用scrapy爬取亚马逊网站项目
这次爬取亚马逊网站,用到了scrapy,代理池,和中间件:
spiders里面:
# -*- coding: utf-8 -*-
import scrapy from scrapy.http.request import Request
from urllib.parse import urlencode
from ..items import AmazonItem class SpiderGoodsSpider(scrapy.Spider):
name = 'spider_goods'
allowed_domains = ['www.amazon.cn']
start_urls = ['http://www.amazon.cn/'] def __init__(self, keyword, *args, **kwargs):
super(SpiderGoodsSpider, self).__init__(*args, **kwargs)
self.keyword = keyword def start_requests(self):
url = 'https://www.amazon.cn/s/ref=nb_sb_noss_1/461-4093573-7508641?'
url += urlencode({'field-keywords': self.keyword})
print('初始url',url)
yield scrapy.Request(url=url,
callback=self.parse_index,
dont_filter=True) def parse_index(self, response):
detail_urls=response.xpath('//*[contains(@id,"result_")]/div/div[3]/div[1]/a/@href').extract() print('所有的url',detail_urls)
for detail_url in detail_urls:
yield scrapy.Request(
url=detail_url,
callback=self.parse_detail,
dont_filter=True
)
next_url = response.urljoin(response.xpath('//*[@id="pagnNextLink"]/@href').extract_first())
yield scrapy.Request(
url=next_url,
callback=self.parse_index,
dont_filter=True
) def parse_detail(self, response):
print('运行啦+++++++++++++++++')
name=response.xpath('//*[@id="productTitle"]/text()').extract_first().strip()
price=response.xpath('//*[@id="priceblock_ourprice"]/text()|//*[@id="priceblock_saleprice"]/text()').extract_first().strip()
deliver_mothod=''.join(response.xpath('//*[@id="ddmMerchantMessage"]//text()').extract())
item=AmazonItem()
item['name']=name
item['price']=price
item['delivery_mothod']=deliver_mothod
print(name,price,deliver_mothod)
return item def close(spider, reason):
print('结束啦')
spiders_goods
自己定义的url去重规则
'''
if hasattr(MydupeFilter,'from_settings'):
func=getattr(MydupeFilter,'from_settings')
obj=func()
else:
obj=MyDupeFilter()
'''
class MyDupeFilter(object):
def __init__(self):
self.visited=set() @classmethod
def from_settings(cls, settings):
return cls() def request_seen(self, request):
if request.url in self.visited:
return True
self.visited.add(request.url) def open(self): # can return deferred
pass def close(self, reason): # can return a deferred
pass def log(self, request, spider): # log that a request has been filtered
pass
cumstomdupefilter.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class AmazonItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
price = scrapy.Field()
delivery_mothod = scrapy.Field()
items
自己定义的下载中间件:里面meta是用来放代理池的
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from .proxy_handler import get_proxy,delete_proxy # class AmazonSpiderMiddleware(object):
# # Not all methods need to be defined. If a method is not defined,
# # scrapy acts as if the spider middleware does not modify the
# # passed objects.
#
# @classmethod
# def from_crawler(cls, crawler):
# # This method is used by Scrapy to create your spiders.
# s = cls()
# crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# return s
#
# def process_spider_input(self, response, spider):
# # Called for each response that goes through the spider
# # middleware and into the spider.
#
# # Should return None or raise an exception.
# return None
#
# def process_spider_output(self, response, result, spider):
# # Called with the results returned from the Spider, after
# # it has processed the response.
#
# # Must return an iterable of Request, dict or Item objects.
# for i in result:
# yield i
#
# def process_spider_exception(self, response, exception, spider):
# # Called when a spider or process_spider_input() method
# # (from other spider middleware) raises an exception.
#
# # Should return either None or an iterable of Response, dict
# # or Item objects.
# pass
#
# def process_start_requests(self, start_requests, spider):
# # Called with the start requests of the spider, and works
# # similarly to the process_spider_output() method, except
# # that it doesn’t have a response associated.
#
# # Must return only requests (not items).
# for r in start_requests:
# yield r
#
# def spider_opened(self, spider):
# spider.logger.info('Spider opened: %s' % spider.name)
#
#
# class AmazonDownloaderMiddleware(object):
# # Not all methods need to be defined. If a method is not defined,
# # scrapy acts as if the downloader middleware does not modify the
# # passed objects.
#
# @classmethod
# def from_crawler(cls, crawler):
# # This method is used by Scrapy to create your spiders.
# s = cls()
# crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# return s
#
# def process_request(self, request, spider):
# # Called for each request that goes through the downloader
# # middleware.
#
# # Must either:
# # - return None: continue processing this request
# # - or return a Response object
# # - or return a Request object
# # - or raise IgnoreRequest: process_exception() methods of
# # installed downloader middleware will be called
# return None
#
# def process_response(self, request, response, spider):
# # Called with the response returned from the downloader.
#
# # Must either;
# # - return a Response object
# # - return a Request object
# # - or raise IgnoreRequest
# return response
#
# def process_exception(self, request, exception, spider):
# # Called when a download handler or a process_request()
# # (from other downloader middleware) raises an exception.
#
# # Must either:
# # - return None: continue processing this exception
# # - return a Response object: stops process_exception() chain
# # - return a Request object: stops process_exception() chain
# pass
#
# def spider_opened(self, spider):
# spider.logger.info('Spider opened: %s' % spider.name)
class DownMiddleware(object):
def process_request(self,request,spider):
#返回值None,继续后续中间件去下载;
#返回值Response,停止process_request的执行,开始执行process_response,
#返回值Request,停止中间件的执行,直接把这Request对象,放在engine里再放到调度器里。
#返回值 raise IgonreRequest异常,停止process_request的执行,开始执行process_exception
print('下载中间件请求1')
request.meta['download_timeout'] = 10
# request.meta['proxy'] = 'https://' + get_proxy() # 加了代理 def process_response(self,request,response,spider):
#返回值有Response
# 返回值Request
# 返回值 raise
print('下载中间件返回1') return response def process_exception(self,request,exception,spider):
print('异常1')
# old_proxy=request.meta['proxy'].split('//')[-1]
# delete_proxy(old_proxy)
return None
middlewares.py
数据的持久化
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # class AmazonPipeline(object):
# def process_item(self, item, spider):
#
# return item from pymongo import MongoClient
from scrapy.exceptions import DropItem class MongoPipline(object):
def __init__(self, db, collection, host, pwd, port, user):
self.db = db
self.collection = collection
self.host = host
self.pwd = pwd
self.port = port
self.user = user @classmethod
def from_crawler(cls, crawler):
db = crawler.settings.get('DB')
collection = crawler.settings.get('COLLECTION')
host = crawler.settings.get('HOST')
pwd = crawler.settings.get('PWD')
port = crawler.settings.getint('PORT')
user = crawler.settings.get('USER')
return cls(db, collection, host, pwd, port, user) def open_spider(self, spider):
print(12311111111111111111111111111111)
self.client = MongoClient("mongodb://%s:%s@%s:%s" % (
self.user,
self.pwd,
self.host,
self.port
)) def close_spider(self, spider):
'''关闭爬虫'''
self.client.close() def process_item(self, item, spider):
d=dict(item)
print('保存数据',d)
if all(d.values()):
self.client[self.db][self.collection].save()
return item
pipelines.py
代理池的:
import requests def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").text def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
proxy_handler.py
settings里面的代码:
# -*- coding: utf-8 -*- # Scrapy settings for Amazon project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html DB='amazon'
COLLECTION='goods'
HOST='localhost'
PORT=27017
USER='root'
PWD='' BOT_NAME = 'Amazon' SPIDER_MODULES = ['Amazon.spiders']
NEWSPIDER_MODULE = 'Amazon.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Amazon (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'Amazon.middlewares.AmazonSpiderMiddleware': 543,
# } # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'Amazon.middlewares.DownMiddleware': 200,
# } # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'Amazon.pipelines.AmazonPipeline': 300,
'Amazon.pipelines.MongoPipline': 300,
} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
DUPEFILTER_CLASS = 'Amazon.cumstomdupefilter.MyDupeFilter'
关于下载中间件:
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response #如果返回的是response,就不走下一个requeest直接从最后一个response返回来了
Request对象,停止中间件的执行,将Request重新调度器#如果返回的是Request对象那就直接到engine,发给调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
代理池的使用:
从github上下载一个代理池的项目:
找到requirements.txt这个文件,看需要哪些配置项:

然后下载
需要更发里面的代码有:
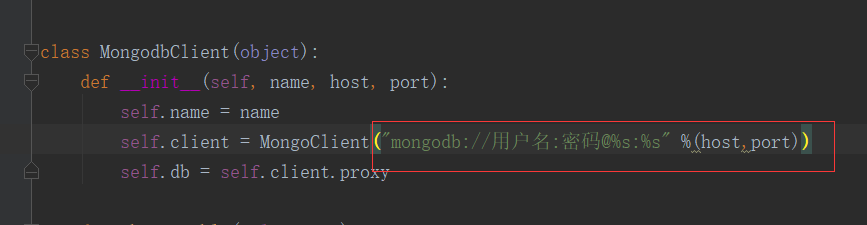
用的是MongoDB的数据库:需要你的用户名,密码,主机名,以及端口号。
在运行爬虫项目之前先运行这个代理池文件:

有了代理后,才有代理可以用来爬取东西.
用scrapy爬取亚马逊网站项目的更多相关文章
- JAVA爬取亚马逊的商品信息
在程序里面输入你想爬取的商品名字,就可以返回这件商品在亚马逊搜索中都所有相关商品的信息,包括名字和价格. 解决了在爬取亚马逊时候,亚马逊可以识别出你的爬虫,并返回503,造成只能爬取几个页面的问题. ...
- 如何使用代理IP进行数据抓取,PHP爬虫抓取亚马逊商品数据
什么是代理?什么情况下会用到代理IP? 代理服务器(Proxy Server),其功能就是代用户去取得网络信息,然后返回给用户.形象的说:它是网络信息的中转站.通过代理IP访问目标站,可以隐藏用户的真 ...
- Python3.6+Scrapy爬取知名技术文章网站
爬取分析 伯乐在线已经提供了所有文章的接口,还有下一页的接口,所有我们可以直接爬取一页,再翻页爬. 环境搭建 Windows下安装Python: http://www.cnblogs.com/0bug ...
- 爬虫框架之Scrapy——爬取某招聘信息网站
案例1:爬取内容存储为一个文件 1.建立项目 C:\pythonStudy\ScrapyProject>scrapy startproject tenCent New Scrapy projec ...
- 第4章 scrapy爬取知名技术文章网站(2)
4-8~9 编写spider爬取jobbole的所有文章 # -*- coding: utf-8 -*- import re import scrapy import datetime from sc ...
- 第4章 scrapy爬取知名技术文章网站(1)
4-1 scrapy安装以及目录结构介绍 安装scrapy可以看我另外一篇博文:Scrapy的安装--------Windows.linux.mac等操作平台,现在是在虚拟环境中安装可能有不同. 1. ...
- 亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.亚马逊商品页面链接地址(本次要爬取的页面url) https://www.amazon.cn/dp/B07BSLQ65P/ 2.代码部分 import requestsurl = "ht ...
- python requests库网页爬取小实例:亚马逊商品页面的爬取
由于直接通过requests.get()方法去爬取网页,它的头部信息的user-agent显示的是python-requests/2.21.0,所以亚马逊网站可能会拒绝访问.所以我们要更改访问的头部信 ...
- 最新亚马逊 Coupons 功能设置教程完整攻略!
最新亚马逊 Coupons 功能设置教程完整攻略! http://m.cifnews.com/app/postsinfo/18479 亚马逊总是有新的创意,新的功能.最近讨论很火的,就是这个 Coup ...
随机推荐
- 搭建jenkins集群
搭建jenkins集群是为了解决单点服务器存在的性能瓶颈,也有业务的需要,比如:java服务打包的环境我们需要linux,ios打包的服务器需要mac机. 一.创建agent节点 1.打开 系统管理- ...
- Apache RocketMQ在linux上的常用命令
Apache RocketMQ在linux上的常用命令 进入maven安装后的rocketmq的bin目录 1.启动Name Server 2.启动Broker 3.关闭Name Server 4 ...
- CentOS安装Subversion 1.9.*版本客户端
安装yum仓库 以下以CentOS6为例,其他类似 # vim /etc/yum.repos.d/wandisco-svn.rep [WandiscoSVN] name=Wandisco SVN Re ...
- EXISTS 执行顺序
select * from a where a.s_status=1 and exists (select orderid from b where a.orderid=b.orderid) exis ...
- Redis的五种数据类型的简单介绍和使用
1.准备工作: 1.1在Linux下安装Redis https://www.cnblogs.com/dddyyy/p/9763098.html 1.2启动Redis 先把root/redis的red ...
- 列表中文字太多 溢出使用省略号css方法
我们经常会遇到文字太多,而为了不打破原有布局,需要将多出文字用省略号代替,实现以下效果: 文字太太太太多多多啦...... 这个不多. html:这是个列表.ul/ol都行. <ul> & ...
- windows下navicate for mysql 零填充不显示
在mysql数据库中我们在需要某个字段时经常要用到零填充 zerofill,之前碰到了一个大坑,在数据表sql语句中明明规定了 unsigned zerofill:但是一直没有显示出来,以为自己写的s ...
- [工作总结]jQuery在工作开发中常用代码片段集锦(1-10)
1.jQuery,JS实现tab切换 原生JS实现 HTML代码如下: <div class="wrap"> <ul id="tag"> ...
- 【代码笔记】Web-HTML-表格
一,效果图. 二,代码. <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- 【读书笔记】iOS-移动开发
一,iPhone 为iPhone编写基于Web的应用程序非常简单.Safari Web浏览器是一款很优秀的工具-它能够完美地对基于Web的应用程序进行缩放,以便在iPhone大小的屏幕上运行.Safa ...