记一次为解决Python读取PDF文件的Shell操作
一、背景
本想将 PDF 文件转换为 Word 文档,然后网上搜索了一下发现有挺多转换的软件。有的是免费的、收费,咱也不知哪个好使,还得一个个安装试用。先不说能不解决问题,就这安装试用想想就脑壳疼。便想起了"Python 大法",随即搜了几篇看起来比较完整的博客,二话不说粘贴复制,改改运行试试。使用环境(python3.6+pdfminer3k),代码这里就不放出来了。
二、问题
运气不好,这一试就报错WARNING:root:GBK-EUC-H,然后又搜了一下有同样的报错问题,但是这篇博客没啥大用,仅仅是知道缺了相关的字体文件,通过其中的链接顺藤摸瓜找到了 github 上的字体文件列表页
https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap
三、解决
下载了报错的对应文件 GBK-EUC-H.pickle.gz,然后将其文件解压把放置 Python 的安装目录下 Lib\site-packages\pdfminer\cmap 路径中,再次运行又报错 "pdfminer.converter:undefined: <PDFCIDFont: basefont='΢ÈíÑźÚ', cidcoding='Adobe-GB1'>, 3027" 。可以说明第一个问题已经解决了,接下来的报错按照这个方法来就行了。但是想想等下有报错还得下,索性全部下下来。
四、一顿分析及 Shell 操作
1.先网页 F12 打开控制台分析 Element 元素,Xpath 信息 "//td[@class='content']/span/a/@href"
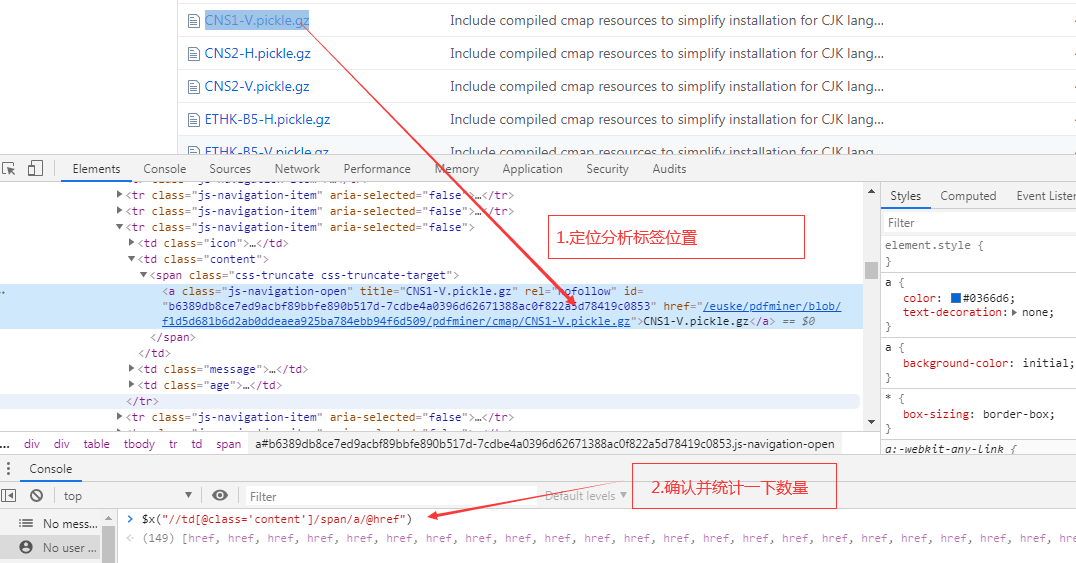
2.使用 curl 命令获取响应并处理 (通过"检查网页源码"发现 span 标签和 a 标签同行)
- 先确认是否与步骤 1 中的数量一致
# 通过获取父标签信息的之后的行
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap | grep -A1 '<td class="content">' |grep "<span" | wc -l
# 直接正则匹配到行
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap | grep -E '\s+<span.*><a.*title' |wc -l
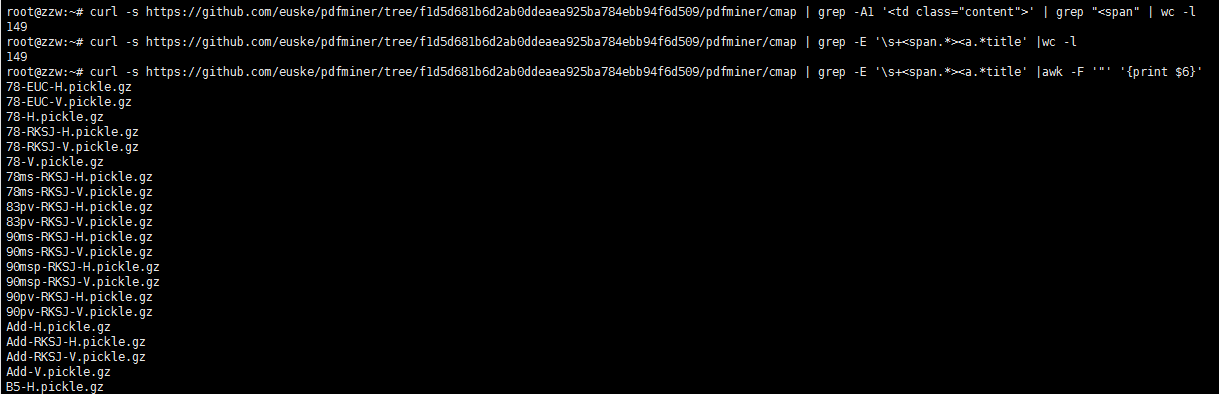
- 确认一致,则进行下一步数据清理,进而获得所有字体文件列表
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap | grep -E '\s+<span.*><a.*title' |awk -F '"' '{print $6}'
3.进入某个文件详情页,分析下载请求地址
将下面链接放入地址栏,会进入文件下载操作,所以这就是文件的真实下载地址

4.对其他两三个文件进行同样分析,发现其规律,部分固定链接地址
https://raw.githubusercontent.com/euske/pdfminer/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap
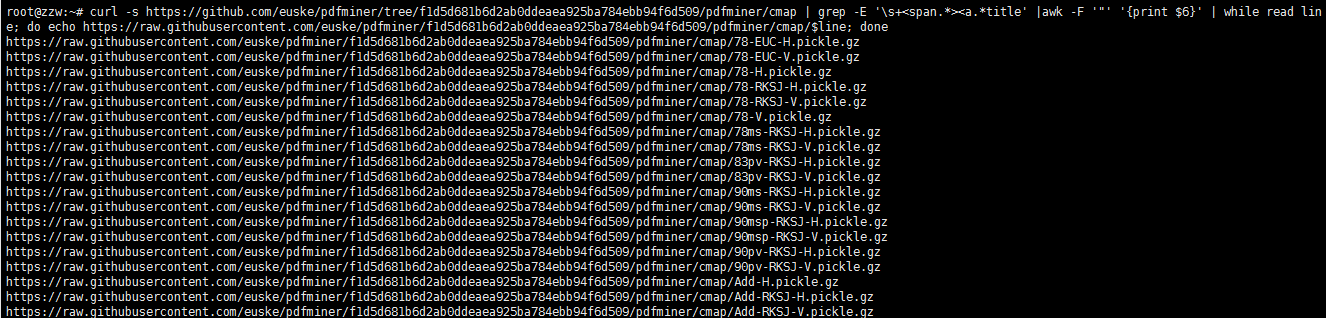
5.开始命令行构造下载地址
curl -s https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap \
|grep -E '\s+<span.*><a.*title'|awk -F '"' '{print $6}'|while read line; do echo \
"https://raw.githubusercontent.com/euske/pdfminer/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/$line"; done
6.升级-->构造及文件下载脚本
# !/usr/bin/bash
# 参数校验
folder=$1
# 参数为空判断
[ -z $folder ] && folder="downfiles"
# 为文件且存在判断,不能重名
if [ -f $folder ]
then
echo "Error: 【$folder】 already exist! and it's file"
exit
fi
# 不存在则创建
if [ ! -e $folder ]
then
mkdir $folder
fi
echo ""
echo "文件保存路径为: $PWD/$folder"
echo ""
# github 主页列表显示地址
listPage="https://github.com/euske/pdfminer/tree/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap"
# github 详情显示地址
# https://github.com/euske/pdfminer/blob/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/
# github 下载按钮地址
# https://github.com/euske/pdfminer/raw/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/
# 真实下载地址
base="https://raw.githubusercontent.com/euske/pdfminer/f1d5d681b6d2ab0ddeaea925ba784ebb94f6d509/pdfminer/cmap/"
# 模拟浏览器
userAgent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
files=`curl -s -A "${userAgent}" $listPage | grep -E '\s+<span.*><a.*title' | awk -F '"' '{print $6}'`
if [ -z "$files" ]
then
echo "获取列表信息失败!!!"
exit
else
num=`echo $files| awk 'BEGIN{RS=" "}END{print NR}'`
echo "成功获取列表信息, 总共 $num"
fi
echo ""
for name in $files
do
# infos="curl -s -A \"${userAgent}\" -w %{http_code} \"$base$name\" -o $folder/$name"
sleep 1
res=`curl -s -A "${userAgent}" -w %{http_code} "$base$name" -o $folder/$name`
if [ "$res" = "200" ]
then
echo "SUCCESS: 【$name】 下载成功"
else
# echo $infos
echo "ERROR: 【$name】 下载失败--$res"
sleep 0.5
fi
done
五、后续
文件下载失败返回码为 000 ----待分析解决
记一次为解决Python读取PDF文件的Shell操作的更多相关文章
- python读取pdf文件
pdfplumber简介 Pdfplumber是一个可以处理pdf格式信息的库.可以查找关于每个文本字符.矩阵.和行的详细信息,也可以对表格进行提取并进行可视化调试. 文档参考https://gith ...
- Python读取mdb文件以及shell检测
最近写了两个python的脚本不过实际意义不是很大,就是想练练python写程序,一直研究web方面脚本写的少多了,还有C语言也用的少多了.现在有时间得多写写程序,别把以前学到的知识给忘了. 作者: ...
- Python读取PDF内容
1,引言 晚上翻看<Python网络数据采集>这本书,看到读取PDF内容的代码,想起来前几天集搜客刚刚发布了一个抓取网页pdf内容的抓取规则,这个规则能够把pdf内容当成html来做网页抓 ...
- 解决 python 读取文件乱码问题(UnicodeDecodeError)
解决 python 读取文件乱码问题(UnicodeDecodeError) 确定你的文件的编码,下面的代码将以'utf-8'为例,否则会忽略编码错误导致输出乱码 解决方案一 with open(r' ...
- 深入学习python解析并读取PDF文件内容的方法
这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应 ...
- Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal multibyte sequence
Python读取CSV文件,报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa7 in position 727: illegal mul ...
- PHP 与Python 读取大文件的区别
php读取大文件的方法 <?php function readFile($file) { # 打开文件 $handle = fopen($file, 'rb'); while (feof($ ...
- Python绘制PDF文件~超简单的小程序
Python绘制PDF文件 项目简介 这次项目很简单,本次项目课,代码不超过40行,主要是使用 urllib和reportlab模块,来生成一个pdf文件. reportlab官方文档 http:// ...
- Python读取txt文件
Python读取txt文件,有两种方式: (1)逐行读取 data=open("data.txt") line=data.readline() while line: print ...
随机推荐
- Python常用三方库安装
//首先更新pip python -m pip install --upgrade pip //一个类似Matlab的Plot绘制数据图的库. python -m pip install matplo ...
- Mate Translate的特色功能phrasebook 常用语手册介绍
Mate Translate是Mac os系统上一款多国语言即时翻译工具,支持103种语言之间的即时互译,还可以在你的所有设备之间轻松同步.Mate Translate 不但推出了适应各个平台使用的客 ...
- 【JZOJ6433】【luoguP5664】【CSP-S2019】Emiya 家今天的饭
description analysis 首先可以知道不符合要求的食材仅有一个,于是可以容斥拿总方案数减去选不合法食材的不合法方案数 枚举选取哪一个不合法食材,设\(f[i][j]\)表示到第\(i\ ...
- 【转】 MySQL主从(Master-Slave)复制
首先声明:此文是在失去U盘极度郁闷的时候写的,有些零散,估计也有错误.欢迎大家指出 MYSQL服务器复制配置 这是根据我之前看的MYSQL复制的文档然后自己亲自实验的过程.配置的功能比较简单. 环 ...
- 【LeetCode 27】移除元素
题目链接 [题解] 沙比提 [代码] class Solution { public: int removeElement(vector<int>& nums, int val) ...
- Python每日一题 002
做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)? 在此生成由数字,字母组成的20位字 ...
- spring 对JDBC的支持 (8)
目录 一.jdbc的简介 二.jdbcTemplate 的使用 2.1 maven 引入spring - jdbc ,c3p0 ,数据库mysql驱动 2.2 配置 数据源以及jdbcTemplate ...
- CSS:CSS 组合选择符
ylbtech-CSS:CSS 组合选择符 1.返回顶部 1. CSS 组合选择符 CSS 组合选择符 组合选择符说明了两个选择器直接的关系. CSS组合选择符包括各种简单选择符的组合方式. 在 CS ...
- Dubbo入门到精通学习笔记(十六):Keepalived+Nginx实现高可用Web负载均衡
文章目录 Keepalived+Nginx实现高可用Web负载均衡 Keepalived+Nginx实现高可用Web负载均衡 高可用架构篇 Keepalived + Nginx 实现高可用 Web 负 ...
- git分布式版本控制系统权威指南学习笔记(三):简单了解git对象、head以及sha1sum
文章目录 git对象(简单了解) 对象是存在哪里的? head和master分支 上面的hash值怎么来的? git对象(简单了解) 每次提交都有tree.parent.author.committe ...