Bayesian Personalized Ranking 算法解析及Python实现
1. Learning to Rank
1.1 什么是排序算法
为什么google搜索 ”idiot“ 后,会出现特朗普的照片?

“我们已经爬取和存储了数十亿的网页拷贝在我们相应的索引位置。因此,你输入一个关键字,我们将关键词与网页进行匹配,并根据200多个因子对其进行排名,这些因子包括相关性、新鲜度、流行度、PageRank值、查询和文档匹配的单词个数、网页URL链接地址长度以及其他人对排序结果的满意度等。在此基础上,在任何给定的时间,我们尝试为该查询排序并找到最佳结果。”
—— GoogleCEO: 桑达尔·皮查伊
1.2 排序算法的发展
1.2.1 早期排序技术
最早主要是利用词频、逆文档频率和文档长度这几个因子来人工拟合排序公式。因为考虑因素不多,由人工进行公式拟合是完全可行的,此时机器学习并不能派上很大用场,因为机器学习更适合采用很多特征来进行公式拟合。此外,对于有监督机器学习来说,首先需要大量的训练数据,在此基础上才可能自动学习排序模型,单靠人工标注大量的训练数据不太现实。
1.2.2 基于机器学习的排序技术
对于搜索引擎来说,尽管无法靠人工来标注大量训练数据,但是用户点击记录是可以当做机器学习方法训练数据的一个替代品,比如用户发出一个查询,搜索引擎返回搜索结果,用户会点击其中某些网页,可以假设用户点击的网页是和用户查询更加相关的页面。
1.3 Learning to Rank(LTR)
机器学习排序系统由4个步骤组成:
- 人工标注训练数据
- 文档特征抽取
- 学习分类函数
- 在实际搜索系统中采用机器学习模型

2. PointWise Approach
定义:单文档方法的处理对象是单独的一篇文档,将文档转换为特征向量后,机器学习系统根据从训练数据中学习到的分类或者回归函数对文档打分,打分结果即是搜索结果。

Score(Q, D)=a×CS+b×PM+c×PR+d
对于某个新的查询Q和文档D,系统首先获得其文档D对应的3个特征的特征值,之后利用学习到的参数组合计算两者得分,当得分大于设定的阈值,即可判断文档是相关文档,否则判断为不相关文档。
3. PairWise Approach

对于左、右两张图,按照pointwise的思想,则认为这两条样本 i 和 j 都被点击,因此label都是1。但在右图包含更重要的信息 :用户只点了红框内的酒店,而没有点黄框内的酒店(右图黄框内的酒店和左图点击红框的酒店一致)。这说明样本 j 的 label应该比样本 i 的label大(样本 j 排名比样本 i 更靠前),很显然,pointwise并没有利用到这个信息。
对于搜索任务来说,系统接收到用户查询后,返回相关文档列表,所以问题的关键是确定文档之间的先后顺序关系。
单文档方法(PointWise Approach)完全从单个文档的分类得分角度计算,没有考虑文档之间的顺序关系。
文档对方法(PairWise Approach)则将重点转向了对文档顺序关系是否合理进行判断。之所以被称为文档对方法,是因为这种机器学习方法的训练过程和训练目标,是判断任意两个文档组成的文档对<Doc1,Doc2>是否满足顺序关系,即判断是否Doc1应该排在Doc2的前面。

根据转换后的训练实例,就可以利用机器学习方法进行分类函数的学习: 输入一个查询和文档对<Doc1,Doc2>,机器学习排序能够判断这种顺序关系是否成立,如果成立,那么在搜索结果中Doc1应该排在Doc2前面,否则Doc2应该排在Doc1前面。通过这种方式,就完成搜索结果的排序任务。
- 文档对方法(PairWise Approach)只考虑了两个文档对的相对先后顺序,却没有考虑文档出现在搜索列表中的位置。排在搜索结果前列的文档更为重要,如果前列文档出现判断错误,代价明显高于排在后面的文档。
- 不同的查询,其相关文档数量差异很大,所以转换为只有十几个对应的文档对,这对机器学习系统的效果评价造成困难。
4. ListWise Approach
1. 单文档方法(PointWise Approach)将训练集里每一个文档当做一个训练实例。
2. 文档对方法(PairWise Approach)将同一个查询的搜索结果里任意两个文档对作为一个训练实例。
3. 文档列表方法(ListWise Approach)与上述两种表示方式不同,是将每一个查询对应的所有搜索结果列表整体作为一个训练实例,这也是为何称之为文档列表方法的原因。
4. 文档列表方法根据K个训练实例(一个查询及其对应的所有搜索结果评分作为一个实例)训练得到最优评分函数F。对于一个新的用户查询,函数F对每一个文档打分,之后按照得分顺序由高到低排序,就是对应的搜索结果。
对于某个评分函数 f 来说,对3个搜索结果文档的相关性打分,得到3个不同的相关度得分F(A)、 F(B)和F(C),根据这3个得分就可以计算6种排列组合情况各自的概率值。不同的评分函数,其6种搜索结果排列组合的概率分布是不一样的。所以可以通过不同的评分函数分布与实际分布比较得出最优的那个评分函数作为排序模型。如何判断 h 和 f 与虚拟的最优评分函数 g 更接近?一般可以用两个分布概率之间的距离远近来度量这种相似性,比如 KL散度等。

5. Bayesian Personalized Ranking
5.1 BPR介绍
- 在推荐系统中,分为召回和排序两个阶段。
贝叶斯个性化排序属于Pairwise Approach。
BPR算法的五个核心知识点:
- 每个⽤户之间的偏好⾏为相互独⽴
- 同⼀⽤户对不同物品的偏序,即排序关系相互独⽴
- 表⽰⽤户u对 I 的偏好⼤于对 j 的偏好
- 满⾜完整性,反对称性和传递性
- 采用最⼤后验估计计算参数
其中,完整性,反对称性和传递性的定义如下:

5.2 BPR参数
在推荐系统中,排序算法通常完成对候选商品的二次筛选,也叫Reranking。这里的BPR算法借鉴了召回步骤中协同过滤算法的思想: 矩阵分解 。
对于用户u:

对于所有用户:

其中用户矩阵W:
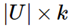
物品矩阵H:

5.3 BPR参数计算方法
BPR算法采用的是最大化后验概率来估计参数(关于什么是最大化后验概率,可移步我的另外一篇文章:似然与概率的异同),因此,这里用到了贝叶斯公式。

之前已经假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以:
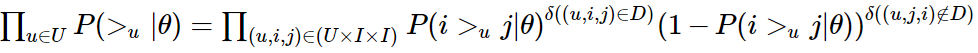
δ(b)函数返回1 如果条件b成立, 否则返回0。D为训练集, (u,i,j) 表示关系,即相对于j,用户u更喜欢 i 。
由于 满足完整性和反对称性,所以上式可简化为:
满足完整性和反对称性,所以上式可简化为:

其中,δ()为sigmod函数,用户 u 相比于 j 更喜欢 i 通过借助用户 u 对 i 的喜欢程度与对 j 的喜欢程度的差进行度量。
因此, 可表示为:
可表示为:

目标是求解θ。 由于采用最大后验估计来学习参数,所以假设θ服从正态分布:

根据概率密度函数,求得:

关于这个等式的推导,笔者尝试将概率分布带入到概率密度函数中,发现并不能推导出来,但是由于存在正比关系,所以可以近似等于。
所以,最终的后验概率估计函数为:

通过最大化这个函数,可以求出参数W和H。
6. Bayesian Personalized Ranking算法实现
网上开源的BPR代码有很多,这里着重表达一下用户embedding矩阵和物品embedding矩阵,以及损失函数的构造。其中损失函数为最小化上一小节的最大后验概率函数。


7. 总结
回顾Bayesian Personalized Ranking 算法,有以下三点值得回味:
1. θ的正态分布(先验)形式:
之所以这样设计,笔者以为有两点:一是方便取对数、二是能与正则化联系起来。
2. 用户 u 相比于 j 更喜欢 i 通过借助用户 u 对 i 的喜欢程度与对 j 的喜欢程度的差进行度量。这当然是最直观的表示方法,当然也可以加以改进。
3. 万物皆可embedding !通过对用户以及物品分别构造embedding向量,从而完成用户对物品喜好程度的计算。
Bayesian Personalized Ranking 算法解析及Python实现的更多相关文章
- 【RS】RankMBPR:Rank-Aware Mutual Bayesian Personalized Ranking for Item Recommendation - RankMBPR:基于排序感知的相互贝叶斯个性化排序的项目推荐
[论文标题]RankMBPR:Rank-Aware Mutual Bayesian Personalized Ranking for Item Recommendation ( WAIM 2016: ...
- 【RS】Using graded implicit feedback for bayesian personalized ranking - 使用分级隐式反馈来进行贝叶斯个性化排序
[论文标题]Using graded implicit feedback for bayesian personalized ranking (RecSys '14 recsys.ACM ) [论文 ...
- 【RS】BPR:Bayesian Personalized Ranking from Implicit Feedback - BPR:利用隐反馈的贝叶斯个性化排序
[论文标题]BPR:Bayesian Personalized Ranking from Implicit Feedback (2012,Published by ACM Press) [论文作者]S ...
- DeepFM算法解析及Python实现
1. DeepFM算法的提出 由于DeepFM算法有效的结合了因子分解机与神经网络在特征学习中的优点:同时提取到低阶组合特征与高阶组合特征,所以越来越被广泛使用. 在DeepFM中,FM算法负责对一阶 ...
- GBDT+LR算法解析及Python实现
1. GBDT + LR 是什么 本质上GBDT+LR是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题.这个方法出自于Facebook 2014年的论文 Practical L ...
- 名人问题 算法解析与Python 实现 O(n) 复杂度 (以Leetcode 277. Find the Celebrity为例)
1. 题目描述 Problem Description Leetcode 277. Find the Celebrity Suppose you are at a party with n peopl ...
- FM算法解析及Python实现
1. 什么是FM? FM即Factor Machine,因子分解机. 2. 为什么需要FM? 1.特征组合是许多机器学习建模过程中遇到的问题,如果对特征直接建模,很有可能会忽略掉特征与特征之间的关联信 ...
- BPR: Bayesian Personalized Ranking from Implicit Feedback-CoRR 2012——20160421
1.Information publication:CoRR 2012 2.What 商品推荐中常用的方法矩阵因子分解(MF),协同过滤(KNN)只考虑了用户购买的商品,文章提出利用购买与未购买的偏序 ...
- FFM算法解析及Python实现
1. 什么是FFM? 通过引入field的概念,FFM把相同性质的特征归于同一个field,相当于把FM中已经细分的feature再次进行拆分从而进行特征组合的二分类模型. 2. 为什么需要FFM? ...
随机推荐
- Android深入四大组件(八)广播的注册、发送和接收过程
前言 我们接着来学习Android四大组件中的BroadcastReceiver,广播主要就是分为注册.接收和发送过程.建议阅读此文前请先阅读Android深入理解四大组件系列的文章,知识重复的部分, ...
- Spark程序数据结构优化
场景: 1.scala中的对象:对象头是16个字节(包含指向对象的指针等源数据信息),如果对象中只有一个int的属性,则会占用20个字节,也就是说对象的源数据占用了大部分的空间,所以在封装数据的时候尽 ...
- [20171211]ora-16014 11g.txt
[20171211]ora-16014 11g.txt --//上午测试了10g下备库log_archive_dest_1参数配置VALID_FOR=(ONLINE_LOGFILES,ALL_ROLE ...
- excel中如何隐藏列和取消隐藏列
https://jingyan.baidu.com/article/148a192191dc9a4d71c3b11c.html excel如何隐藏列 1 先看下原表格是怎么样的. 2 隐藏列方法一:首 ...
- 转:IIS 应用程序池 内存 自动回收
原文地址:https://www.cnblogs.com/guohu/p/5209209.html IIS可以设置定时自动回收,默认回收是1740分钟,也就是29小时.IIS自动回收相当于服务器IIS ...
- https证书概念
https://studygolang.com/articles/10776 http://www.360doc.com/content/15/0520/10/21412_471902987.shtm ...
- owncloud 实现私有云进行多端文件同步
研究生生涯开始了,事情逐渐多了起来.都没时间写博客了... 开学实验室配了台电脑,我把主机装上了Fedora 作为我的服务器.平时有些实验室的材料,经常几个电脑一起看,使用U盘拷来拷去很是麻烦.今天重 ...
- Centos7查询开机启动项服务
问题描述: 最近安装了zabbix设置了一些开机启动服务 例如:zabbix-server.service,httpd.service,mariadb.service,或者系统的firework.se ...
- linux 报错Mysql.pid 文件不存在导致service Mysqld start 失败
Mysql.pid 文件不存在导致service Mysqld start 失败 1. 到提示报错的mysql.pid 不存在的目录下 使用 touch 命令创建mysql.pid文件. t ...
- ethereum/EIPs-100 挖矿难度计算
https://github.com/ethereum/EIPs/blob/master/EIPS/eip-100.md 创世纪区块的难度是131,072,有一个特殊的公式用来计算之后的每个块的难度. ...