如何使用强化学习算法解决贪吃蛇问题(Neural Network Learns to Play Snake)
相关:
Neural Network Learns to Play Snake
https://github.com/greerviau/SnakeAI/
RL算法是有很多baseline算法的,算法library也是比较多的,因此使用ML/RL求解贪吃蛇问题的难点其实在于问题建模而不是使用RL方法求解。
在上面的相关链接中可以知道,这里面的建模方法为:
我们建设蛇的头可以发射8个射线,分别是8个方向,间隔45度角,具体如下:
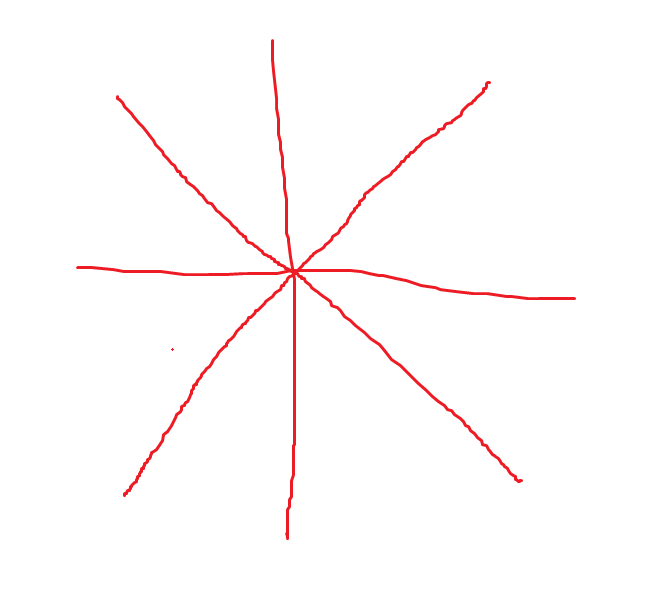
每个射线返回三个数值,分别是这个射线方向上食物、蛇身体、墙体到蛇头的距离,由此可以得到8*3=24个数值,该数值组成输入向量,输入到神经网络中,表示当前的蛇的状态,这样就完成了贪吃蛇的问题建模。
注意:
该问题的建模中蛇的头是没有方向的,也就是说蛇头是没有朝向的,蛇头可以想象为一个点,游戏中是以一个方格的形式出现。
Vision
The snake can see in 8 directions. In each of these directions the snake looks for 3 things:
- Distance to food
- Distance to its own body
- Distance to a wall
3 x 8 directions = 24 inputs. The 4 outputs are simply the directions the snake can move.

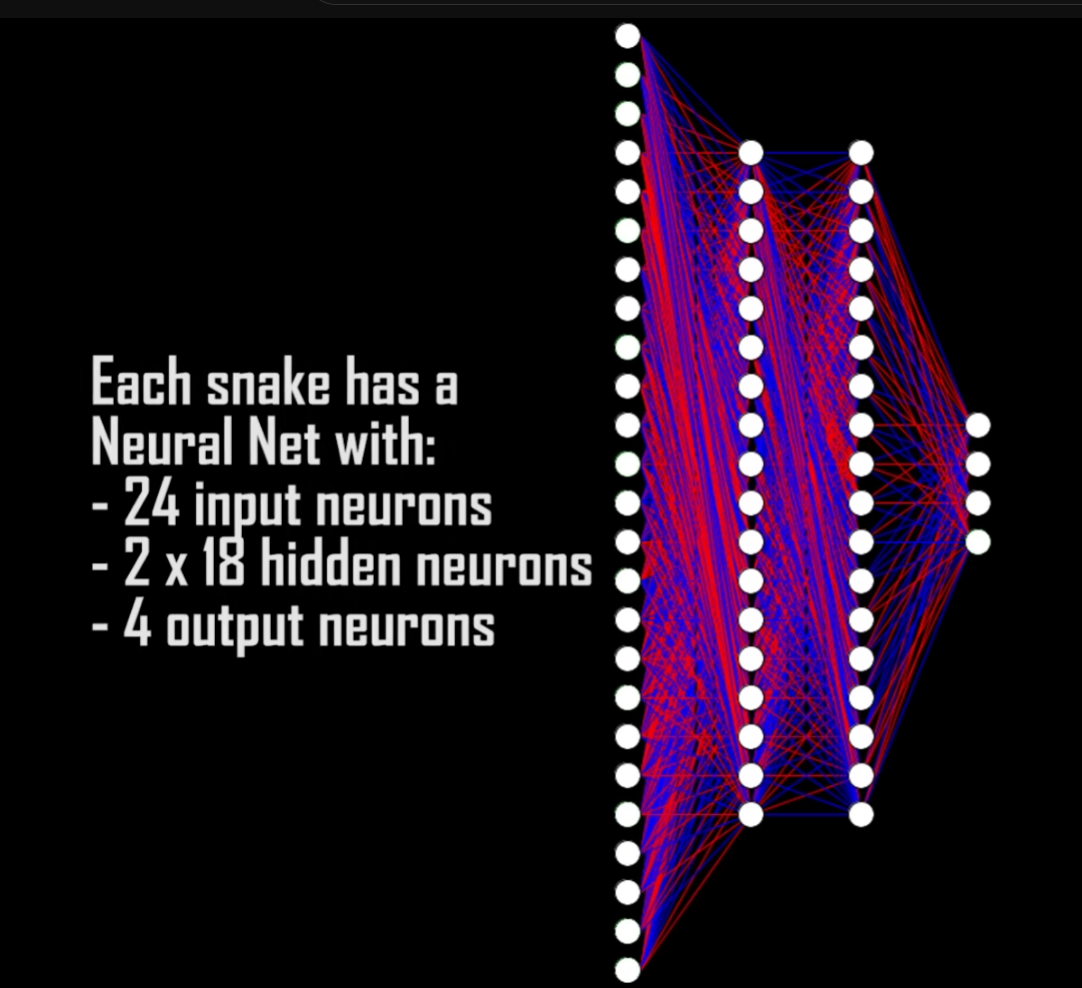
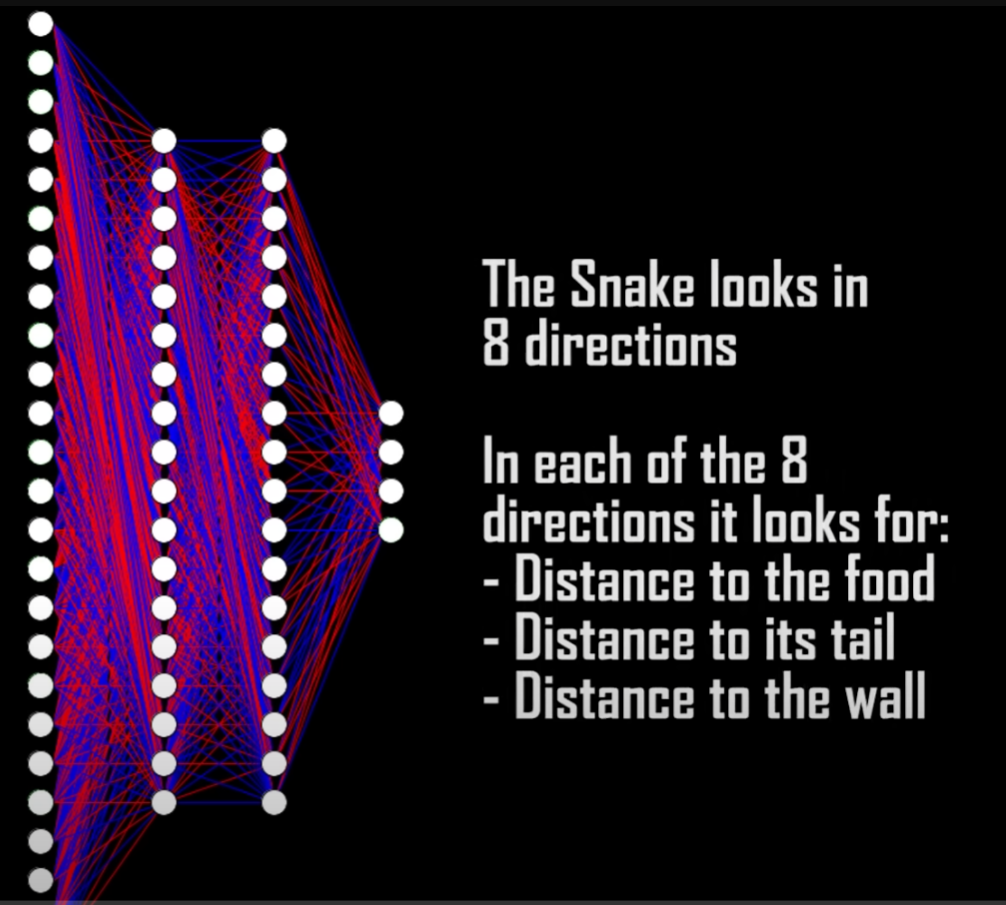
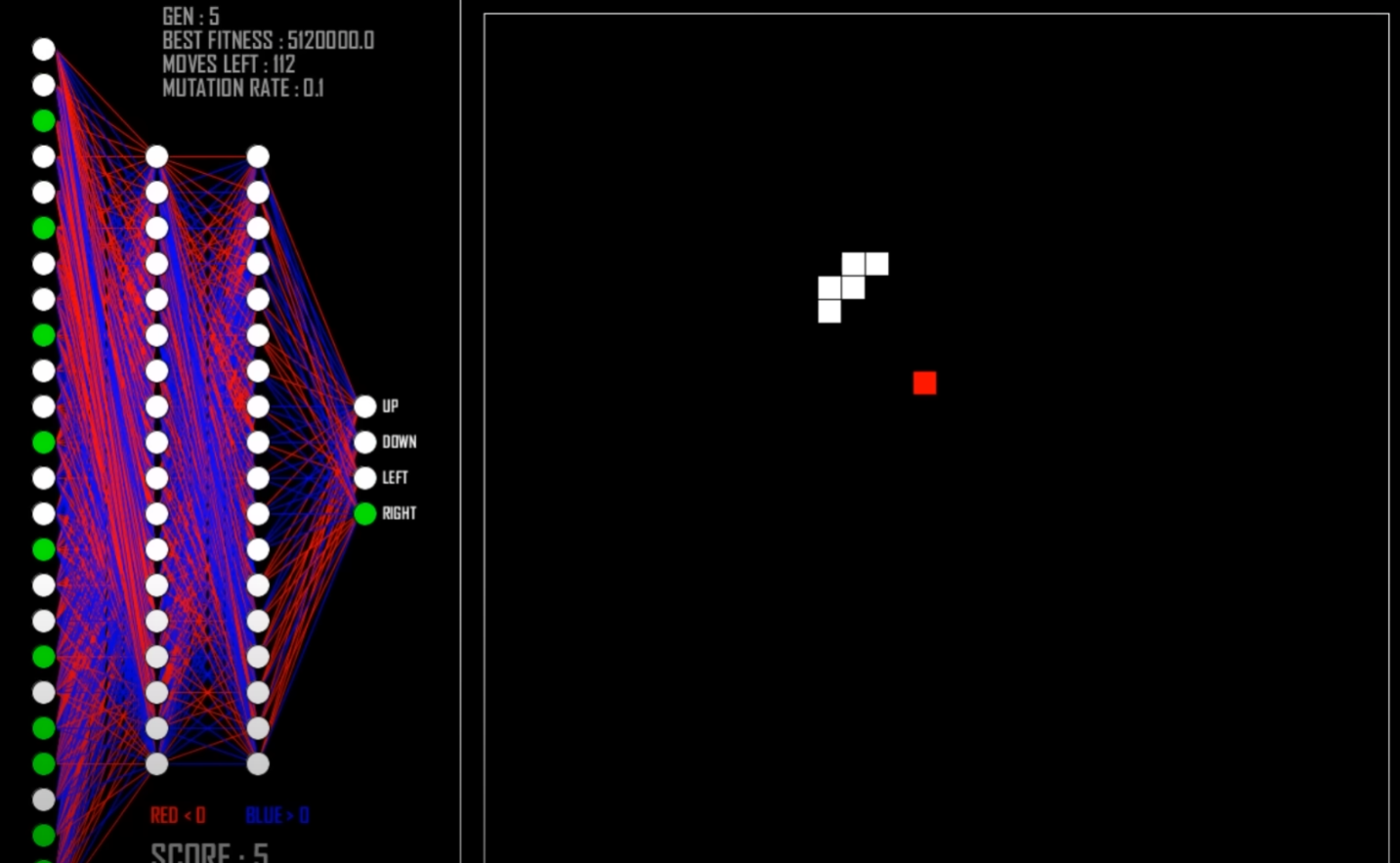
上面给出的是使用机器学习算法解决贪吃蛇问题,其实使用ML/RL方法解决贪吃蛇问题并不是最高效率的方法,由于贪吃蛇问题是可以使用数学方式求解析解的,或者使用数据结构建立好用算法策略来求解,总之,使用启发式算法或者数学解析解的方法可以更高效率求解贪吃蛇问题,不过由于本文主要是研究Reinforcement Learning问题,因此其他方法求解该问题不具体展开,下面给出其他方法的相关资料。
其他方法解决贪吃蛇问题:
How to Win Snake: The UNKILLABLE Snake AI
https://github.com/BrianHaidet/AlphaPhoenix/tree/master/Snake_AI_(2020a)_DHCR_with_strategy
强化学习算法library库:(集成库)
https://github.com/Denys88/rl_games
https://github.com/Domattee/gymTouch
个人github博客地址:
https://devilmaycry812839668.github.io/
如何使用强化学习算法解决贪吃蛇问题(Neural Network Learns to Play Snake)的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
- 深度学习:卷积神经网络(convolution neural network)
(一)卷积神经网络 卷积神经网络最早是由Lecun在1998年提出的. 卷积神经网络通畅使用的三个基本概念为: 1.局部视觉域: 2.权值共享: 3.池化操作. 在卷积神经网络中,局部接受域表明输入图 ...
- 强化学习算法Policy Gradient
1 算法的优缺点 1.1 优点 在DQN算法中,神经网络输出的是动作的q值,这对于一个agent拥有少数的离散的动作还是可以的.但是如果某个agent的动作是连续的,这无疑对DQN算法是一个巨大的挑战 ...
- 强化学习(十七) 基于模型的强化学习与Dyna算法框架
在前面我们讨论了基于价值的强化学习(Value Based RL)和基于策略的强化学习模型(Policy Based RL),本篇我们讨论最后一种强化学习流派,基于模型的强化学习(Model Base ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 【整理】强化学习与MDP
[入门,来自wiki] 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的 ...
- 贪吃蛇的java代码分析(一)
自我审视 最近自己学习java已经有了一个多月的时间,从一开始对变量常量的概念一无所知,到现在能勉强写几个小程序玩玩,已经有了长足的进步.今天没有去学习,学校里要进行毕业答辩和拍毕业照了,于是请了几天 ...
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
随机推荐
- redhat8 rhel8 启动grub损坏修复
环境:redhat8.4 RHEL8.4 服务器:华为G560 问题描述:调整了/etc/default/grub文件,重新生成/boot/grub2/grub.cfg导致机器启动失败,直接进入了re ...
- 旧笔记本安装Win8.1实录
昨天发现一台尘封已久的Lenovo ideapad Y550,给它装上了Windows 10 然后第二天系统挂掉了 挂的原因是半夜万恶之源Windows更新开始造孽了 刚好没电 文件全坏了 真 解除封 ...
- 初三奥赛模拟测试1--T1回文
初三奥赛模拟测试1--\(T1\)回文 HZOI 题意 给定一个 \(n \times m\) 的,由字符组成的矩阵 \(A\) , 问你由 \(( 1 , 1 )\) 开始,点 \(( i , j ...
- MSYS2、MinGW、Cygwin 关系梳理
还记得大一刚开始写 C 代码时,经常看到 MSYS2.MinGW.Cygwin 等名词.对于第一次接触编程的我来说这些名词让我眼花缭乱.当时查阅了一些资料,但是对于这些名词的解释始终让我云里雾里.现在 ...
- HTB-Runner靶机笔记
HTB-Runner靶机笔记 概述 Runner是HTB上一个中等难度的Linux靶机,它包含以下teamcity漏洞(CVE-2023-42793)该漏洞允许用户绕过身份验证并提取API令牌.以及d ...
- Splay/LCT 学习笔记
唔,其实我不会 Splay,但是我会 LCT. 众所周知,会 LCT 和会 Splay 是两回事,因为 LCT 只需要旋至根即可. 到现在还是不会,但是先把 LCT 的 Splay 写一下吧. 自己复 ...
- parser.add_argument
parser.add_argument 在解析参数时,有个地方很值得注意. --dict-name,会把dict-name解析为变量dict_name.也就是说会把破折号转成下划线.
- Dubbo框架的1个核心设计点
Java领域要说让我最服气的RPC框架当属Dubbo,原因有许多,但是最吸引我的还是它把远程调用这个事情设计得很有艺术. 1.Dubbo优点较多,我只钟情其一 1.1.优点 业内对于微服务之间调用的框 ...
- 面试官:GROUP BY和DISTINCT有什么区别?
在 MySQL 中,GROUP BY 和 DISTINCT 都是用来处理查询结果中的重复数据,并且在官方的描述文档中也可以看出:在大多数情况下 DISTINCT 是特殊的 GROUP BY,如下图所示 ...
- 【赵渝强老师】在Hive中使用Load语句加载数据
一.Hive中load语句的语法说明 Hive Load语句不会在加载数据的时候做任何转换工作,而是纯粹的把数据文件复制/移动到Hive表对应的地址.语法格式如下: LOAD DATA [LOCAL] ...