kylin入门到实战:cube详述
版权申明:转载请注明出处。
文章来源:http://bigdataer.net/?p=306
排版乱?请移步原文获得更好的阅读体验
1.什么是cube?
cube是所有dimession的组合,每一种dimession的组合称之为cuboid。某一有n个dimession的cube会有2n个cuboid,如图: 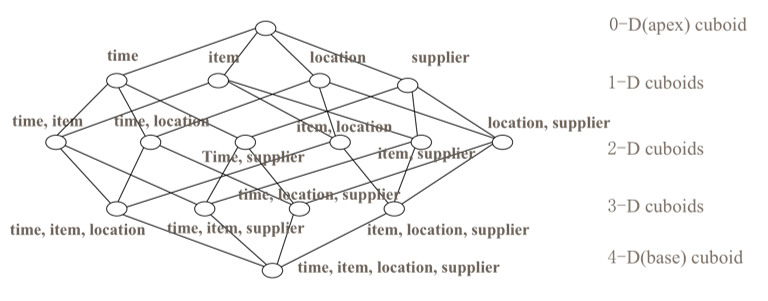
对应一张hive表,有time,item,location,supplier这四个维度,则0-D cuboid时对应的查询语句为 select sum(money) from table;1-D cuboid对应的查询语句有四个,分别为select sum(money) from table group by time,以及select sum(money) from table group by item,以及select sum(money) from table group by location。对应的在2-D时group by 后面的维度会是time,item,location,supplier两两组合。如果不采取优化措施,理论上kylin在预计算过程中会对上述每一种组合进行预计算,随着维度的增加,计算量将会呈几何倍数的增长。为了解决这种问题,kylin对dimession做了分类,见下文。
2.dimession
为了减少cuboid的数量,kylin对dimession做了如下分类
normal:最为普通常见的dimession类型,与其他类型的dimession组成cuboid。
mandatory:每次查询均会使用到的dimession,在下图中A为Mandatory dimension,则与B、C总共构成了4个cuboid,相较于normal dimension的cuboid(23=8)减少了一半。 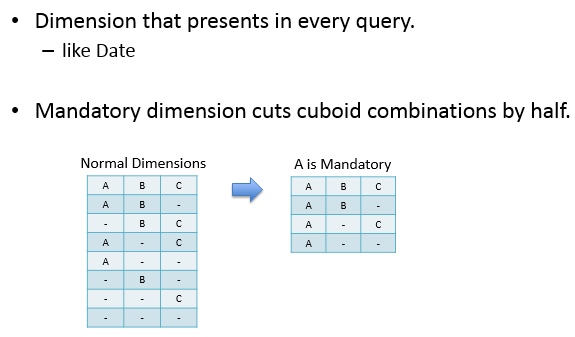
在实际生产应用中,比如对于日报表的分析,可能日期就是一个mandatory dimession。
hierarchy:带层级的dimession,如:年->月->日,要求子级的父级必须存在。如下的例子中cuboid由2n降为了n+1。 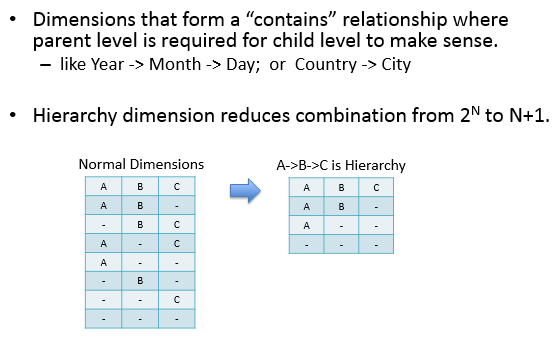
然而,Kylin的Hierarchy dimensions并没有做集合包含约束,比如:kylin_sales_cube定义Hierarchy dimension为META_CATEG_NAME->CATEG_LVL2_NAME->CATEG_LVL3_NAME,但是同一个CATEG_LVL2_NAME可以对应不同META_CATEG_NAME。因此,hierarchy 显得非常鸡肋,以至于在Kylin后台处理时被废弃了。
derived:指该dimession与维表的primary key是一一对应的关系,可以有效减少cuboid的数量,derived dimession只能由Lookup Table生成。 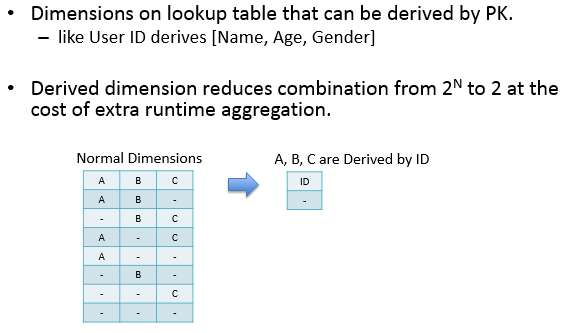
3.measure
measure为事实表的度量值,kylin提供了下面几个函数:
sum,count,max,min,avarage,count_distinct
其中count_distinct有两种实现方式:
(1)近似Count Distinct。Apache Kylin使用HyperLogLog算法实现了近似Count Distinct,提供了错误率从9.75%到1.22%几种精度供选择;
算法计算后的Count Distinct指标,理论上,结果最大只有64KB,最低的错误率是1.22%;这种实现方式用在需要快速计算、节省存储空间,并且能接受错误率的Count Distinct指标计算。
(2)准Count Distinct。从1.5.3版本开始,Kylin中实现了基于bitmap的精确Count Distinct计算方式。当数据类型为tiny int(byte)、small int(short)以及int,
会直接将数据值映射到bitmap中;当数据类型为long,string或者其他,则需要将数据值以字符串形式编码成dict(字典),再将字典ID映射到bitmap;
指标计算后的结果,并不是计数后的值,而是包含了序列化值的bitmap.这样,才能确保在任意维度上的Count Distinct结果是正确的。
这种实现方式提供了精确的无错误的Count Distinct结果,但是需要更多的存储资源,如果数据中的不重复值超过百万,结果所占的存储应该会达到几百MB。
更多文章请关注微信公众号:bigdataer
kylin入门到实战:cube详述的更多相关文章
- kylin入门到实战:入门
版权申明:转载请注明出处.文章来源:http://bigdataer.net/?p=292 排版乱?请移步原文获得更好的阅读体验 1.概述 kylin是一款开源的分布式数据分析工具,基于hadoop之 ...
- kylin从入门到实战:实际案例
版权申明:转载请注明出处.文章来源:http://bigdataer.net/?p=308 排版乱?请移步原文获得更好的阅读体验 前面两篇文章已经介绍了kylin的相关概念以及cube的一些原理,这篇 ...
- 赞一个 kindle电子书有最新的计算机图书可买了【Docker技术入门与实战】
最近对docker这个比较感兴趣,找一个比较完整的书籍看看,在z.cn上找到了电子书,jd dangdang看来要加油啊 Docker技术入门与实战 [Kindle电子书] ~ 杨保华 戴王剑 曹亚仑 ...
- docker-9 supervisord 参考docker从入门到实战
参考docker从入门到实战 使用 Supervisor 来管理进程 Docker 容器在启动的时候开启单个进程,比如,一个 ssh 或者 apache 的 daemon 服务.但我们经常需要在一个机 ...
- webpack入门和实战(一):webpack配置及技巧
一.全面理解webpack 1.什么是 webpack? webpack是近期最火的一款模块加载器兼打包工具,它能把各种资源,例如JS(含JSX).coffee.样式(含less/sass).图片等都 ...
- CMake快速入门教程-实战
http://www.ibm.com/developerworks/cn/linux/l-cn-cmake/ http://blog.csdn.net/dbzhang800/article/detai ...
- Sping Boot入门到实战之入门篇(三):Spring Boot属性配置
该篇为Sping Boot入门到实战系列入门篇的第三篇.介绍Spring Boot的属性配置. 传统的Spring Web应用自定义属性一般是通过添加一个demo.properties配置文件(文 ...
- Sping Boot入门到实战之入门篇(二):第一个Spring Boot应用
该篇为Spring Boot入门到实战系列入门篇的第二篇.介绍创建Spring Boot应用的几种方法. Spring Boot应用可以通过如下三种方法创建: 通过 https://start.spr ...
- Sping Boot入门到实战之入门篇(一):Spring Boot简介
该篇为Spring Boot入门到实战系列入门篇的第一篇.对Spring Boot做一个大致的介绍. 传统的基于Spring的Java Web应用,需要配置web.xml, applicationCo ...
随机推荐
- Efficient data transfer through zero copy
Efficient data transfer through zero copy https://www.ibm.com/developerworks/library/j-zerocopy/ Eff ...
- Myeclipse下配置struts2和hibernate
最近维护一个项目,是用struts2做的,所以特意学了下struts的入门,否则代码都看不懂啊.下面记录下过程.Myeclipse 版本为2014.struts2,hibernate为4.1. 1.既 ...
- 【JVM】启动脚本的参数设置
dump文件生成 JVM会在遇到OutOfMemoryError时拍摄一个“堆转储快照”,并将其保存在一个文件中. 1.配置方法 在JAVA_OPTIONS变量中增加 -XX:+HeapDumpOnO ...
- 【云安全与同态加密_调研分析(3)】国内云安全组织及标准——By Me
◆3. 国内云安全组织及标准◆ ◆云安全标准机构(主要的)◆ ◆标准机构介绍◆ ◆相关标准制定◆ ◆建立的相关模型参考◆ ◆备注(其他参考信息)◆ ★中国通信标准化协会(CCSA) ●组织简介:200 ...
- 详解Spark sql用户自定义函数:UDF与UDAF
UDAF = USER DEFINED AGGREGATION FUNCTION Spark sql提供了丰富的内置函数供猿友们使用,辣为何还要用户自定义函数呢?实际的业务场景可能很复杂,内置函数ho ...
- PLSQLDeveloper安装与配置
1.前提:首先要有oracle数据库或者有oracle服务器,才可以实现使用PLSQL Developer 工具连接到oracle数据库进行开发 2.下载PLSQLDeveloper并解压 3.配置环 ...
- Mysql-xtrabackup 与MySQL5.7 binlog 实现数据即时点恢复
Mysql-xtrabackup 与MySQL5.7 binlog 实现数据即时点恢复 一.数据库准备 1. rpm -e mariadb-libs postfix tar xf mysql-5.7 ...
- java中使用MD5对密码进行加密
import org.springframework.security.authentication.encoding.MessageDigestPasswordEncoder; import org ...
- Multiple encodings set for module chunk explatform "GBK" will be used by compiler
项目用idea启动的时候,突然报了个这个 Multiple encodings set for module explatform "GBK" will be used by co ...
- 函数对象[条款18]---《C++必知必会》
有时需要一些行为类似于函数指针的东西,但函数指针显得笨拙.危险而且过时(让我们承认这一点).通常最佳方式是使用函数对象(function object)取代函数指针. 与智能指针一样,函数对象也是一个 ...