Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT
这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%。随后作者研究了对整体预测系统产生影响的几个因素,发现Feature(能挖掘出用户和广告的历史信息)+Model(GBDT+LR)的贡献程度最大,而其他因素(数据实时性,模型学习速率,数据采样)的影响则较小。
1. INTRODUCTION
介绍了先前的一些相关paper。包括Google,Yahoo,MS的关于CTR Model方面的paper。
而在Facebook,广告系统是由级联型的分类器(a cascade of classifiers)组成,而本篇paper讨论的CTR Model则是这个cascade classifiers的最后一环节。
2. EXPERIMENTAL SETUP
作者介绍了如何构建training data和testing data,以及Evaluation Metrics。包括Normalized Entropy和Calibration。
Normalized Entropy的定义为每次展现时预测得到的log loss的平均值,除以对整个数据集的平均log loss值。之所以需要除以整个数据集的平均log loss值,是因为backgroud CTR越接近于0或1,则越容易预测取得较好的log loss值,而做了normalization后,NE便会对backgroud CTR不敏感了。这个Normalized Entropy值越低,则说明预测的效果越好。下面列出表达式:
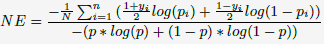
Calibration的定义为预估CTR除以真实CTR,即预测的点击数除以真实观察到的点击数。这个值越接近1,则表明预测效果越好。
3. PREDICTION MODEL STRUCTURE
作者介绍了两种Online Learning的方法。包括Stochastic Gradient Descent(SGD)-based LR:

和Bayesian online learning scheme for probit regression(BOPR):
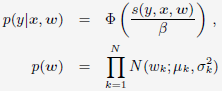
BOPR每轮迭代时的更新公式为:
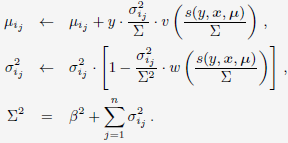
3.1 Decision tree feature transforms
Linear Model的表达能力不够,需要feature transformation。第一种方法是对连续feature进行分段处理(怎样分段,以及分段的分界点是很重要的);第二种方法是进行特征组合,包括对离散feature做笛卡尔积,或者对连续feature使用联合分段(joint binning),比如使用k-d tree。
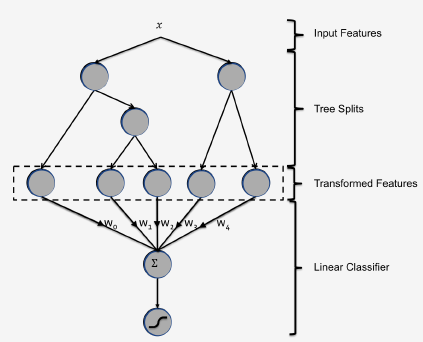
而使用GBDT能作为一种很好的feature transformation的工具,我们可以把GBDT中的每棵树作为一种类别的feature,把一个instance经过GBDT的流程(即从根节点一直往下分叉到一个特定的叶子节点)作为一个instance的特征组合的过程。这里GBDT采用的是Gradient Boosting Machine + L2-TreeBoost算法。这里是本篇paper的重点部分,放一张经典的原图:
3.2 Data freshness
CTR预估系统是在一个动态的环境中,数据的分布随时在变化,所以本文探讨了data freshness对预测效果的影响,表明training data的日期越靠近,效果越好。
3.3 Online linear classifier
探讨了对SGD-based LR中learning rate的选择。最好的选择为:
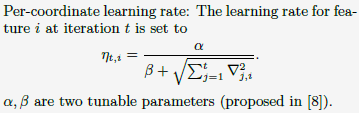
1)global效果差的原因:每个维度上训练样本的不平衡,每个训练样本拥有不同的feature。那些拥有样本数较少的维度的learning rate下降过快,导致无法收敛到最优值。
2)per weight差的原因:虽然对于各个维度有所区分,但是其对于各个维度的learning rate下降速度都太快了,训练过早结束,无法收敛到最优值。
SGD-based LR vs BOPR
1)SGD-based LR对比BOPR的优势:
1-1)模型参数少,内存占用少。SGD-based LR每个维度只有一个weight值,而BOPR每个维度有1个均值 + 1个方差值。
1-2)计算速度快。SGD-LR只需1次内积计算,BOPR需要2次内积计算。
2)BOPR对比SGD-based LR的优势:
2-1)BOPR可以得到完整的预测点击概率分布。
4 ONLINE DATA JOINER
Online Data Joiner主要是用于在线的将label与相应的features进行join。同时作者也介绍了正负样本的选取方式,以及选取负样本时候的waiting time window的选择。
5 CONTAINING MEMORY AND LATENCY
作者探讨了GBDT中tree的个数,各种类型的features(包括contextual features和historical features),对预测效果的影响。结论如下:
1)NE的下降基本来自于前500棵树。
2)最后1000棵树对NE的降低贡献低于0.1%。
3)Submodel 2 过拟合,数据量较少,只有其余2个模型的约四分之一。
4)Importance为feature带来的累积信息增益 / 平方差的减少
5)Top 10 features贡献了将近一半的importance
6)最后的300个features的贡献不足1%
6 COPYING WITH MASSIVE TRANING DATA
作者探讨了如何进行样本采样的过程,包括了均匀采样(Uniform subsampling),和负样本降采样(Negative down sampling),以及对预测效果的影响。
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
Practical Lessons from Predicting Clicks on Ads at Facebook的更多相关文章
- Practical Lessons from Predicting Clicks on Ads at Facebook (2014)论文阅读
文章链接: https://quinonero.net/Publications/predicting-clicks-facebook.pdf abstract Facebook日活跃度7.5亿,活跃 ...
- [笔记]Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT 这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%.随后作者研究了对整体预测系统产生影响的几个因素,发现Feature+Model的贡献程度最大,而其 ...
- 广告点击率 CTR预估中GBDT与LR融合方案
http://www.cbdio.com/BigData/2015-08/27/content_3750170.htm 1.背景 CTR预估,广告点击率(Click-Through Rate Pred ...
- 利用GBDT模型构造新特征具体方法
利用GBDT模型构造新特征具体方法 数据挖掘入门与实战 公众号: datadw 实际问题中,可直接用于机器学**模型的特征往往并不多.能否从"混乱"的原始log中挖掘到有用的 ...
- ML学习分享系列(2)_计算广告小窥[中]
原作:面包包包包包包 改动:寒小阳 && 龙心尘 时间:2016年2月 出处:http://blog.csdn.net/Breada/article/details/50697030 ...
- 用深度学习(DNN)构建推荐系统 - Deep Neural Networks for YouTube Recommendations论文精读
虽然国内必须FQ才能登录YouTube,但想必大家都知道这个网站.基本上算是世界范围内视频领域的最大的网站了,坐拥10亿量级的用户,网站内的视频推荐自然是一个非常重要的功能.本文就focus在YouT ...
- GBDT原理及利用GBDT构造新的特征-Python实现
1. 背景 1.1 Gradient Boosting Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向.损失函数是 ...
- 机器学习算法GBDT
http://www-personal.umich.edu/~jizhu/jizhu/wuke/Friedman-AoS01.pdf https://www.cnblogs.com/bentuwuyi ...
- 主流CTR预估模型的演化及对比
https://zhuanlan.zhihu.com/p/35465875 学习和预测用户的反馈对于个性化推荐.信息检索和在线广告等领域都有着极其重要的作用.在这些领域,用户的反馈行为包括点击.收藏. ...
随机推荐
- java中获取两个时间中的每一天
引入下面方法即可: /** * 获取两个时间中的每一天 * @param bigtimeStr 开始时间 yyyy-MM-dd * @param endTimeStr 结束时间 yyyy-MM-dd ...
- GPRS模块在Linux平台上ppp拨号上网总结与心得
linux平台的ppp拨号上网,(注明:这里只谈命令行拨号,用linux就要习惯和熟练使用命令行) 在网上常见的有三种方式:1.使用智能的ppp拨号软件wvdial:参考案例:本博客的<使用wv ...
- 删除JS 对象属性(元素)
var a={"id":1,"name":"danlis"}; //添加属性 a.age=18; console.log(a); //结果: ...
- Eclipse 左侧树形展示字体调节
eclipse中项目导航字体大小由配置文件中的设置决定 1.配置文件:找到eclipse安装位置(或解压路径): eclipse\plugins\org.eclipse.ui.themes_1.2.0 ...
- Excel条件格式
任务需求,将Excel中年龄为90后出生的人员筛选出来,并将重复的人员数据删除. 一.Excel去重 选中表格数据->数据->删除重复值 此时弹出对话框,选择去重列. 点击确定即可. 二. ...
- CentOS7.X中设置nginx和php-fpm的开机自启动
一.设置nginx的开机自启动方法 1.在/etc/init.d/目录下创建nginx文件 vi /etc/init.d/nginx 编写内容如下: #!/bin/sh # # nginx - thi ...
- webStorm的使用
最近要写点前端的东西,ideaCE版对js支持不好,写着很蛋疼,于是乎尝试了网上很流行的前端webstorm,但是在加载库文件时总是出错. 源文件:<script src="/jque ...
- string find_last_of 用法
int find_first_of(char c, int start = 0): 查找字符串中第1个出现的c,由位置start开始. 如果有匹配, ...
- Gym 101981K - Kangaroo Puzzle - [玄学][2018-2019 ACM-ICPC Asia Nanjing Regional Contest Problem K]
题目链接:http://codeforces.com/gym/101981/problem/K Your friend has made a computer video game called “K ...
- 黏包:传输过程中 read(不可靠)传输时由于网络造成黏包
但是你在读取本地文件 不涉及传输文件时 read还是可靠的