Spark学习之路 (十七)Spark分区[转]
分区的概念
分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个数,也是由RDD(准确来说是作业最后一个RDD)的分区数决定。
为什么要进行分区
数据分区,在分布式集群里,网络通信的代价很大,减少网络传输可以极大提升性能。mapreduce框架的性能开支主要在io和网络传输,io因为要大量读写文件,它是不可避免的,但是网络传输是可以避免的,把大文件压缩变小文件, 从而减少网络传输,但是增加了cpu的计算负载。
Spark里面io也是不可避免的,但是网络传输spark里面进行了优化:
Spark把rdd进行分区(分片),放在集群上并行计算。同一个rdd分片100个,10个节点,平均一个节点10个分区,当进行sum型的计算的时候,先进行每个分区的sum,然后把sum值shuffle传输到主程序进行全局sum,所以进行sum型计算对网络传输非常小。但对于进行join型的计算的时候,需要把数据本身进行shuffle,网络开销很大。
spark是如何优化这个问题的呢?
Spark把key-value rdd通过key的hashcode进行分区,而且保证相同的key存储在同一个节点上,这样对改rdd进行key聚合时,就不需要shuffle过程,我们进行mapreduce计算的时候为什么要进行shuffle?,就是说mapreduce里面网络传输主要在shuffle阶段,shuffle的根本原因是相同的key存在不同的节点上,按key进行聚合的时候不得不进行shuffle。shuffle是非常影响网络的,它要把所有的数据混在一起走网络,然后它才能把相同的key走到一起。要进行shuffle是存储决定的。
Spark从这个教训中得到启发,spark会把key进行分区,也就是key的hashcode进行分区,相同的key,hashcode肯定是一样的,所以它进行分区的时候100t的数据分成10分,每部分10个t,它能确保相同的key肯定在一个分区里面,而且它能保证存储的时候相同的key能够存在同一个节点上。比如一个rdd分成了100份,集群有10个节点,所以每个节点存10份,每一分称为每个分区,spark能保证相同的key存在同一个节点上,实际上相同的key存在同一个分区。
key的分布不均决定了有的分区大有的分区小。没法分区保证完全相等,但它会保证在一个接近的范围。所以mapreduce里面做的某些工作里边,spark就不需要shuffle了,spark解决网络传输这块的根本原理就是这个。
进行join的时候是两个表,不可能把两个表都分区好,通常情况下是把用的频繁的大表事先进行分区,小表进行关联它的时候小表进行shuffle过程。
大表不需要shuffle。
需要在工作节点间进行数据混洗的转换极大地受益于分区。这样的转换是 cogroup,groupWith,join,leftOuterJoin,rightOuterJoin,groupByKey,reduceByKey,combineByKey 和lookup。
分区是可配置的,只要RDD是基于键值对的即可。
Spark分区原则及方法
RDD分区的一个分区原则:尽可能是得分区的个数等于集群核心数目
无论是本地模式、Standalone模式、YARN模式或Mesos模式,我们都可以通过spark.default.parallelism来配置其默认分区个数,若没有设置该值,则根据不同的集群环境确定该值
本地模式
默认方式
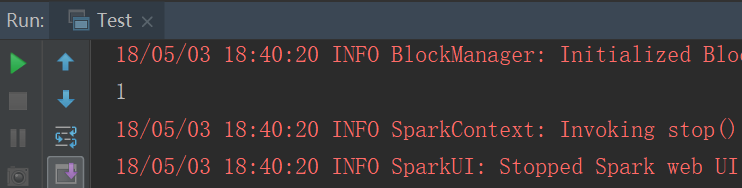
以下这种默认方式就一个分区

结果
手动设置
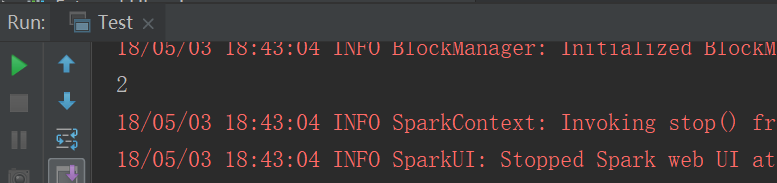
设置了几个分区就是几个分区

结果
跟local[n] 有关
n等于几默认就是几个分区
如果n=* 那么分区个数就等于cpu core的个数
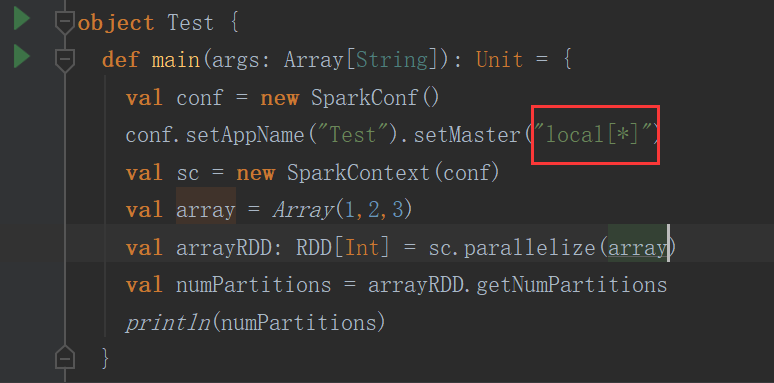
结果

参数控制
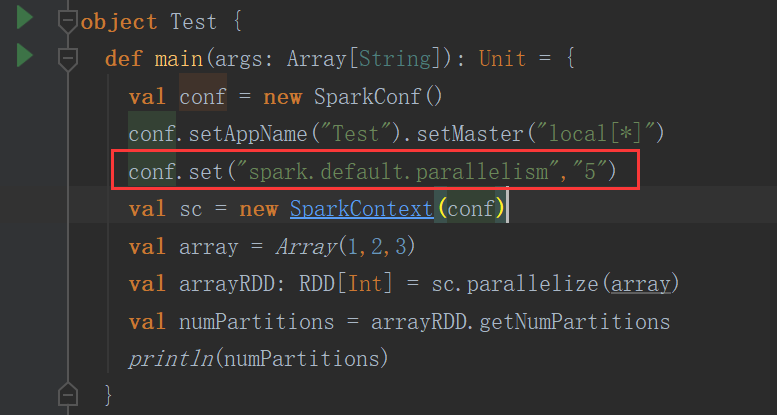
结果
YARN模式

进入defaultParallelism方法

继续进入defaultParallelism方法

这个一个trait,其实现类是(Ctrl+h)
进入TaskSchedulerImpl类找到defaultParallelism方法

继续进入defaultParallelism方法,又是一个trait,看其实现类
Ctrl+h看SchedulerBackend类的实现类
进入CoarseGrainedSchedulerBackend找到defaultParallelism

totalCoreCount.get()是所有executor使用的core总数,和2比较去较大值
如果正常的情况下,那你设置了多少就是多少
分区器
(1)如果是从HDFS里面读取出来的数据,不需要分区器。因为HDFS本来就分好区了。
分区数我们是可以控制的,但是没必要有分区器。
(2)非key-value RDD分区,没必要设置分区器
al testRDD = sc.textFile("C:\\Users\\Administrator\\IdeaProjects\\myspark\\src\\main\\hello.txt")
.flatMap(line => line.split(","))
.map(word => (word, 1)).partitionBy(new HashPartitioner(2))没必要设置,但是非要设置也行。
(3)Key-value形式的时候,我们就有必要了。
HashPartitioner
val resultRDD = testRDD.reduceByKey(new HashPartitioner(2),(x:Int,y:Int) => x+ y)
//如果不设置默认也是HashPartitoiner,分区数跟spark.default.parallelism一样
println(resultRDD.partitioner)
println("resultRDD"+resultRDD.getNumPartitions)RangePartitioner
val resultRDD = testRDD.reduceByKey((x:Int,y:Int) => x+ y)
val newresultRDD=resultRDD.partitionBy(new RangePartitioner[String,Int](3,resultRDD))
println(newresultRDD.partitioner)
println("newresultRDD"+newresultRDD.getNumPartitions)注:按照范围进行分区的,如果是字符串,那么就按字典顺序的范围划分。如果是数字,就按数据自的范围划分。
自定义分区
需要实现2个方法
class MyPartitoiner(val numParts:Int) extends Partitioner{
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
val domain = new URL(key.toString).getHost
val code = (domain.hashCode % numParts)
if (code < 0) {
code + numParts
} else {
code
}
}
}
object DomainNamePartitioner {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("word count").setMaster("local")
val sc = new SparkContext(conf)
val urlRDD = sc.makeRDD(Seq(("http://baidu.com/test", 2),
("http://baidu.com/index", 2), ("http://ali.com", 3), ("http://baidu.com/tmmmm", 4),
("http://baidu.com/test", 4)))
//Array[Array[(String, Int)]]
// = Array(Array(),
// Array((http://baidu.com/index,2), (http://baidu.com/tmmmm,4),
// (http://baidu.com/test,4), (http://baidu.com/test,2), (http://ali.com,3)))
val hashPartitionedRDD = urlRDD.partitionBy(new HashPartitioner(2))
hashPartitionedRDD.glom().collect()
//使用spark-shell --jar的方式将这个partitioner所在的jar包引进去,然后测试下面的代码
// spark-shell --master spark://master:7077 --jars spark-rdd-1.0-SNAPSHOT.jar
val partitionedRDD = urlRDD.partitionBy(new MyPartitoiner(2))
val array = partitionedRDD.glom().collect()
}
}Spark学习之路 (十七)Spark分区[转]的更多相关文章
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习之路 (二十三)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
- Spark学习之路 (三)Spark之RDD
一.RDD的概述 1.1 什么是RDD? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark学习之路(十六)—— Spark Streaming 整合 Kafka
一.版本说明 Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: s ...
- Spark学习之路(十四)—— Spark Streaming 基本操作
一.案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计.项目依赖和代码实现如下: <dependency> <groupId>org.apac ...
- Spark学习之路(十一)—— Spark SQL 聚合函数 Aggregations
一.简单聚合 1.1 数据准备 // 需要导入spark sql内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSess ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
随机推荐
- CenOS安装MySQL服务
说明:本教程是CenOS安装MySQL服务. 0. 预备知识: 什么是rpm RMP 是 LINUX 下的一种软件的可执行程序,你只要安装它就可以了.这种软件安装包通常是一个RPM包(Redha ...
- 一份中规中矩的 iOS笔试题
一.背景 因为一些原因,我从公司离职,在此之前,我需要帮忙招聘一个新人来做我的工作,于是就有了这篇文章. 由于公司项目16年就已经上线了,前同事写的项目中,有用xib.storyBoard.代码自动布 ...
- Ceph 存储集群3-部署:
ceph-deploy 工具是一种部署 Ceph 的方法,它只依赖到服务器的 SSH 访问. sudo 和 Python .它可在你的工作站上运行,不需要服务器.数据库.或其它工具.如果你安装.拆卸过 ...
- OpenCV3入门(五)图像的阈值
1.图像阈值与二值化 阈值是一种简单的图像分割方法,一幅图像包括目标物体(前景).背景还有噪声,要想从数字图像中直接提取出目标物体,可以设定一个像素值即阈值,然后用图像的每一个像素点和阈值做比较,给出 ...
- tmobst2an
(单选题)与下面代码效果相同的HQL 语句是( ). Criteria criteria = session.createCriteria(User.class); criteria.add(Rest ...
- CSS3 animation属性中的steps实现GIF动图(逐帧动画)
相信 animation 大家都用过很多,知道是 CSS3做动画用的.而我自己就只会在 X/Y轴 上做位移旋转,使用 animation-timing-function 规定动画的速度曲线,常用到的 ...
- Codeforces_821
A.直接判断每一个数. #include<bits/stdc++.h> using namespace std; ][]; int main() { ios::sync_with_stdi ...
- [python]locals内置函数
locals() Update and return a dictionary representing the current local symbol table. Free variables ...
- 51Nod 1021 石子归并(区间dp经典入门)
题意: N堆石子摆成一条线.现要将石子有次序地合并成一堆.规定每次只能选相邻的2堆石子合并成新的一堆,并将新的一堆石子数记为该次合并的代价.计算将N堆石子合并成一堆的最小代价. n<=100 思 ...
- win10系统安装VMware虚拟机软件以及linux系统
一.安装VMware 1.在VMware官网下载VMware Workstation Pro 15.5.1 下载地址:https://my.vmware.com/cn/web/vmware/detai ...