近端梯度算法(Proximal Gradient Descent)
L1正则化是一种常用的获取稀疏解的手段,同时L1范数也是L0范数的松弛范数。求解L1正则化问题最常用的手段就是通过加速近端梯度算法来实现的。
考虑一个这样的问题:
minx f(x)+λg(x)
x∈Rn,f(x)∈R,这里f(x)是一个二阶可微的凸函数,g(x)是一个凸函数(或许不可导),如上面L1的正则化||x||。
此时,只需要f(x)满足利普希茨(Lipschitz)连续条件,即对于定义域内所有向量x,y,存在常数M使得||f'(y)-f'(x)||<=M·||y-x||,那么这个模型就可以通过近端梯度算法来进行求解了。
ps:下面涉及很多数学知识,不想了解数学的朋友请跳到结论处,个人理解,所以也不能保证推理很严谨,如有问题,请一定帮忙我告诉我。
利普希茨连续条件的几何意义可以认为是函数在定义域内任何点的梯度都不超过M(梯度有上限),也就是说不会存在梯度为正负无穷大的情况。
因而,我们有下图所示的推算:
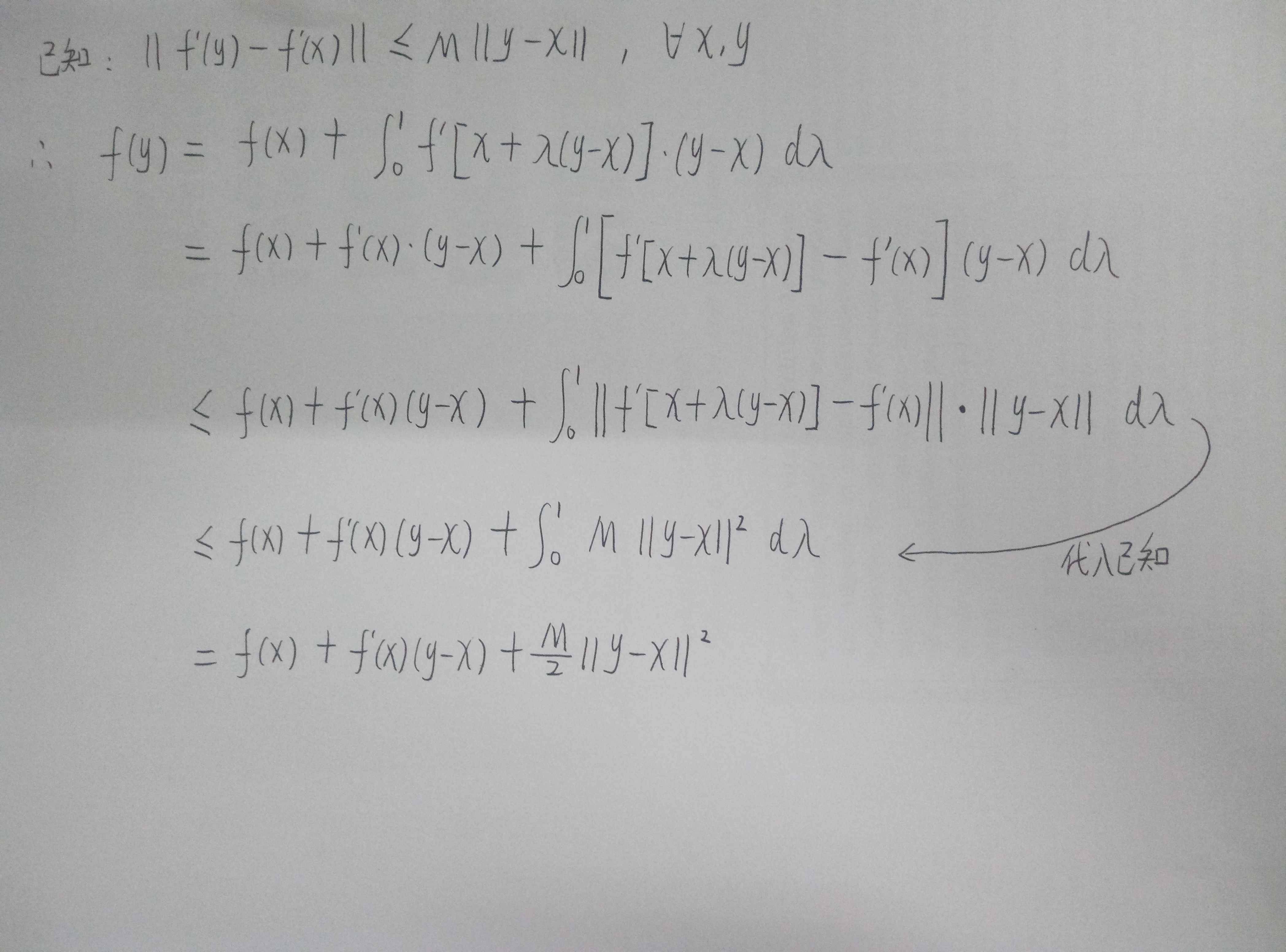
我们可以用f(y) = f(x)+f'(x)(y-x)+M/2*||y-x||2来近似的表示f(y),也可以认为是高维下的泰勒分解,取到二次项。
我们换一种写法,f(xk+1) = f(xk)+f'(xk)(xk+1-xk)+M/2*||xk+1-xk||2,也就是说可以直接迭代求minx f(x),就是牛顿法辣。
再换一种写法,f(xk+1)=(M/2)(xk+1-(xk+(1/M)f'(xk)))2+CONST,其中CONST是一个与xk+1无关的常数,也就是说,此时我们可以直接写出这个条件下xk+1的最优取值就是xk+1=xk+(1/M)f'(xk)。令z=xk+(1/M)f'(xk)。
回到原问题,minx f(x)+λg(x),此时问题变为了求解minx (M/2)||x-z||2+λg(x)。
实际上在求解这个问题的过程中,x的每一个维度上的值是互不影响的,可以看成n个独立的一维优化问题进行求解,最后组合成一个向量就行。
如果g(x)=||x||1,就是L1正则化,那么最后的结论可以通过收缩算子来表示。
即xk+1=shrink(z,λ/M)。具体来说,就是Z向量的每一个维度向原点方向移动λ/M的距离(收缩,很形象),对于xk+1的第i个维度xi=sgn(zi)*max(|zi|-λ/M,0),其中sgn()为符号函数,正数为1,负数为-1。
一直迭代直到xk收敛吧。
参考文献:
[1]Nesterov Y. Introductory lectures on convex optimization: A basic course[M]. Springer Science & Business Media, 2013.
[2]https://people.eecs.berkeley.edu/~elghaoui/Teaching/EE227A/lecture18.pdf
近端梯度算法(Proximal Gradient Descent)的更多相关文章
- Proximal Gradient Descent for L1 Regularization(近端梯度下降求解L1正则化问题)
假设我们要求解以下的最小化问题: $min_xf(x)$ 如果$f(x)$可导,那么一个简单的方法是使用Gradient Descent (GD)方法,也即使用以下的式子进行迭代求解: $x_{k+1 ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- Proximal Gradient Descent for L1 Regularization
[本文链接:http://www.cnblogs.com/breezedeus/p/3426757.html,转载请注明出处] 假设我们要求解以下的最小化问题: ...
- 梯度下降(Gradient Descent)
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 梯度下降(Gradient Descent)相关概念
梯度,直观理解: 梯度: 运算的对像是纯量,运算出来的结果会是向量在一个标量场中, 梯度的计算结果会是"在每个位置都算出一个向量,而这个向量的方向会是在任何一点上从其周围(极接近的周围,学过 ...
- One-hot 编码/TF-IDF 值来提取特征,LAD/梯度下降法(Gradient Descent),Sigmoid
1. 多值无序类数据的特征提取: 多值无序类问题(One-hot 编码)把“耐克”编码为[0,1,0],其中“1”代表了“耐克”的中 间位置,而且是唯一标识.同理我们可以把“中国”标识为[1,0],把 ...
- [机器学习] ML重要概念:梯度(Gradient)与梯度下降法(Gradient Descent)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自网上的免费课程和一些经典书籍,免费课 ...
- ML:梯度下降(Gradient Descent)
现在我们有了假设函数和评价假设准确性的方法,现在我们需要确定假设函数中的参数了,这就是梯度下降(gradient descent)的用武之地. 梯度下降算法 不断重复以下步骤,直到收敛(repeat ...
- 机器学习基础——梯度下降法(Gradient Descent)
机器学习基础--梯度下降法(Gradient Descent) 看了coursea的机器学习课,知道了梯度下降法.一开始只是对其做了下简单的了解.随着内容的深入,发现梯度下降法在很多算法中都用的到,除 ...
随机推荐
- 20175310 迭代和JDB
迭代和JDB 1 使用C(n,m)=C(n-1,m-1)+C(n-1,m)公式进行递归编程实现求组合数C(m,n)的功能 zuheshu.java文件夹下的代码: import java.util.S ...
- PAT A1106 Lowest Price in Supply Chain (25 分)——树的bfs遍历
A supply chain is a network of retailers(零售商), distributors(经销商), and suppliers(供应商)-- everyone invo ...
- python:利用smtplib模块发送邮件
自动化测试中,测试报告一般都需要发送给相关的人员,比较有效的一个方法是每次执行完测试用例后,将测试报告(HTML.截图.附件)通过邮件方式发送. 参考代码:send_mail.py 一.python对 ...
- js求数组的最大值--奇技淫巧和笨方法
写这篇文章的原因 我目前做的项目很少用到算法,于是这方面的东西自然就有点儿生疏.最近的一次编码中遇到了从数组中获取最大值的需求,当时我不自觉的想到了js的sort()函数,现在想来真是有些“罪过”,当 ...
- SpringMVC之单/多文件上传
1.准备jar包(图标所指必备包,其他按情况导入) 2.项目结构 3.SingleController.java(控制器代码单文件和多文件) package com.wt.uplaod; import ...
- CF 859E Desk Disorder
题目大意:一个经典的游戏:抢椅子.有\(n\)个人以及\(2n\)把椅子.开始时每个人坐在一把椅子上,而且他们每个人都有一个下一步想坐的位置(可以与之前重合).每一个下一次可以在自己现在做的椅子和想坐 ...
- linux svn代码回滚命令
取消对代码的修改分为两种情况: 第一种情况:改动没有被提交(commit). 这种情况下,使用svn revert就能取消之前的修改. svn revert用法如下: # svn revert [-R ...
- 认识Python&基础环境搭建
前言 作为.NET Coder可能.NET Core是现阶段首要学习方向,但是说实在的对Core真的不感冒. 原因有几点: 1.公司项目底层需要的一部分库,Core还不支持. 2.同样的需求,.NET ...
- Azure Load Balancer : 支持 IPv6
越来越多的网站开始支持 IPv6,即使是哪些只提供 api 服务的站点也需要支持 IPv6,比如苹果应用商店中的 app 早就强制要求服务器端支持 IPv6 了.笔者在前文<Azure Load ...
- Nginx+Tomcat+Memcached部署
环境清单列表:(因为只有三台电脑,所有把Nginx和memcached放到一起) 应用服务器1:192.168.51.10: 应用服务器2:192.168.55.110: memcached服务器:1 ...