OpenShift负载分区策略(Router Shading)
在很多场景下,单靠几个在Infra节点上的Router进行服务请求的转发是不够的,项目中很多时候都有流量隔离的需求,主要场景在于:
- 一个集群中的不同的环境的流量隔离需求,比如开发走几个Router,生产走另外几个Router.
- 不同项目的流量不希望相互影响,希望保持独立
- 为保证关键服务的SLA,需要单独的流量入口
Openshift集群支持大规模节点环境部署,这种环境下做负载的分区就很有必要了。因为所有的流量集中在几个Infra节点上,性能
和扩展性都有问题。Openshift的Router提供了Shading的功能,下面我们来看看具体的实现
1.Router Shading的架构
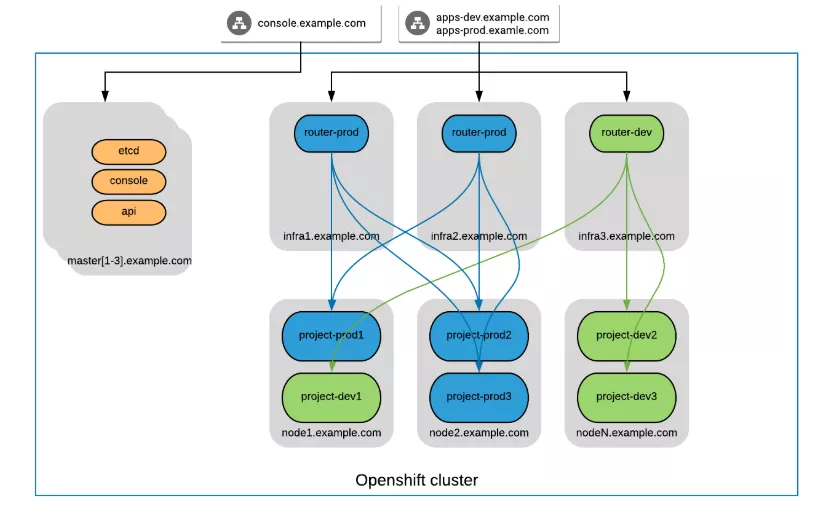
2.前端负载均衡说明
在Router节点前端应有F5或者软件负载均衡器,根据域名进行路由到不同的router
Router部署不一定部署在infra节点上,Router部署以后采用hostnetwork绑定宿主机的IP和端口。
|
域名 |
负载均衡vip |
Router IP |
|
apps-prod.example.com |
10.30.0.33(举例) |
192.168.56.106 |
|
192.168.56.104(暂时没有) |
||
|
apps-dev.example.com |
10.30.0.35 |
192.168.56.103 |
3.建立Router
打开绑定主机网络权限
oc adm policy add-scc-to-user hostnetwork -z router
创建router-dev,对应开发环境,创建router-prod对应生产环境
[root@master openshift-ansible]# oc adm router router-dev --replicas= --force-subdomain='${name}-${namespace}.apps-dev.example.com'
info: password for stats user admin has been set to gGaytR7cPj
--> Creating router router-dev ...
warning: serviceaccounts "router" already exists
warning: clusterrolebindings.authorization.openshift.io "router-router-dev-role" already exists
deploymentconfig.apps.openshift.io "router-dev" created
service "router-dev" created
--> Success
[root@master openshift-ansible]# oc adm router router-prod --replicas= --force-subdomain='${name}-${namespace}.apps-prod.example.com'
info: password for stats user admin has been set to 49wuWv7F6O
--> Creating router router-prod ...
warning: serviceaccounts "router" already exists
warning: clusterrolebindings.authorization.openshift.io "router-router-prod-role" already exists
deploymentconfig.apps.openshift.io "router-prod" created
service "router-prod" created
--> Success
设置标签绑定Router和相应的节点
给Router设置namespace_label.
oc set env dc/router-prod NAMESPACE_LABELS="router=prod"
oc set env dc/router-dev NAMESPACE_LABELS="router=dev" oc label node node3.example.com "router=prod"
oc label node master.example.com "router=dev"
编辑router dc的node-selector
oc edit dc/router-dev -n default 在spec->template->spec下
添加
nodeSelector:
router: dev oc edit dc/router-prod -n default 在spec->template->spec下
添加
nodeSelector:
router: prod
然后确保启动成功
[root@master ~]# oc get pods -n default -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
docker-registry--q5t5m / Running 22d 10.130.1.110 node1.example.com <none>
registry-console--8m2mq / Running 25d 10.128.0.122 master.example.com <none>
router--w7bgw / Running 22d 192.168.56.104 node1.example.com <none>
router-dev--srvcz / Running 3h 192.168.56.103 master.example.com <none>
router-prod--vx8bw / Running 1m 192.168.56.106 node3.example.com <none>
4.建立项目及应用
建立一个项目project-1用于生产环境prod,同时给project-1打标签
[root@master openshift-ansible]# oc new-project project-
Now using project "project-1" on server "https://master.example.com:8443". [root@master ~]# oc label namespace project- router=prod
namespace/project- labeled
部署应用,并建立Route,发现Project1下建立的route自动带有apps-prod.example.com的域名
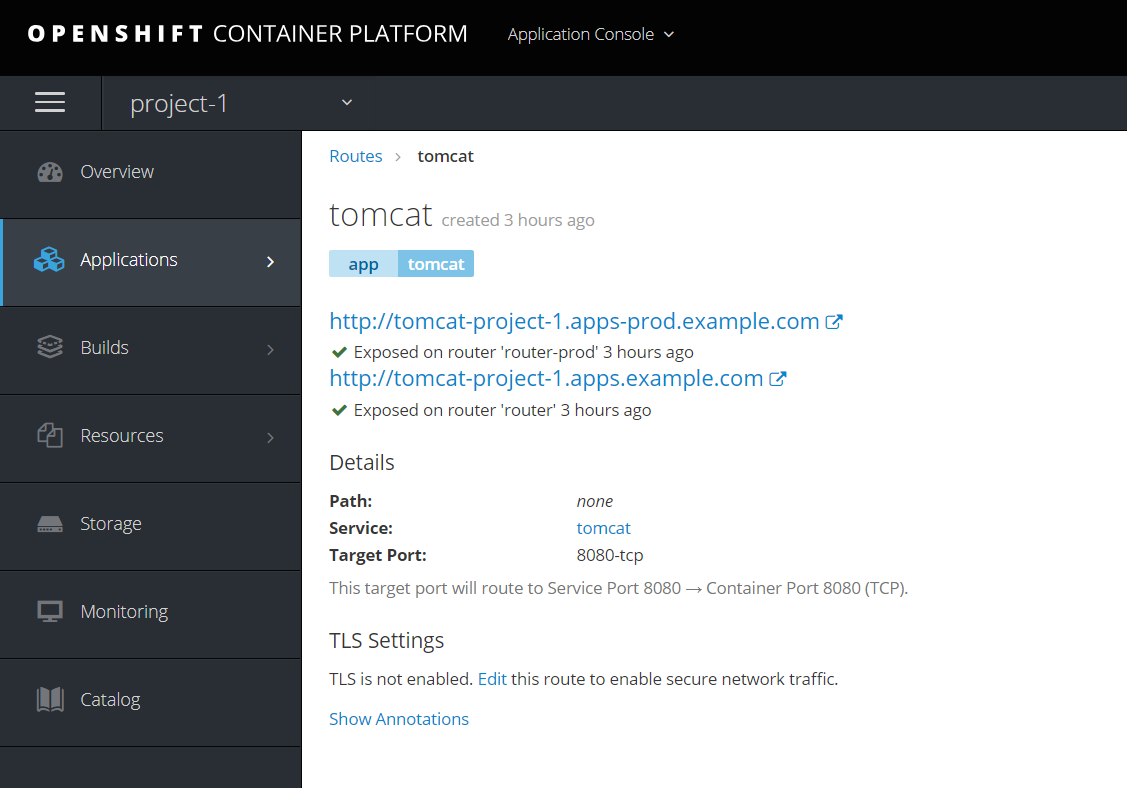
建立一个project-2用于开发环境dev,同时给project-2打标签
[root@master openshift-ansible]# oc new-project project-
Now using project "project-2" on server "https://master.example.com:8443". [root@master ~]# oc label namespace project- router=dev
namespace/project- labeled
部署应用,并建立Route

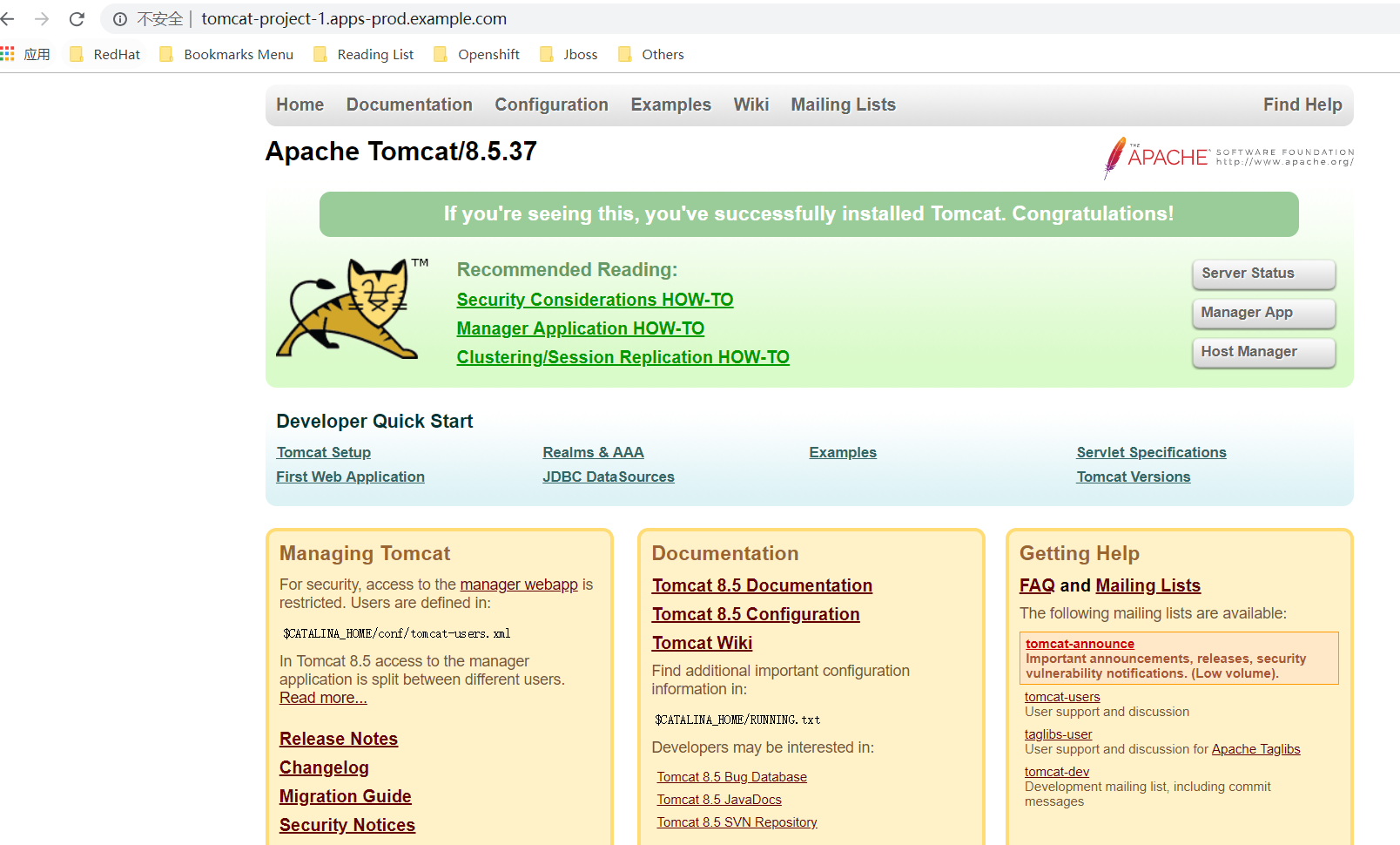
5.访问验证
因没有负载均衡器,在hosts文件中设置
192.168.56.106 tomcat-project-.apps-prod.example.com
192.168.56.103 project2tomcat-project-.apps-dev.example.com
指到正确的Router节点所在的node ip,应用能够正常访问
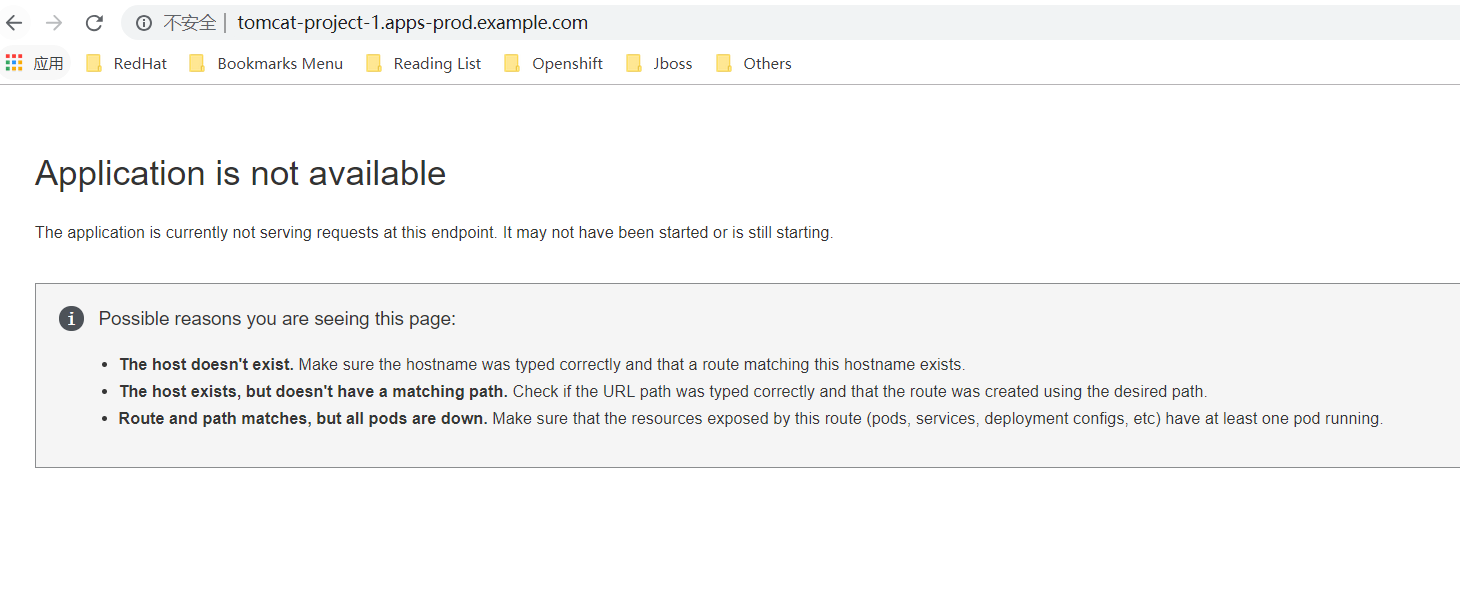
修改192.168.56.106为192.168.56.103或者其他router所在节点, 让请求路由到其他的Router节点,访问失败
6.域名规划
鉴于OpenShift具备这种负载分区的策略,可以比较灵活的规划Router的分布
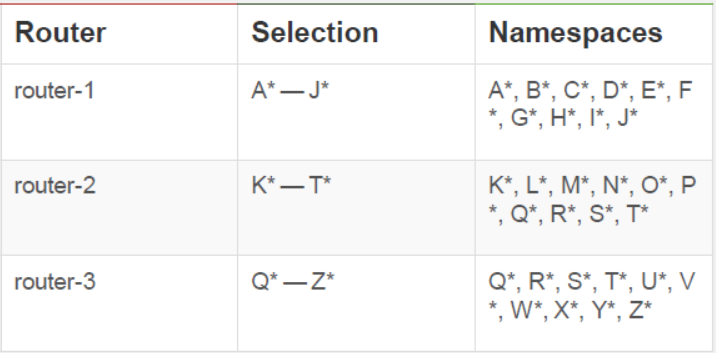
相对的,也可以基于两种模式对Router暴露出去的域名进行规划。
- 规划方案1:
- 不同的数据中心成为二级域名,或者分地域,如dc1.a.com, dc2.a.com
- 在数据中心上基于应用规划三级域名,如app1.dc1.a.com, app3.dc2.a.com
- 应用提供的对外服务为 service1.app1.dc1.a.com, service2.app1.dc1.a.com
- 规划方案2:
- 直接以应用作为二级域名,如app1.a.com, app2.a.com
- 应用提供的对外服务为 service1.app1.a.com, service2.app1.a.com
无论那种模式,都需要相应的域名,如app1.dc1.a.com或app1.a.com,对应上端的负载均衡地址存在于DNS解析记录。也就是DNS将最后的域名解析为OpenShift上Router上端的负载均衡地址。
OpenShift负载分区策略(Router Shading)的更多相关文章
- c数据库读写分离和负载均衡策略
最近在学习数据库的读写分离和主从复制,采用的是一主多从策略,采用轮询的方式,读取从数据库的内容.但是,假如某一台从数据库宕机了,而客户端不知道,每次轮选到此从数据库,不都要报错?到网上查阅了资料,找到 ...
- 【Nginx(四)】Nginx配置集群 负载均衡策略
1.Nginx常见的负载均衡策略 ip_hash (固定分发) 简介:根据请求按访问ip的hash结果分配,这样每个用户就可以固定访问一个后端服务器 场景:服务器业务分区.业务缓存.Session需要 ...
- Kafka分区策略
Kafka分区策略 所谓分区策略是决定生产者将消息发送到哪个分区的算法.Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略. 常见的分区策略包含以下几种:轮询策略.随机策略 .按消息 ...
- nginx入门篇----负载均衡策略
负载均衡策略 负载均衡策略:内置策略和扩展策略. 内置策略包括:轮询.加权轮询.IP hash:扩展策略包括:url hash.fair等 策略详细介绍 轮询:对前端的访问逐一分流到后端网络节点,类似 ...
- nginx 负载均衡策略
nginx 负载均衡策略 1. 轮询轮询方式是nginx负载均衡的默认策略,根据每个server的权重值来轮流发送请求,例如:upstream backend {server backend1.e ...
- Dubbo负载均衡策略
在集群负载均衡时,Dubbo提供了多种均衡策略,缺省为random随机调用. 可以自行扩展负载均衡策略,参见:负载均衡扩展Random LoadBalance 随机,按权重设置随机概率. 在一个截面上 ...
- Ribbon负载均衡策略配置
在这里吐槽一句:网上很多文章真是神坑,你不看还好,看了只会问题越来越多,就连之前的问题都没有解决!!! 不多说了,Ribbon作为后端负载均衡器,比Nginx更注重的是请求分发而不是承担并发,可以直接 ...
- nginx系列10:通过upstream模块选择上游服务器和负载均衡策略round-robin
upstream模块的使用方法 1,使用upstream和server指令来选择上游服务器 这两个指令的语法如下图: 示例: 2,对上游服务使用keepalive长连接 负载均衡策略round-rob ...
- Spring Cloud中的负载均衡策略
在上篇博客(Spring Cloud中负载均衡器概览)中,我们大致的了解了一下Spring Cloud中有哪些负载均衡器,但是对于负载均衡策略我们并没有去详细了解,我们只是知道在BaseLoadBal ...
随机推荐
- jquery重置
在使用jquery时要先引用 <script type="text/javascript" src="/Themes/Default/Js/jquery-1.11. ...
- 在ubuntu下安装kaldi基本步骤
注:最近在学习kaldi语音识别工具,在安装过程中遇到了许多问题,在此记录,以备后需. 在一开始,我看了这篇博客(http://blog.topspeedsnail.com/archives/1001 ...
- Linux下文件特殊权限
SUIDSUID表示在所有者的位置上出现了s在一个命令的所有者的权限上如果出现了s,当其他人在执行该命令的时候将具有所有者的权限.SUID权限仅对二进制文件有效 SGID表示在组的位置上出现了s如果一 ...
- C# 6.0 新特性 (一)
概述 尽管 C# 6.0 尚未完成,但现在这些功能正处于接近完成的关键时刻.自 2014 年 5 月发布文章“C# 6.0 语言预览版”(msdn.microsoft.com/magazine/dn6 ...
- Python爬虫-urllib的基本用法
from urllib import response,request,parse,error from http import cookiejar if __name__ == '__main__' ...
- Redis实战(五)
删除Redis中数据 using (var redisClient = RedisManager.GetClient()) { var user = redisClient.GetTypedClien ...
- 基于Ubuntu系统搭建以太坊go-ethereum源码的开发环境
第一.先安装geth的CLI环境sudo apt-get install geth,这个很重要 第二.下载源代码 git clone https://github.com/ethereum/go-et ...
- Vsftpd支持SSL加密传输
ftp传输数据是明文,弄个抓包软件就可以通过数据包来分析到账号和密码,为了搭建一个安全性比较高ftp,可以结合SSL来解决问题 SSL(Secure Socket Layer)工作于传输层和应用程 ...
- windows 10 下安装python 2.7
下载msi的安装包: https://www.python.org/ftp/python/2.7.8/python-2.7.8.msi [incorrect] PS C:\Python27> . ...
- React Native 系列(一)
前言 本系列是基于React Native版本号0.44.3写的,最初学习React Native的时候,完全没有接触过React和JS,本文的目的是为了给那些JS和React小白提供一个快速入门,让 ...