(转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日。
翻着安静到死寂的聊天列表,我忽然惊醒,不行,我们不能这样下去,光羡慕别人有什么用,我们要行动起来,去找自己的幸福!!!
我也想“谈不分手的恋爱” !!!内牛满面!!!
注册登陆一气呵成~
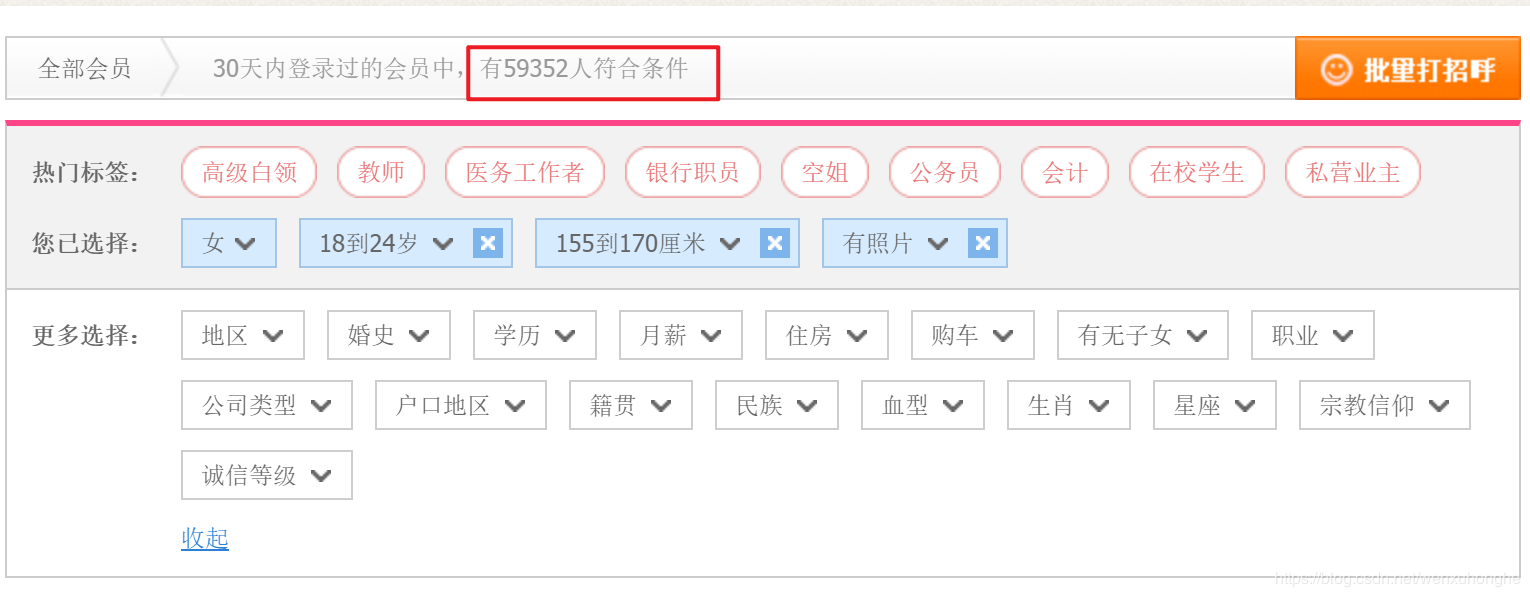
筛选条件,嗯...性别女,年龄...18到24岁,身高嘛,无所谓啦,就按默认155-170吧,地区...嗯北京好,北京近一点,照片?那肯定要啊,必须的!!!
小姐姐们我来了~
哇,好多小姐姐啊,到底该选哪个搭讪啊.......

这时候就该我们的爬虫出场了
爬虫部分
爬虫部分还是我们之前的四步:分析目标网页,获取网页内容,提取关键信息,输出保存
1. 首先分析目标网页
按F12召唤开发者工具页面,切换到Network选项,然后在翻页的时候抓包,成功截获请求URL。
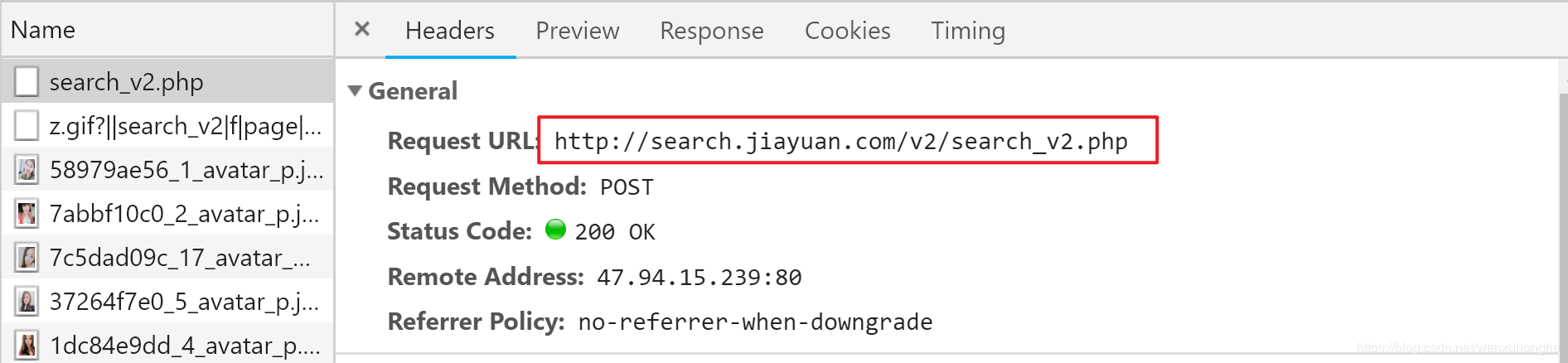
不过,这个请求是 POST 方法的,和我们之前见到的 GET 方法的请求有点不同。哪里不同呢......它有点短?
没错,它太短了,少了很多信息,比如我们搜索的条件,甚至连页码的信息都没有,光靠它怎么可能正确的找到小姐姐嘛!
别急,往下翻,其实, POST 方法请求的参数是放在 Form Data 的地方(怎么可能没有嘛是吧)
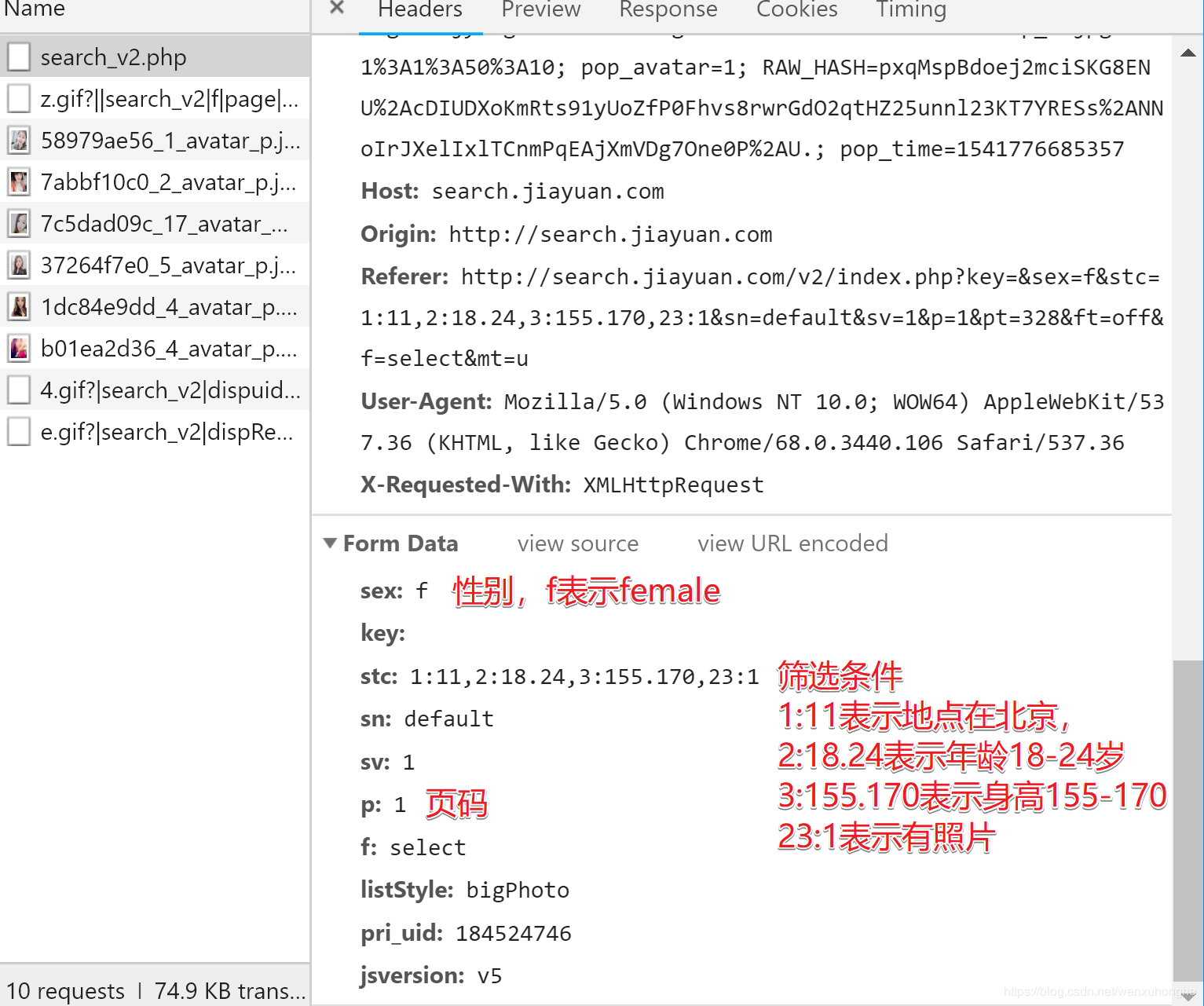
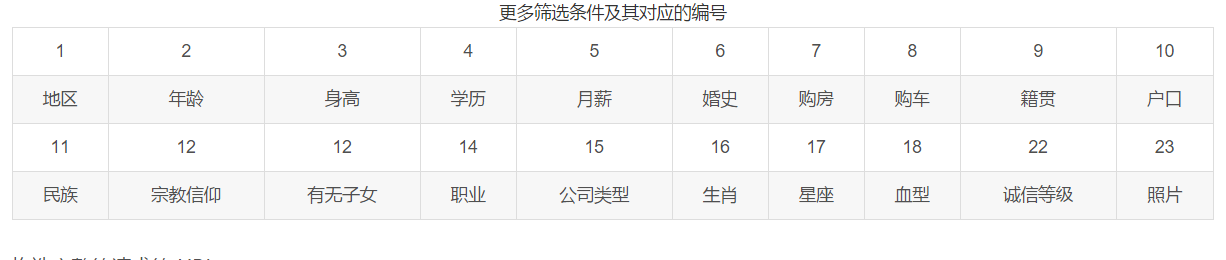
PS:除了这些之外,还有更多更细的筛选条件
更多筛选条件及其对应的编号
1 2 3 4 5 6 7 8 9 10
地区 年龄 身高 学历 月薪 婚史 购房 购车 籍贯 户口
11 12 12 14 15 16 17 18 22 23
民族 宗教信仰 有无子女 职业 公司类型 生肖 星座 血型 诚信等级 照片
构造完整的请求的 URL ,
http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=1:11,2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select
访问,没问题,改变p的值,访问,没问题,OK本阶段完成。
2. 解析网页内容
通过上面的url,我们可以获取到服务器返回的 json格式的用户信息。代码如下:
import requests def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Cookie': 'guider_quick_search=on; SESSION_HASH=f09e081981a0b33c26d705c2f3f82e8f495a7b56; PHPSESSID=e29e59d3eacad9c6d809b9536181b5b4; is_searchv2=1; save_jy_login_name=18511431317; _gscu_1380850711=416803627ubhq917; stadate1=183524746; myloc=11%7C1101; myage=23; mysex=m; myuid=183524746; myincome=30; COMMON_HASH=4eb61151a289c408a92ea8f4c6fabea6; sl_jumper=%26cou%3D17%26omsg%3D0%26dia%3D0%26lst%3D2018-11-07; last_login_time=1541680402; upt=4mGnV9e6yqDoj%2AYFb0HCpSHd%2AYI3QGoganAnz59E44s4XkzQZ%2AWDMsf5rroYqRjaqWTemZZim0CfY82DFak-; user_attr=000000; main_search:184524746=%7C%7C%7C00; user_access=1; PROFILE=184524746%3ASmartHe%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10; pop_avatar=1; RAW_HASH=n%2AazUTWUS0GYo8ZctR5CKRgVKDnhyNymEBbT2OXyl07tRdZ9PAsEOtWx3s8I5YIF5MWb0z30oe-qBeUo6svsjhlzdf-n8coBNKnSzhxLugttBIs.; pop_time=1541680493356'
} try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'unicode_escape'
print(r.url)
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !") if __name__ == '__main__':
url = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select'
html = fetchURL(url)
print(html)
在这里有几个需要注意的点:
① 网站的搜索功能是需要登陆的,否则会一直弹框提示登陆,所以我只好注册了个账号,登陆后将 cookie 放入爬虫的请求头中,这样便可正确访问数据(不过在爬虫爬取过程中,我发现其实不需要登陆也可以获取,我是不是亏了?!!)
②直接打开请求返回的结果,其实是不能“看”的,通篇没一个汉字,都是各种类似于乱码的东西,这其实是一种 unicode 编码,将汉字转化成 \u 开头的一串字符。

想要解码成汉字也很容易,只需要将 response 的编码方式 encoding 设定为 unicode_escape 即可。
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'unicode_escape'
print(r.text)
③为了尽可能多一点的寻找,我决定将“地区”这一条件限制去掉,重新访问,果然,搜到的小姐姐由原先的 3229 瞬间涨到了 59146 ,这下可以开心的爬了。

3.提取关键信息
通过分析上面获取到的 josn 文件,我们可以知道,这里面包含了用户的相当多的信息,包括用户ID,昵称,性别,年龄,身高,照片,学历,城市,择偶标准,以及个性宣言等(不过有些信息在这里是获取不到的,需要进入个人主页才能查看,比如收入等)。
import json def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
s = json.loads(html) usrinfo = [] for key in s['userInfo']: blist = [] uid = key['uid']
nickname = key['nickname']
sex = key['sex']
age = key['age']
work_location = key['work_location']
height = key['height']
education = key['education'] matchCondition = key['matchCondition']
marriage = key['marriage']
income = key['income']
shortnote = key['shortnote']
image = key['image'] blist.append(uid)
blist.append(nickname)
blist.append(sex)
blist.append(age)
blist.append(work_location)
blist.append(height)
blist.append(education)
blist.append(matchCondition)
blist.append(marriage)
blist.append(income)
blist.append(shortnote)
blist.append(image) usrinfo.append(blist)
print(nickname,age,work_location) #writePage(usrinfo)
print('---' * 20)
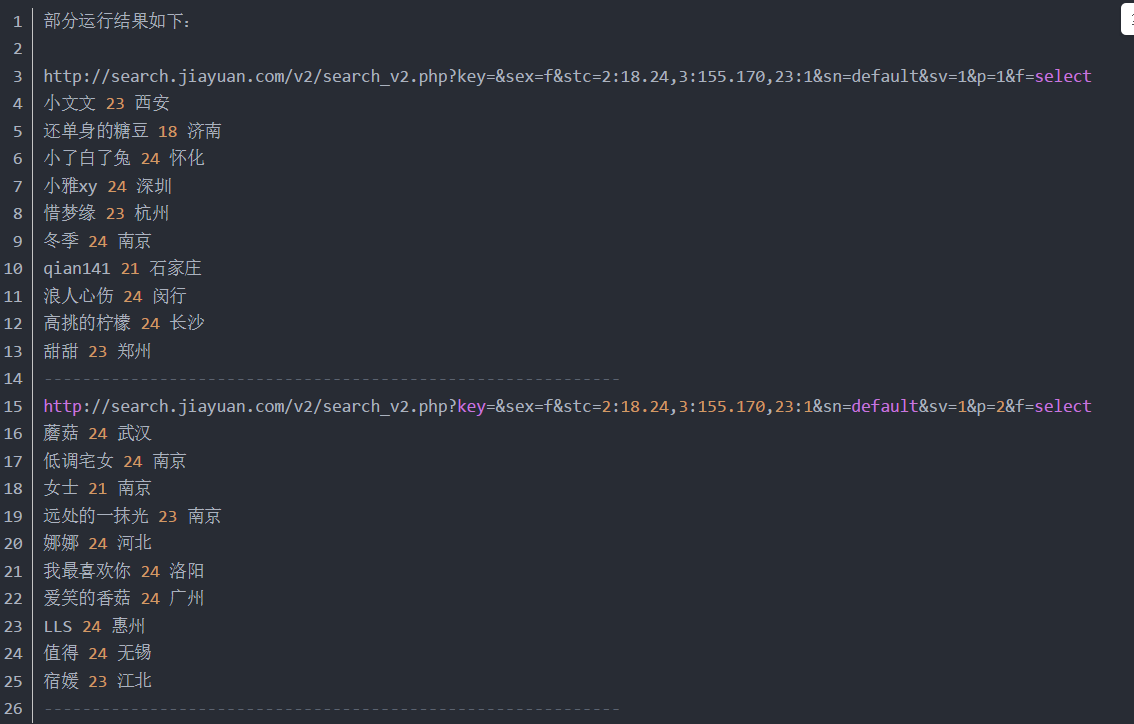
部分运行结果如下:
http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=1&f=select
小文文 23 西安
还单身的糖豆 18 济南
小了白了兔 24 怀化
小雅xy 24 深圳
惜梦缘 23 杭州
冬季 24 南京
qian141 21 石家庄
浪人心伤 24 闵行
高挑的柠檬 24 长沙
甜甜 23 郑州
------------------------------------------------------------
http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=2&f=select
蘑菇 24 武汉
低调宅女 24 南京
女士 21 南京
远处的一抹光 23 南京
娜娜 24 河北
我最喜欢你 24 洛阳
爱笑的香菇 24 广州
LLS 24 惠州
值得 24 无锡
宿媛 23 江北
------------------------------------------------------------
4. 保存输出文件
最后,只需要把提取出的信息写入csv文件,即可完成本次爬取的工作。下面是完整代码:
import requests
import json
import time def fetchURL(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'Cookie': 'guider_quick_search=on; SESSION_HASH=f09e081981a0b33c26d705c2f3f82e8f495a7b56; PHPSESSID=e29e59d3eacad9c6d809b9536181b5b4; is_searchv2=1; save_jy_login_name=18511431317; _gscu_1380850711=416803627ubhq917; stadate1=183524746; myloc=11%7C1101; myage=23; mysex=m; myuid=183524746; myincome=30; COMMON_HASH=4eb61151a289c408a92ea8f4c6fabea6; sl_jumper=%26cou%3D17%26omsg%3D0%26dia%3D0%26lst%3D2018-11-07; last_login_time=1541680402; upt=4mGnV9e6yqDoj%2AYFb0HCpSHd%2AYI3QGoganAnz59E44s4XkzQZ%2AWDMsf5rroYqRjaqWTemZZim0CfY82DFak-; user_attr=000000; main_search:184524746=%7C%7C%7C00; user_access=1; PROFILE=184524746%3ASmartHe%3Am%3Aimages1.jyimg.com%2Fw4%2Fglobal%2Fi%3A0%3A%3A1%3Azwzp_m.jpg%3A1%3A1%3A50%3A10; pop_avatar=1; RAW_HASH=n%2AazUTWUS0GYo8ZctR5CKRgVKDnhyNymEBbT2OXyl07tRdZ9PAsEOtWx3s8I5YIF5MWb0z30oe-qBeUo6svsjhlzdf-n8coBNKnSzhxLugttBIs.; pop_time=1541680493356'
} try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'unicode_escape'
print(r.url)
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !") def parserHtml(html):
'''
功能:根据参数 html 给定的内存型 HTML 文件,尝试解析其结构,获取所需内容
参数:
html:类似文件的内存 HTML 文本对象
'''
s = json.loads(html) usrinfo = [] for key in s['userInfo']: blist = [] uid = key['uid']
nickname = key['nickname']
sex = key['sex']
age = key['age']
work_location = key['work_location']
height = key['height']
education = key['education'] matchCondition = key['matchCondition']
marriage = key['marriage']
income = key['income']
shortnote = key['shortnote']
image = key['image'] blist.append(uid)
blist.append(nickname)
blist.append(sex)
blist.append(age)
blist.append(work_location)
blist.append(height)
blist.append(education)
blist.append(matchCondition)
blist.append(marriage)
blist.append(income)
blist.append(shortnote)
blist.append(image) usrinfo.append(blist)
print(nickname,age,work_location) writePage(usrinfo)
print('---' * 20) def writePage(urating):
'''
Function : To write the content of html into a local file
html : The response content
filename : the local filename to be used stored the response
''' import pandas as pd
dataframe = pd.DataFrame(urating)
dataframe.to_csv('Jiayuan_UserInfo.csv', mode='a', index=False, sep=',', header=False) if __name__ == '__main__':
for page in range(1, 5916):
url = 'http://search.jiayuan.com/v2/search_v2.php?key=&sex=f&stc=2:18.24,3:155.170,23:1&sn=default&sv=1&p=%s&f=select' % str(page)
html = fetchURL(url)
parserHtml(html) # 为了降低被封ip的风险,每爬100页便歇5秒。
if page%100==99:
time.sleep(5)
后续工作
1. 文件去重
花了两个多小时,爬了5千多页,爬到了接近六万条数据,本来是一个相当开心的事情,但是当我打开文件,按 用户ID 排序之后,发现!!!!

神魔鬼!!!居然有大量重复的数据,单就这个叫 “名芳” 的用户,便有两千多条,这能得了?!!!
为了验证是不是我程序哪儿出错了,我反复检查调试了很久。
我发现,如果只爬前100页的数据,则重复率较低,而100页之后,便开始大量的出现重复用户了;而且重复的数据并不是同一页中连续出现,而是来自不同页。
百思不得其解,遂求助大佬,大佬听完我的描述之后说,会不会是网站的数据本身便是有问题的?
为了解开这个疑惑,我决定去网站上手动查找,一探究竟,到底在100页之后,发生了什么事儿。

此网站的翻页功能用的相当蹩脚,只有首页,上一页和下一页,页码跳转也每次只能选择前后5页。点了好久终于到了一百多页之后,发现了一件令人震惊的事情。
这是我随手截的三页的截图,108页,109页,和110页,图片下方有截图为证,来感受一下,跟连连看似的。
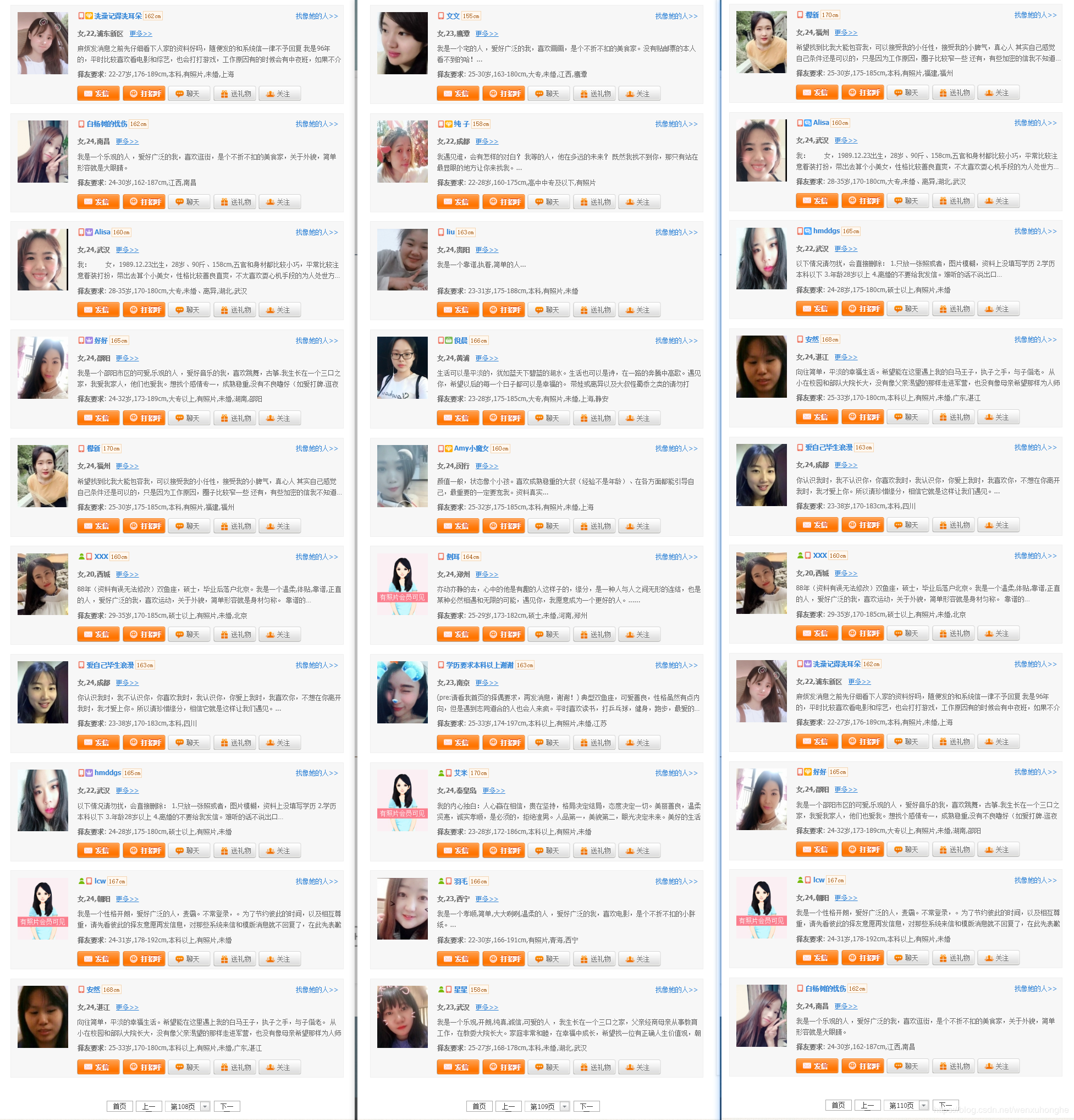
好吧,同样的用户换个顺序来凑页数是吗,我现在就想看看去重之后究竟还剩多少个。
import pandas as pd inputfile = "Jiayuan_UserInfo.csv"
outputfile = "Jiayuan_UserInfo_output.csv" df = pd.read_csv(inputfile,encoding='utf-8',names=['uid','nickname','sex','age','work_location','height','education','matchCondition','marriage','income','shortnote','image']) datalist = df.drop_duplicates()
datalist.to_csv(outputfile,encoding='utf-8',index=False, header=False)
print("Done!")
下面是运行结果:
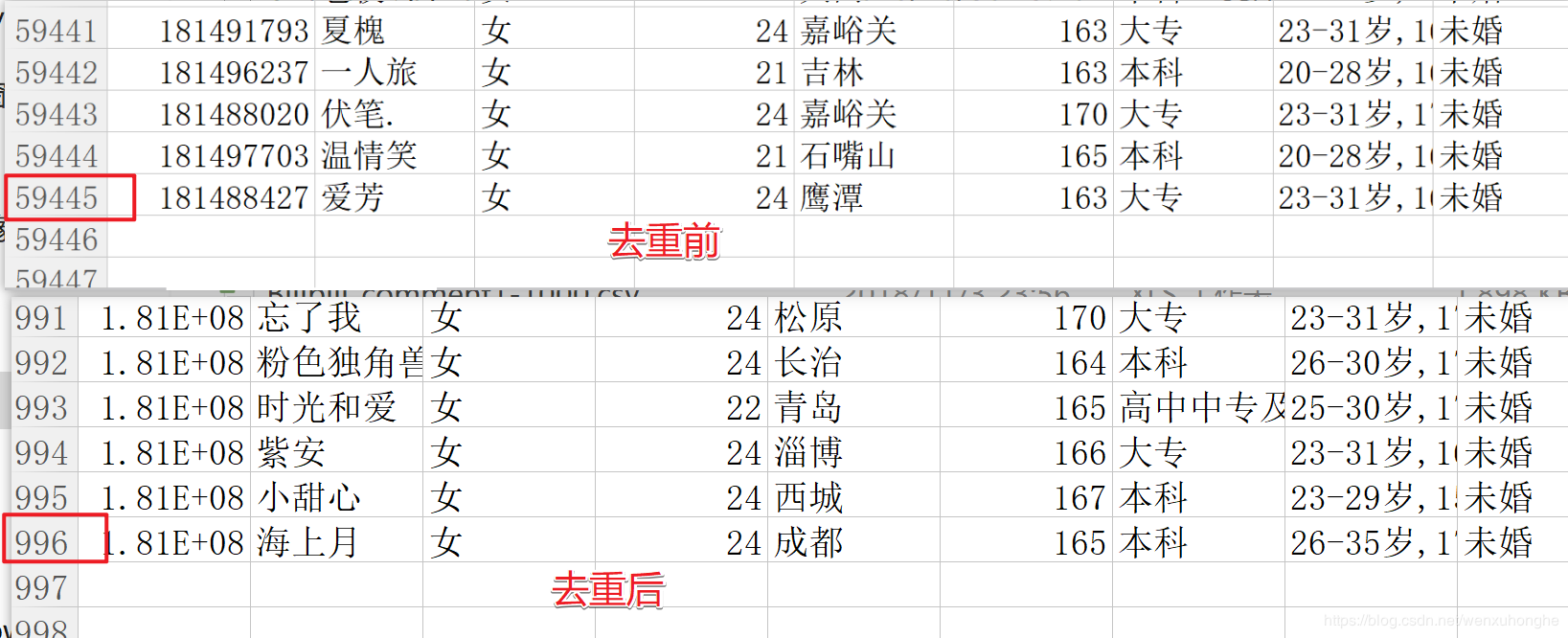
堂堂接近6万人的搜索结果,去重之后居然只剩下不到1000人,再回头看看看看网站上 “有 59352 人符合条件”,是不是感觉啪啪打脸呢。用这种手段来营造用户量很大的假象,高明的很呐。
2.照片下载
抛开数据作假不说,我们此行的目的可是看小姐姐来的呢!
言归正传,我们来下载小姐姐们的照片咯,照片的链接在我们之前保存的csv文件中就有。
import requests
import pandas as pd # 读取csv文件
userData = pd.read_csv("Jiayuan_UserInfo_output.csv",names=['uid','nickname','sex','age','work_location','height','education','matchCondition','marriage','income','shortnote','image']) for line in range(len(userData)):
url = userData['image'][line]
img = requests.get(url).content
nickname = re.sub("[\s+\.\!\/_,$%^*(+\"\'?|]+|[+——!,。?、~@#¥%……&*()▌]+", "",userData['nickname'][line]) filename = str(line) + '-' + nickname + '-' + str(userData['height'][line]) + '-' + str(userData['age'][line]) + '.jpg'
try:
with open('images_output/' + filename, 'wb') as f:
f.write(img)
except:
print(filename) print("Finished!")
为了方便辨认,我这里将 序号 + 用户昵称 + 身高 + 年龄 作为图片的文件名
这里有一点需要注意的是,用户昵称中可能会包含一些奇形怪状的字符,以它们作为文件名的话,在保存文件的时候会出现异常,所以这里先将用户名做了一些处理,剔除其中的标点符号等字符,并且做了一个异常处理,即如果出现异常,则输出该文件名,并继续保存下一个。
于是乎,我得到了 996 张小姐姐的照片。。。
不过,这些已经不重要了,
这次,我不仅顺利爬到了全部小姐姐的数据,还发现了网站的一点“小秘密”。
此时的我无比的膨胀,我觉得我很牛逼
我觉得她们都配不上我。
---------------------
作者:机灵鹤
来源:CSDN
原文:https://blog.csdn.net/wenxuhonghe/article/details/83904396
版权声明:本文为博主原创文章,转载请附上博文链接!
(转)Python网络爬虫实战:世纪佳缘爬取近6万条数据的更多相关文章
- 爬虫(二)Python网络爬虫相关基础概念、爬取get请求的页面数据
什么是爬虫 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程. 哪些语言可以实现爬虫 1.php:可以实现爬虫.php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- 【Python网络爬虫四】通过关键字爬取多张百度图片的图片
最近看了女神的新剧<逃避虽然可耻但有用>,同样男主也是一名程序员,所以很有共鸣 被大只萝莉萌的一脸一脸的,我们来爬一爬女神的皂片. 百度搜索结果:新恒结衣 本文主要分为4个部分: 1.下载 ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- Python网络爬虫案例(二)——爬取招聘信息网站
利用Python,爬取 51job 上面有关于 IT行业 的招聘信息 版权声明:未经博主授权,内容严禁分享转载 案例代码: # __author : "J" # date : 20 ...
- python网络爬虫之scrapy 调试以及爬取网页
Shell调试: 进入项目所在目录,scrapy shell “网址” 如下例中的: scrapy shell http://www.w3school.com.cn/xml/xml_syntax.as ...
- 关于Python网络爬虫实战笔记③
Python网络爬虫实战笔记③如何下载韩寒博客文章 Python网络爬虫实战笔记③如何下载韩寒博客文章 target:下载全部的文章 1. 博客列表页面规则 也就是, http://blog.sina ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- 关于Python网络爬虫实战笔记①
python网络爬虫项目实战笔记①如何下载韩寒的博客文章 python网络爬虫项目实战笔记①如何下载韩寒的博客文章 1. 打开韩寒博客列表页面 http://blog.sina.com.cn/s/ar ...
随机推荐
- Shell 示例:将指定的文件内容转换为大写
程序代码如下: #!/bin/bash # 将一个指定的输入文件内容转换为大写 E_FILE_ACCESS=70 E_WRONG_ARGS=71 if [ ! -r "$1" ] ...
- [转]Angular 4|5 Material Dialog with Example
本文转自:https://www.techiediaries.com/angular-material-dialogs/ In this tutorial, we're going to learn ...
- typeof() 和 GetType()区是什么
1.typeof(x)中的x,必须是具体的类名.类型名称等,不可以是变量名称. 2.GetType()方法继承自Object,所以C#中任何对象都具有GetType()方法,它的作用和typeof() ...
- Android开发——使用自带图标
Android其实也是自带有许多常用的图标,我们直接使用即可 在源代码*.Java中可以进入如下方式引用: myMenuItem.setIcon(android.R.drawable.ic_menu_ ...
- Matlab illustrate stiffness
% matlab script to illustrate stiffness % using simple flame propagation model close all clear all % ...
- SQL Server 创建和修改数据表
一.CREATE语句(创建) 1.创建DataBase 1.CONTAINMENT SQL Server 2012 新功能 , 默认值是OFF .(太高级 书上也没有详细介绍). 2.ON ON用于两 ...
- JS 数组位置方法 indexOf()和lastIndexOf()的理解
var numbers = [1,3,5,7,9,4,3,2,1]; console.log(numbers.indexOf(5)); //从数组的0位开始查找 5 位于数组里面的位置 输出2 首先 ...
- 【读书笔记】iOS-方法声明
编译的时候 ,编译器会把方法前面的IBAction替换成void,把属性前面的IBOutlet移除掉,因为这些都 只是Interface Builder的标志而已.这个IBAction方法会被UI控件 ...
- mybatis 中between and用法
今天遇到一个问题,半天没看出来问题,特意记录一下 Dao ConfigEvaluation findConfigEvaluationByEvalpecent(BigDecimal evalPercen ...
- 用Web Services来整合.NET和J2EE
互用性(Interoperability)问题说起来容易但通常实现起来却比较困难.尽管Web service曾承诺要提供最佳的解决方案来衔接基于.NET和J2EE的应用程序,但其过程却并不简单.我们发 ...