深度探索C++对象模型之第三章:数据语义学
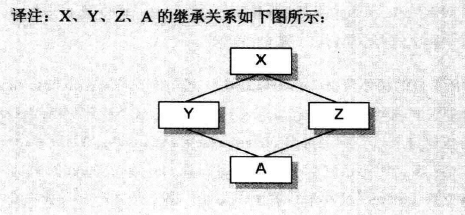
如下三个类:
class X { };
class Y :public virtual X { };
class Z : public virtual X {};
class A :public Y,public Z {};
一、编译器优化之前的大小:
上述四个类在优化之前的大小分别是:1、8、8 、12
类X明明没有任何成员为什么大小是1byte呢?因为那是编译器插入的一个char,这使得这一class的两个object在内存中有独一无二的地址。
Y和Z的大小都是8,这受到了机器和编译器共同的影响。即以下三个因素:
- 语言本身造成的负担(overhead) 当C++支持virtual base classes时,就会导致一些额外负担。在derived class中,这个负担会反映成一个指针,它要么指向virtual base class subobject或者指向一个相关table:表格中存放的不是virtual base class subobject的地址,就是其偏移位置。
- 编译器对特殊情况所提供的优化处理。virtual base class X subobject的1bytes大小也出现在Y和Z上。传统上它们被放在derived class的固定部分的尾端。
- Alignment的限制(将数值调整到某数的整数倍)
以下是X Y Z A的对象布局:
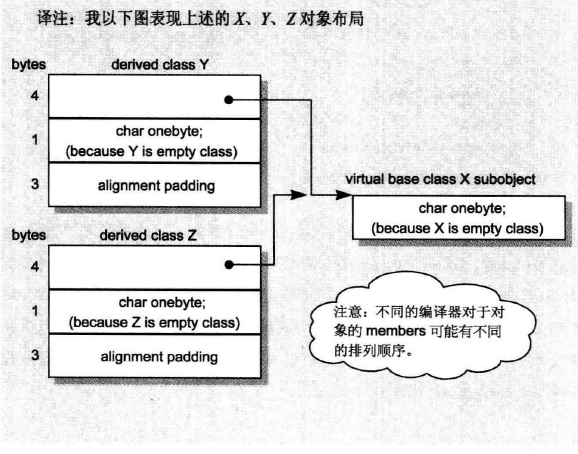
来看下类A的大小:一个virtual base class subobject只会在derived class存在一份实例,不管它在class继承体系中出现了多少次:
- 被大家共享的一个X实例,大小是1byte
- Base class Y的大小,是4Bytes。Base class Z也是一样。
- class A自己的大小是:0 bytes
- alignment 将9bytes调整到12bytes
每个类的大小会增加,由以下两个因素决定:
- 编译器自动加上额外的data members,用以支持某些语言特性(主要是virtual特性)
- alignment(边界调整)的需要
二、编译器优化之后的大小:
对于Empty virtual base class (X ),它没有定义任何数据。某些编译器对它提供了特殊处理,处理之后,empty virtual base class变成了derived class object最开头的一部分(既然有了members,就不需要原本为了empyt安插的一个char).
如果编译器进行优化处理(将empty virtual base class X)的那1byte拿掉,类A只剩下8bytes。
所以优化后的模型大小分别是:1/4/4/8
三、类的data member;
一个class的data members,可以表现这个class在执行程序时的某种状态。Nonstatic data member放置的是“个别class object”感兴趣的数据,static data members则是放置的整个“class”感兴趣的事情。
C++将nonstatic data members数据直接放在每一个class object中。对于继承而来的nonstatic data members也是如此,但是并没强制定义其间的排序顺序。而static data member永远只存在一份实例(即使class没有任何object实例),它被存放于程序的一个global data segment中。但是一个template class的static data members行为稍有不同。
四、data member的绑定:
我们知道编译器先对整个类的声明进行编译,在进行名字查找时,总是先查找类内的名字,所以当类外和类内使用相同名字的变量时,总是会屏蔽掉类外的那一个,如果我们真的想使用类外的那一个,就使用作用域运算符::。
但是这种情况对于argument list并不为真, 对于这种情况,应该将nested type声明放置于class的起始处。
五、data member的布局:

如上所述的一个类,其Nonstatic data members在class object中的排列顺序将和其声明的顺序一样。任何static data member都不会放入对象布局之中,它们被放在data segment中。members的排列在class object中有较高的地址(C++ Standard)各个members之间并不一定需要连续,比如members的alignment也会填补一些bytes,所以C++标准对数据成员的布局还是相对开放的。
除了上述members以外,编译器还会合成一些members比如vptr,vptr的位置也是随意,不过最好还是放在开头或结尾部分、
另外access sections(public/private/protected)的多寡,不会影响class object的大小和组成(暂时认为是同一个access section的多少:比如private)
六、Data的存取
Point3d origin;
Point3d origin , *pt = &origin
对于static data member,它被视为一个global变量(但是只在class的生命范围之内可见)。classd的存取、关联都不会影响static data member。
并且static data member有且只有一个实例,存放在data segment中。
比如如下操作:
origin.chunkSize = ;
pt->chunkSize =;
C++通过指针和一个对象来存取member,结论是一样的。其实member并不在class object之中,因此存取static member并不需要class object.即使chunkSize是经过复杂关系继承而来,那也不会影响,static members还是只有一个实例,且存取路径仍然是那么直接。
若取一个static data member的地址,会得到一个指向其数据类型的指针,而不是一个指向其class member的指针,因为static member并不包含在class object之中。
&Point3d::chunkSize;
//会得到如下结果:
const int*
如果两个class中都声明了static data member,放心啦~编译器会自动对它们进行编码的,咱们不用操心。
对于Nonstatic data members,它们直接存放在每个class object中,除非经过explicit或implicit的class object,否则没有办法直接存取它们。只有程序员在member function中直接处理一个nonstatic data member,那么implicit class object就会发生。如下所示:
Point3d Point3d::translate(const Point3d*pt){
x+= pt.x;
y+= pt.y;
z+= py.z;
};
//表面看到的对x/y/z的直接存取,实际上是通过implicit class object (this指针表达)完成的
//成员函数的内部转换如下:
Point3d Point3d::translate(Point3d *const this,const Point3d &pt){
this->x += pt.x;
this->y += pt.y;
this->z += pt.z;
};
若是对一个nonstatic data member进行存取操作,则是通过class object的起始地址加上data member的偏移位置(offset).
origin._y = 0.0;
//则地址&origin._y是如下:
&origin + (&Point3d::_y - );
上述-1操作是指向data member的指针,其offset总是被加上1,用于区分指向data member和class的第一个data member的情况。每个nonstatic data members的偏移位置在编译时期就可以知道。
origin._x = 0.0;
pt-> _x = 0.0;
上述代码的区别在于当Point3d是一个derived class,且其继承结构中有一个virtual base class,并且被存取的member是从virtual base class继承而来的,那么此时我们就不能说pt具体是指向的哪一种类型,所以我们也就不知道这个offset的真正位置,这个存取操作必须必须延迟到执行时期,经过一个额外的间接导引,才能实现。但是如果使用第一种方式,其类型无疑是Point3d,即使它继承自virtual base class,所以_x的offset在编译时期也就能够确定下来。
七、继承的数据成员布局:
对于derived class和base class的排列顺序,一般编译器总是让base class先出现,但是属于virtual base class的除外。任何一条通则遇到virtual base class都会失效.
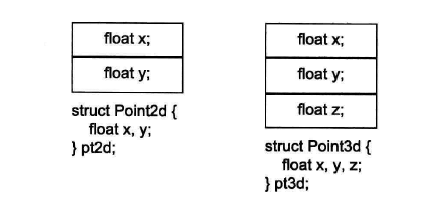
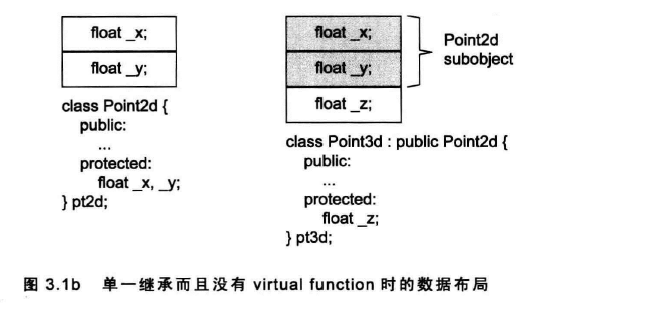
class Point2d{
public:
private:
float x,y;
};
class Point3d{
public:
private:
float x,y,z;
};
1.无virtual function的对象布局图:
2.单一继承无虚函数:
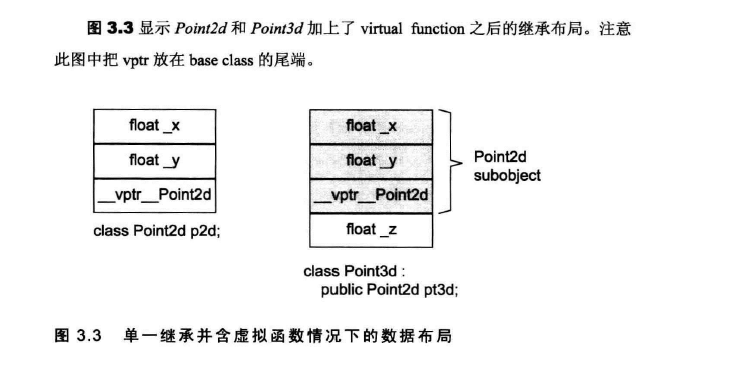
3.单一继承有虚函数:
当加入虚函数之后,势必会对Point2d class带来空间和存取时间上的额外负担:
- 导入一个和Point2d有关的virtual table,用于存放每个virtual function的地址。table的元素数 =虚函数个数 + 一个或两个slots(用于RTTI)
- 在每个class object中,导入一个vptr,用于提供执行期的链接,使每个object都能够找到相应的virtual table.
- 增强constructor,使它能够为vptr设定初值,让它指向class所对应的virtual table。
- 增强destructor,使它能够抹消vptr。
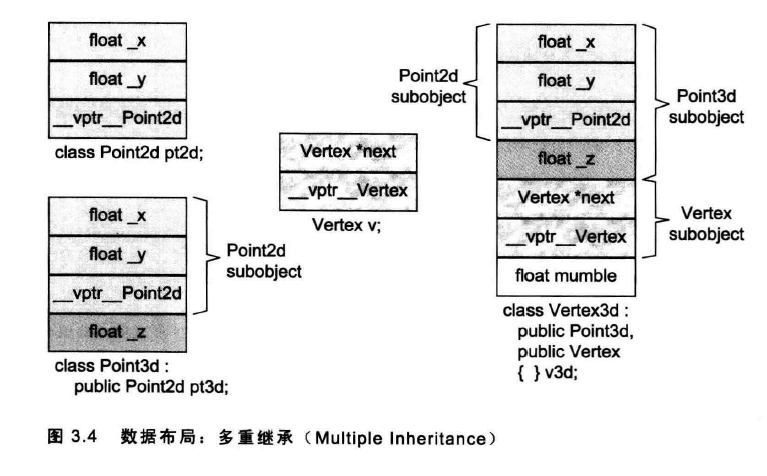
4.多重继承:
例如如下多重继承机制:
多重继承的问题主要发生在derived class objects和其第二或后继的base class objects之间的转换:对一个多重派生对象,将其地址指定给最左端(第一个)base class的指针,情况和单一继承相同,因为二者具有相同的起始地址。至于第二个或后继的base class则需要,对地址进行修改。
Vertex3d v3d;
Vertex *pv;
Point2d *p2d;
Pint3d *p3d; pv = &v3d; //这是将一个派生类赋给第二个base class //则需要这样的内部转换
pv = (Vertex*)(((char*)&v3d) + sizeof(Point3d));//要找到v3d显示转换为Vertex大小,然后再加上(Point3d)的地址长度。
4.虚拟继承:
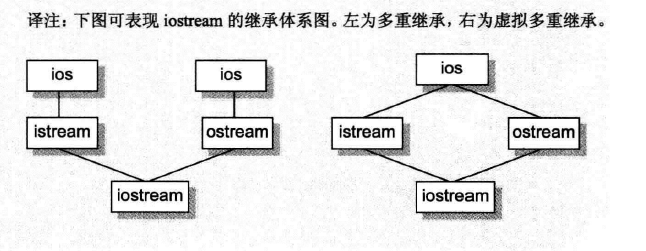
要找到一个办法将istream和ostream各自维护的一个ios subobject,折叠成一个由iostream维护的单一 ios subobject,并且可以保存base class 和derived class的指针(以及reference)之间的多态指定操作。
方法如下:
如果类中含有一个或多个virtual base class subobjects,像istream一样,那么这个class将被分割为两部分:一个不变区域和一个共享区域。
- 不变区域中的数据不管后继如何衍化,总有固定的offset(从object的开头算起),所以这一部分数据可以被直接存取。
- 共享区域中的数据(virtual base class subobject)其位置会因为每次的派生操作而有所变化,所以它们只能被间接存取。
其中不同编译器之间的差距就在于,间接存取的方式,例如如下继承体系:
一般布局策略是先安排好derived class中的派上部分,然后再建立其共享部分。如何存取class的共享部分呢?cfront编译器会在每一个derived class object中安插一些指针,每个指针指向virtual base class。要存取继承得来的virtual base class members,通过相关指针间接完成。
例如如下代码:
void Point3d:: operator +=(const Point3d &rhs){
_x += rhs._x;
_y += rhs._y;
_z += rhs._z;
};
//在cfront的策略之下,运算符会被内部转换为:
_vbcPoint2d->_x +=rhs._vbcPoint2d->_x; //_vpcPoint2d是那个derived class的指向virtual base class
_vbcPoint2d->_y +=rhs._vbcPoint2d->_y;
_z += rhs._z;
同时derived class到base class的之间的转换:
Point2d *p2d = pv3d;
//在c++模型之下变成
Point2d *p2d = pv3d ? pv3d->_vbcPoint2d :
上述模型缺点:
- 每个对象必须对其每个virtual base class背负一个额外的指针,导致其负担因virtual base classes的个数而变化。
- 若虚拟继承串链加长,导致间接存取层次增加,如果我有三层虚拟派生,我就需要三次间接存取(经过三个virtual base class的指针),但是我希望的是有固定的存取时间。
解决第二个问题:由拷贝操作取得所有的nested virtual base class的指针,放到derived class object中,虽然空间上付出了一些代价,但是解决了固定存取时间的问题:如下所示:
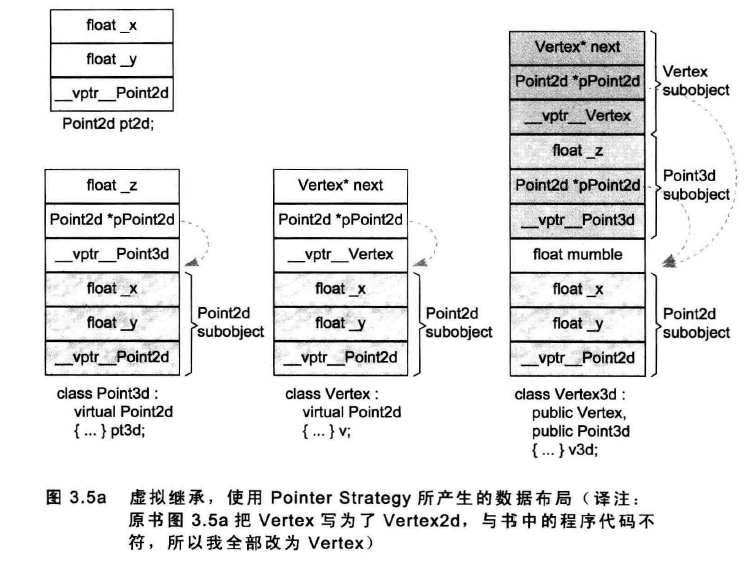
解决第一个问题:引入所谓的virtual base class table.每个class object如果有一个或多个virtual base classes,就会由编译器安插一个指针,指向virtual base class table,这里面放的是真正的virtual base class 指针。
通常,virtual base class最有效的运用方式是:一个抽象的Virtual base class,没有任何data members.
八、对象成员的效率
1.封装和inline测试:
- 如果把编译器的优化打开,“封装和inline”就不会带来执行期的效率成本。
- 如果没有把优化开关打开,就很难猜测到一个程序的效率表现。
2.继承测试:
- 单一继承并不会影响效率,因为members被连续存储在derived class object中,并且它的offset在编译时期就已经知道了。这个结果在多重继承下应该也是一样的。
- 虚拟继承的效率令人失望,间接存取操作压抑了“把所有运算都移往寄存器的优化能力”,但是间接性并不会严重影响非优化程序的执行效率。
九、指向数据成员的指针
如下述代码:
class Point3d{
public:
virtual ~Point3d();
protected:
static Point3d origin;
float x,y,z;
};
static成员放在class object之外,x/y/z按照声明顺序进行排列。vptr不是放在开头就是结尾。
先假设将vptr放在尾端:则x y z在对象布局中offset分别是0 4 8,但是传回的是1 5 9 ?问题在于如何区分一个“没有指向任何data member的指针”和一个指向“第一个data member”的指针:
考虑如下例子:
float Point3d::*p1 = ;
float Point3d::*p2 = &Point3d::x;
//Point3d::*的意思是指向“Point3d data member”的指针类型
很明显p1是一个没有指向任何data member的指针,而p2是指向第一个data member的指针。
为了区分p1和p2,每一个真正的data member offset的值都应该被加上1.因此当我们在真正使用该值以指出一个member之前,请先减掉1.
接下里看一下,取一个nonstatic data member的地址和取一个绑定到真正class object上的data member的地址,有什么不同?
& Point3d::z;
& origin.z;
第一种将会得到它在class中的offset,即float Point3d::*,而第二行将会得到该member在内存中的真正地址float*。
十、指向members的指针的效率问题:
为每个成员存取操作加上一层间接性,会使得执行时间多出一倍不止。以指向member的指针来存取数据,再一次几乎用掉了双倍时间。而优化使得三种存取策略表现一致。
由于被继承的data members是直接存放在在class object中的,所以继承的引入并没有影响这些代码的效率。
深度探索C++对象模型之第三章:数据语义学的更多相关文章
- 深度探索C++对象模型之第四章:函数语义学
C++有三种类型的成员函数:1.static/nonstatic/virtual 一.成员的各种调用方式 C with Classes 只支持非静态成员函数(Nonstatic Member Func ...
- 【C++对象模型】第三章 Data语义学
1. Data Member 的布局 同一个Access Section(private, public等)中,data member的顺序按照声明顺序排列,但是没有规定需要连续排序.同时编译器可能会 ...
- 拾遗与填坑《深度探索C++对象模型》3.2节
<深度探索C++对象模型>是一本好书,该书作者也是<C++ Primer>的作者,一位绝对的C++大师.诚然该书中也有多多少少的错误一直为人所诟病,但这仍然不妨碍称其为一本好书 ...
- 《深度探索C++对象模型》读书笔记(一)
前言 今年中下旬就要找工作了,我计划从现在就开始准备一些面试中会问到的基础知识,包括C++.操作系统.计算机网络.算法和数据结构等.C++就先从这本<深度探索C++对象模型>开始.不同于& ...
- 拾遗与填坑《深度探索C++对象模型》3.3节
<深度探索C++对象模型>是一本好书,该书作者也是<C++ Primer>的作者,一位绝对的C++大师.诚然该书中也有多多少少的错误一直为人所诟病,但这仍然不妨碍称其为一本好书 ...
- 深度探索C++对象模型
深度探索C++对象模型 什么是C++对象模型: 语言中直接支持面向对象程序设计的部分. 对于各个支持的底层实现机制. 抽象性与实际性之间找出平衡点, 需要知识, 经验以及许多思考. 导读 这本书是C+ ...
- c++学习书籍推荐《深度探索C++对象模型》下载
百度云及其他网盘下载地址:点我 百度云及其他网盘下载地址:点我 编辑推荐 如果你是一位C++程序员,渴望对于底层知识获得一个完整的了解,那么这本<深度探索C++对象模型>正适合你 作者简介 ...
- 读书笔记《深度探索c++对象模型》 概述
<深度探索c++对象模型>这本书是我工作一段时间后想更深入了解C++的底层实现知识,如内存布局.模型.内存大小.继承.虚函数表等而阅读的:此外在很多面试或者工作中,对底层的知识的足够了解也 ...
- 柔性数组-读《深度探索C++对象模型》有感 (转载)
最近在看<深度探索C++对象模型>,对于Struct的用法中,发现有一些地方值得我们借鉴的地方,特此和大家分享一下,此间内容包含了网上搜集的一些资料,同时感谢提供这些信息的作者. 原文如下 ...
随机推荐
- oracle锁表和解锁
1.查看锁表清空 select * from v$session t1, v$locked_object t2 where t1.sid = t2.SESSION_ID; alter system k ...
- ASE团队项目alpha阶段Frontend组 scrum2 记录
ASE团队项目alpha阶段Frontend组 scrum2 记录 本次会议于11.5日, 11:30在微软北京西二楼13158研讨室,讨论持续15分钟 与会人员:Jingyi Xie, Jiaqi ...
- DQN的第一次尝试 -- 软工结对编程第一次作业
DQN的第一次尝试 在本篇博客中将为大家形象地介绍一下我对DQN的理解,以及我和我的队友如何利用DQN进行黄金点游戏.最后我会总结一下基于我在游戏中看到的结果,得到的dqn使用的注意事项和这次游戏中我 ...
- junit单元测试报错Failed to load ApplicationContext,但是项目发布到tomcat浏览器访问没问题
junit单元测试报错Failed to load ApplicationContext,但是项目发布到tomcat浏览器访问没问题,说明代码是没问题的,配置也没问题.开始时怀疑是我使用junit版本 ...
- 每天一个Linux常用命令 ls命令
ls:列出目录中的内容 -l 显示详细信息 -a 显示所有文件,包括隐藏文件 -i 显示inode -t :依时间排序,而不是用档名. -r :将排序结果反向输出,例如:原本档名由小到大,反向则为 ...
- Linux (ifconfig/docker) 移除网桥/虚拟网卡
今天上大数据实践课时,使用学校提供的云主机平台创建了几台vps,但是安全组配置好之后发现无法用ssh无法登录,ping也不通,提示网络无法到达. 但是拿别人的电脑试了下能顺利使用ssh连接. 有人说是 ...
- Hession实现远程通讯(基于Binary-RPC协议)
一.开发工具 1.jdk1.6 64位 百度网盘地址:https://pan.baidu.com/s/1Zwqfmi20X4ANNswZzPMzXQ 提取码:k50r 2.apache-maven-3 ...
- Vuex的管理员Module(实战篇)
Module按照官方来的话,对于新手可能有点难以接受,所以想了下,决定干脆多花点时间,用一个简单的例子来讲解,顺便也复习一下之前的知识点. 首先还是得先了解下 Module 的背景.我们知道,Vuex ...
- java中的final关键字的用法
一. 什么是final关键字? final在Java中是一个保留的关键字,可以声明成员变量.方法.类以及本地变量.一旦你将引用声明作final,你将不能改变这个引用了,编译器会检查代码,如果你试图将变 ...
- 【leetcode】388. Longest Absolute File Path
题目如下: Suppose we abstract our file system by a string in the following manner: The string "dir\ ...