OLAP了解与OLAP引擎——Mondrian入门
一、 OLAP的基本概念
OLAP(On-Line Analysis Processing)在线分析处理是一种共享多维信息的快速分析技术;OLAP利用多维数据库技术使用户从不同角度观察数据;OLAP用于支持复杂的分析操作,侧重于对管理人员的决策支持,可以满足分析人员快速、灵活地进行大数据复量的复杂查询的要求,并且以一种直观、易懂的形式呈现查询结果,辅助决策。
二、 OLAP的基本内容
(1)变量(度量)
变量是数据度量的指标,是数据的实际意义,即描述数据“是什么”。像示例中的人数。
(2)维度
维度是描述与业务主题相关的一组属性,单个属性或属性集合可以构成一个维。如示例中的学历、民族、性别等都是维度。
(3)维的层次
一个维往往可以具有多个层次,例如时间维度分为年、季度、月和日等层次,地区维可以是国家、地区、省、市等层次。这里的层次表示数据细化程度,对应概念分层。后面介绍的上钻操作就是由低层概念映射到高层概念。概念分层可除根据概念的全序和偏序关系确定外,还可以通过对数据进行离散化和分组实现。
(4)维的成员
若维是多层次的,则不同的层次的取值构成一个维成员。部分维层次同样可以构成维成员,例如“某年某季度”、“某季某月”等都可以是时间维的成员。
(5)多维数组
多维数组用维和度量的组合表示。一个多维数组可以表示为(维1,维2,……,维n,变量),例如(部门,职系、民族、性别,人数)组成一个多维数组。
(6)数据单元(单元格)
多维数组的取值。当多维数组中每个维都有确定的取值时,就唯一确定一个变量的值。数据单元可以表示为(维1成员,维2成员,……,维N成员,变量的值),例如(人事教育部,技能,回族,男,1人)表示一个数据单元,表示人事教育部职系是技能的回族男性有1人。
(7)事实
事实是不同维度在某一取值下的度量,例如上述人事教育部职系是技能的回族男性有1人就表示在部门、职系、民族、性别四个维度上企业人数的事实度量,并且在为人数事实中包含部门维度人事教育部这一个维度层次,如果将人数事实的所有维度考虑在内,就构成有关人数的多维分析立方体。
三、 OLAP的特点
电子数据表与OLAP相比,不具备OLAP的多维性、层次、维度计算以及结构与视图分离等特点。
1.快速。终端用户对于系统的快速响应有很高的要求。调查表明如果用户在30秒内得不到回应,就会变得不耐烦。因此OLAP平台彩用了多种技术提高响应速度,例如专门的数据存储格式、大量的预处理和特殊的硬件设计等,通过减小在线分析处理的动态计算,事先存储OLAP所需粒度的数据等主要手段来获得OLAP响应速度的提高,尽管如此,查询反应慢仍然是OLAP产品中经常被提及的问题。
2.可分析。用户可以应用OLAP平台分析数据,也可以使用其他外部分析工具,例如电子数据表,这些分析工具基本上都以直观的方式为用户提供了分析功能。
3.共享。由于人们认为OLAP是只读的,仅需要简单的安全管理,导致目前许多OLAP产品在安全共享方面还存在许多问题。因此当多个用户访问OLAP服务器时,系统就在适当的粒度上加锁。
4.多维。维是OLAP的核心概念,多维性是OLAP的关键属性,这与数据仓库的多维数据组织正好相互补充。为了使用户能够从多个维度、多个数据粒度查看数据,了解数据蕴含的信息,系统需要提供对数据的多维分析功能,包括切片、旋转和钻取等多种操作
四、 OLAP的操作
OLAP比较常用的操作包括对多维数据的切片与切块、上钻(drill-up)与下钻(drill-down)以下旋转(rotate)等。此外,OLAP还能对多维数据进行深加工。OALP的这些操作使用户能够从多个视角观察数据,并以图形、报表等多种形式展示,从而获取隐藏在数据中的信息。
(1)切片与切块。
选定多维数组的一个维成员做数据分割的操作称为该维上的一个切片。通常把多维数组中选定一个二维子集的操作视为切片,假设选定的维i上的某个维成员Vi,则此多维数组子集可以定义为(维V1……,维Vi,维N,变量)。当某维只取一个维成员时,便得到一个切片,而切块则是某一维取值范围下的多个切片的叠合。通过对数据立方体的切片或切块分割,可以从不同的视角得到各种数据。
(2)钻取
钻取包括上钻和下钻。争取能够帮助用户获得更多的细节性数据,逐层的分析问题的所在和原因。
- §
上钻又称为上卷(roll-up)。上钻操作是指通过一个维的概念分层向上攀升或者通过维归约在数据立方体上进行数据汇总。例如在上面的示例中,可以按学历汇总数据,如把各种学历的都归约为所有学历,便可以得到沿学历维上钻的数据汇总。 - §
下钻是上钻的逆操作,通过对某一汇总数据进行维层次的细分(沿维的概念分层向下)分析数据。下钻使用用户对数据能够获得更深入的了解,更容易发现问题本质,从而做出正确的决策。 - §
钻取使用户不会再被海量的数据搞得晕头转向:上钻让用户站在更高层次观察数据,下钻则可以细化到用户所判决的详细数据。钻取的尝试与维度与维所划分的层次相对应,根据用户关心的数据粒度合理划分。
(3)旋转
旋转又称转轴,是一种视图操作,通过旋转变换一个报告或页面显示的维度方向,在表格中重新安排维的位置,例如行列转换。这种对立方体的重定位可以得到不同视角的信息。
(4)其他OLAP操作
除以上常用多维操作外,还有其他多维操作。
- §
钻过(drill-across)。钻过操作涉及多个事实表的查询并把结果合并为单个数据集,一个典型的例子就是预测数据与当前数据的结合:通常预测数据与当前数据存在于不同的表中,当用户比较预测销售与当月销售时,需要跨多个事实表查询。 - §
钻透(drill-through)。钻透使用关系SQL,查询数据立方体的底层,一直到后羰的关系表。
五、 OLAP的分类
OLAP的分类,如下图所示
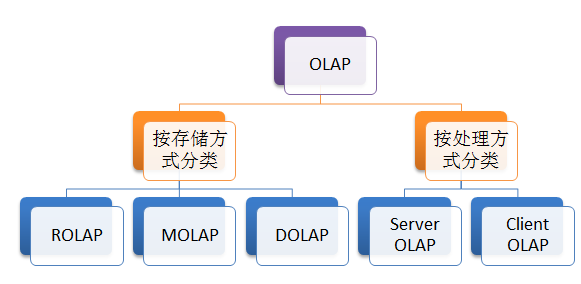
按处理方式分类
- §
Server OLAP:绝大多数的OLAP系统都属于此类,Server OLAP在服务端的数据库上建立多维数据立方体,由服务端提供多维分析,并把最终结果呈现给用户 - §
Client OLAP:所相关立方体数据下载一本地,由本地为用户提供多维分析,从而保证在网络故障时仍然能正常工作。
按存储方式分类
- §
ROLAP。ROLAP使用关系数据库或扩充关系数据库(XRDBMS)存储管理数据仓库,以关系表存储多维数据,有较强的可伸缩性。其中维数据存储在维表中,而事实数据和维ID则存储在事实表中,维表和事实表通过主外键关联。 - §
MOLAP。MOLAP支持数据的多维视图,采用多维数据组存储数据,它把维映射到多维数组的下标或下标的范围,而事实数据存储在数组单元中,从而实现了多维视图到数组的映射,形成了立方体的结构。大容量的数据使立方体稀疏化,此时需要稀疏矩阵压缩技术处理,由于MOLAP是从物理上实现,故又称为物理OLAP(Physical OLAP)。 - §
DOLAP。DOLAP是属于单层架构,它是基于桌面的客户端OLAP,主要特点是由服务器生成请求数据相关的立方体并下载到本地,由本地提供数据结构与报表格式重组,为用户提供多维分析,此时无需任何的网络连接,灵活的存储方式方便了移动用户的需求,但支持数据有限,使用范围有限。
一、 Mondrian简介
Mondrian是一个开源项目。一个用Java写成的OLAP引擎。它用MDX语言实现查询,从关系数据库(RDBMS)中读取数据。然后经过java API以多维的方式对结果进行展示。
Mondrian的使用方式同JDBC驱动类似。可以非常方便的与现有的Web项目集成
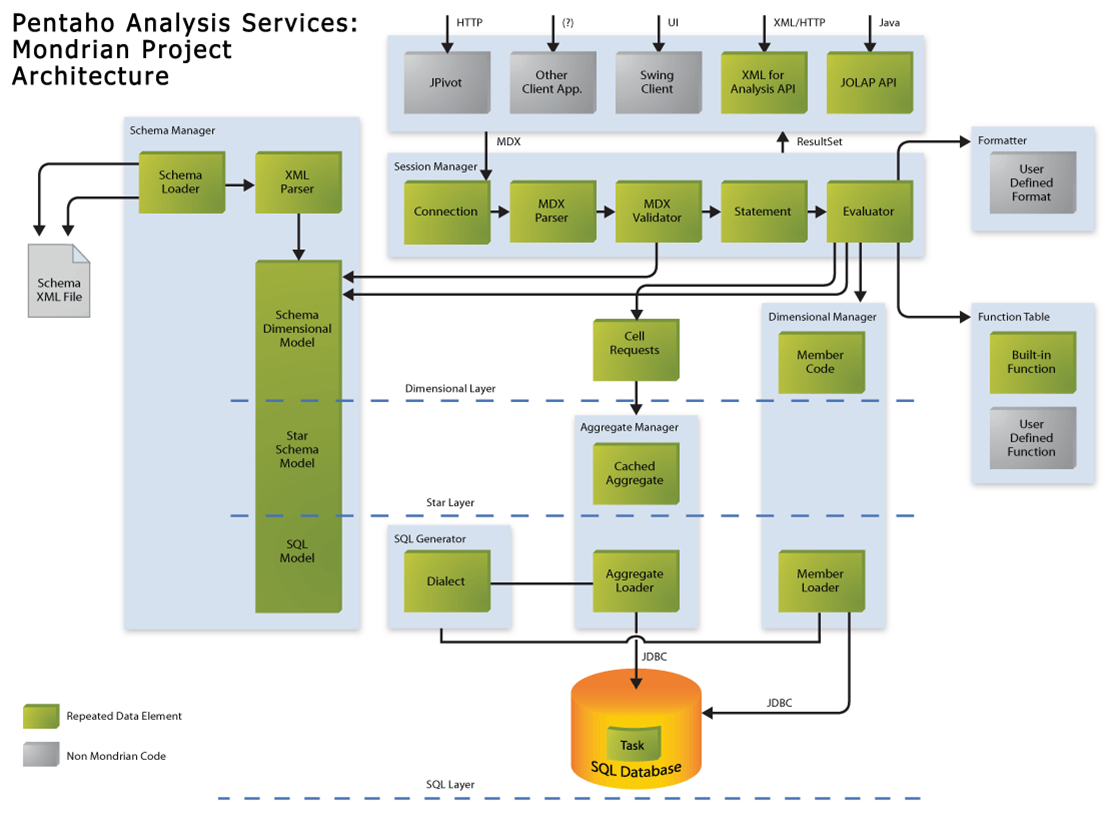
1.1 Mondrian的体系结构(Architecture)
Mondrian
OLAP 系统由四个层组成;
从最终用户到数据中心,
顺序为:
1.1.1 表现层(the
presentation layer)
1.1.2 维度层(the
dimensional layer)
1.1.3 集合层(the
star layer)
1.1.4 存储层(the
storage layer)
结构图如下:
1.1.1 表现层(the
presentation layer)
表现层决定了最终用户将在他们的显示器上看到什么,
及他们如何同系统产生交互。
有许多方法可以用来向用户显示多维数据集,
有 pivot 表 (一种交互式的表), pie,
line 和图表(bar
charts)。它们可以用Swing
或 JSP来实现。
表现层以多维"文法(grammar)(维、度量、单元)”的形式发出查询,然后OLAP服务器返回结果。
1.1.1.1
Jpivot表现层
JPivot
是Mondrian的表现层TagLib,一直保持着良好的开发进度。
您可以通过访问jpivot的官方网站http://jpivot.sourceforge.net/以获得更多的帮助及支持
jpivot使用XML/
XSLT渲染OLAP报表:
JPivot
使用 WCF
(Web Component Framework) ,基于XML/XSLT来渲染Web UI组件。这使它显得十分另类。不过,OLAP报表这种非常复杂但又有规律可循的东西,最适合使用XSLT来渲染。
jpivot完全基于JSP+TagLib:
JPivot另外一个可能使人不惯的地方是它完全基于taglib而不是大家熟悉的MVC模式。
但它可以很方便的将多维数据展示给最终用户,如下表格:
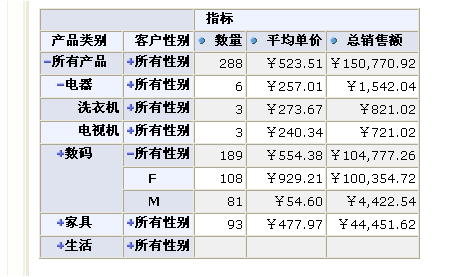
jpivot其实是一个自定义jsp的标签库。它基于XML/XSLT配置来生成相应的html。所幸的是,我们并不需要了解太多关于这方面的内容,我们只要掌握相应jsp标签的使用即可。
在本教程的实例中,我们将会对一些常用到的jpivot标签进行讲解。
您还可以通过汉化WEB-INF/jpivot下的xml文件来完成对jpivot的汉化工作
1.1.2 维度层(the
dimensional layer)
维度层用来解析、验证和执行MDX查询要求。
一个MDX查询要通过几个阶段来完成:首先是计算坐标轴(axes),再者计算坐标轴axes 中cell的值。
为了提高效率,维度层把要求查询的单元成批发送到集合层,查询转换器接受操作现有查询的请求,而不是对每个请求都建立一个MDX
声明。
1.1.3 集合层(the star
layer)
集合层负责维护和创建集合缓存,一个集合是在内存中缓存一组单元值, 这些单元值由一组维的值来确定。
维度层对这些单元发出查询请求,如果所查询的单元值不在缓存中,则集合管理器(aggregation
manager)会向存储层发出查询请求
1.1.4 存储层(the storage
layer)
存储层是一个关系型数据库(RDBMS)。它负责创建集合的单元数据,和提供维表的成员。
1.2 API
Mondrian
为客户端提供一个用于查询的API
因为到目前为止,并没有一个通用的用于OLAP查询的API,因此Mondrian提供了它私有的API.
尽管如此,一个常使用JDBC的人将同样发现它很熟悉.不同之处仅在于它使用的是MDX查询语言,而非SQL
下面的java片段展示了如何连接到Mondrian,然后执行一个查询,最后打印结果.
[java] view plaincopy
- import mondrian.olap.*;
- import java.io.PrintWriter;
- Connection connection = DriverManager.getConnection("Provider=mondrian;"
- +"Jdbc=jdbc:odbc:MondrianFoodMart;"
- +"Catalog=/WEB-INF/FoodMart.xml;",null,false);
- Query query = connection.parseQuery("SELECT {[Measures].[Unit Sales], [Measures].[Store Sales]} on columns,"
- +" {[Product].children} on rows "
- +"FROM [Sales] " +"WHERE ([Time].[1997].[Q1], [Store].[CA].[San Francisco])");
- Result result = connection.execute(query);
- 10. result.print(new PrintWriter(System.out));
与JDBC类似,一个Connection由DriverManager创建,Query 对象类似于JDBC 的Statement,它通过传递一个MDX语句来创建.Result对象类似于JDBC的ResultSet,只不过它里面保存的是多维数据
您可以通过查看Mondrian帮助文档里的javadoc来获取更多关于Mondrian
API的资料
通过上面的介绍,您应该对mondrian的体系有一个基本的了解。
Mondrian安装完成后,便可直接使用自带的Derby数据库中的数据进行测试和学习。
我们看一个最简单的MDX语句:
select
{
[Measures].[Unit Sales],
[Measures].[Store Cost],
[Measures].[Store Sales]
} ON COLUMNS,
{(
[Promotion Media].[All Media],
[Product].[All Products]
)} ON ROWS
from [Sales]
where [Time].[1997]
其中,SELECT 后跟着的是测量指和维度,[Measures]是指测量值,也就是报表中的指标,[Promotion
Media]、[Product]、[Time]是指维度,也就是我们需要挖掘的维度。我们发现,WHERE后面也是跟着维度的,代表从维度中过滤出一些数据。
FROM后面跟着的是立方体,[Sales]是我们OLAP中建立的数据立方体。
好了,我们一步步看看这个DMX语句后面配置的Schema吧,Schema这个怎么翻译好呢,我估计协议比较妥当,因为它就只是XML定义的协议。
首先,看from后跟的数据立方体,Sales
<!--
定义立方体
name 立方体名称
defaultMeasure 默认测量值
-->
<Cube name="Sales" defaultMeasure="Unit Sales">
<!-- 定义table,也就是表,使用name指定表名 -->
<Table name="sales_fact_1997">
</Table>
</Cube>
<!--
定义度量值
name 度量的名称,用于select
column 对应的表的列
aggregator 聚合函数
formatString 格式化字符串,可以格式化类似Money、时间之类的格式
-->
<Measure name="Unit Sales" column="unit_sales"
aggregator="sum" formatString="Standard"/>
<!--
定义维度
name 维度名称,用于Select
foreignKey 外键id
-->
<Dimension name="Promotion Media"
foreignKey="promotion_id">
<!--
定义维度的层次
hasAll 是否包含所有的维度
allMemberName 所有维度的名称
primaryKey 翻译表的主键
defaultMember 默认维度,可以为allMemberName
-->
<Hierarchy hasAll="true" allMemberName="All Media"
primaryKey="promotion_id" defaultMember="All Media">
<!-- 指定翻译表 -->
<Table name="promotion"/>
<!--
定义层次的水平,也就是调用维度的哪个字段来表现维度
name
-->
<Level name="Media Type" column="media_type"
uniqueMembers="true"/>
</Hierarchy>
</Dimension>
<!--
维度复用
name 维度名称,用于Select
foreignKey 外键id
source 来源,也就是参考其他立方体中的Dimension
-->
<DimensionUsage name="Product" source="Product"
foreignKey="product_id"/>
<!--
查看具体的Product维度的定义
name 维度名称,一样的使用于Select
-->
<Dimension name="Product">
<!--
定义维度的层次
hasAll 是否包含所有的维度
allMemberName 所有维度的名称
primaryKey 翻译表的主键
defaultMember 默认维度,可以为allMemberName
primaryKeyTable 主键的表名
-->
<Hierarchy hasAll="true" primaryKey="product_id"
primaryKeyTable="product">
<Join leftKey="product_class_id"
rightKey="product_class_id">
<Table name="product"/>
<Table name="product_class"/>
</Join>
<!--
第一个层次
产品的总类
name 层次的名称
table 层次的表名
column 对应的列
uniqueMembers 成员是否唯一
-->
<Level name="Product Family" table="product_class" column="product_family"
uniqueMembers="true"/>
<Level name="Product Department"
table="product_class" column="product_department"
uniqueMembers="false"/>
<Level name="Product Category"
table="product_class" column="product_category"
uniqueMembers="false"/>
<Level name="Product Subcategory"
table="product_class" column="product_subcategory"
uniqueMembers="false"/>
<Level name="Brand Name" table="product"
column="brand_name" uniqueMembers="false"/>
<Level name="Product Name" table="product"
column="product_name" uniqueMembers="true"/>
</Hierarchy>
</Dimension>
<!--
最后,学习一个where语句中的时间维度的设定
type 维度类型,这里是TimeDimension 时间维度
-->
<Dimension name="Time" type="TimeDimension">
<Hierarchy hasAll="false" primaryKey="time_id">
<Table name="time_by_day"/>
<Level name="Year" column="the_year"
type="Numeric" uniqueMembers="true"
levelType="TimeYears"/>
<Level name="Quarter" column="quarter"
uniqueMembers="false" levelType="TimeQuarters"/>
<Level name="Month" column="month_of_year"
uniqueMembers="false" type="Numeric"
levelType="TimeMonths"/>
</Hierarchy>
<Hierarchy hasAll="true" name="Weekly"
primaryKey="time_id">
<Table name="time_by_day"/>
<Level name="Year" column="the_year"
type="Numeric" uniqueMembers="true"
levelType="TimeYears"/>
<Level name="Week" column="week_of_year"
type="Numeric" uniqueMembers="false"
levelType="TimeWeeks"/>
<Level name="Day" column="day_of_month"
uniqueMembers="false" type="Numeric"
levelType="TimeDays"/>
</Hierarchy>
</Dimension>
看完以上Schema的协议定义,我们就可以把这个例子需要的协议文件最小化了,在${apache-tomcat-7.0.29}\webapps\mondrian\WEB-INF\queries\目录下新建一个XML文件TestSchema.xml,内容如下:
<?xml version="1.0"?>
<Schema name="Test">
<Dimension name="Product">
<Hierarchy hasAll="true" primaryKey="product_id"
primaryKeyTable="product">
<Join leftKey="product_class_id" rightKey="product_class_id">
<Table name="product"/>
<Table name="product_class"/>
</Join>
<Level name="Product Family" table="product_class"
column="product_family" uniqueMembers="true"/>
<Level name="Product Department"
table="product_class" column="product_department"
uniqueMembers="false"/>
<Level name="Product Category"
table="product_class" column="product_category"
uniqueMembers="false"/>
<Level name="Product Subcategory"
table="product_class" column="product_subcategory"
uniqueMembers="false"/>
<Level name="Brand Name" table="product"
column="brand_name" uniqueMembers="false"/>
<Level name="Product Name" table="product"
column="product_name" uniqueMembers="true"/>
</Hierarchy>
</Dimension>
<Dimension name="Time" type="TimeDimension">
<Hierarchy hasAll="false" primaryKey="time_id">
<Table name="time_by_day"/>
<Level name="Year" column="the_year"
type="Numeric" uniqueMembers="true"
levelType="TimeYears"/>
<Level name="Quarter" column="quarter"
uniqueMembers="false" levelType="TimeQuarters"/>
<Level name="Month" column="month_of_year"
uniqueMembers="false" type="Numeric"
levelType="TimeMonths"/>
</Hierarchy>
<Hierarchy hasAll="true" name="Weekly"
primaryKey="time_id">
<Table name="time_by_day"/>
<Level name="Year" column="the_year"
type="Numeric" uniqueMembers="true"
levelType="TimeYears"/>
<Level name="Week" column="week_of_year"
type="Numeric" uniqueMembers="false"
levelType="TimeWeeks"/>
<Level name="Day" column="day_of_month"
uniqueMembers="false" type="Numeric"
levelType="TimeDays"/>
</Hierarchy>
</Dimension>
<Cube name="Sales" defaultMeasure="Unit Sales">
<Table name="sales_fact_1997"></Table>
<DimensionUsage name="Product" source="Product"
foreignKey="product_id"/>
<DimensionUsage name="Time" source="Time"
foreignKey="time_id"/>
<Dimension name="Promotion Media"
foreignKey="promotion_id">
<Hierarchy hasAll="true" allMemberName="All Media"
primaryKey="promotion_id" defaultMember="All Media">
<Table name="promotion"/>
<Level name="Media Type" column="media_type"
uniqueMembers="true"/>
</Hierarchy>
</Dimension>
<Measure name="Unit Sales" column="unit_sales"
aggregator="sum" formatString="Standard"/>
<Measure name="Store Cost" column="store_cost"
aggregator="sum" formatString="#,###.00"/>
<Measure name="Store Sales" column="store_sales"
aggregator="sum" formatString="#,###.00"/>
</Cube>
</Schema>
1.3 下载与发布
下载地址:https://sourceforge.net/projects/mondrian/?source=typ_redirect
点击files 里面有Mondrian的各种版本,其中mondrian-3.14.0是最新版本,mondrian-3.12.0是稳定版本。下载完成后就其解压,有2种部署方法。
第一种方法:在解压后的文件中找到lib,打开里面有一个mondrian.war文件,将其直接扔到tomcat的webapps目录下,然后启动Tomcat,自动解压。打开浏览器输入localhost:8080/mondrian
出现欢迎界面说明部署成功。
第一种方法:利用常用的ida开发工具。本次使用的是eclipse。
打开eclipse新建一个Dynamic Web
Project

取名为Tezz,注意要勾上自动生成web.xml
选项

然后添加必须的文件
将下载的压缩包进行解压。完成后,进入文件夹可以看到如下目录结构。双击进入lib文件夹。
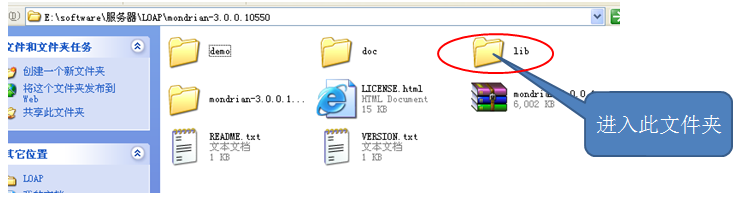
Lib文件夹有如下内容:注意到这里的mondrian.war文件是一个可直接布署的项目,我们需要将它解压,然后从中取出我们所需要的文件。(建议将其扩展名改成zip,然后直接右键解压)

进入解压后的文件夹,选中jpivot、wcf二个文件夹及busy.jsp、error.jsp、testpage.jsp三个文件,我们需要将这些资源复制到我们测试项目的WebRoot文件夹中。按ctrl+C键复制。
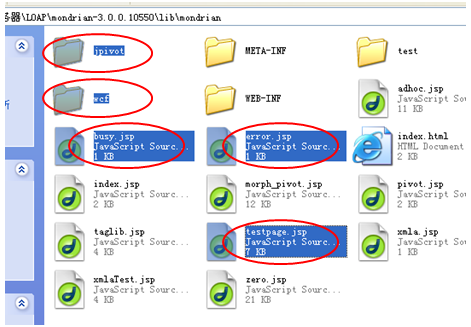
注:jpivot、wcf这两个文件夹包含mondrian使用的图像和css文件。Busy.jsp显示等待页面、error.jsp显示出错页面、testpage.jsp这文件的用处将在后面介绍。
切换到eclipse界面,在我们的Tezz项目的WebRoot文件夹处右击鼠标,在弹出的菜单中选择Paste(粘贴)即可
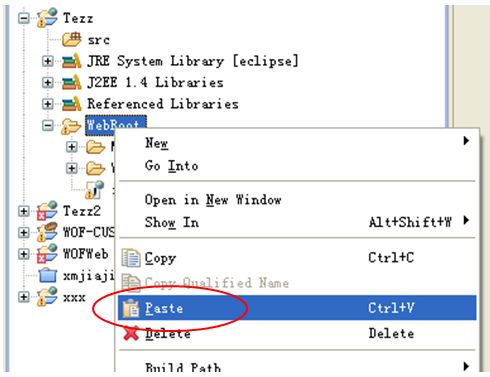
粘贴完成后的项目结构如下

注意:因为我们还未将所有资料复制到项目中,因此eclipse会显示错误图标
最后进入WEB-INF文件夹(在上面步骤中解压的项目文件mondrian.war里),选中jpivot、lib、wcf这三个文件夹,同样需要复制它们到测试项目的WEB-INF文件夹中。
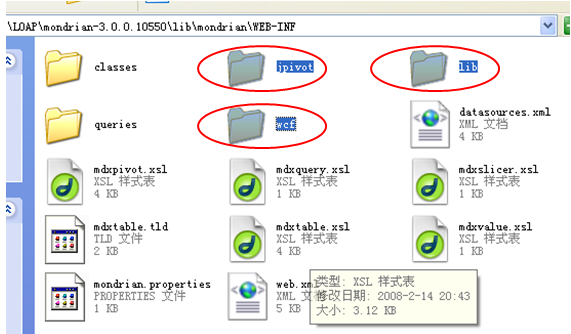
Jpivot、wcf这两个文件夹包含jpivot和wcf用于生成用户界面的配置文件(*.xml、*.xsl)及标签文件(*.tld)的定义。Lib文件夹包含的是mondrian所要用的java包。
切换到eclipse界面,在我们的Tezz项目的WebRoot文件夹处右击鼠标,在弹出的菜单中选择Paste(粘贴)
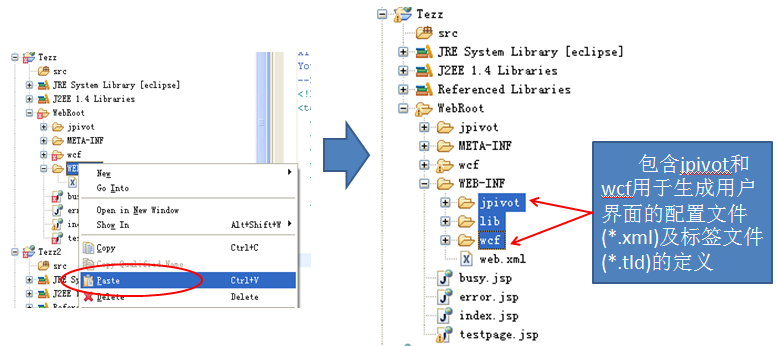
至此Mondrian的支持添加完毕,下面我们将配置web.xml,让我们的项目能够使用到mondrian的功能。
接下来我们需要配置的是web.xml
过滤器(filter)
复制如下所示的xml代码到我们测试项目Tezz的web.xml文件中。
作用:这个过滤器在访问/testpage.jsp前被调用。它被设计成jpivot的前端控制器,用于判断并将用户的请求发送到某个页面。
注:在实际项目中可以使用您自己定义的servlet或使用其他技术来替代它以提供更多的功能
- <filter>
- <filter-name>JPivotController</filter-name>
- <filter-class>com.tonbeller.wcf.controller.RequestFilter</filter-class>
- <init-param>
- <param-name>indexJSP</param-name>
- <param-value>/index.html</param-value>
- <description>如果这是一个新的会话,则转到此页面</description>
- </init-param>
- <init-param>
- 10. <param-name>errorJSP</param-name>
- 11. <param-value>/error.jsp</param-value>
- 12. <description>出错时显示的页面</description>
- 13. </init-param>
- 14. <init-param>
- 15. <param-name>busyJSP</param-name>
- 16. <param-value>/busy.jsp</param-value>
- 17. <description>这个页面用于当用户点击一个查询时,在这个查询还未将结果还回给用户时所显示的界面</description>
- 18. </init-param>
19. </filter>
- 20.
- 21. <filter-mapping>
- 22. <filter-name>JPivotController</filter-name>
- 23. <url-pattern>/testpage.jsp</url-pattern>
- 24. </filter-mapping>
Print servlet,该servlet用于将数据生成Excel文件或pdf文件并返回给用户,如果您需要用到该功能,则需要将其copy到您项目的web.xml文件中
- <servlet>
- <servlet-name>Print</servlet-name>
- <display-name>Print</display-name>
- <description>Default configuration created for servlet.</description>
- <servlet-class>com.tonbeller.jpivot.print.PrintServlet</servlet-class>
- </servlet>
- <servlet-mapping>
- <servlet-name>Print</servlet-name>
- <url-pattern>/Print</url-pattern>
- 10. </servlet-mapping>
MDXQueryServlet用于接受并执行一个MDX查询,然后将该查询以Html表格的形式返回。其中的参数connectString用于指定连接到数据库的字符串,例如使用jtds驱动连接到sql server 2000的字符串如下:
Provider=mondrian;Jdbc=jdbc:jtds:sqlserver://localhost/Tezz;user=sa;password=123456;Catalog=/WEB-INF/queries/tezz.xml;JdbcDrivers=net.sourceforge.jtds.jdbc.Driver;
如果您需要用到该功能,则需要将其copy到您项目的web.xml文件中。
- <servlet>
- <servlet-name>MDXQueryServlet</servlet-name>
- <servlet-class>mondrian.web.servlet.MDXQueryServlet</servlet-class>
- <init-param>
- <param-name>connectString</param-name>
- <param-value>@mondrian.webapp.connectString@</param-value>
- </init-param>
- </servlet>
- <servlet-mapping>
- 10. <servlet-name>MDXQueryServlet</servlet-name>
- 11. <url-pattern>/mdxquery</url-pattern>
- 12. </servlet-mapping>
DisplayChart
和GetChart 这两个Servlet 用于生成图表和将其显示给最终用户,如果您需要用到该功能,则需要将其copy到您项目的web.xml文件中。
- <!-- jfreechart provided servlet -->
- <servlet>
- <servlet-name>DisplayChart</servlet-name>
- <servlet-class>org.jfree.chart.servlet.DisplayChart</servlet-class>
- </servlet>
- <!-- jfreechart provided servlet -->
- <servlet>
- <servlet-name>GetChart</servlet-name>
- <display-name>GetChart</display-name>
- 10. <description>Default configuration created for servlet.</description>
- 11. <servlet-class>com.tonbeller.jpivot.chart.GetChart</servlet-class>
- 12. </servlet>
13. <servlet-mapping>
- 14. <servlet-name>DisplayChart</servlet-name>
- 15. <url-pattern>/DisplayChart</url-pattern>
- 16. </servlet-mapping>
17. <servlet-mapping>
- 18. <servlet-name>GetChart</servlet-name>
- 19. <url-pattern>/GetChart</url-pattern>
- 20. </servlet-mapping>
最后添加以下标签库到我们的web.xml项目中即可
- <taglib>
- <taglib-uri>http://www.tonbeller.com/wcf</taglib-uri>
- <taglib-location>/WEB-INF/wcf/wcf-tags.tld</taglib-location>
- </taglib>
- <taglib>
- <taglib-uri>http://www.tonbeller.com/jpivot</taglib-uri>
- <taglib-location>/WEB-INF/jpivot/jpivot-tags.tld</taglib-location>
- </taglib>
至此,一个mondrian项目配置已经完成,下面就是写xml和jsp了
如果使用的是Myeclipse的话需新建一个Web
Project,注意需要加入JSTL支持

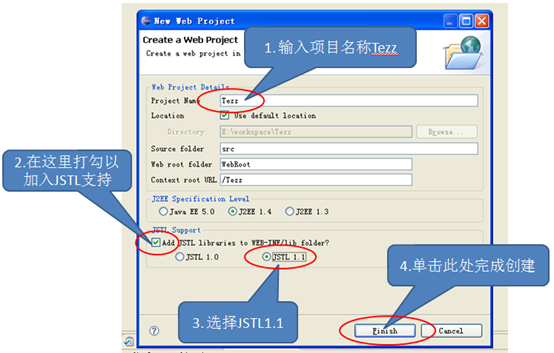
剩余步骤和在Eclipse中一样
1.4 测试用例
下面贴出一个测试用例,以及中间遇见的问题供大家参考
建表语句
/**销售表*/
create table Sale (
saleId int not null,
proId int null,
cusId int null,
unitPrice float null, --单价
number int null, --数量
constraint PK_SALE primary key (saleId)
)
/**用户表*/
create table Customer (
cusId int not null,
gender char(1) null, --性别
constraint PK_CUSTOMER primary key (cusId)
)
/**产品表*/
create table Product (
proId int not null,
proTypeId int null,
proName varchar(32) null,
constraint PK_PRODUCT primary key (proId)
)
/**产品类别表*/
create table ProductType (
proTypeId int not null,
proTypeName varchar(32) null,
constraint PK_PRODUCTTYPE primary key (proTypeId)
)
插入数据
insert into
Customer(cusId,gender) values(1,'F')
insert into
Customer(cusId,gender) values(2,'M')
insert into
Customer(cusId,gender) values(3,'M')
insert into
Customer(cusId,gender) values(4,'F')
insert into
producttype(proTypeId,proTypeName) values(1,'电器')
insert into
producttype(proTypeId,proTypeName) values(2,'数码')
insert into
producttype(proTypeId,proTypeName) values(3,'家具')
insert into
product(proId,proTypeId,proName) values(1,1,'洗衣机')
insert into
product(proId,proTypeId,proName) values(2,1,'电视机')
insert into
product(proId,proTypeId,proName) values(3,2,'mp3')
insert into
product(proId,proTypeId,proName) values(4,2,'mp4')
insert into
product(proId,proTypeId,proName) values(5,2,'数码相机')
insert into
product(proId,proTypeId,proName) values(6,3,'椅子')
insert into
product(proId,proTypeId,proName) values(7,3,'桌子')
insert into
sale(saleId,proId,cusId,unitPrice,number) values(1,1,1,340.34,2)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(2,1,2,140.34,1)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(3,2,3,240.34,3)
insert into sale(saleId,proId,cusId,unitPrice,number)
values(4,3,4,540.34,4)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(5,4,1,80.34,5)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(6,5,2,90.34,26)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(7,6,3,140.34,7)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(8,7,4,640.34,28)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(9,6,1,140.34,29)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(10,7,2,740.34,29)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(11,5,3,30.34,28)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(12,4,4,1240.34,72)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(13,3,1,314.34,27)
insert into
sale(saleId,proId,cusId,unitPrice,number) values(14,3,2,45.34,27)
建立模式(schema)文件
简单的说,配置一个模式就是配置一个关系数据结构到多维数据结构的映射。就是创建一个xml文件来实现数据库表与多维数据源的对应关系,聚合,新增字段。
在WEB-INFO目录下新建一个queries的文件夹,然后新建一个名为tse的XML文件,文件内容如下;注意Schema name 与 Cube name
<?xml version="1.0"
encoding="UTF-8"?>
<Schema name="tse">
<Cube name="Sales">
<!-- 事实表(fact table) -->
<Table
name="SALE" />
<!-- 客户维 -->
<Dimension
name="sex" foreignKey="CUSID">
<Hierarchy
hasAll="true" allMemberName="allsex"
primaryKey="CUSID">
<Table
name="CUSTOMER"></Table>
<Level
name="gender" column="GENDER"></Level>
</Hierarchy>
</Dimension>
<!-- 产品类别维 -->
<Dimension
name="good" foreignKey="PROID">
<Hierarchy
hasAll="true" allMemberName="allgood"
primaryKey="PROID" primaryKeyTable="PRODUCT">
<join
leftKey="PROTYPEID" rightKey="PROTYPEID">
<Table
name="PRODUCT" />
<Table
name="PRODUCTTYPE"></Table>
</join>
<Level
name="proTypeId" column="PROTYPEID"
nameColumn="PROTYPENAME"
uniqueMembers="true" table="PRODUCTTYPE" />
<Level
name="proId" column="PROID" nameColumn="PRONAME"
uniqueMembers="true"
table="PRODUCT" />
</Hierarchy>
</Dimension>
<Measure
name="quan1" column="NUMBER1" aggregator="sum"
datatype="Numeric" />
<Measure
name="totalsell" aggregator="sum" formatString="¥#,##0.00">
<!--
unitPrice*number所得值的列 -->
<MeasureExpression>
<SQL
dialect="generic">(UNITPRICE*NUMBER1)</SQL>
</MeasureExpression>
</Measure>
<CalculatedMember
name="avgsell" dimension="Measures">
<Formula>[Measures].[totalsell]
/ [Measures].[quan1]</Formula>
<CalculatedMemberProperty
name="FORMAT_STRING" value="¥#,##0.00"
/>
</CalculatedMember>
</Cube>
</Schema>
接着在该文件夹下建立一个同名的jsp文件,文件用来存储我们连接数据库的驱动,地址,用户名,密码和我们要使用的sql查询语句 示例如下:
<%@ page
session="true" pageEncoding="UTF-8"
contentType="text/html; charset=UTF-8" %>
<%@ taglib
uri="http://www.tonbeller.com/jpivot" prefix="jp" %>
<%@ taglib
prefix="c" uri="http://java.sun.com/jstl/core" %>
<jp:mondrianQuery
id="query01" jdbcDriver="oracle.jdbc.driver.OracleDriver"
jdbcUrl="jdbc:oracle:thin:@localhost:1521:orcl"
catalogUri="/WEB-INF/queries/tse.xml"
jdbcUser="hlsoa"
jdbcPassword="hlsoa" connectionPooling="false">
select
{[Measures].[quan1], [Measures].[avgsell],
[Measures].[totalsell]} on columns,
{([good].[allgood], [sex].[allsex])} ON rows
from Sales
</jp:mondrianQuery>
<c:set
var="title01" scope="session">Test Query uses Mondrian
OLAP</c:set>
如果是直接在Tomcat部署的话,打开浏览器输入http://localhost:8080/mondrian/testpage.jsp?query=tse就可以出现结果
如果是通过IDE,打开浏览器输入http://localhost:8080/Tezz/testpage.jsp?query=tse
1.5常见的错误与问题
1.5.1数据库驱动和数据库连接问题

报这个错误说明我们缺少oracle驱动jar包加载不了oracle驱动,此时我们可以从Oracle官网下载或者在以前的项目中复制一个过来放到WEB-INF下的lib文件夹中

第二点要注意的是我们写在tse.jsp文件中的jdbcUrl,Driver一定不能写错,不要前后多出
空格。同时cataloguri也要写成相对应的,用户名、密码同样不能出错。

1.5.2 testpage.jsp attribute”test” with 报错问题

解决方法:找到webapps下的testpage.jsp页面到到<c:if>query01这一段直接删除
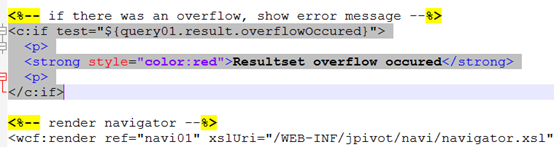
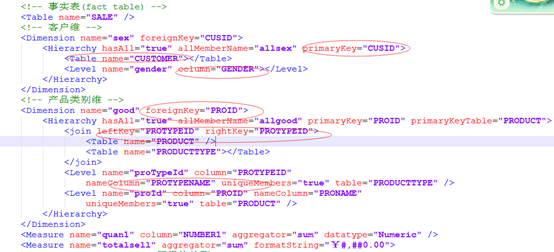
1.5.3执行SQl语句报错情景1(Oracle数据库特有问题)

当时一切都改好了,就是在执行SQL语句是报错,将这段语句看了半天也没发现错误,在网上查找半天也没有解决方案,最后发现错误出现在cube文件中,因为本人使用的数据库是Oracle,所以cube文件里面所涉及到数据库字段的名称都要改成大写,这样mondrian才能够识别。这个问题耽误好长时间。。。。
1.5.4 常见的乱码和字符集设置问题
在jsp和xml文件中要与数据库的字符集保持一致,同时为了防止出现乱码问题,也可以借鉴作者的方法在jsp和xml文件中尽量避免出现中文。

OLAP了解与OLAP引擎——Mondrian入门的更多相关文章
- 微软TTS语音引擎编程入门
原文链接地址:http://www.jizhuomi.com/software/135.html 我们都使用过一些某某词霸的英语学习工具软件,它们大多都有朗读的功能,其实这就是利用的Windows ...
- 复杂事件处理引擎—Esper入门(第二弹)
说明: 以下内容,可以参考Esper官方网站<Qucik start & Tutorial >(顺序做了部分调整). PS:因为英语水平有限(大学期间刚过CET4的英语小盲童一枚) ...
- 复杂事件处理引擎—Esper入门
说明: 以下内容,可以参考Esper官方网站<Qucik start & Tutorial >(顺序做了部分调整). PS:因为英语水平有限(大学期间刚过CET4的英语小盲童一枚) ...
- Camunda工作流引擎简单入门
官网:https://camunda.com/ 官方文档:https://docs.camunda.org/get-started/spring-boot/project-setup/ 阅读新体验:h ...
- 模板引擎ejs入门学习
1:利用 NPM 安装 EJS 很简单 npm install ejs 2:安装完成肯定就是使用了 var template = ejs.compile(str, options); template ...
- Away3D引擎学习入门笔记
(1). 准备工作,一些必须知道的东西 (创建时间:2014-06-05) A.必要的开发语言基础.至少要懂点ActionScript 3.0语法(ActionScript 3.0语法及API参考), ...
- RoadFlowCore工作流引擎快速入门
RoadFlow新建一个流程分为以下几步: 1.建表 在数据库建一张自己的业务表(根据你自己的业务需要确定表字段,如请假流程就有,请假人.请假时间.请假天数等字段),数据表必须要有一个主键,主键类型是 ...
- Slickflow.NET 开源工作流引擎快速入门之三: 简单或分支流程代码编写示例
前言:对于急切想了解引擎功能的开发人员,在下载版本后,就想尝试编写代码,完成一个流程的开发和测试.本文试图从请假流程,或分支模式来快速了解引擎代码的编写. 1. 创建或分支流程图形 或分支流程是常见的 ...
- Slickflow.NET 开源工作流引擎快速入门之二: 简单并行分支流程代码编写示例
前言:对于急切想了解引擎功能的开发人员,在下载版本后,就想尝试编写代码,完成一个流程的开发和测试.本文试图从一个最简单的并行分支流程来示例说明,如何快速了解引擎代码的编写. 版本:.NET Core2 ...
随机推荐
- 知识点补充 set 深浅拷贝
一 对前面知识点的补充 1.str中的join()方法是将列表转换成字符串 lst = ["韩雪","赵丽颖","黄渤","李连杰 ...
- java微信开发之地图定位
页面代码: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEnc ...
- axios的封装
function axios(options){ var promise = new Promise((resolve,reject)=>{ var xhr = null; if(window. ...
- aliplayer 视频播放报错
问题总结: 1.引用 阿里库时href和src 文件路径不加http <link rel="stylesheet" href="//g.alicdn.com/de/ ...
- 【团队】EasyKing的实现_2
下载开发版 完成情况 完成了碰撞箱的制作 TODO 子弹攻击范围 音效 英雄技能 建筑 双人联机 物品 小兵 地图移动
- 【ASP.NET】 Config Error: This configuration section cannot be used at this path.
Config Error: This configuration section cannot be used at this path. This happens when the section ...
- 使用C#加密及解密字符串
using System; using System.IO; using System.Security.Cryptography; using System.Text; namespace Util ...
- pip安装第三方库镜像源选择
在pip安装时,有些库速度及其缓慢从而导致失败,可以通过更改镜像源的方式来安装. 我在安装的时候使用了清华的镜像源,格式如下: 想要安装什么库就在后面替换即可.
- 【文献07】基于MPC的WMR点镇定-极坐标系下和轨迹跟踪
参考: Kuhne F , Lages W , Silva J D . Point stabilization of mobile robots with nonlinear model predic ...
- LINUX介绍
Linux操作系统被称为领先的服务器操作系统之一,它被普遍和广泛使用着.全球大约有数百款的Linux系统版本,每个系统版本都有自己的特性和目标人群. Linux的发行版本可以大体分为两类,一类是商业公 ...