NodeJs 入门到放弃 — 常用模块及网络爬虫(二)
码文不易啊,转载请带上本文链接呀,感谢感谢 https://www.cnblogs.com/echoyya/p/14473101.html
Buffer (缓冲区)
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。二进制可以存储任意类型的数据,电脑中所有的数据都是二进制。
在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。
Buffer 与字符编码:当在 Buffer 和字符串之间转换时,可以指定字符编码。 如果未指定字符编码,则默认使用 UTF-8 。
Buffer 创建
Buffer对象可以通过多种方式创建,v6.0之前直接使用new Buffer()构造函数来创建对象实例,v6.0以后,官方文档建议使用Buffer.from() 创建对象。nodejs中文网、菜鸟教程-nodejs
Buffer.from(buffer):复制传入的 Buffer ,返回一个新的 Buffer 实例
Buffer.from(string[, encoding]):要编码的字符串。字符编码。默认值: 'utf8'。
Buffer.alloc(size[, fill[, encoding]]): 返回一个指定大小的 Buffer 实例,如果没有设置 fill,则默认填满 0
var buf = Buffer.from('Echoyya');
var buf1 = Buffer.from(buf);
console.log(buf); // <Buffer 45 63 68 6f 79 79 61>
buf1[0] = 0x65;
console.log(buf.toString());// Echoyya
console.log(buf1.toString()); // echoyya
var buf2 = Buffer.from('4563686f797961', 'hex'); // 设置编码
console.log(buf2); // <Buffer 45 63 68 6f 79 79 61>
console.log(buf2.toString()); // Echoyya
var buf3 = Buffer.from('4563686f797961'); // 默认编码
console.log(buf3); // <Buffer 34 35 36 33 36 38 36 66 37 39 37 39 36 31>
console.log(buf3.toString()); // 4563686f797961
var buf4 = Buffer.alloc(4);
console.log(buf4); // <Buffer 00 00 00 00>
Buffer 写入
buf.write(string[, offset[, length]][, encoding])
参数描述:
string - 写入缓冲区的字符串。
offset - 缓冲区开始写入的索引值,默认为 0 。
length - 写入的字节数,默认为 buffer.length
encoding - 使用的编码。默认为 'utf8' 。
根据 encoding 的字符编码写入 string 到 buf 中的 offset 位置。 length 参数是写入的字节数。
返回值:返回实际写入的大小。如果 buffer 空间不足, 则只会写入部分字符串。
//buffer的大小一旦被确定则不能被修改
var buf5 = Buffer.alloc(4);
console.log(buf5.length); // 4
var len = buf5.write("Echoyya");
console.log(buf5.toString()); // Echo
console.log("写入字节数 : "+ len); // 写入字节数 : 4
Buffer 读取
读取 Node 缓冲区数据:buf.toString([encoding[, start[, end]]])
参数描述:
encoding - 使用的编码。默认为 'utf8' 。
start - 指定开始读取的索引位置,默认为 0。
end - 结束位置,默认为缓冲区的末尾。
返回值:解码缓冲区数据并使用指定的编码返回字符串。
buf = Buffer.alloc(26);
for (var i = 0 ; i < 26 ; i++) {
buf[i] = i + 97;
}
console.log(buf); // <Buffer 61 62 63 64 65 66 67 68 69 6a 6b 6c 6d 6e 6f 70 71 72 73 74 75 76 77 78 79 7a>
console.log( buf.toString('ascii')); // abcdefghijklmnopqrstuvwxyz
console.log( buf.toString('ascii',0,5)); // abcde
console.log( buf.toString('utf8',0,5)); // abcde
console.log( buf.toString(undefined,0,5)); // abcde 默认utf8
更多>>
除上述最基本的读写操作外,还有许多强大的API:
缓冲区合并:Buffer.concat(list[, totalLength])
缓冲区比较:Buffer.compare(target[, targetStart[, targetEnd[, sourceStart[, sourceEnd]]]])
缓冲区判断:Buffer.isBuffer(obj)
缓冲区拷贝:Buffer.copy(target[, targetStart[, sourceStart[, sourceEnd]]])
fs (文件系统)
Node.js提供一组文件操作API,fs 模块可用于与文件系统进行交互。所有的文件系统操作都具有同步的、回调的、以及基于 promise 的形式。同步与异步的区别,主要在于有无回调函数,同步方法直接在异步方法后面加上Sync
const fs = require('fs');
读取文件
异步:fs.readFile(path, callback)
同步:fs.readFileSync(path)
fs.readFile('文件名', (err, data) => {
if (err) throw err;
console.log(data);
});
var data = fs.readFileSync('文件名');
获取文件信息
异步模式获取文件信息:fs.stat(path, callback)
- path - 文件路径。
- callback - 回调函数,带有两个参数如:(err, stats), stats 是 fs.Stats 对象。
fs.stat(path)执行后,将stats实例返回给回调函数。可以通过提供方法判断文件的相关属性。
var fs = require('fs');
fs.stat('./data', function (err, stats) {
// stats 是文件的信息对象,包含常用的文件信息
// size: 文件大小(字节)
// mtime: 文件修改时间
// birthtime:文件创建时间
// 等等...
console.log(stats.isDirectory()); //true
})
stats类中的方法有:
| 方法 | 描述 |
|---|---|
| stats.isFile() | 判断是文件返回 true,否则返回 false。 |
| stats.isDirectory() | 判断是目录返回 true,否则返回 false。 |
var fs = require("fs");
console.log("准备打开文件!");
fs.stat('./data', function (err, stats) {
if (err) {
return console.error(err);
}
console.log(stats);
console.log("读取文件信息成功!");
// 检测文件类型
console.log("是否为文件(isFile) ? " + stats.isFile());
console.log("是否为目录(isDirectory) ? " + stats.isDirectory());
});
写入文件
异步:fs.writeFile(file, data, callback)
同步:fs.writeFileSync(file, data),没有返回值
如果文件存在,该方法写入的内容会覆盖原有内容,反之文件不存在,调用该方法写入将创建一个新文件
const fs = require('fs')
var hello = '<h1>hello fs</h1>'
fs.writeFile('./index.html',hello,function(err){
if(err) throw err
else console.log('文件写入成功');
})
var helloSync= '<h1>hello fs Sync</h1>'
fs.writeFileSync('./index.html',helloSync)
删除文件
异步:fs.unlink(path, callback)
同步:fs.unlinkSync(path),没有返回值
对空或非空的目录均不起作用。 若要删除目录,则使用 fs.rmdir()。
const fs = require('fs')
fs.unlink('./index.html',function(err){
if(err) throw err
else console.log('文件删除成功');
})
fs.unlinkSync('./index.html')
目录操作
创建目录
异步:
fs.mkdir(path, callback)同步:
fs.mkdirSync(path),没有返回值
读取目录文件
异步:
fs.readdir(path, callback),callback 回调有两个参数err, files,files是目录下的文件列表。同步:
fs.readdirSync(path)
const fs = require("fs"); console.log("查看 ./data 目录");
fs.readdir("./data",function(err, files){
if(err) throw err
else{
files.forEach( function (file){
console.log( file );
});
}
}); var files = fs.readdirSync('./data')
删除空目录
注:不能删除非空目录
异步:
fs.rmdir(path, callback),回调函数,没有参数同步:
fs.rmdirSync(path)
删除非空目录(递归)
实现思路:
fs.readdirSync:读取文件夹中所有文件及文件夹
fs.statSync:读取每一个文件的详细信息
stats.isFile():判断是否是文件,是文件则删除,否则递归调用自身
fs.rmdirSync:删除空文件夹
const fs = require('fs') function deldir(p) {
// 读取文件夹中所有文件及文件夹
var list = fs.readdirSync(p)
list.forEach((v, i) => {
// 拼接路径
var url = p + '/' + v
// 读取文件信息
var stats = fs.statSync(url)
// 判断是文件还是文件夹
if (stats.isFile()) {
// 当前为文件,则删除文件
fs.unlinkSync(url)
} else {
// 当前为文件夹,则递归调用自身
arguments.callee(url)
}
})
// 删除空文件夹
fs.rmdirSync(p)
} deldir('./data')
Stream (流)
流是一组有序的、有起点、有终点的字节数据的传输方式,在应用程序中,各种对象之间交换与传输数据时:
总是先将该对象总所包含的数据转换为各种形式的流数据(即字节数据)
在流传输到达目的对象后,再将流数据转换为该对象中可以使用的数据
与直接读写文件的区别:可以监听它的'data',一节一节处理文件,用过的部分会被GC(垃圾回收),所以占内存少。 readFile是把整个文件全部读到内存里。然后再写入文件,对于小型的文本文件,没多大问题,但对于体积较大文件,使用这种方法,很容易使内存“爆仓”。理想的方法应该是读一节写一节
流的类型:
Readable - 可读操作。
Writable - 可写操作。
Duplex - 可读可写操作.
Transform - 操作被写入数据,然后读出结果。
常用的事件:
data - 当有数据可读时触发。
end - 没有更多的数据可读时触发。
error - 在接收和写入过程中发生错误时触发。
finish - 所有数据已被写入到底层系统时触发。
读取流
var fs = require('fs')
var data = '';
// 创建可读流
var readerStream = fs.createReadStream('./file.txt');
// 设置编码为 utf8。
readerStream.setEncoding('UTF8');
// 处理流事件 --> data, end, error
readerStream.on('data', function(chunk) {
data += chunk;
console.log(chunk.length) // 一节65536字节, 65536/1024 = 64kb
});
readerStream.on('end',function(){
console.log(data);
});
readerStream.on('error', function(err){
console.log(err.stack);
});
console.log("程序执行完毕");
写入流
var fs = require('fs')
var data = '创建一个可以写入的流,写入到文件 file1.txt 中';
// 创建写入流,文件 file1.txt
var writerStream = fs.createWriteStream('./file1.txt')
// 使用 utf8 编码写入数据
writerStream.write(data,'UTF8');
// 标记文件末尾
writerStream.end();
// 处理流事件 --> finish、error
writerStream.on('finish', function() {
console.log("写入完成。");
});
writerStream.on('error', function(err){
console.log(err.stack);
});
console.log("程序执行完毕");
管道 pipe
管道提供了一个输出流 -> 输入流的机制。通常用于从一个流中获取数据传递到另外一个流中。用一根管子(pipe)连接两个桶使得水从一个桶流入另一个桶,这样就可实现大文件的复制过程。
管道语法:reader.pipe(writer);
读取 input.txt 文件内容,并写入 output.txt 文件,两种实现方式对比:
var fs = require("fs");
var readerStream = fs.createReadStream('input.txt'); // 创建一个可读流
var writerStream = fs.createWriteStream('output.txt'); // 创建一个可写流
//1. 以流的方式实现大文件复制
readerStream.on('data',function(chunk){
writerStream.write(chunk) // 读一节写一节
})
readerStream.on('end',function(){ // 无可读数据
writerStream.end() // 标记文件末尾
writerStream.on('finish',function(){ // 所有数据已被写入
console.log('复制完成')
})
})
// 2. 以管道方式实现大文件复制
readerStream.pipe(writerStream);
链式流
将多个管道连接起来,实现链式操作
用管道和链式来压缩和解压文件:
var fs = require("fs");
var zlib = require('zlib');
// 压缩 input.txt 文件为 input.txt.gz
var reader = fs.createReadStream('input.txt')
var writer = fs.createWriteStream('input.txt.gz')
reader.pipe(zlib.createGzip()).pipe(writer);
// 解压 input.txt.gz 文件为 input.txt
var reader = fs.createReadStream('input.txt.gz')
var writer = fs.createWriteStream('input.txt')
reader.pipe(zlib.createGunzip()).pipe(writer);
path (路径)
是nodejs中提供的系统模块,不需安装,用于格式化或拼接转换路径,执行效果会因应用程序运行所在的操作系统不同,而有所差异。
常用方法:
| 方法 | 描述 |
|---|---|
| path.normalize(path) | 规范化给定的 path,解析 '..' 和 '.' 片段。 |
| path.join([...paths]) | 将所有给定的 path 片段连接到一起(使用平台特定的分隔符作为定界符),然后规范化生成的路径。如果路径片段不是字符串,则抛出 TypeError。 |
| path.dirname(path) | 返回路径中文件夹部分 |
| path.basename(path) | 返回路径中文件部分(文件名和扩展名) |
| path.extname(path) | 返回路径中扩展名部分 |
| path.parse(path) | 解析路径,返回一个对象,其属性表示 path 的有效元素 |
var path = require('path')
var p1 = "../../../hello/../a/./b/../c.html"
var p2 = path.normalize(p1)
console.log(path.normalize(p1)); // ../../../a/c.html
console.log(path.dirname(p2)) // ../../../a
console.log(path.basename(p2)) // c.html
console.log(path.extname(p2)) // .html
console.log(path.parse(p2)) // { root: '', dir: '..\\..\\..\\a', base: 'c.html', ext: '.html', name: 'c'}
console.log(path.join('/目录1', '目录2', '目录3/目录4', '目录5')); // '/目录1/目录2/目录3/目录4'
var pArr = ['/目录1', '目录2', '目录3/目录4', '目录5']
console.log(path.join(...pArr)); // '/目录1/目录2/目录3/目录4'
// path.join('目录1', {}, '目录2'); // 抛出 ' The "path" argument must be of type string. Received an instance of Object'
url (URL)
url :全球统一资源定位符,对网站资源的一种简洁表达形式,也称为网址
官方规定完整构成:协议://用户名:密码@主机名.名.域:端口号/目录名/文件名.扩展名?参数名=参数值&参数名2=参数值2#hash哈希地址
http 协议 URL常见结构:协议://主机名.名.域/目录名/文件名.扩展名?参数名=参数值&参数名2=参数值2#hash哈希地址
域名是指向IP地址的,需要解析到 IP 地址上,服务器与IP地址形成标识,域名只是人可以看懂的符号,而计算机并看不懂,所以需要 DNS 域名服务器来解析。
nodejs中提供了两套对url模块进行处理的API功能,二者处理后的结果有所不同:
旧版本传统的 API
实现了 WHATWG 标准的新 API
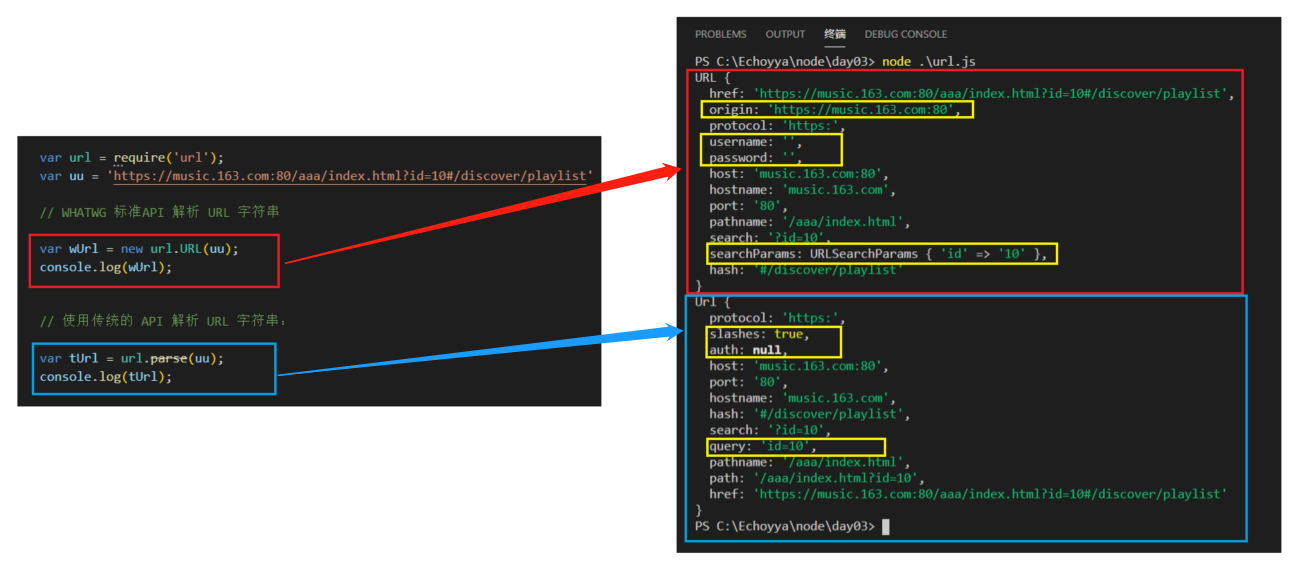
var url = require('url');
var uu = 'https://music.163.com:80/aaa/index.html?id=10#/discover/playlist'
// WHATWG 标准API 解析 URL 字符串
var wUrl = new url.URL(uu);
console.log(wUrl);
// 使用传统的 API 解析 URL 字符串:
var tUrl = url.parse(uu);
console.log(tUrl);
http (协议)
网络是信息传输、接收、共享的虚拟平台,而网络传输数据有一定的规则,称协议,HTTP就是其中之一,且使用最为频繁。
B/S开发模式
(Browser/Server,浏览器/服务器模式),浏览器(web客户端)使用HTTP协议就可以访问web服务器上的数据
客户端:发送请求,等待响应
服务器:处理请求,返回响应
定义、约束、交互特点
定义:HTTP 即 超文本传输协议,是一种网络传输协议,采用的是请求 / 响应方式传递数据,该协议规定了数据在服务器与浏览器之间,传输数据的格式与过程
约束:
约束了浏览器以何种格式两服务器发送数据
约束了服务器以何种格式接收客户端发送的数据
约束了服务器以何种格式响应数据给浏览器
约束了以何种格式接收服务器响应的数据
交互特点:一次请求对应一次响应,多次请求对应多次响应
http (模块)
由于大多数请求都是不带请求体的 GET 请求,因此最最最常用的方法:
http.get(url[, options][, callback])var http = require('http')
var fs = require('fs') http.get('http://www.baidu.com/',function(res){
// console.log(res);
// res 返回的即为一个可读流,
res.pipe(fs.createWriteStream('./a.html'))
})
网络爬虫
网络爬虫(又称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
小案例
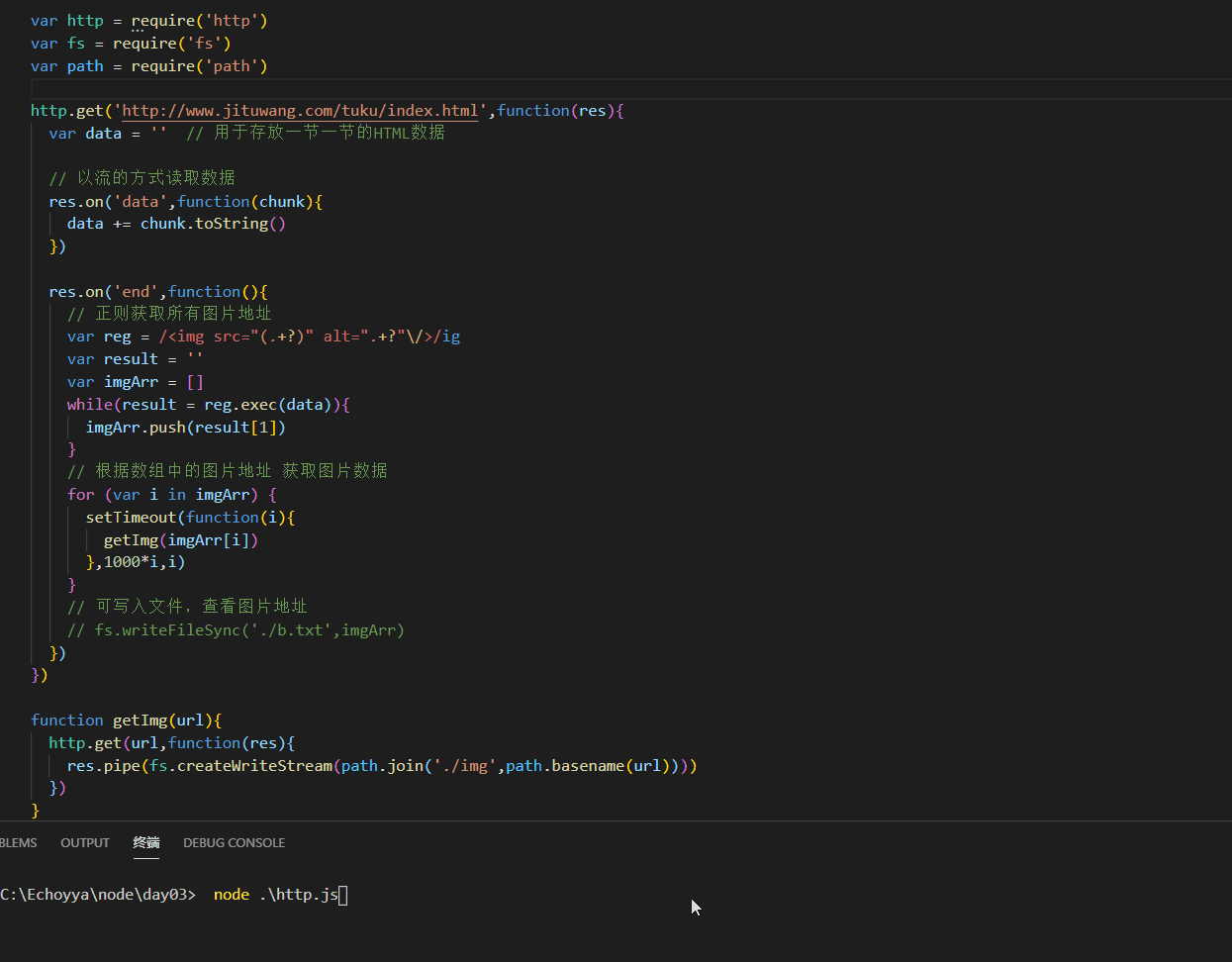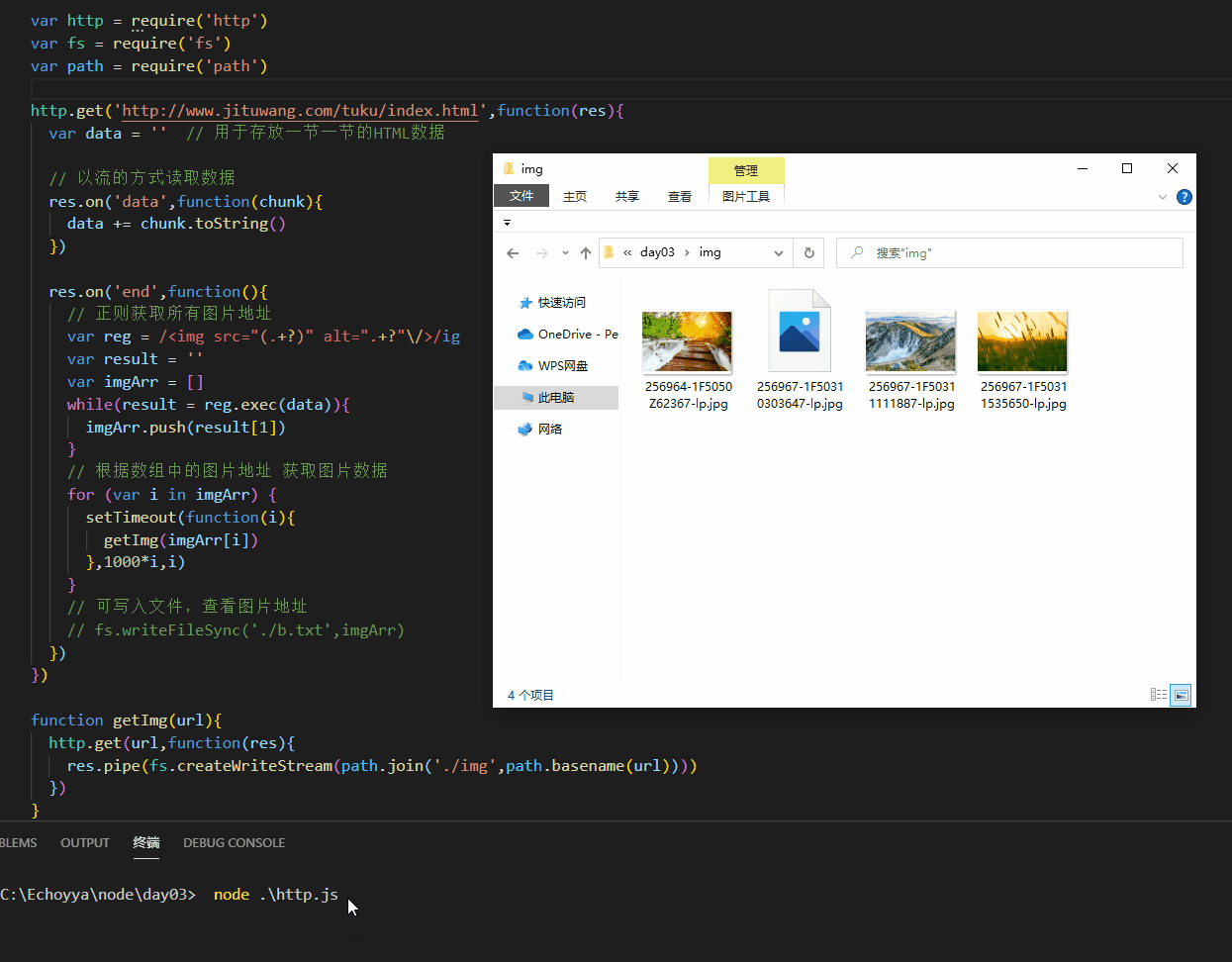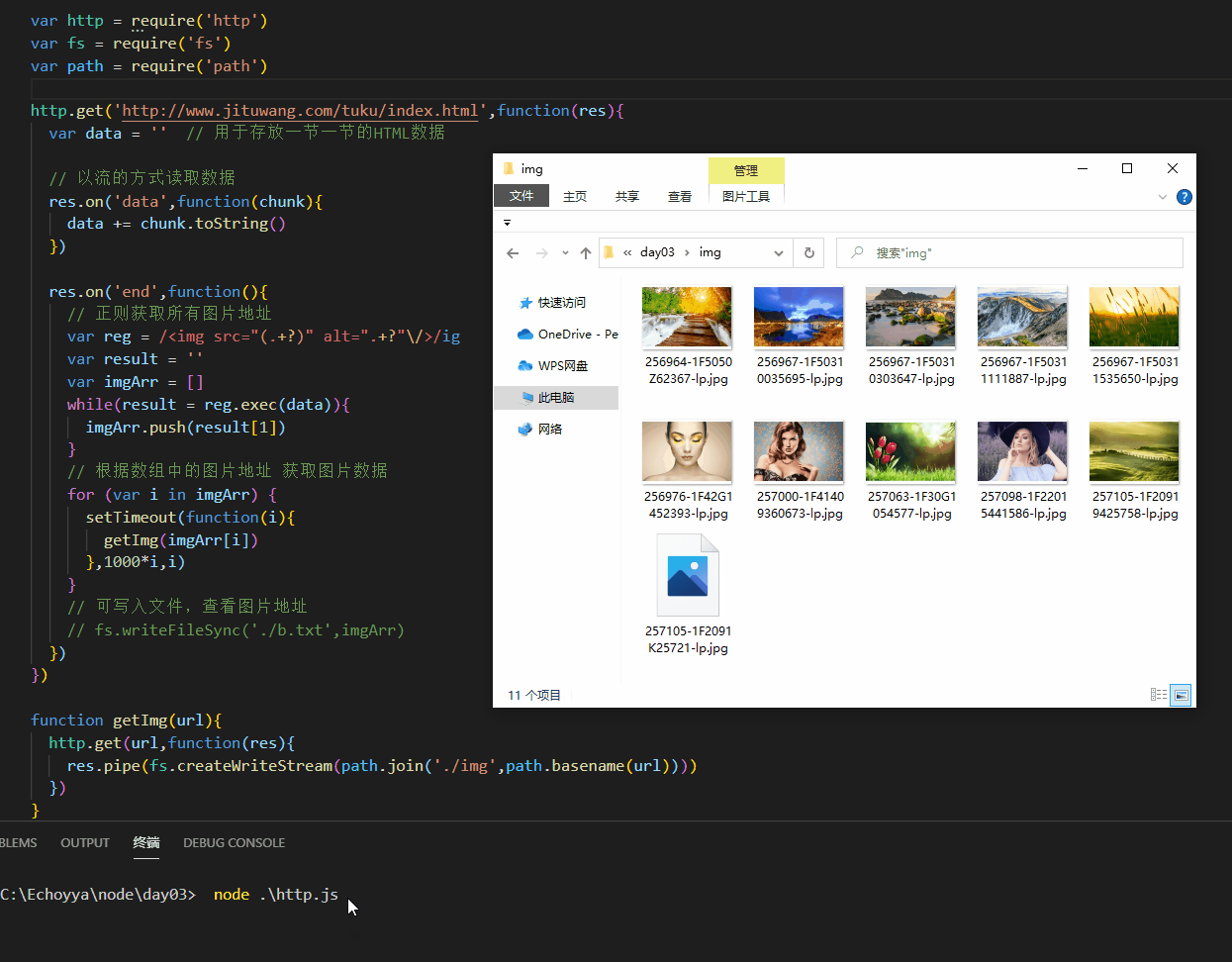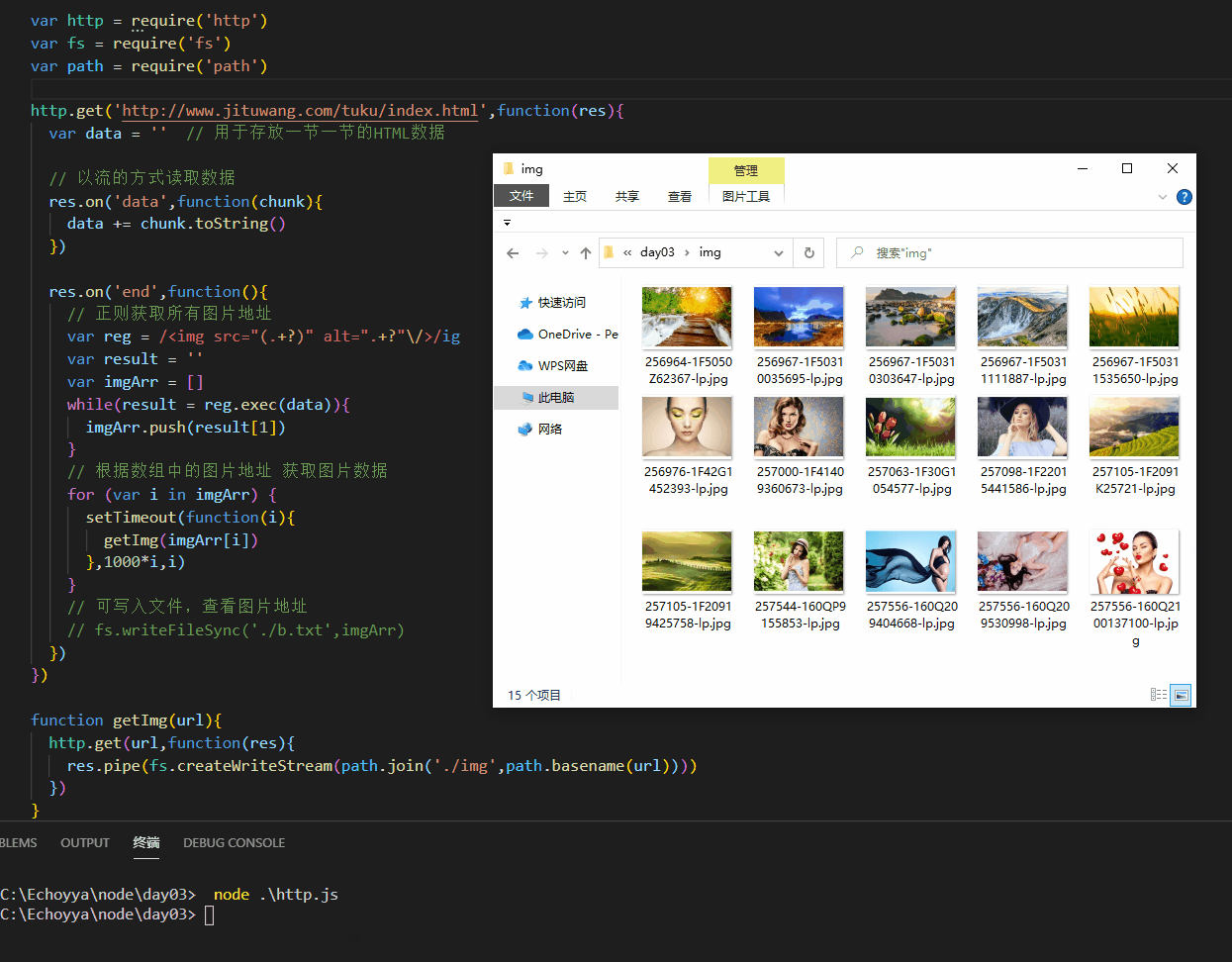
需求:写一个爬虫程序批量下载图片 http://www.nipic.com/photo/canyin/xican/index.html
思路:
打开对应网站查看内容,找图片地址,找规律
编写代码获取网站内html代码
通过正则表达式提取出图片地址
遍历图片地址数组,请求数据
将获取到的图片保存下来
var http = require('http')
var fs = require('fs')
var path = require('path')
http.get('http://www.jituwang.com/tuku/index.html',function(res){
var data = '' // 用于存放一节一节的HTML数据
// 以流的方式读取数据
res.on('data',function(chunk){
data += chunk.toString()
})
res.on('end',function(){
// 正则获取所有图片地址
var reg = /<img src="(.+?)" alt=".+?"\/>/ig
var result = ''
var imgArr = []
while(result = reg.exec(data)){
imgArr.push(result[1])
}
// 根据数组中的图片地址 获取图片数据
for (var i in imgArr) {
setTimeout(function(i){
getImg(imgArr[i])
},1000*i,i)
}
// fs.writeFileSync('./b.txt',imgArr) // 可写入文件,查看图片地址
})
})
function getImg(url){
http.get(url,function(res){
res.pipe(fs.createWriteStream(path.join('./img',path.basename(url))))
})
}
for循环请求数据时,为避免对其服务器造成压力,设置定时器,每隔一秒请求一次,将读到的数据,存储为与服务器上同名。利用上述path模块提供的方法,path.basename(url)
NodeJs 入门到放弃 — 常用模块及网络爬虫(二)的更多相关文章
- nodejs入门开发与常用模块
npm:NodeJs包管理器 express:服务器端比较流行的MVC框架,处理服务请求,路由转发,逻辑处理 http://socket.io:实现服务端和客户端socket通信解决方案 ); // ...
- nodejs入门API之net模块
net常用API解析以及应用 手动解析HTTP请求头 基于网络模块net与文件模块fs搭建简易的node服务 net模块部分API参数详细解析 一.net常用API解析以及简单的应用 net模块的组成 ...
- Python从入门到放弃系列(Django/Flask/爬虫)
第一篇 Django从入门到放弃 第二篇 Flask 第二篇 爬虫
- [Python 从入门到放弃] 6. 文件与异常(二)
本章所用test.txt文件可以在( [Python 从入门到放弃] 6. 文件与异常(一))找到并自行创建 现在有个需求,对test.txt中的文本内容进行修改: (1)将期间的‘:’改为‘ sai ...
- Python初学者之网络爬虫(二)
声明:本文内容和涉及到的代码仅限于个人学习,任何人不得作为商业用途.转载请附上此文章地址 本篇文章Python初学者之网络爬虫的继续,最新代码已提交到https://github.com/octans ...
- NodeJs 入门到放弃 — 网络服务器(三)
码文不易啊,转载请带上本文链接呀,感谢感谢 https://www.cnblogs.com/echoyya/p/14484454.html 目录 码文不易啊,转载请带上本文链接呀,感谢感谢 https ...
- NodeJs 入门到放弃 — 入门基本介绍(一)
码文不易啊,转载请带上本文链接呀,感谢感谢 https://www.cnblogs.com/echoyya/p/14450905.html 目录 码文不易啊,转载请带上本文链接呀,感谢感谢 https ...
- nodejs入门API之http模块
HTTP上的一些API及应用 HTTP模块上的服务(server)与响应(response) HTTP模块上的消息(message) HTTP模块上的代理(agent)与请求(request) HTT ...
- nodejs入门API之fs模块
fs模块下的类与FS常量 fs模块下的主要方法 fs的Promise API与FileHandle类 一.fs模块下的类 1.1 fs.Dir:表示目录流的类,由 fs.opendir().fs.op ...
随机推荐
- 2015 Multi-University Training Contest 1(7/12)
2015 Multi-University Training Contest 1 A.OO's Sequence 计算每个数的贡献 找出第\(i\)个数左边最靠右的因子位置\(lp\)和右边最靠左的因 ...
- hdu4028 The time of a day (map+dp)
Problem Description There are no days and nights on byte island, so the residents here can hardly de ...
- 洛谷 P2391.白雪皑皑 (并查集,思维)
题意:有\(n\)个点,对这些点进行\(m\)次染色,第\(i\)次染色会把区间\((i*p+q)\ mod\ N+1\)和\((i*q+p)\ mod\ N+1\)之间的点染成颜色\(i\),问最后 ...
- 一张图解决ThreadLocal
一张图解决ThreadLocal 一.前言 年底梳理知识体系时,研究了一下ThreadLocal的源码,整理了一张核心图. 想着,都走到这一步了,那就写一篇深度解读的文章吧.看过我之前文章的小伙伴都知 ...
- PHP 弱类型 && CODE/COMMADN injection
CODE/COMMAND INJECTION CODE INJECTION https://www.freebuf.com/sectool/168653.html EXAMPLE1 <?php ...
- leetcode 4 寻找两个有序数组的中位数 二分法&INT_MAX
小知识 INT_MIN在标准头文件limits.h中定义. #define INT_MAX 2147483647#define INT_MIN (-INT_MAX - 1) 题解思路 其实是类似的二分 ...
- PTA L1-006 连续因子【暴力模拟】
一个正整数N的因子中可能存在若干连续的数字.例如630可以分解为3*5*6*7,其中5.6.7就是3个连续的数字.给定任一正整数N,要求编写程序求出最长连续因子的个数,并输出最小的连续因子序列. 输入 ...
- List遍历以及剔除指定数据
一.list三种遍历方式 1.for循环 List<String> list = new ArrayList<String>(); list.add("A" ...
- Linux Bash Script conditions
Linux Bash Script conditions shell 编程之条件判断 条件判断式语句.单分支 if 语句.双分支 if 语句.多分支 if 语句.case 语句 refs http:/ ...
- website i18n and L10n all in one
website i18n and L10n all in one Localization & Internationalization 本地化 & 国际化 https://www.w ...