pandas时间序列学习笔记
- 创建一个时间序列
- asfred()
- shifted(),滞后函数
- diff()求差分
- DataFrame.reindex()
- 通过data_range指定时间序列的起止时间
- 通过as.fred()指定时间序列的间隔
- interpolate()
- resample()
- 补充一个绘图的参数
- pct_change()
- rolling window functions.
- rolling()
- join()
- quantile()
- pandas 中统计累计次数
- 一个案例学习
- seed()
- random walk
- choice()
- Relationships between time series: correlation
- heatmap()
- Select index components & import data
- groupby()
- 最后一行or一列的表示方法
- sort_values
- plotz中的参数kind
- to_excel()
创建一个时间序列
pd.date_range()
这个函数是手动设置时间的范围,参数periods是设置时间间隔的
# Create the range of dates hereseven_days = pd.date_range('2017-1-1', periods=7)# Iterate over the dates and print the number and name of the weekdayfor day in seven_days:print(day.dayofweek, day.weekday_name)<script.py> output:6 Sunday0 Monday1 Tuesday2 Wednesday3 Thursday4 Friday5 Saturday
info()
查看数据索引和内存信息的
data = pd.read_csv('nyc.csv')# Inspect dataprint(data.info())# Convert the date column to datetime64data.date = pd.to_datetime(data.date)# Set date column as indexdata.set_index('date', inplace=True)# Inspect dataprint(data.info())# Plot datadata.plot(subplots=True)plt.show()<script.py> output:<class 'pandas.core.frame.DataFrame'>RangeIndex: 6317 entries, 0 to 6316Data columns (total 4 columns):date 6317 non-null objectozone 6317 non-null float64pm25 6317 non-null float64co 6317 non-null float64dtypes: float64(3), object(1)memory usage: 197.5+ KBNone<class 'pandas.core.frame.DataFrame'>DatetimeIndex: 6317 entries, 1999-07-01 to 2017-03-31Data columns (total 3 columns):ozone 6317 non-null float64pm25 6317 non-null float64co 6317 non-null float64dtypes: float64(3)memory usage: 197.4 KBNone
# Create dataframe prices hereprices = pd.DataFrame()# Select data for each year and concatenate with prices herefor year in ['2013', '2014', '2015']:price_per_year = yahoo.loc[year, ['price']].reset_index(drop=True)price_per_year.rename(columns={'price': year}, inplace=True)prices = pd.concat([prices, price_per_year], axis=1)# Plot pricesprices.plot()plt.show()
asfred()
给已经存在的时间序列调整时间间隔
# Inspect dataprint(co.info())# Set the frequency to calendar dailyco = co.asfreq('D')# Plot the dataco.plot(subplots=True)plt.show()# Set frequency to monthlyco = co.asfreq('M')# Plot the dataco.plot(subplots=True)plt.show()
shifted(),滞后函数
等价于r里面的lag()
peroid参数指定滞后阶数
\(x_t\)/\(x_{t-1}\)
diff()求差分
\(x_t\)-\(x_{t-1}\)
# Import data heregoogle = pd.read_csv('google.csv', parse_dates=['Date'], index_col='Date')# Set data frequency to business dailygoogle = google.asfreq('B')# Create 'lagged' and 'shifted'google['lagged'] = google.Close.shift(periods=-90)google['shifted'] = google.Close.shift(periods=90)# Plot the google price seriesgoogle.plot()plt.show()
加减乘除
- 减:.sub()
- 加:.add()
- 成:.mul()
- 除:.sub()
这几个方法只能被数据框直接调用,不然会报错,这里可以补一下基础
主要是因为这几个函数都是基于pandas的,而pandas这个包的操作就和tidyverse一样都是在数据框的基础上进行操作的
# Convert index series to dataframe heredata = index.to_frame('Index')# Normalize djia series and add as new column to datadjia = djia.div(djia.iloc[0]).mul(100)data['DJIA'] = djia# Show total return for both index and djiaprint(data.iloc[-1].div(data.iloc[0]).sub(1).mul(100))
# Create daily_returngoogle['daily_return'] = google.Close.pct_change().mul(100)# Create monthly_returngoogle['monthly_return'] = google.Close.pct_change(30).mul(100)# Create annual_returngoogle['annual_return'] = google.Close.pct_change(360).mul(100)# Plot the resultgoogle['daily_return']google.plot(subplots=True)plt.show()
上面这几行的代码暴露一个问题是我的语法还是不太熟。。。
整熟了再往下学啊
# Import data hereprices = pd.read_csv('asset_classes.csv',parse_dates=['DATE'],index_col='DATE')# Inspect prices hereprint(prices.info())# Select first pricesfirst_prices = prices.iloc[0]# Create normalizednormalized = prices.div(first_prices).mul(100)# Plot normalized#画图这个地方老是写错,记住直接调用normalized.plot()plt.show()
# Create tickerstickers = ['MSFT', 'AAPL']# Import stock data herestocks = pd.read_csv('msft_aapl.csv', parse_dates=['date'], index_col='date')# Import index heresp500 = pd.read_csv('sp500.csv', parse_dates=['date'], index_col='date')# Concatenate stocks and index heredata = pd.concat([stocks, sp500], axis=1).dropna()# Normalize datanormalized = data.div(data.iloc[0]).mul(100)# Subtract the normalized index from the normalized stock prices, and plot the resultnormalized[tickers].sub(normalized['SP500'], axis=0).plot()plt.show()
DataFrame.reindex()
这个函数就是重新定义索引
DataFrame.reindex(self, labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)[source]
通过data_range指定时间序列的起止时间
# Set start and end datesstart = '2016-1-1'end = '2016-2-29'# Create monthly_dates here#这个就是创建一个指定的起止时间,然后有相同的时间间隔monthly_dates = pd.date_range(start=start, end=end, freq='M')# Create monthly here,构造一个时间序列,但是要给一个时间戳monthly = pd.Series(data=[1,2], index=monthly_dates)print(monthly)# Create weekly_dates hereweekly_dates = pd.date_range(start=start, end=end, freq='W')# Print monthly, reindexed using weekly_datesprint(monthly.reindex(weekly_dates))print(monthly.reindex(weekly_dates, method='bfill'))print(monthly.reindex(weekly_dates, method='ffill'))#ffill : foreaward fill 向前填充,#如果新增加索引的值不存在,那么按照前一个非nan的值填充进去同理,bfill是后向补充<script.py> output:2016-01-31 12016-02-29 2Freq: M, dtype: int642016-01-03 NaN2016-01-10 NaN2016-01-17 NaN2016-01-24 NaN2016-01-31 1.02016-02-07 NaN2016-02-14 NaN2016-02-21 NaN2016-02-28 NaNFreq: W-SUN, dtype: float642016-01-03 12016-01-10 12016-01-17 12016-01-24 12016-01-31 12016-02-07 22016-02-14 22016-02-21 22016-02-28 2Freq: W-SUN, dtype: int642016-01-03 NaN2016-01-10 NaN2016-01-17 NaN2016-01-24 NaN2016-01-31 1.02016-02-07 1.02016-02-14 1.02016-02-21 1.02016-02-28 1.0Freq: W-SUN, dtype: float64
通过as.fred()指定时间序列的间隔
这个比较适合读入是时间序列的数据,然后直接做处理
# Import data heredata = pd.read_csv('unemployment.csv', parse_dates=['date'], index_col='date')# Show first five rows of weekly seriesprint(data.asfreq('W').head())# Show first five rows of weekly series with bfill optionprint(data.asfreq('W', method='bfill').head())# Create weekly series with ffill option and show first five rowsweekly_ffill = data.asfreq('W', method='ffill')print(weekly_ffill.head())# Plot weekly_fill starting 2015 hereweekly_ffill.loc['2015':].plot()plt.show()
interpolate()
这个函数是根据需求进行插值,目前的理解就是因为存在很多的缺失值进行插补,达到剔除缺失值的目的,一般情况下会暴力删除缺失值,剔除行或者列
官方文档有个demo
>>> s = pd.Series([np.nan, "single_one", np.nan,... "fill_two_more", np.nan, np.nan, np.nan,... 4.71, np.nan])>>> s0 NaN1 single_one2 NaN3 fill_two_more4 NaN5 NaN6 NaN7 4.718 NaNdtype: object>>> s.interpolate(method='pad', limit=2)0 NaN1 single_one2 single_one3 fill_two_more4 fill_two_more5 fill_two_more6 NaN7 4.718 4.71dtype: object
resample()
这个函数可以给已经存在的时间序列重新划分frequency
DataFrame.resample(self, rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0, on=None, level=None)
# Import and inspect data hereozone = pd.read_csv('ozone.csv',parse_dates=['date'],index_col='date')print(ozone.info())# Calculate and plot the weekly average ozone trend#日期的fre是week,并且求出每周的平均值ozone.resample('W').mean().plot()plt.show()
补充一个绘图的参数
plot(subplots=True)
这个参数代表的是有子图,且子图共用y轴
first()
这个函数是打印指定的前几行,但是不包括end
>>> i = pd.date_range('2018-04-09', periods=4, freq='2D')>>> ts = pd.DataFrame({'A': [1,2,3,4]}, index=i)>>> tsA2018-04-09 12018-04-11 22018-04-13 32018-04-15 4Get the rows for the first 3 days:>>> ts.first('3D')A2018-04-09 12018-04-11 2
pct_change()
DataFrame.pct_change(periods=1, fill_method=‘pad’, limit=None, freq=None, **kwargs)
表示当前元素与先前元素的相差百分比,当然指定periods=n,表示当前元素与先前n 个元素的相差百分比
嗯,这个函数适合批量求百分比
官方文档给的例子或许更好理解
>>> df = pd.DataFrame({... 'FR': [4.0405, 4.0963, 4.3149],... 'GR': [1.7246, 1.7482, 1.8519],... 'IT': [804.74, 810.01, 860.13]},... index=['1980-01-01', '1980-02-01', '1980-03-01'])>>> dfFR GR IT1980-01-01 4.0405 1.7246 804.741980-02-01 4.0963 1.7482 810.011980-03-01 4.3149 1.8519 860.13>>> df.pct_change()FR GR IT1980-01-01 NaN NaN NaN1980-02-01 0.013810 0.013684 0.0065491980-03-01 0.053365 0.059318 0.061876
pd.contact()
这个函数应该是类似于R 里面的rbind按行拼接,即纵向合并
>>> pd.concat([s1, s2], ignore_index=True)0 a1 b2 c3 ddtype: object
agg()
与groupby对应的聚合函数,有点类似于summarize
将一些基础运算整合到一起
rolling window functions.
滚动窗口函数
不知道之前的garch模型滑动窗口是不是用到了这个,这个我再查一下,确实不太明白
查到了 参考:
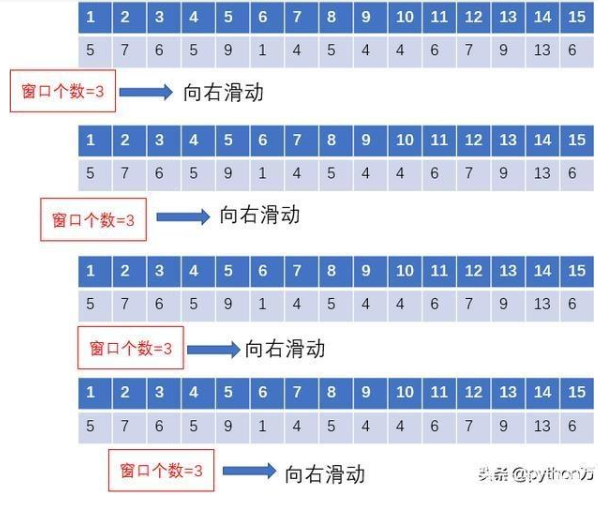
“时点的数据波动较大,某一点的数据不能很好的表现它本身的特性,于是我们就想,能否用一个区间的的数据去表现呢,这样数据的准确性是不是更好一些呢?因此,引出滑动窗口(移动窗口)的概念,简单点说,为了提升数据的可靠性,将某个点的取值扩大到包含这个点的一段区间,用区间来进行判断,这个区间就是窗口。如下面的示意图所示,其中时间序列数据代表的是15日每日的温度,现在我们以3天为一个窗口,将这个窗口从左至右依次滑动,统计出3天的平均值作为这个点的值,比如3号的温度就是1号、2号、3号的平均温度”
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)
- window
时间窗的大小,一般有两种形式,int:表示计算统计量的观测值的数量,即向前几个数量,要是offset则表示时间窗的大小。
min_periods:每个窗口最少包含的观测值的数量,小于这个窗口就是na
rolling()
join()
合并数据表的一个函数
两个DataFrame中的不同的列索引合并成为一个DataFrame
# Import and inspect ozone data heredata = pd.read_csv('ozone.csv', parse_dates=['date'], index_col='date').dropna()# Calculate the rolling mean and std hererolling_stats = data.Ozone.rolling(360).agg(['mean', 'std'])# Join rolling_stats with ozone data#默认左拼接,有点像R里面的left_join()stats = data.join(rolling_stats)# Plot statsstats.plot(subplots=True);plt.show()
quantile()
分位数函数
四分位数
概念:把给定的乱序数值由小到大排列并分成四等份,处于三个分割点位置的数值就是四分位数。
第1四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第2四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第3四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
四分位距(InterQuartile Range, IQR)= 第3四分位数与第1四分位数的差距
同时拓展到多分位数的概念
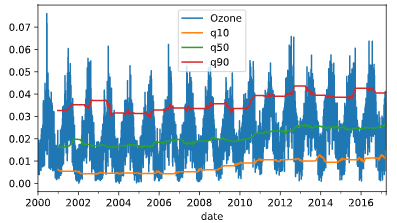
# Resample, interpolate and inspect ozone data heredata = data.resample('D').interpolate()data.info()# Create the rolling windowrolling = data.rolling(360)['Ozone']# Insert the rolling quantiles to the monthly returnsdata['q10'] = rolling.quantile(.1)data['q50'] = rolling.quantile(.5)data['q90'] = rolling.quantile(.9)# Plot the datadata.plot()plt.show()
append()
向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加
这个函数挺好使的 参考下官方文档 demo很好理解
可以进行行列合并
pandas 中统计累计次数
.cumsum()
累加
.cumprod()
累乘
# Import numpyimport numpy as np# Define a multi_period_return functiondef multi_period_return(period_returns):return np.prod(period_returns + 1) - 1# Calculate daily returnsdaily_returns = data.pct_change()# Calculate rolling_annual_returnsrolling_annual_returns = daily_returns.rolling('360D').apply(multi_period_return)# Plot rolling_annual_returnsrolling_annual_returns.mul(100).plot();plt.show()

np.prod这个是numpy里面求阶乘的
# Create multi_period_return function heredef multi_period_return(r):return (np.prod(r + 1) - 1) * 100
定义一个函数然后直接调用就行,计算数组乘积
一个案例学习
seed()
设定种子简书
设定生成随机数的种子,种子是为了让结果具有重复性,重现结果。如果不设定种子,生成的随机数无法重现
计算机并不能产生真正的随机数,如果你不设种子,计算机会用系统时钟来作为种子,如果你要模拟什么的话,每次的随机数都是不一样的,这样就不方便你研究,如果你事先设置了种子,这样每次的随机数都是一样的,便于重现你的研究,也便于其他人检验你的分析结果
random walk
# Set seed hereseed(42)# Create random_walkrandom_walk = normal(loc=.001, scale=0.01, size=2500)# Convert random_walk to pd.seriesrandom_walk = pd.Series(random_walk)# Create random_pricesrandom_prices = random_walk.add(1).cumprod()# Plot random_prices hererandom_prices.mul(1000).plot()plt.show();

choice()
随机抽样函数
生成随机数
Relationships between time series: correlation
heatmap()
相关系数矩阵热力图
之前论文中读到的热图,这回终于知道该怎么画了

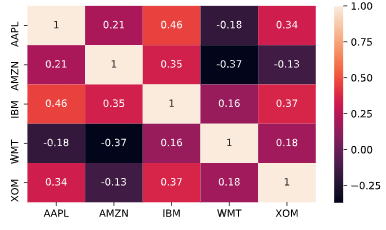
# Inspect data hereprint(data.info())# Calculate year-end prices hereannual_prices = data.resample('A').last()# Calculate annual returns hereannual_returns = annual_prices.pct_change()# Calculate and print the correlation matrix herecorrelations = annual_returns.corr()print(correlations)# Visualize the correlations as heatmap heresns.heatmap(correlations, annot=True)plt.show();
Select index components & import data
groupby()
简书
和R里面的group_by函数是一样的,好好用哦,之前写了一个for循环还是给写错了,真的是。。卧槽。。md
# Select largest company for each sectorcomponents = listings.groupby(['Sector'])['Market Capitalization'].nlargest(1)# Print components, sorted by market capprint(components.sort_values(ascending=False))# Select stock symbols and print the resulttickers = components.index.get_level_values('Stock Symbol')print(tickers)# Print company name, market cap, and last price for each componentinfo_cols = ['Company Name', 'Market Capitalization', 'Last Sale']print(listings.loc[tickers, info_cols].sort_values('Market Capitalization', ascending=False))<script.py> output:Sector Stock SymbolTechnology AAPL 740,024.47Consumer Services AMZN 422,138.53Miscellaneous MA 123,330.09Health Care AMGN 118,927.21Transportation UPS 90,180.89Finance GS 88,840.59Basic Industries RIO 70,431.48Public Utilities TEF 54,609.81Consumer Non-Durables EL 31,122.51Capital Goods ILMN 25,409.38Energy PAA 22,223.00Consumer Durables CPRT 13,620.92Name: Market Capitalization, dtype: float64Index(['RIO', 'ILMN', 'CPRT', 'EL', 'AMZN', 'PAA', 'GS', 'AMGN', 'MA', 'TEF', 'AAPL', 'UPS'], dtype='object', name='Stock Symbol')Company Name Market Capitalization Last SaleStock SymbolAAPL Apple Inc. 740,024.47 141.05AMZN Amazon.com, Inc. 422,138.53 884.67MA Mastercard Incorporated 123,330.09 111.22AMGN Amgen Inc. 118,927.21 161.61UPS United Parcel Service, Inc. 90,180.89 103.74GS Goldman Sachs Group, Inc. (The) 88,840.59 223.32RIO Rio Tinto Plc 70,431.48 38.94TEF Telefonica SA 54,609.81 10.84EL Estee Lauder Companies, Inc. (The) 31,122.51 84.94ILMN Illumina, Inc. 25,409.38 173.68PAA Plains All American Pipeline, L.P. 22,223.00 30.72CPRT Copart, Inc. 13,620.92 29.65
最后一行or一列的表示方法
可以用“-1”表示
sort_values
这个函数就是排序函数,类似于r里面的arrange函数
plotz中的参数kind
这个参数是用来设置绘图类型的
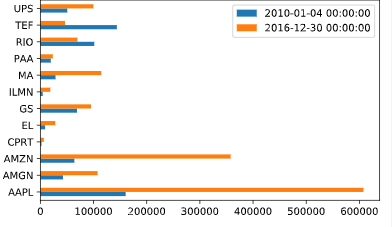
# Select the number of sharesno_shares = components['Number of Shares']print(no_shares.sort_values())# Create the series of market cap per tickermarket_cap = stock_prices.mul(no_shares)# Select first and last market cap herefirst_value = market_cap.iloc[0]last_value = market_cap.iloc[-1]# Concatenate and plot first and last market cap herepd.concat([first_value, last_value], axis=1).plot(kind='barh')plt.show()
to_excel()
将数据输出到excel中
# Export data and data as returns to excelwith pd.ExcelWriter('data.xls') as writer:data.to_excel(writer, sheet_name='data')returns.to_excel(writer, sheet_name='returns')
还行吧,记住语法,多尝试几遍就好了
pandas时间序列学习笔记的更多相关文章
- pandas包学习笔记
目录 zip Importing & exporting data Plotting with pandas Visual exploratory data analysis 折线图 散点图 ...
- pandas库学习笔记(二)DataFrame入门学习
Pandas基本介绍——DataFrame入门学习 前篇文章中,小生初步介绍pandas库中的Series结构的创建与运算,今天小生继续“死磕自己”为大家介绍pandas库的另一种最为常见的数据结构D ...
- 初步了解pandas(学习笔记)
1 pandas简介 pandas 是一种列存数据分析 API.它是用于处理和分析输入数据的强大工具,很多机器学习框架都支持将 pandas 数据结构作为输入. 虽然全方位介绍 pandas API ...
- pandas库学习笔记(一)Series入门学习
Pandas基本介绍: pandas is an open source, BSD-licensed (permissive free software licenses) library provi ...
- python的pandas库学习笔记
导入: import pandas as pd from pandas import Series,DataFrame 1.两个主要数据结构:Series和DataFrame (1)Series是一种 ...
- Pandas DataFrame学习笔记
对一个DF r1 r2 r3 c1 c2 c3 选行: df['r1'] df['r2':'r2'] #包含r2 df[df['c1']>5] #按条件选 选列: df['c1'] ...
- 数据分析之Pandas和Numpy学习笔记(持续更新)<1>
pandas and numpy notebook 最近工作交接,整理电脑资料时看到了之前的基于Jupyter学习数据分析相关模块学习笔记.想着拿出来分享一下,可是Jupyter导出来h ...
- Pandas学习笔记
本学习笔记来自于莫烦Python,原视频链接 一.Pandas基本介绍和使用 Series数据结构:索引在左,值在右 import pandas as pd import numpy as np s ...
- Pandas 学习笔记
Pandas 学习笔记 pandas 由两部份组成,分别是 Series 和 DataFrame. Series 可以理解为"一维数组.列表.字典" DataFrame 可以理解为 ...
随机推荐
- 使用Java, AppleScript对晓黑板进行自动打卡
使用Java, AppleScript对晓黑板进行自动打卡 由于我们学校要求每天7点起床打卡,但是实在做不到,遂写了这个脚本. 绪论 由于晓黑板不支持网页版,只能使用App进行打卡,所以我使用网易的安 ...
- chrome报错:您目前无法访问 因为此网站使用了 HSTS
chrome报错:您目前无法访问 因为此网站使用了 HSTS 其然: 现象 :访问github仓库报错'您目前无法访问XXXX 因为此网站使用了 HSTS' 解决方法:清理HSTS的设定,重新获取.c ...
- vim 快捷键方式
https://juejin.im/post/5ab1275d5188255588053e70#heading-14 安装方式 https://juejin.im/entry/57b281f72e95 ...
- android应用开发错误:Your project contains error(s),please fix them before running your
重新打开ECLIPSE运行android项目,或者一段时间为运行ECLIPSE,打开后,发现新建项目都有红叉,以前的项目重新编译也有这问题,上网搜索按下面操作解决了问题 工程上有红叉,不知道少了什么, ...
- StarUML之六、StarUML规则与快捷键
本章内容参考官网即可,不做详细说明,实践出真知! starUMl规则主要是在模型设计的约束条件 https://docs.staruml.io/user-guide/validation-rules ...
- ggEditor给节点增加提示框
参考官方文档: https://www.yuque.com/antv/g6/plugin.tool.tooltip 在react-ggEditor使用方法: import React from 're ...
- shell 一键配置单实例oracle基础环境变量(linux7)
#!/bin/bash echo "修改主机名" hostnamectl set-hostname wangxfa hostname sleep 1 echo "查看并关 ...
- P2024 NOI2001 种类冰茶鸡
展开 题目描述 动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形.A 吃 B,B 吃 C,C 吃 A. 现有 N 个动物,以 1 - N 编号.每个动物都是 A,B,C 中的一种, ...
- 全网小说免费阅读下载APP
先说主题:今天分享一个全网小说免费阅读下载APP.这篇文章是凌晨2点钟写的,原因呢可能有两点: 半夜无眠,一时兴起就想分享点有用的东西给大家,就问你感动不?其实吧,可能是晚上喝了点儿浓茶导致的无眠,所 ...
- Uva12169 扩展欧几里得模板
Uva12169(扩展欧几里得) 题意: 已知 $x_i=(a*x_{i-1}+b) mod 10001$,且告诉你 $x_1,x_3.........x_{2t-1}$, 让你求出其偶数列 解法: ...