Spark之 Spark Streaming流式处理
SparkStreaming
Spark Streaming类似于Apache Storm,用于流式数据的处理。Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据源有很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象操作如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。

特性
1、易用性
可以像编写离线批处理一样去开发流式的处理程序,并且可以使用java/scala/Python语言进行代码开发
2、容错性
SparkStreaming在没有额外代码和配置的情况下可以恢复丢失的工作。
3、可以融合到spark生态系统
sparkStreaming流式处理可以跟批处理和交互式查询相结合
与storm对比
storm是来一条数据处理一条数据,SparkStreaming是以某一时间间隔批量处理数据。
SparkStreaming原理
Spark Streaming 是基于spark的流式批处理引擎,其基本原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流。
计算流程
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),
每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,
将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行缓存或者存储到外部设备。下图显示了Spark Streaming的整个流程。
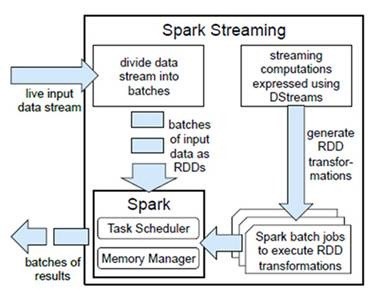
容错性
对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),
所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
实时性
对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG图分解以及Spark的任务集的调度过程。
对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),
所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
DStream
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark算子操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:
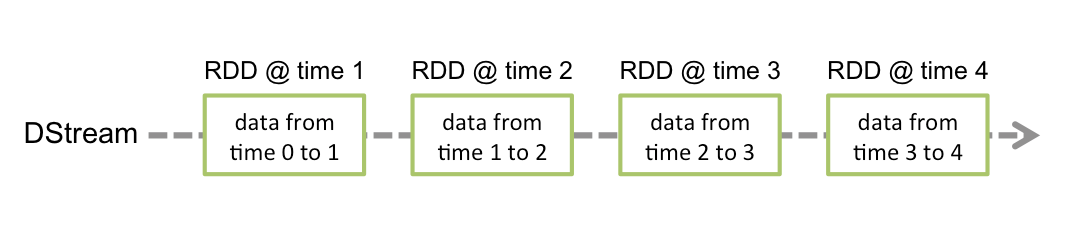
对数据的操作也是按照RDD为单位来进行的
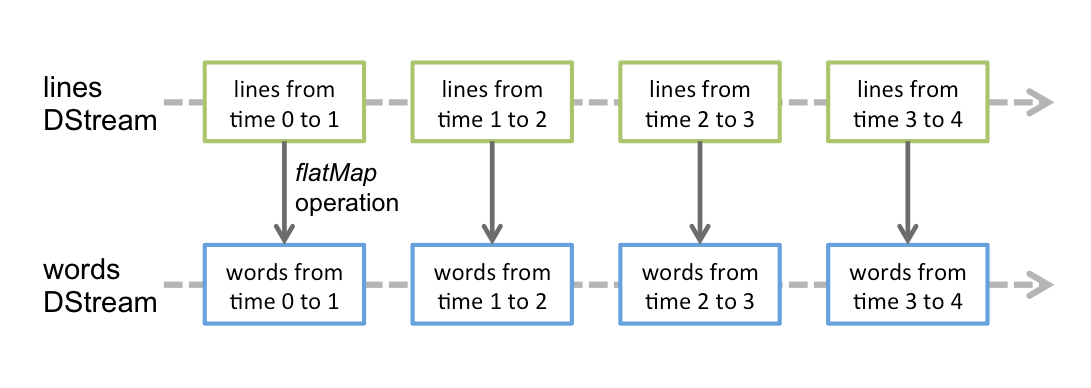
Spark Streaming使用数据源产生的数据流创建DStream,也可以在已有的DStream上使用一些操作来创建新的DStream。
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
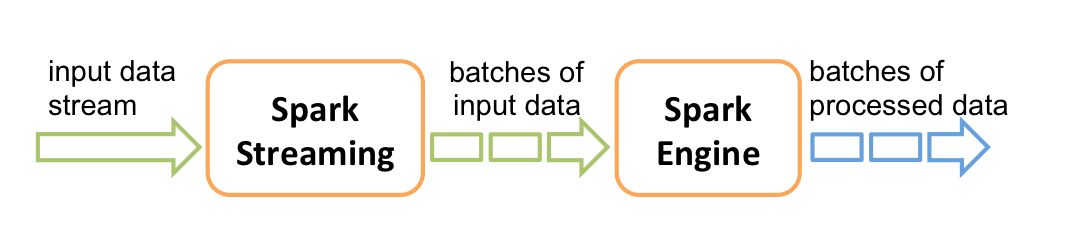
DStream相关操作
DStream上的操作与RDD的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的操作,如:updateStateByKey()、transform()以及各种Window相关的操作。
Transformations on DStreams
|
Transformation |
Meaning |
|
map(func) |
对DStream中的各个元素进行func函数操作,然后返回一个新的DStream |
|
flatMap(func) |
与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
|
filter(func) |
过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
|
repartition(numPartitions) |
增加或减少DStream中的分区数,从而改变DStream的并行度 |
|
union(otherStream) |
将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream. |
|
count() |
通过对DStream中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成的DStream |
|
reduce(func) |
对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream. |
|
countByValue() |
对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
|
reduceByKey(func, [numTasks]) |
利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
|
join(otherStream, [numTasks]) |
输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W))类型的DStream |
|
cogroup(otherStream, [numTasks]) |
输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
|
transform(func) |
通过RDD-to-RDD函数作用于DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD |
|
updateStateByKey(func) |
根据key的之前状态值和key的新值,对key进行更新,返回一个新状态的DStream |
特殊的Transformations:
updateStateByKey 用于记录历史记录,保存上次的状态
reduceByKeyAndWindow 开窗函数
Output Operations on DStreams
相当于rdd的action的作用,transformation不会立即执行,到这才会执行
|
Output Operation |
Meaning |
|
print() |
打印到控制台 |
|
saveAsTextFiles(prefix, [suffix]) |
保存流的内容为文本文件,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
saveAsObjectFiles(prefix, [suffix]) |
保存流的内容为SequenceFile,文件名为 "prefix-TIME_IN_MS[.suffix]". |
|
saveAsHadoopFiles(prefix, [suffix]) |
保存流的内容为hadoop文件,文件名为 "prefix-TIME_IN_MS[.suffix]". |
Spark之 Spark Streaming流式处理的更多相关文章
- Spark Streaming流式处理
Spark Streaming介绍 Spark Streaming概述 Spark Streaming makes it easy to build scalable fault-tolerant s ...
- spark streaming流式计算---监听器
随着对spark的了解,有时会觉得spark就像一个宝盒一样时不时会出现一些难以置信的新功能.每一个新功能被挖掘,就可以使开发过程变得更加便利一点.甚至使很多不可能完成或者完成起来比较复杂的操作,变成 ...
- spark streaming 流式计算---跨batch连接池共享(JVM共享连接池)
在流式计算过程中,难免会连接第三方存储平台(redis,mysql...).在操作过程中,大部分情况是在foreachPartition/mapPartition算子中做连接操作.每一个分区只需要连接 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- Spark Streaming:大规模流式数据处理的新贵(转)
原文链接:Spark Streaming:大规模流式数据处理的新贵 摘要:Spark Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业.本文阐释了Spark Str ...
- Spark Streaming:大规模流式数据处理的新贵
转自:http://www.csdn.net/article/2014-01-28/2818282-Spark-Streaming-big-data 提到Spark Streaming,我们不得不说一 ...
- StreamDM:基于Spark Streaming、支持在线学习的流式分析算法引擎
StreamDM:基于Spark Streaming.支持在线学习的流式分析算法引擎 streamDM:Data Mining for Spark Streaming,华为诺亚方舟实验室开源了业界第一 ...
- 从Storm和Spark 学习流式实时分布式计算的设计
0. 背景 最近我在做流式实时分布式计算系统的架构设计,而正好又要参加CSDN博文大赛的决赛.本来想就写Spark源码分析的文章吧.但是又想毕竟是决赛,要拿出一些自己的干货出来,仅仅是源码分析貌似分量 ...
- Spark SQL - 对大规模的结构化数据进行批处理和流式处理
Spark SQL - 对大规模的结构化数据进行批处理和流式处理 大体翻译自:https://jaceklaskowski.gitbooks.io/mastering-apache-spark/con ...
随机推荐
- Maven中配置生成单元测试报告配置
对junit单元测试的报告: 1. ------------------------------------------------------- 2. T E S T S 3. ------ ...
- 你真的了解分层架构吗?——写给被PetShop"毒害"的朋友们
一叶障目 .NET平台上的分层架构(很多朋友称其为“三层架构”),似乎是一个长盛不衰的话题.经常看到许多朋友对其进行分析.探讨.辩论甚至是抨击.笔者在仔细阅读了大量这方面文章后,认为许多朋友在分层架构 ...
- 数据库视图View的使用
一.视图的概念: 概念: 视图是指计算机数据库中的视图,是一个虚拟表,其内容由查询定义.同真实的表一样,视图包含一系列带有名称的列和行数据.但是,视图并不在数据库中以存储的数据值集形式存在.行和列数据 ...
- js继承方式及其优缺点?
原型链继承的缺点一是字面量重写原型会中断关系,使用引用类型的原型,并且子类型还无法给超类型传递参数.借用构造函数(类式继承)借用构造函数虽然解决了刚才两种问题,但没有原型,则复用无从谈起.所以我们需要 ...
- 笔记本启动时提示错误:amd_xata.sys数字签名无法验证
开机失败,提示adm文件无法验证 文件:Windows\system32\drivers\amd_xata.sys 状态:0xc0000428 信息:Windows 无法验证此文件的数字签名 工具 ...
- Vue.js实现数据的双向数据流
众所周知,Vue.js一直使用的是单向数据流的,和angularJs的双向数据流相比,单向数据流更加容易控制.Vue.js允许父组件通过props属性传递数据到子组件.但是有些情况下我们需要在子组件里 ...
- 关于硬件实现FFT逆运算
前面的文章我们介绍了关于FFT的硬件实现.关于FFT的逆运算IFFT,其实就是将实现FFT的过程反过来执行就可以了. 在实现过程中要注意很多问题. 同 FFT一样,效率问题.以2048点为例,根据理论 ...
- windows7下怎样安装whl文件(python)
本文转载自:http://blog.csdn.net/fhl812432059/article/details/51745226 windows7 python2.7 1.用管理员方式打开cmd 2. ...
- windows10 vs2015编译 带nginx-rtmp-module 模块的32位nginx
1 下载必要软件 从 http://xhmikosr.1f0.de/tools/msys/下载msys:http://xhmikosr.1f0.de/tools/msys/MSYS_MinGW-w6 ...
- Android ListView的item背景色设置
1.如何改变item的背景色和按下颜色 listview默认情况下,item的背景色是黑色,在用户点击时是黄色的.如果需要修改为自定义的背景颜色,一般情况下有三种方法: 1)设置listSelecto ...