多分类下的ROC曲线和AUC
本文主要介绍一下多分类下的ROC曲线绘制和AUC计算,并以鸢尾花数据为例,简单用python进行一下说明。如果对ROC和AUC二分类下的概念不是很了解,可以先参考下这篇文章:http://blog.csdn.net/ye1215172385/article/details/79448575
由于ROC曲线是针对二分类的情况,对于多分类问题,ROC曲线的获取主要有两种方法:
假设测试样本个数为m,类别个数为n(假设类别标签分别为:0,2,...,n-1)。在训练完成后,计算出每个测试样本的在各类别下的概率或置信度,得到一个[m, n]形状的矩阵P,每一行表示一个测试样本在各类别下概率值(按类别标签排序)。相应地,将每个测试样本的标签转换为类似二进制的形式,每个位置用来标记是否属于对应的类别(也按标签排序,这样才和前面对应),由此也可以获得一个[m, n]的标签矩阵L。
比如n等于3,标签应转换为:

方法1:每种类别下,都可以得到m个测试样本为该类别的概率(矩阵P中的列)。所以,根据概率矩阵P和标签矩阵L中对应的每一列,可以计算出各个阈值下的假正例率(FPR)和真正例率(TPR),从而绘制出一条ROC曲线。这样总共可以绘制出n条ROC曲线。最后对n条ROC曲线取平均,即可得到最终的ROC曲线。
方法2:首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。基于这两点,将标签矩阵L和概率矩阵P分别按行展开,转置后形成两列,这就得到了一个二分类的结果。所以,此方法经过计算后可以直接得到最终的ROC曲线。
上面的两个方法得到的ROC曲线是不同的,当然曲线下的面积AUC也是不一样的。 在python中,方法1和方法2分别对应sklearn.metrics.roc_auc_score函数中参数average值为'macro'和'micro'的情况。

下面以方法1为例,直接上代码,概率矩阵P和标签矩阵L分别对应代码中的y_score和y_one_hot:
#!/usr/bin/python
# -*- coding:utf-8 -*- import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.preprocessing import label_binarize if __name__ == '__main__':
np.random.seed(0)
data = pd.read_csv('iris.data', header = None) #读取数据
iris_types = data[4].unique()
n_class = iris_types.size
x = data.iloc[:, :2] #只取前面两个特征
y = pd.Categorical(data[4]).codes #将标签转换0,1,...
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.6, random_state = 0)
y_one_hot = label_binarize(y_test, np.arange(n_class)) #装换成类似二进制的编码
alpha = np.logspace(-2, 2, 20) #设置超参数范围
model = LogisticRegressionCV(Cs = alpha, cv = 3, penalty = 'l2') #使用L2正则化
model.fit(x_train, y_train)
print '超参数:', model.C_
# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(x_test)
# 1、调用函数计算micro类型的AUC
print '调用函数auc:', metrics.roc_auc_score(y_one_hot, y_score, average='micro')
# 2、手动计算micro类型的AUC
#首先将矩阵y_one_hot和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(y_one_hot.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print '手动计算auc:', auc
#绘图
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title(u'鸢尾花数据Logistic分类后的ROC和AUC', fontsize=17)
plt.show()
我的实战
Bnew_one1=[]
for lis in Bnew4:
bol=np.zeros(51)
bol=bol.tolist()
bol[lis[0]]=1
Bnew_one1.append(bol) Blast_one=[]
for lis in Blast:
bol=np.zeros(51)
bol=bol.tolist()
bol[lis[0]]=1
Blast_one.append(bol) Bnew_one1=np.array(Bnew_one1)
Blast_one=np.array(Blast_one)
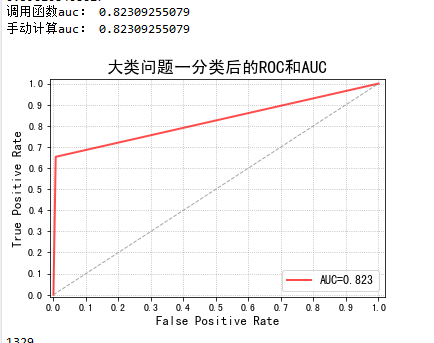
Bnew_one=np.array(Bnew_one) print('调用函数auc:', metrics.roc_auc_score(Blast_one, Bnew_one1, average='micro')) fpr, tpr, thresholds = metrics.roc_curve(Blast_one.ravel(),Bnew_one1.ravel())
auc = metrics.auc(fpr, tpr)
print('手动计算auc:', auc)
#绘图
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title(u'大类问题一分类后的ROC和AUC', fontsize=17)
plt.show()
多分类下的ROC曲线和AUC的更多相关文章
- 【分类模型评判指标 二】ROC曲线与AUC面积
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031 略有改动,仅供个人学习使用 简介 ROC曲线与AUC面积均是用来 ...
- 机器学习之分类器性能指标之ROC曲线、AUC值
分类器性能指标之ROC曲线.AUC值 一 roc曲线 1.roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性 ...
- ROC曲线、AUC、Precision、Recall、F-measure理解及Python实现
本文首先从整体上介绍ROC曲线.AUC.Precision.Recall以及F-measure,然后介绍上述这些评价指标的有趣特性,最后给出ROC曲线的一个Python实现示例. 一.ROC曲线.AU ...
- ROC曲线的AUC(以及其他评价指标的简介)知识整理
相关评价指标在这片文章里有很好介绍 信息检索(IR)的评价指标介绍 - 准确率.召回率.F1.mAP.ROC.AUC:http://blog.csdn.net/marising/article/det ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- ROC曲线,AUC面积
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间.Auc作为数值可以直观的评价分类器的好坏,值越大越好. 首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本, ...
- ROC曲线和AUC值(转)
http://www.cnblogs.com/dlml/p/4403482.html 分类器性能指标之ROC曲线.AUC值 一 roc曲线 1.roc曲线:接收者操作特征(receiveroperat ...
- 混淆矩阵、准确率、召回率、ROC曲线、AUC
混淆矩阵.准确率.召回率.ROC曲线.AUC 假设有一个用来对猫(cats).狗(dogs).兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结.假设总共 ...
- 机器学习常见的几种评价指标:精确率(Precision)、召回率(Recall)、F值(F-measure)、ROC曲线、AUC、准确率(Accuracy)
原文链接:https://blog.csdn.net/weixin_42518879/article/details/83959319 主要内容:机器学习中常见的几种评价指标,它们各自的含义和计算(注 ...
随机推荐
- ios 第2天
类的方法和实例的方法 -(void)runwithspeed:(int)speed and direction:(int)direction; 实例方法 -开头 运用对象调用 函数名为runwiths ...
- MoreEffectiveC++Item35 条款25 将constructor和non-member functions虚化
1.virtual constructor 在语法上是不可将构造函数声明成虚函数,虚函数用于实现"因类型而异的行为",也就是根据指针或引用所绑定对象的动态类型而调用不同实体.现在所 ...
- Android 仿微信朋友圈查看
项目要做一个类似于这样的功能,就做了. 项目下载地址:http://download.csdn.net/detail/u014608640/9917626 一,看下效果: 二.activity类 pu ...
- 几种常见的微服务架构方案——ZeroC IceGrid、Spring Cloud、基于消息队列、Docker Swarm
微服务架构是当前很热门的一个概念,它不是凭空产生的,是技术发展的必然结果.虽然微服务架构没有公认的技术标准和规范草案,但业界已经有一些很有影响力的开源微服务架构平台,架构师可以根据公司的技术实力并结合 ...
- 将海康大华等网络摄像机RTSP流进行网页Flash rtmp和H5 hls直播的技术方案
前言 再小的技术点也会有他的市场! 一直以来,都有一些不被看好,认为是成本太高,无法大规模展开的软件和产品形态,就好比每一座城市都会有他的著名小吃一样,即使是慕名而来的人源源不断,受众群体也总是有限, ...
- python常用模块之shelve模块
python常用模块之shelve模块 shelve模块是一个简单的k,v将内存中的数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据类型 我们在上面讲json.pickle ...
- linux命令-xz
tar.xz文件如何压缩解压xz是绝大数linux默认就带的一个压缩工具,压缩率很高. xz压缩文件方法 默认压缩等级是6.要设置压缩率加入参数 -0 到 -9调节压缩率. xz -z [文件名] 不 ...
- css3实现对radio和checkbox的美化
一,如何隐藏小程序中的很粗的滚动条,实现页面的美化? tit: 在开发小程序的过程中,无论是横向或者纵向当产生滚动条时,系统默认的滚动条会很粗,效果展示十分难看,我们可以通过设置如下wxss代码实 ...
- NFS,两台linux设置网络共享文件系统
NFS,MOUNT,UMOUNT 简介 NFS是Network File System的简写,网络文件系统.通过使用NFS,用户和程序可以像访问本地文件一样访问远端系统上的文件,根据权限的控制可以对N ...
- 每天一个linux命令:【转载】nl命令
nl命令在linux系统中用来计算文件中行号.nl 可以将输出的文件内容自动的加上行号!其默认的结果与 cat -n 有点不太一样, nl 可以将行号做比较多的显示设计,包括位数与是否自动补齐 0 等 ...