爬虫入门 beautifulsoup库(一)
先贴一个beautifulsoup的官方文档,https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#id12
requests库用来获取url的响应,但是获取到确实网页代码,为了拿到自己想要的东西,我们需要用一下beautifulsoup这个库,这个库能把想要的东西提取出来。
下载和安装在官方文档里都有,这里还要说一下解析器。beautifulsoup这个库除了支持python标准库中的HTML解析器,还支持其他类似,lxml和html5lib。

上面这张表来自官方文档,选择哪种解析器就因人而异了。
接下来进入正文,首先要构造一个对象,用soup = BeautifulSoup(html,'lxml'),这html可以是事先用requests库请求来的,也可以是自己写的,当然,也可以用soup = BeautifulSoup(open("index.html"))这种方法打开自己html。
然后就是去查看那个html,当html里有a标签时,用soup.a即可输出遇到的第一条a标签,同理,也可以soup.title输出html的title标签。
仅仅是第一个标签那么满足不了我们的需求,我们需要所有的标签里的数据就需要用到findAll这个方法啦,用all_a=soup.findAll('a'),即可获得所有的a标签,但是这时候的输出都是带着a标签的,想要只获得内容,有需要用到string方法,all_a.string,即可。
话不多说,先试着把小米官网中的h2标签,即小标题给爬取下来试试
from bs4 import BeautifulSoup
import lxml
import requests url = 'https://www.mi.com/'
try:
#模拟浏览器
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url , headers = kv)
#状态码检查,用于
r.raise_for_status()
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text,'lxml')
for tag in soup.findAll('h2'):
print(tag.string)
except:
("爬取失败")
然后再讲讲string方法,在官方文档中的解释是这样的
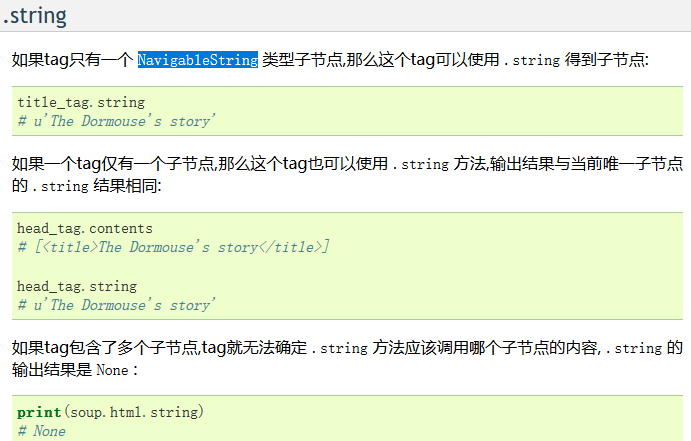
简单的说就是,当你获取的标签里没有别的标签了,你调用这个方法会输出这个标签里的内容,但这个标签里如果有其他的小标签和内容时,返回一个none值,比如说再爬取小米的a标签时、

这一条数据返回的就是none值
我们爬取数据的时候有时会把空白爬进去,但是又不想要空白的时候可以用.stripped_strings方法去除掉空白
然后讲一讲定位就比如说上面那条带着i标签的a标签,我们可以先找到i标签,在用他的父节点输出a标签,用。parent的方法,同理,通过 .next_siblings 和 .previous_siblings 属性可以找到当前节点的兄弟节点
爬虫入门 beautifulsoup库(一)的更多相关文章
- 爬虫之BeautifulSoup库
文档:https://beautifulsoup.readthedocs.io/zh_CN/latest/ 一.开始 解析库 # 安装解析库 pip3 install lxml pip3 instal ...
- python简单页面爬虫入门 BeautifulSoup实现
本文可快速搭建爬虫环境,并实现简单页面解析 1.安装 python 下载地址:https://www.python.org/downloads/ 选择对应版本,常用版本有2.7.3.4 安装后,将安装 ...
- Python爬虫之BeautifulSoup库
1. BeautifulSoup 1.1 解析库 1)Python标准库 # 使用方法 BeautifulSoup(markup, "html.parser") # 优势 Pyth ...
- Python爬虫入门 Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- python爬虫入门--beautifulsoup
1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ 2, from bs4 import Be ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- 爬虫入门 requests库
写在最前的具体资料: https://2.python-requests.org//zh_CN/latest/user/quickstart.html https://www.liaoxuefeng. ...
- python爬虫入门四:BeautifulSoup库(转)
正则表达式可以从html代码中提取我们想要的数据信息,它比较繁琐复杂,编写的时候效率不高,但我们又最好是能够学会使用正则表达式. 我在网络上发现了一篇关于写得很好的教程,如果需要使用正则表达式的话,参 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
随机推荐
- git 命令 总结
1.添加所有文件 git add . 2.添加某个文件 git add filename 3.commit 注释 git commit -m'commit 注释' 4.修改commit 注释 git ...
- SpringMVC 和 Struts2的区别
SpringMVC 和 Struts2的区别 1.Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方 ...
- hive删除表时直接卡死
原因:因为以前安装的mysql,字符集都改为了utf-8. 解决方案:需要把字符集都改为latin1 首先进入mysql查看字符集 show variables like 'char%' 找到mysq ...
- 2020牛客寒假算法基础集训营2 J.求函数 (线段树 推公式 单点修改 区间查询)
https://ac.nowcoder.com/acm/contest/3003/J 题解: #include<bits/stdc++.h> typedef long long ll; u ...
- 二分-B - Dating with girls(1)
B - Dating with girls(1) Everyone in the HDU knows that the number of boys is larger than the number ...
- mysql视图的创建、基本操作、作用
一.mysql视图的创建 作用:提高了重用性,就像一个函数.如果要频繁获取user的name和goods的name.就应该使用以下sql语言.示例: 先创建3张表 1.1user表 1.2goods表 ...
- Python之二:基础知识
1.常量: 1.1.数:5.1.23.9.25e-3 4种类型的数——整数.长整数.浮点数和复数 2是一个整数的例子. 长整数不过是大一些的整数. 3.23和52.3E-4是浮点数的例子.E标记表示1 ...
- jave的安装
1.此电脑-属性-高级系统设置-环境变量2.点下面那个 新建- JAVA_HOME3. 双击PATH变量,新建一个参数 4.新建CLASSPATH环境变量
- Spring作用域和BeenFactory
1.Spring Bean实例作用域: ① singleton: IOC容器仅创建一个Bean实例,IOC容器每次返回的是同一个Bean实例. ② prototype: IOC容器可以创建多个 ...
- Codeforces Round #623 (Div. 1, based on VK Cup 2019-2020 - Elimination Round, Engine)A(模拟,并查集)
#define HAVE_STRUCT_TIMESPEC #include<bits/stdc++.h> using namespace std; pair<]; bool cmp( ...