自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396)
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自然语言处理时,通常需要先进行分词。本文详细介绍现在非常流行的且开源的分词器结巴jieba分词器,并使用python实战介绍。
jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。(这里面很多概念小修之前的文章都有陆续讲过哦)
jieba分词支持三种分词模式:
1. 精确模式, 试图将句子最精确地切开,适合文本分析:
2. 全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
3. 搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词。
jiaba分词还支持繁体分词和支持自定义分词。
1jieba分词器安装
在python2.x和python3.x均兼容,有以下三种:
1. 全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
2. 半自动安装: 先下载,网址为: http://pypi.python.org/pypi/jieba, 解压后运行: python setup.py install
3. 手动安装: 将jieba目录放置于当前目录或者site-packages目录,
jieba分词可以通过import jieba 来引用
2jieba分词主要功能
先介绍主要的使用功能,再展示代码输出。jieba分词的主要功能有如下几种:
1. jieba.cut:该方法接受三个输入参数:需要分词的字符串; cut_all 参数用来控制是否采用全模式;HMM参数用来控制是否适用HMM模型
2. jieba.cut_for_search:该方法接受两个参数:需要分词的字符串;是否使用HMM模型,该方法适用于搜索引擎构建倒排索引的分词,粒度比较细。
3. 待分词的字符串可以是unicode或者UTF-8字符串,GBK字符串。注意不建议直接输入GBK字符串,可能无法预料的误解码成UTF-8,
4. jieba.cut 以及jieba.cut_for_search返回的结构都是可以得到的generator(生成器), 可以使用for循环来获取分词后得到的每一个词语或者使用
5. jieb.lcut 以及 jieba.lcut_for_search 直接返回list
6. jieba.Tokenizer(dictionary=DEFUALT_DICT) 新建自定义分词器,可用于同时使用不同字典,jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
代码演示:
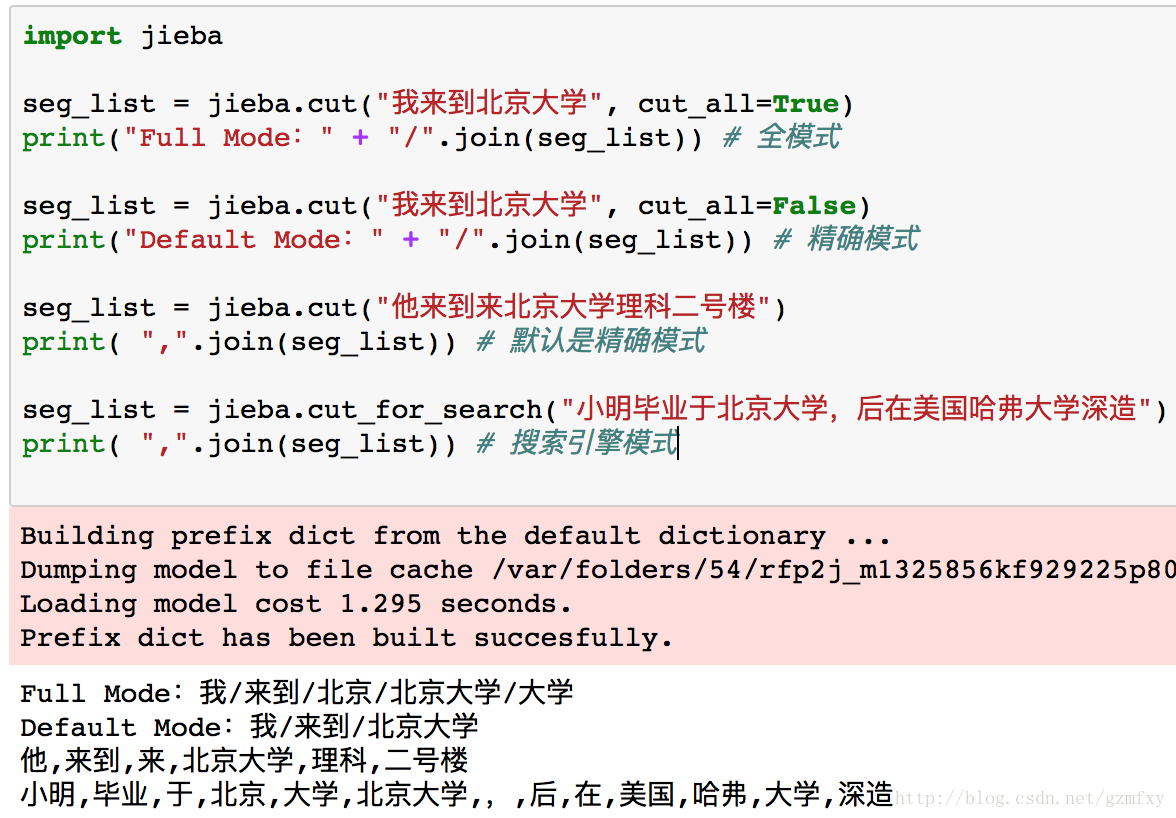
其中下面的是输出结果。
3jieba分词器添加自定义词典
jieba分词器还有一个方便的地方是开发者可以指定自己的自定义词典,以便包含词库中没有的词,虽然jieba分词有新词识别能力,但是自行添加新词可以保证更高的正确率。
使用命令:
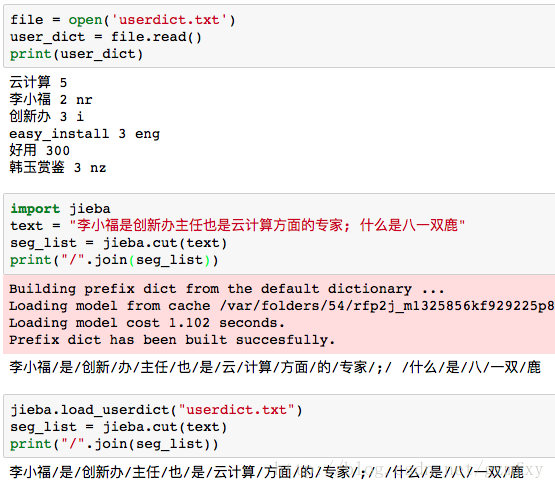
jieba.load_userdict(filename) # filename为自定义词典的路径
在使用的时候,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开。下面其中userdict.txt中的内容为小修添加的词典,而第二部分为小修没有添加字典之后对text文档进行分词得到的结果,第三部分为小修添加字典之后分词的效果。
4利用jieba进行关键词抽取
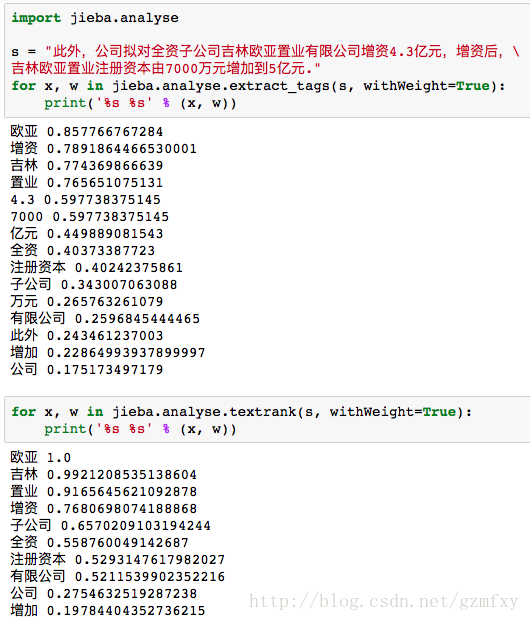
这里介绍基于TF-IDF算法的关键词抽取(干货|详解自然语言处理之TF-IDF模型和python实现), 只有关键词抽取并且进行词向量化之后,才好进行下一步的文本分析,可以说这一步是自然语言处理技术中文本处理最基础的一步。
jieba分词中含有analyse模块,在进行关键词提取时可以使用下列代码

当然也可以使用基于TextRank算法的关键词抽取:

这里举一个例子,分别使用两种方法对同一文本进行关键词抽取,并且显示相应的权重值。
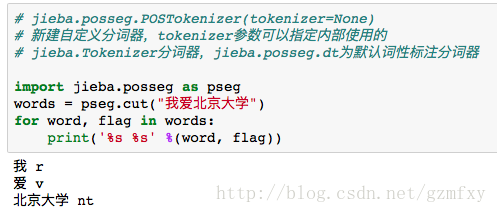
5jieba分词的词性标注
jieba分词还可以进行词性标注,标注句子分词后每个词的词性,采用和ictclas兼容的标记法,这里知识简单的句一个列子。
6jieba分词并行分词
jieba分词器如果是对于大的文本进行分词会比较慢,因此可以使用jieba自带的并行分词功能进行分词,其采用的原理是将目标文本按照行分割后,把各行文本分配到多个Python进程并行分词,然后归并结果,从而获得分词速度可观的提升。
该过程需要基于python自带的multiprocessing模块,而且目前暂时不支持windows. 在使用的时候,只需要在使用jieba分词导入包的时候同时加上下面任意一个命令:

在第五步进行关键词抽取并且计算相应的TF-iDF就可以进行后续的分类或者预测,推荐的相关步骤,后面小修会陆续介绍。
参考内容:
[1] jieba分词github介绍文档:https://github.com/fxsjy/jieba
自然语言处理之中文分词器-jieba分词器详解及python实战的更多相关文章
- 处理器拦截器(HandlerInterceptor)详解
处理器拦截器(HandlerInterceptor)详解 编程界的小学生 关注 2017.04.06 15:19* 字数 881 阅读 657评论 0喜欢 4 简介SpringWebMVC的处理器拦截 ...
- 第7.18节 案例详解:Python类中装饰器@staticmethod定义的静态方法
第7.18节 案例详解:Python类中装饰器@staticmethod定义的静态方法 上节介绍了Python中类的静态方法,本节将结合案例详细说明相关内容. 一. 案例说明 本节定义了类Sta ...
- python装饰器(docorator)详解
引言: 装饰器是python面向对象编程三大器之一,另外两个迭代器.生成器只是我现在还没有遇到必须使用的场景,等确实需要用到的时候,在补充资料:装饰器在某些场景真的是必要的,比如定义了一个类或者一个函 ...
- Spring MVC拦截器(Interceptor )详解
处理器拦截器简介 Spring Web MVC的处理器拦截器(如无特殊说明,下文所说的拦截器即处理器拦截器)类似于Servlet开发中的过滤器Filter,用于对处理器进行预处理和后处理. 常见应用场 ...
- 处理器拦截器(HandlerInterceptor)详解(转)
简介 SpringWebMVC的处理器拦截器,类似于Servlet开发中的过滤器Filter,用于处理器进行预处理和后处理. 应用场景 1.日志记录,可以记录请求信息的日志,以便进行信息监控.信息统计 ...
- 关于开源中文搜索引擎架构coreseek中算法详解
Coreseek 是一款中文全文检索/搜索软件,以GPLv2许可协议开源发布,基于Sphinx研发并独立发布,专攻中文搜索和信息处理领域,适用于行业/垂直搜索.论坛/站内搜索.数据库搜索.文档/文献 ...
- python描述符(descriptor)、属性(property)、函数(类)装饰器(decorator )原理实例详解
1.前言 Python的描述符是接触到Python核心编程中一个比较难以理解的内容,自己在学习的过程中也遇到过很多的疑惑,通过google和阅读源码,现将自己的理解和心得记录下来,也为正在为了该问题 ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python装饰器使用规范案例详解
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数. >>> def now(): ... print('2015-3-25') ... >> ...
随机推荐
- jQuery的deferred对象详解(转载)
jQuery的开发速度很快,几乎每半年一个大版本,每两个月一个小版本.(由于无法转载,复制原文 .原文链接——原作者:阮一峰) 每个版本都会引入一些新功能.今天我想介绍的,就是从jQuery 1.5. ...
- 利用 netsh 给 mysql 开启多端口监听
利用 netsh 给 mysql 开启多端口监听 标题党,实际并不是真的多端口监听,只是端口转发而已. 由于某种特殊原因需要 mysql 服务器多个端口监听. mysql 服务器本身是不支持的,但可以 ...
- oracle 内存分配和调优 总结
一直都想总结一下oracle内存调整方面的知识,最近正好优化一个数据库内存参数,查找一些资料并且google很多下.现在记录下来,做下备份. 一.概述: ...
- 网站建设之高速WEB的实现
1.此文目的 漂亮的色彩.绚丽的动画在输入网址后便能呈现在你的眼前.互联网无可否认已经融入了我们的生活. 我们可以山寨出iPhone却很难有属于自己独特的理念关于事物的思想和心脏. 互联网是现实.艺术 ...
- table tr列 鼠标经过时更改背景颜色
<html> <head> <meta http-equiv="Content-Type" content="text/html; char ...
- Charles 协助解决 metaweblog 排序问题
Charles 是 http代理抓包工具,可有效用于手机客户端网络抓包,详见Charles安装说明.这里使用使用Charles的请求转发功能调试metaweblog的最近博文排序功能. 由于OpenL ...
- 通俗讲讲FPGA
通俗讲讲什么是FPGA. FPGA出现之前,所有集成电路都可以看成雕塑家,但是雕成一个成品,往往要浪费很多半成品和原料,这就是ASIC的制造. 后来FPGA出现了,FPGA就是块橡皮泥,什么硬件电路都 ...
- h5调用手机摄像头/相册
<!DOCTYPE HTML><html><head> <title>上传图片</title> <meta charset=" ...
- 配置IVR实现语音
1.新建系统录音档 登入FreePBX,在Admin面板下选择System Recordings,如下图: 在这个页面可以上传制作好的一些录音,例如像“欢迎致电XXX,按1中文,按2英文... ...
- C++常考算法
1 strcpy, char * strcpy(char* target, char* source){ // 不返回const char*, 因为如果用strlen(strcpy(xx,xxx)) ...