Druid.io系列(四):索引过程分析
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52956083
Druid底层不保存原始数据,而是借鉴了Apache Lucene、Apache Solr以及ElasticSearch等检索引擎的基本做法,对数据按列建立索引,最终转化为Segment,用于存储、查询与分析。
首先,无论是实时数据还是批量数据在进入Druid前都需要经过Indexing Service这个过程。在Indexing Service阶段,Druid主要做三件事:第一,将每条记录转换为列式(columnar format);第二,为每列数据建立位图索引;第三,使用不同的压缩算法进行压缩,其中默认使用LZ4,对于字符类型列采用字典编码(Dictionary encoding)进行压缩,对于位图索引采用Concise/Roaring bitmap进行编码压缩。最终的输出结果也就是Segment。
下面,我们先讲解Druid的索引过程中的几个基本概念,再介绍实时索引的基本原理,最后结合我们在生产环境中使用过的两种索引模式加深对原理的理解。
1 Segment粒度与时间窗口
Segment粒度(SegmentGranularity)表示每一个实时索引任务中产生的Segment所涵盖的时间范围。比如设置{”SegmentGranularity” : “HOUR”},表示每个Segment任务周期为1小时。
时间窗口(WindowPeriod)表示当前实时任务的时间跨度,对于落在时间窗口内的数据,Druid会将其“加工”成Segment,而任何早于或者晚于该时间窗口的数据都会被丢弃。
Segment粒度与时间窗口都是DruidReal-Time中重要的概念与配置项,因为它们既影响每个索引任务的存活时间,又影响数据停留在Real-TimeNode上的时长。所以,每个索引任务“加工”Segment的最长周期 =SegmentGranularity+WindowPeriod,在实际使用中,官方建议WindowPeriod<= SegmentGranularity,以避免创建大量的实时索引任务。
2 实时索引原理
Druid实时索引过程有三个主要特性:
主要面向流式数据(Event Stream)的摄取(ingest)与查询,数据进入Real-TimeNode后可进行即席查询。
实时索引面向一个小的时间窗口,落在窗口内的原始数据会被摄取,窗口外的原始数据则会被丢弃,已完成的Segments会被Handoff到HistoricalNode。
虽然Druid集群内的节点是彼此独立的,但是整个实时索引过程通过Zookeeper进行协同工作。
实时索引过程可以划分为以下四个阶段:
Ingest阶段
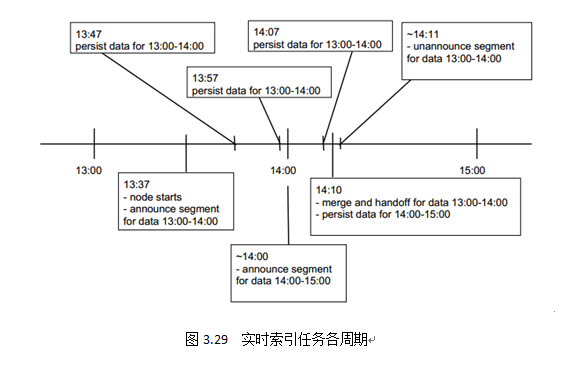
Real-TimeNode对于实时流数据,采用LSM-Tree(Log-Structured Merge-Tree )将数据持有在内存中(JVM堆中),优化数据的写入性能。图3.29中,Real-TimeNodes在13:37申明服务13:00-14:00这一小时内的所有数据。
Persist阶段
当到达一定阈值(0.9.0版本前,阈值是500万行或10分钟,为预防OOM,0.9.0版本后,阈值改为75000行或10分钟)后,内存中的数据会被转换为列式存储物化到磁盘上,为了保证实时窗口内已物化的Smoosh文件依然可以被查询,Druid使用内存文件映射方式(mmap)将Smoosh文件加载到直接内存 中,优化读取性能。如图3.29中所示,13:47、13:57、14:07都是Real-TimeNodes物化数据的时间点。
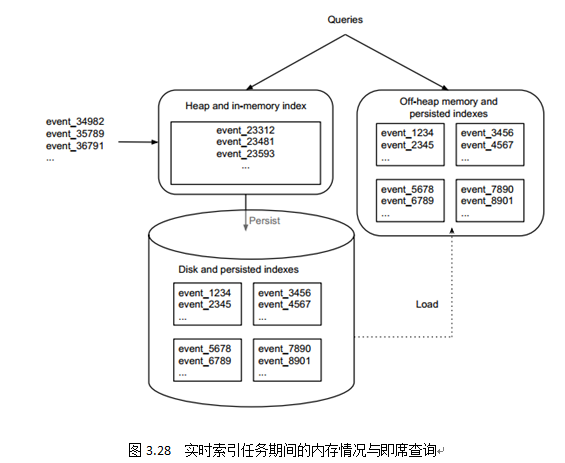
图3.28描述了Ingest阶段与Persist阶段内数据流走向以及内存情况。Druid对实时窗口内数据读写都做了大量优化,从而保证了实时海量数据的即席可查。
Merge阶段
对于Persist阶段,会出现很多Smoosh碎片,小的碎片文件会严重影响后期的数据查询工作,所以在实时索引任务周期的末尾(略少于SegmentGranularity+WindowPeriod时长),每个Real-TimeNode会产生back-groundtask,一方面是等待时间窗口内“掉队”的数据,另一方面搜索本地磁盘所有已物化的Smoosh文件,并将其拼成Segment,也就是我们最后看到的index.zip。图3.29中,当到达索引任务末期14:10分时,Real-TimeNodes开始merge磁盘上的所有文件,生成Segment,准备Handoff。
Handoff阶段
本阶段主要由CoordinatorNodes负责,CoordinatorNodes会将已完成的Segment信息注册到元信息库、上传DeepStorage,并通知集群内HistoricalNode去加载该Segment,同时每隔一定时间间隔(默认1分钟)检查Handoff状态,如果成功,Real-TimeNode会在Zookeeper中申明已不服务该Segment,并执行下一个时间窗口内的索引任务;如果失败,CoordinatorNodes会进行反复尝试。图3.29中,14:11分完成Handoff工作后,该Real-TimeNode申明不再为此时间窗口内的数据服务,开始下一个时间窗口内的索引任务。
下面,我们介绍Tranquility-Kafka索引过程与0.9.1.1版本中最新的Kafkaindexingservice索引过程。
3 Tranquility-Kafka
Tranquility是托管在GitHub上的开源Scala Library,主要负责协调实时索引任务中创建Indexing Service Tasks、处理partition、副本、服务发现以及更新schema。在集群中,我们可以启动多个Tranquility-Kafka实例,所有实例均通过Zookeeper协同处理Indexing Service Tasks。
Tranquility的出现主要是因为Indexing Service API更偏向底层(low-level),就如同Kafka Producer和Consumer在low-level API(Scala API)的基础上又封装了high-level API(Java API),供开发者使用。
任务生命周期
Tranquility会为时间窗口内的每一个Segment启动一个Indexing Service Task,其中Tranquility将数据以POST请求 的方式提交给EventReceiverFirehose(Firehose实现类,默认丢弃所有时间窗口外的数据),当到达任务最大时长(SegmentGranularity+WindowPeriod)时,TimedShutoffFirehose会自动关闭Firehose,此时Segment会进行合并、注册元信息、存储到Deep Storage中并等待Handoff,当某个Historical Node声明自己已加载该Segment后,Indexing Service Task会正常退出。所以,每个Indexing Service Task的生命周期包括SegmentGranularity + WindowPeriod+push to Deep Storage + wait forHandoff。
Schema更新
Schema更新表示我们增加或减少了原始数据中的维度数或度量数。Tranquility可以自动检测Schema更新,并保存新老两份Schema,对于先前创建的任务依然使用老Schema,当到达新的SegmentGranularity时,Tranquility则会使用新Schema摄取数据。
高可用性
Tranquility的所有操作都是尽最大努力(best-effort),我们可以通过配置多个任务副本保证数据不丢失,但是在某些情况下,数据可能会丢失或出现重复:
早于或晚于时间窗口,数据一定会被丢弃。
失败的Middle Manager数目多于配置的任务副本数,部分数据可能会丢失。
IndexingService内部(Overlord、MiddleManager、Peon)通信长时间丢失,同时重试次数超过最大上限,或者运行周期已经超过了时间窗口,这种情况部分数据也会被丢弃。
Tranquility一直未收到IndexingService的确认请求,那么Tranquility会切换到批量加载模式,数据可能会出现重复。
所以,Druid官方建议,如果使用Tranquility作为Real-TimeNodes,那么可以采用如下解决方案减少数据丢失或者重复的风险,从而保证Druid中数据的exactly-oncesemantics:
将数据备份到S3或者HDFS等存储中;
晚间对备份数据运行Hadoopbatchindexingjob,从而对白天的数据重做Segment。
4 Kafka-Indexing-Service
Druid 0.9.1.1版本中新增了Experimental Features:KafkaIndexingService。之所以会增加这个新的特性,根据Druid官方博客:将Kafka集成进Druid,不仅是看重Kafka的高吞吐量以及高可靠性,同时也因为Kafka可以使流数据下游系统,也就是KafkaConsumer端能够更好地实现exactly-oncesemantics。我们在使用过Tranquility-Kafka后可知,数据丢失可能不仅是因为集群节点问题,同样可能是因为数据延迟从而造成没有落在时间窗口内而“被丢失”。
采用Kafkaindexingservice主要有以下几方面的考虑:
每一个进入Kafka的message都是有序、不变的,同时可以通过partition+offset的方式定位,而Druid作为Kafka的Consumer,可以通过该方式rewind到Kafka已存在的buffer中的任意一条message;
Message是由Consumer端,也就是Druid自主地pull进入,而不是被KafkaBrokerpush进集群,push的方式我们知道,接收端无法控制接收速率,容易造成数据过载,而pull的方式Consumer端可以控制ingest速率,从而保证数据有序、稳定地进入Druid;
Message中都包含了partition+offset标签,这就保证了作为Consumer的Druid可以通过确认机制保证每一条message都被读取,不会“被丢失”或“被重读”。
所以,在Kafkaindexingservice中,每一个IndexingServiceTask都对应当前topic的一个partition,每一个partition都有对应的起止offset,那么Druid只需要按照offset顺序遍历读取该partition中所有的数据即可。同时,在读取过程中,Druid收到的每条message都会被确认,从而保证所有数据都被有序的读取,作索引,“加工成”Segment。当到达SegmentGranularity时,当前partition被读过的offset会被更新到元信息库的druid_dataSource表中。
KafkaSupervisor
KafkaSupervisor作为Kafkaindexingservice的监督者,运行在Overlord中,管理Kafka中某个topic对应的Druid中所有Kafkaindexingservicetasks生命周期。在生产环境中,我们通过构造Kafka Supervisor对应的spec文件,以JSON-OVER-HTTP 的方式发送给Overlord节点,Overlord启动KafkaSupervisor,监控对应的Kafkaindexingservicetasks。
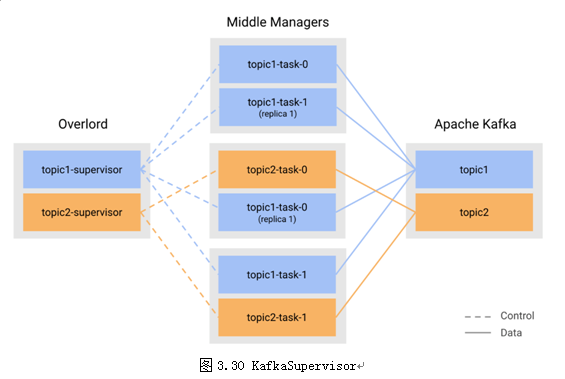
图3.30给出了KafkaIndexingService中的数据流以及控制流。我们总结Supervisor的特性如下:
Supervisor启动后,会启动最多不超过目标topic中最大partition数目的IndexingServiceTasks;
负责管理所有Indexing Service Tasks的生命周期,包括每个task的运行状态、已运行时长(以秒为单位),剩余时长等;
重新创建失败任务以及协调下一个SegmentGranularity内新任务的创建工作等;
Overlord的重启或Leader切换并不会影响Supervisor的工作;
对于Schema更新,Supervisor首先会自动停止所有以老Schema运行中的任务,发布Segment;然后使用新Schema重新创建Indexing Service Tasks,保证在此过程中没有messages会被丢失或者重复读取。
Kafka indexing service在生产环境中的使用说明

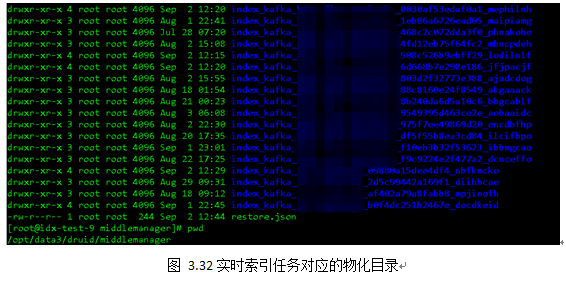
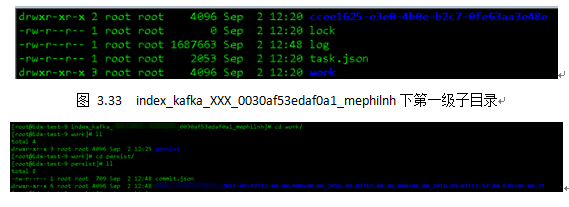
在图3.32中我们可以看到,该目录下有众多Kafkaindexingservicetasks子目录,只有在restore.json文件中记录的才是目前正在运行中的任务,而剩余的子目录可能是因为各种原因(任务失败、实例重启)而未被删除的文件夹。我们以第一个任务(index_kafka_XXX_0030af53edaf0a1_mephilnh)为例。
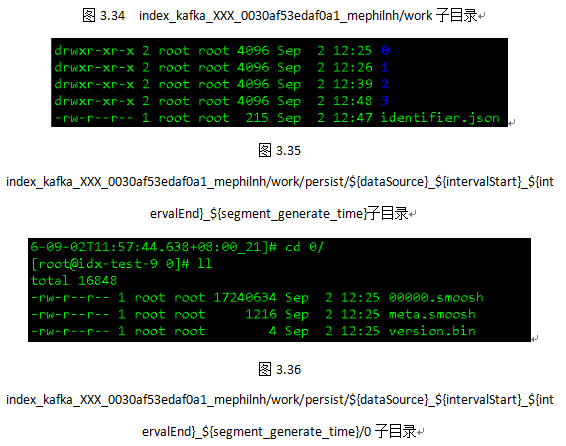
图3.33中lock表示当前tasklock,task.json是当前索引任务的描述文件,log是当前peon日志信息。图3.34中,work目录下只有一层子目录persist,表示当前索引任务已物化的“Segment碎片”。图3.35展示了persist目录下的具体情况,进入persist/${dataSource}_${intervalStart}_${intervalEnd}_${segment_generate_time}/目录下,我们可以看到四个以数字命名的文件夹,这些文件夹是当前索引任务在实时时间窗口内按照一定规则(时间阈值10分钟或者行数阈值75000行)物化的索引文件,每个文件夹内都由meta.smoosh、XXXXX.smoosh以及version.bin这三个文件构成,当索引任务运行到SegmentGranularity+WindowPeriod左右,当前文件夹下会生成一个以“merged”命名的文件夹,将所有以数字命名的文件夹下的文件合并归一为descriptor.json和index.zip,也就是我们所说的Segment,等待publish和handoff。
Druid.io系列(四):索引过程分析的更多相关文章
- Druid.io系列(一):简介
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52955676 Druid.io(以下简称Druid)是面向海量数据的.用于实时查询与 ...
- Druid.io系列(九):数据摄入
1. 概述 Druid的数据摄入主要包括两大类: 1. 实时输入摄入:包括Pull,Push两种 - Pull:需要启动一个RealtimeNode节点,通过不同的Firehose摄取不同种类的数据源 ...
- Druid.io系列(五):查询过程
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52956194 Druid使用JSON over HTTP 作为底层的查询语言,不过强 ...
- Druid.io系列(二):基本概念与架构
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52955788 在介绍Druid架构之前,我们先结合有关OLAP的基本原理来理解Dr ...
- Druid.io系列(七):架构剖析
1. 前言 Druid 的目标是提供一个能够在大数据集上做实时数据摄入与查询的平台,然而对于大多数系统而言,提供数据的快速摄入与提供快速查询是难以同时实现的两个指标.例如对于普通的RDBMS,如果想要 ...
- Druid.io系列(六):问题总结
原文地址: https://blog.csdn.net/njpjsoftdev/article/details/52956508 我们在生产环境中使用Druid也遇到了很多问题,通过阅读官网文档.源码 ...
- Druid.io系列(三): Druid集群节点
原文链接: https://blog.csdn.net/njpjsoftdev/article/details/52955937 1 Historical Node Historical Node的职 ...
- Druid.io系列(八):部署
介绍 前面几个章节对Druid的整体架构做了简单的说明,本文主要描述如何部署Druid的环境 Imply提供了一套完整的部署方式,包括依赖库,Druid,图形化的数据展示页面,SQL查询组件等.本文将 ...
- Node.js学习系列总索引
Node.js学习系列也积累了一些了,建个总索引方便相互交流学习,后面会持续更新^_^! 尽量写些和实战相关的,不讲太多大道理... Node.js学习笔记系列总索引 Nodejs学习笔记(一)--- ...
随机推荐
- CUDA Samples: Streams' usage
以下CUDA sample是分别用C++和CUDA实现的流的使用code,并对其中使用到的CUDA函数进行了解说,code参考了<GPU高性能编程CUDA实战>一书的第十章,各个文件内容如 ...
- 海思arm平台AAC音频转码cpu占用高、效率低的问题解决
问题背景 目前市面上的大部分IPC摄像机音频输出基本都是G711.G726编码格式,而在类似于<基于EasyNVR实现RTSP/Onvif监控摄像头Web无插件化直播监控>这种业务中,都是 ...
- EasyAACEncoder海思/ARM平台优化G711、G726转AAC的CPU占用高问题
本文转自EasyDarwin开源团队成员Kim的博客:http://blog.csdn.net/jinlong0603/article/details/75645378 引言 目前EasyDarwin ...
- EasyRMS录播管理服务器项目实战:windows上开机自启动NodeJS服务
本文转自EasyDarwin开源团队成员Penggy的博客:http://www.jianshu.com/p/ef840505ae06 近期在EasyDarwin开源团队开发一款基于EasyDarwi ...
- 设计模式 - 代理模式(Proxy Pattern)
一.引言 在软件开发过程中,有些对象有时候会由于网络或其他的障碍,以至于不能够或者不能直接访问到这些对象,如果直接访问对象给系统带来不必要的复杂性,这时候可以在客户端和目标对象之间增加一层中间层,让代 ...
- 機器學習基石 机器学习基石(Machine Learning Foundations) 作业2 第10题 解答
由于前面分享的几篇博客已经把其他题的解决方法给出了链接,而这道题并没有,于是这里分享一下: 原题: 这题说白了就是求一个二维平面上的数据用决策树来分开,这就是说平面上的点只能画横竖两个线就要把所有的点 ...
- caffe 一些网络参数
caffe一些网络参数的:http://www.docin.com/p-871820919.html
- python之List排序
sorted() #coding:utf-8 #sorted Ascending 升序 L = [12,23,43,3,65,34,21,3645] print(sorted(L)) >> ...
- java大文件断点续传
java两台服务器之间,大文件上传(续传),采用了Socket通信机制以及JavaIO流两个技术点,具体思路如下: 实现思路:1.服:利用ServerSocket搭建服务器,开启相应端口,进行长连接操 ...
- Xcode ARC需要什么版本的环境支持
Mac OS X v10.6 和 v10.7 (64位应用) 的Xcode 4.2以上版本支持ARC,iOS 4 和 iOS 5 下ARC都能工作,但Weak不支持Mac OS X v10.6 和 i ...