨ √ 人的符号 ♀ ♂ ヅ ツ ü 星星符号 ☆ ★ ✽ 箭头符号 ↖ ↗ ↘ ...
- 2019杭电多校 permutation2
Problem:http://acm.hdu.edu.cn/contests/contest_showproblem.php?pid=1007&cid=852 #include<bits ...
- 515,前端性能优化--减少http请求(待补充)
对于影响页面呈选的因素有三个地方:服务器连接数据库并计算返回数据,http请求以及数据(文件)经过网络传输,文件在浏览器中计算渲染呈选:其中大约80%的时间都消耗在了http的请求上,所以要想大幅度的 ...
- 安装rocky版本:openstack-nova-compute.service 计算节点服务无法启动
问题描述:进行openstack的rocky版本的安装时,计算节点安装openstack-nova-compute找不到包. 解决办法:本次实验我安装的rocky版本的openstack 先安装cen ...
- 【Python】 平方根
平方根,又叫二次方根,表示为[√ ̄],如:数学语言为:√ ̄16=4.语言描述为:根号下16=4. 以下实例为通过用户输入一个数字,并计算这个数字的平方根: num = float(input('请输入 ...
- [CF]Round510
由于我的codeforces的帐号登不上,所以我错过了这场比赛,只好赛后再抄题解自己做. A Benches 最大的情况就是所有人都挤在那个人最多的长椅上,最小的情况是所有人尽量平均的坐. #incl ...
- [AGC027A]Candy Distribution Again
Description AGC027A 你有一些糖果,你要把这些糖果一个不剩分给一些熊孩子,但是这帮熊孩子只要特定数目的糖果,否则就会不开心,求最多的开心人数. Solution 如果\(\sum a ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- .NET知识梳理——2.反射
1. 反射 1.1 DLL-IL-Metadata-反射 DLL:程序集,包含IL 和Metadada IL:面向对象中间语言(不太好阅读) Metadata描述了dll.exe中的各种 ...
- 973. 最接近原点的 K 个点
1.暴力排序,新建节点类重载小于符号排序. class Solution { public: struct comb{ int index,distance; comb():index(0),dist ...