MySQL Join算法与调优白皮书(一)

MySQL Join算法与调优白皮书(一)的更多相关文章
- MySQL Join算法与调优白皮书(二)
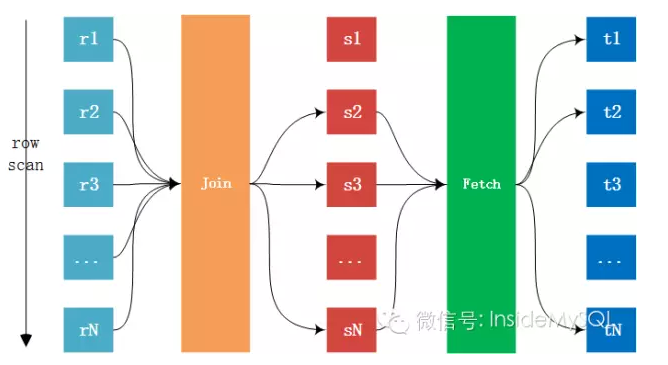
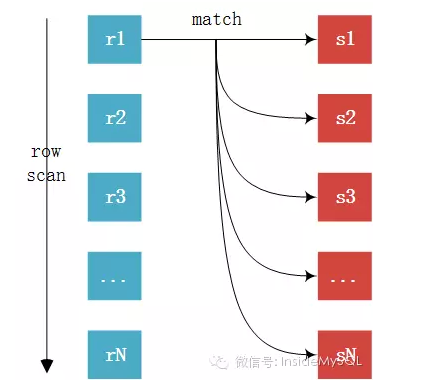
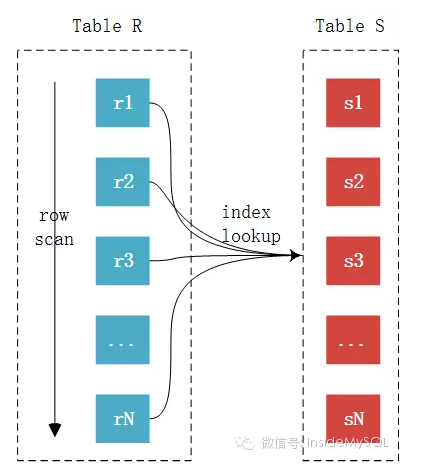
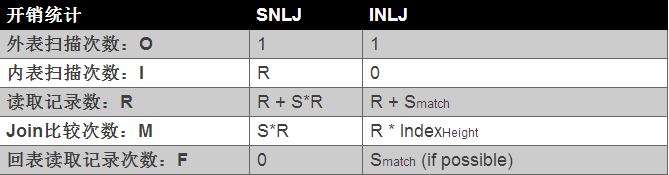
Index Nested-Loop Join (接上篇)由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大 ...
- MySQL Join算法与调优白皮书(三)
Batched Key Access Join Index Nested-Loop Join虽好,但是通过辅助索引进行链接后需要回表,这里需要大量的随机I/O操作.若能优化随机I/O,那么就能极大的提 ...
- 【叶问】 MySQL常用的sql调优手段或工具有哪些
MySQL常用的sql调优手段或工具有哪些1.根据执行计划优化 通常使用desc或explain,另外可以添加format=json来输出更详细的json格式的执行计划,主要注意点如下: ...
- mysql监控、性能调优及三范式理解
原文:mysql监控.性能调优及三范式理解 1监控 工具:sp on mysql sp系列可监控各种数据库 2调优 2.1 DB层操作与调优 2.1.1.开启慢查询 在My.cnf文件中添加如 ...
- MySQL性能诊断与调优 转
http://www.cnblogs.com/preftest/ http://www.highperfmysql.com/ BOOK LAMP 系统性能调优,第 3 部分: MySQL 服务 ...
- MySQL插入数据性能调优
插入数据性能调优总结: 1.SQL插入语句调优 2.如果是InnoDB引擎的话,尝试开启事务,批量提交 3.调整MySQl数据库配置 参考: 百度空间 - MySQL插入数据性能调优 CSDN ...
- MySQL性能诊断与调优
LAMP 系统性能调优,第 3 部分: MySQL 服务器调优http://www.ibm.com/developerworks/cn/linux/l-tune-lamp-3.html LoadRun ...
- MySQL索引和SQL调优手册
MySQL索引 MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等.为了避免混乱,本文将只关注于BTree ...
- mysql 索引优化 性能调优 锁
1 检查mysql 是否安装 rpm -qa|grep -i mysql 2 ntsysv 查看和设置开机启动列表 3 mysql 在 centos 上默认 的数据目录是 /var/lib/mysql ...
随机推荐
- Access control allow origin 简单请求和复杂请求
原文地址:http://blog.csdn.net/wangjun5159/article/details/49096445 错误信息: XMLHttpRequest cannot load http ...
- SVM之解决线性不可分
SVM之问题形式化 SVM之对偶问题 SVM之核函数 >>>SVM之解决线性不可分 写在SVM之前——凸优化与对偶问题 上一篇SVM之核函数介绍了通过计算样本核函数,实际上将样本映射 ...
- log4cpp单例类封装
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 【Html 学习笔记】第八节——表单实践
列举一些实践的例子: 1.点击按钮后跳转: <html> <body> <form action="1.html"> First <inp ...
- Week14《Java程序设计》第14次作业总结
Week14<Java程序设计>第14次作业总结 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结与数据库相关内容. 2. 使用数据库技术改造你的系统 2.1 简述如何 ...
- 初次使用Quartus II 13.0的疑惑及解决方法
初次接触Quartus II 13.0,遇到了很多的问题,把问题总结如下: 1.Quartus II 13.0的安装及破解 下载地址:http://t.cn/Rh2TFcz,密码是:g3gc (参考贴 ...
- 浅析Postgres中的并发控制(Concurrency Control)与事务特性(上)(转)
这篇博客将MVCC讲的很透彻,以前自己懂了,很难给别人讲出来,但是这篇文章给的例子就让人很容易的复述出来,因此想记录一下,转载给更多的人 转自:https://www.cnblogs.com/flyi ...
- Ubuntu 中sendmail 的安装、配置与发送邮件的具体实现
一.安装 ubuntu中sendmail函数可以很方便的发送邮件,ubuntu sendmail先要安装两个包. 必需安装的两个包: 代码 sudo apt-get install sendmail ...
- (转)MapReduce Design Patterns(chapter 2 (part 2))(三)
Median and standard deviation 中值和标准差的计算比前面的例子复杂一点.因为这种运算是非关联的,它们不是那么容易的能从combiner中获益.中值是将数据集一分为两等份的数 ...
- [置顶]
曙光到来,我的新书《Android进阶之光》已出版
独立博客版本请点击这里 由来 2016年我开始建立了自己的知识体系,所有的文章都是围绕着这个体系来写,随着这个体系的慢慢成长,开始有很多出版社联系我写书,因为比较看好电子工业出版社,就顺理成章的开始了 ...