[DeeplearningAI笔记]序列模型2.6Word2Vec/Skip-grams/hierarchical softmax classifier 分级softmax 分类器
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.6 Word2Vec
- Word2Vec相对于原先介绍的词嵌入的方法来说更加的简单快速。
Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
Skip-grams
- 假设在训练集中给出了如下的例句:“I want a glass of orange juice to go along with my cereal” 抽取上下文与目标词配对来构造一个监督学习的问题。
- 上下文不一定总是目标单词之前离得最近的四个单词,或者里的最近的n个单词,可以随机的选择句子中的一个单词作为上下文词。例如选择orange作为上下文单词,然后 随机在一定词距内选定另一个词,在上下文单词前后的五到十个单词随机选择目标词
| Content | Target |
|---|---|
| orange | juice |
| orange | glass |
| orange | my |
- 于是构造一个监督学习问题,给定上下文单词,在这个词正负十个词距中或者正负五个词距中随机选择某个目标词。
这显然不是一个简单的学习问题,因为在单词orange的正负十个词距之间会有很多不同的单词,但是构造这个监督学习问题的目标并不是要解决这个监督学习问题本身,而是想要使用这个监督学习来学到一个好的词嵌入模型
Skip-grams model
- 此处使用的是一个1W词的词汇表,有时训练使用的词汇表会超过100W词,我们想要解决的有监督学习问题是学习一种对应关系,即从Content出发对Target的映射。
- 假设在训练集中的一个实例是“Orange”-->"Juice"的对应,而Content“Orange”对应字典中的第6257个单词,Target“Juice”对应字典中的第4834个单词。
- 使用One-hot向量表示的方式表示出“Orange”和“Juice”即\(O_{c}\)和\(O_{t}\)
- 使用E表示词嵌入矩阵,使用\(e_{c}\)表示词嵌入向量Context,使用\(e_{t}\)表示词嵌入向量Target
- 则具有式子\(e_{c}=EO_{c}\),\(e_{t}=EO_{t}\)
将词嵌入向量输入到一个Softmax单元
- 对于Softmax单元,其计算的是已知上下文的情况下目标词出现的概率
- 其中\(\theta_{t}\)是一个与输出t有关的参数即表示和标签t相符的概率
\[P(target|content)=\frac{e^{\theta_{t}^{T}e_{c}}}{\sum^{10000}_{j=1}{e^{\theta^{T}_{j}e_{c}}}}\] - 则此时的损失函数可表示为:\[L(\hat{y},y)=-\sum^{10000}_{i=1}{y_{i}log{\hat{y_i}}}\]其中\(y_{i}\)表示Target的真实值,而\(\hat{y_{i}}\)表示模型得出的Taret的预测值。
- y是训练集中的真实值即\(y=\begin{equation}\left[\begin{matrix}0\\.\\.\\.\\1\\.\\.\\.\\.\\.\\0\\\end{matrix}\right]\end{equation}\)y是一个与词汇表中词汇数量相同维度的one-hot向量,例如:如果y表示juice,其在词汇表的序号是4834,且词汇表中总共有1W个单词,则y为一个1W维度的向量并且第4834维的值为1其余维度均为0。
- 类似的\(\hat{y}\)是一个从softmax单元输出的具有1W维度的向量表示所有可能目标词的概率。
矩阵E会有很多参数,其对应了词嵌入向量\(e_{c}\)的值,softmax单元也有参数\(\theta_{t}\),如果通过反向传播算法优化损失函数L,你就会得到一个很好的嵌入向量集。此就称之为--skip-gram 模型。
- skip-gram模型将一个词汇作为输入,跳过(skip)一些单词并预测这个输入词从左数或从右数的某个词。
hierarchical softmax classifier 分级softmax 分类器
- 但是此方法需要使用softmax分类函数,每次计算softmax的分母的时候需要对输出向量中的1W个词做计算,而这个求和操作是十分耗时的。而且词汇表中的单词数量越多,则softmax操作耗时越多。
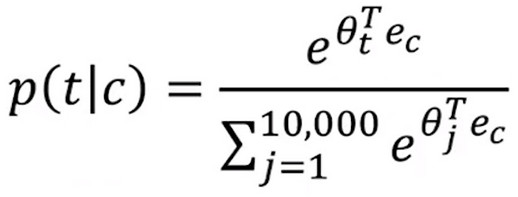
- 为了解决这个问题,引入了 hierarchical softmax classifier 分级softmax 分类器 意思是不是一次性确定属于1W类中的哪一类,而是采用一种 类似二分查找的方法区分词嵌入向量所在类别。
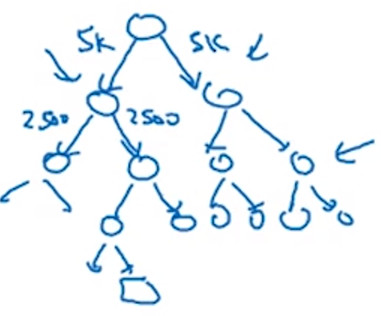
- 当然,为了节省查找的时间和计算资源,将常见词汇构造在查找树的靠近根部的节点,而不常见的词汇则构造在查找树更深的节点上。
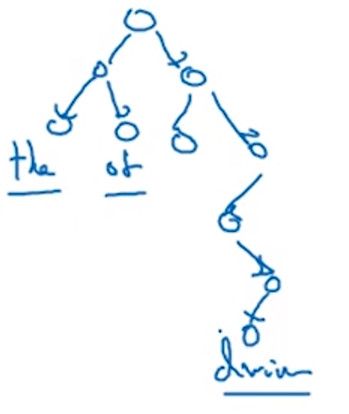
How to sample the context C 如何对上下文进行采样
- 对上下文进行均匀而随机的采样,而目标Target在上下文的前后5-10个区间中进行均匀而随机的采样。
- 这样做,你会发现像词汇 the of a and to 诸如此类介词在Context和Target中出现的相当频繁。而像 orange apple durain 这种有实际意义的词汇不会那么频繁的出现。
- 使用启发式的方式在常用词和不常用的词汇之间分别进行采样。
补充
- 这就是本节介绍的Word2Vec中的skip-gram模型,在参考文献提及的论文原文中,实际上提到了两个不同版本的Word2Vec模型, skip-gram 只是其中之一。还有另外一个模型称为 CBOW--连续词袋模型。
- CBOW--连续词袋模型 获得中间词两边的上下文,然后用周围的词来预测中间的词,这个模型也十分的有效也有其优点和缺点。
- skip-gram 模型的关键问题在于: Softmax 步骤计算成本非常昂贵,需要在分母中对词汇表中的所有词进行求和
[DeeplearningAI笔记]序列模型2.6Word2Vec/Skip-grams/hierarchical softmax classifier 分级softmax 分类器的更多相关文章
- [DeeplearningAI笔记]序列模型3.9-3.10语音辨识/CTC损失函数/触发字检测
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.9语音辨识 Speech recognition 问题描述 对于音频片段(audio clip)x ,y生成文本 ...
- [DeeplearningAI笔记]序列模型3.7-3.8注意力模型
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.7注意力模型直观理解Attention model intuition 长序列问题 The problem of ...
- [DeeplearningAI笔记]序列模型3.6Bleu得分/机器翻译得分指标
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.6Bleu得分 在机器翻译中往往对应有多种翻译,而且同样好,此时怎样评估一个机器翻译系统是一个难题. 常见的解决 ...
- [DeeplearningAI笔记]序列模型3.3集束搜索
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.3 集束搜索Beam Search 对于机器翻译来说,给定输入的句子,会返回一个随机的英语翻译结果,但是你想要一 ...
- [DeeplearningAI笔记]序列模型3.2有条件的语言模型与贪心搜索的不可行性
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.2选择最可能的句子 Picking the most likely sentence condition lan ...
- [DeeplearningAI笔记]序列模型3.1基本的 Seq2Seq /image to Seq
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.1基础模型 [1] Sutskever I, Vinyals O, Le Q V. Sequence to Se ...
- [DeeplearningAI笔记]序列模型1.10-1.12LSTM/BRNN/DeepRNN
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.10长短期记忆网络(Long short term memory)LSTM Hochreiter S, Schmidhu ...
- [DeeplearningAI笔记]序列模型1.7-1.9RNN对新序列采样/GRU门控循环神经网络
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.7对新序列采样 基于词汇进行采样模型 在训练完一个模型之后你想要知道模型学到了什么,一种非正式的方法就是进行一次新序列采 ...
- [DeeplearningAI笔记]序列模型1.5-1.6不同类型的循环神经网络/语言模型与序列生成
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.5不同类型的循环神经网络 上节中介绍的是 具有相同长度输入序列和输出序列的循环神经网络,但是对于很多应用\(T_{x}和 ...
随机推荐
- eclipse版本信息及操作系统
一.查看版本信息: 进入到eclipse安装目录下,有一个.eclipseproduct文件,用记事本打开,就可以知道版本了,后面version=的值就是版本 二.是否为32位操作系统: 找到ecli ...
- c++ Dynamic Memory (part 2)
Don't use get to initialize or assign another smart pointer. The code that use the return from get c ...
- “Hello World!”团队第六周的第一次会议
今天是我们团队“Hello World!”团队第六周召开的第一次会议.博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.Todo List 六.会议照片 七.燃尽图 一.会议时间 ...
- struts传值方式ModelDriven的使用
struts传值不需要用到request,struts会处理好. 1.不是面向对象直接在jsp页面和Java代码都写:name,password... 以下为面向对象 2.action类实现Model ...
- Linux 安装php扩展 swoole
swoole是一个PHP的异步.并行.高性能网络通信引擎,使用纯C语言编写,提供了PHP语言的异步多线程服务器,异步TCP/UDP网络客户端,异步MySQL,异步Redis,数据库连接池,AsyncT ...
- 第一阶段android学习笔记
1.学习<第一行代码> 第一个android项目: 项目的注意点,如创建项目时包名具有唯一性,在做项目的时候要手动改成Project模式.还知道了引用字符串的两种方式. AS项目的三种依赖 ...
- 一次WebSphere性能问题诊断过程
一次接到用户电话,说某个应用在并发量稍大的情况下就会出现响应时间陡然增大,同时管理控制台的响应时间也很慢,几乎无法进行正常工作. 赶到现场后,查看平台版本为Webshpere6.0.2.29,操作系统 ...
- cobbler-web 网络安装服务器套件 Cobbler(补鞋匠)
Cobbler作为一个预备工具,使部署RedHat/Centos/Fedora系统更容易,同时也支持Suse和Debian系统的部署. 它提供以下服务集成: * PXE服务支持 * DHCP服务管 ...
- 软工实践团队展示——WorldElite
软工实践团队展示--WorldElite 本次作业链接 团队成员 031602636许舒玲(组长) 031602237吴杰婷 031602634吴志鸿 081600107傅滨 031602220雷博浩 ...
- 个人项目----词频统计WEB(部分功能)
需求分析 1.使用web上传txt文件,对上传的txt进行词频统计. 2.将统计后的结果输出到web页面,力求界面优美. 3.在界面上展示所给url的文章词频统计,力求界面优美. 3.将每个单词同四. ...