用实战玩转pandas数据分析(一)——用户消费行为分析(python)
CD商品订单数据的分析总结。根据订单数据(用户的消费记录),从时间维度和用户维度,分析该网站用户的消费行为。通过此案例,总结订单数据的一些共性,能通过用户的消费记录挖掘出对业务有用的信息。对其他产品的线上消费数据分析有一定的借鉴价值,能达到举一反三的效果。
订单交易数据分析
一、案例背景
CDNOW是一家美国在线零售商,主营商品为CD唱片,ToC业务。1998年上市,2000年被贝塔斯曼收购。网上有一份用户订单消费数据集:CDNOW订单数据集
二、案例目的
这份数据集只包含了四个基本信息字段:用户ID、购买日期、购买数量、购买金额。本案例的目标:通过这个四个字段,在数据集时间窗口内,分析用户消费的基本概况;通过用户分层、周期分析、复购率和回购率分析等,梳理现阶段用户的价值现状,并尝试根据业务经验提一些运营建议。
三、分析框架
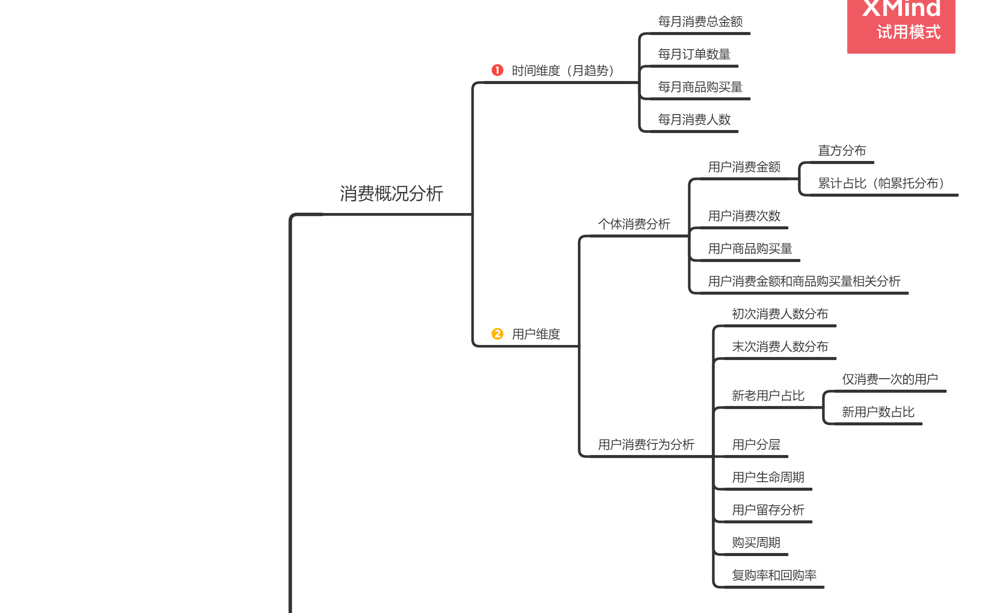
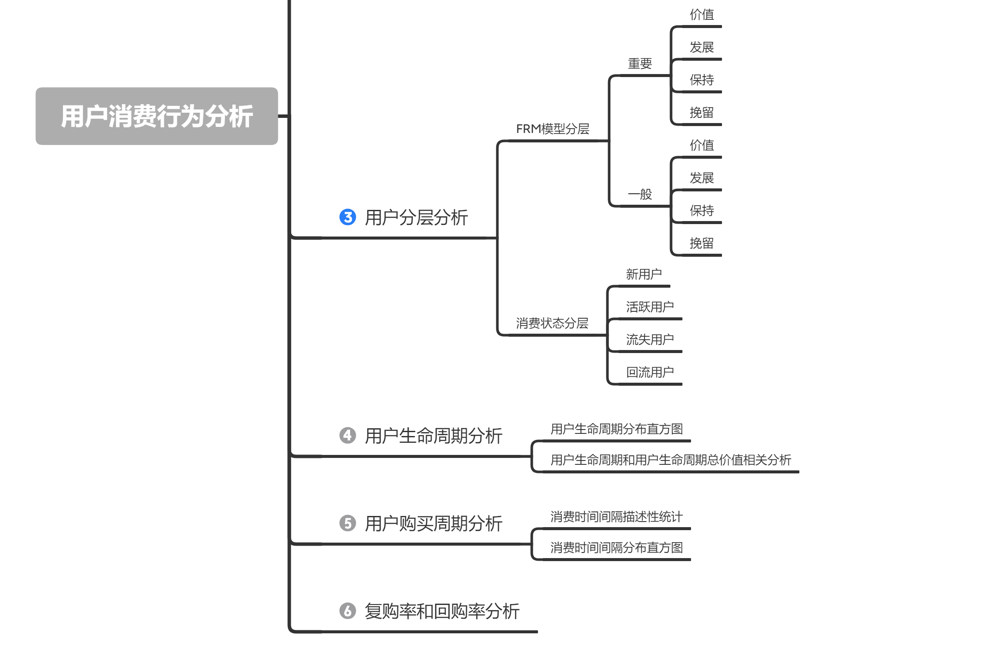
四、分析过程
4.1数据加载和初探
(1)导入相关包、设置风格样式
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
# jupter魔法函数,设置可视化页内显示
%matplotlib inline
# 正常显示中文和负号
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 画图的样式风格设置为:ggplot
plt.style.use('ggplot')
(2)导入数据集
字段信息:
- user_id:用户ID
- order_dt:购买日期
- order_products:购买数量
- order_amount:购买金额
源数据为txt文件,通过pd.read_csv()。分割符为空白字符串,用正则表达'\s+',匹配任意空白符。
# 导入数据集
os.chdir(r'D:/数据集/电商零售类/CDNOW数据集/')
columns = ['user_id', 'order_dt', 'order_products', 'order_amount']
df = pd.read_csv('CDNOW_Dataset.txt',delimiter='\s+',names=columns)
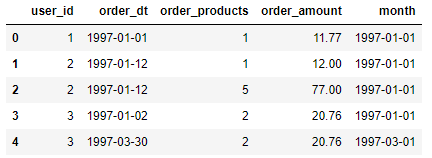
df.head()

从前5行数据中可以发现:同一个用户在同一天可能购买多次、同一用户在不同时间购买多次等消费现象。
(3)数据清洗
df.info()

源数据质量描述:数据不存在缺失值,但购买日期order_dt字段数据类型为int64,需要转换为日期型datetime64[ns]
# 'order_dt'字段类型转换
df['order_dt'] = pd.to_datetime(df['order_dt'],format='%Y%m%d')
按月份分析销售趋势,新增month字段。(tip:datetime64[M]:每月的第一天日期,datetime64[Y]:每年的第一天日期。)
# 新增month字段
df['month'] = df['order_dt'].values.astype('datetime64[M]')
# 查看字段的数据类型
df.dtypes

df.head()
(4)数据初探
# 数据描述性统计分析
df.describe()
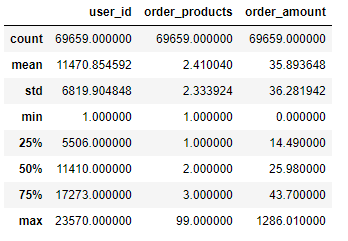
描述性统计分析:
- 用户平均每笔订单购买2.4件商品,中位数为2.0,数据呈现正偏态(右偏)特征,最大值99,需要关注极值点(为何该用户同时买了那么多CD);
- 用户平均订单金额为35.89,中位数为25.98,数据同样呈现正偏态(右偏)特征,大部分订单金额都集中在中小额范围(14.4~43.7),存在极值点。
4.2消费概况分析
4.2.1时间维度分析消费情况(按月)
按月份降采样,统计信息。
df_dtindex = df.set_index(['order_dt'])
# 统计每月订单商品量、每月订单金额
month_grouped = df_dtindex.resample('m').sum()[['order_products','order_amount']]
# 统计每月消费人数
month_grouped['user_num'] = df_dtindex.resample('m')['user_id'].nunique()
# 统计每月订单数
month_grouped['order_quantity'] = df_dtindex.resample('m')['user_id'].size()
month_grouped.head()

每月订单商品量、每月订单金额、每月消费人数、每月订单数趋势图。
month_grouped.plot(kind='line',subplots=True,figsize=(10,8))

从折线趋势图可以看出:
- 1-3月份订单商品量和订单金额都较高,4月份急速下降后趋于平缓;
- 1-3月份月均消费人数在7800~9600之间,4月份开始月均消费人数开始下降,在2000人次附近波动,反应用户粘性不高,留存率低。
出现以上的原因,可能是该网站1-3月份做大推广;或者明星新CD专辑集中发布,大量粉丝涌入网站购买。
4.2.2用户维度分析消费情况
4.2.2.1个体消费分析
(1)用户消费次数、消费金额、订单商品量描述性统计
# 对用户分组,并统计每个用户的消费次数、消费金额、订单商品量
user_grouped = df.groupby('user_id').agg({'user_id': 'count','order_amount': 'sum','order_products': 'sum'})
# 列字段重命名consumptions:消费次数
user_grouped.rename(columns={'user_id':'consumptions'},inplace=True)
# 描述性统计
user_grouped.describe()
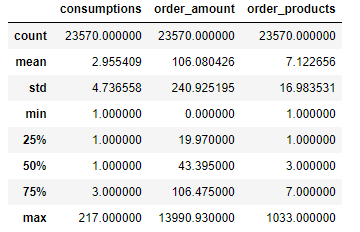
用户维度消费情况描述性统计分析:
- 用户平均消费次数为2.96次,中位数1,用户消费次数数据右偏,反映时间段内大部分用户只在该网站消费1次。
- 订单金额和订单商品量的均值与75%分位值接近,反映订单金额和订单商品量主要由少部分用户贡献,要关注极值点影响。
(2)用户消费次数、消费金额、订单商品量分布直方图
plt.figure(figsize=(20,4))
plt.subplot(1,3,1)
user_grouped['consumptions'].plot.hist(bins=15,title='consumptions')
plt.subplot(1,3,2)
user_grouped['order_amount'].plot.hist(bins=30,title='order_amount')
plt.subplot(1,3,3)
user_grouped['order_products'].plot.hist(bins=30,title='order_products')
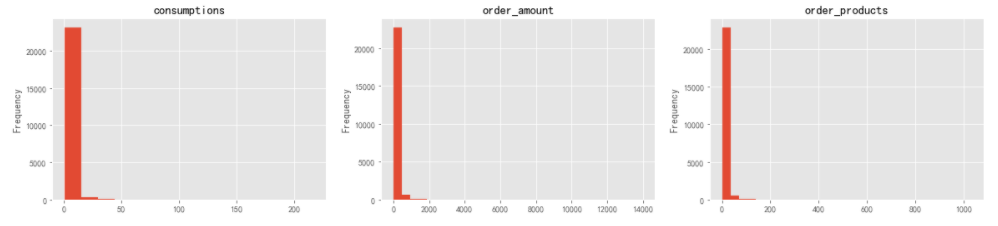
数据分布存在一定的极值干扰,需要对极值进行过滤处理再观察数据分布特征。对于非正态分布数据集,根据切比雪夫定理:所有数据,至少有24/25(或96%)的数据位于均值±5个标准差范围内。根据描述性统计,分别计算过滤条件:
- consumptions:mean + 5std = 2.95+5*4.73=26.6,选择27作为过滤阈值
- order_amount:160.08+5*240.93=1310.73,选择1310作为过滤阈值
- order_products:7.12+5*16.98=92.02,选择95作为过滤阈值
# 过滤极值,画分布直方图
plt.figure(figsize=(20,4))
plt.subplot(1,3,1)
user_grouped.query('consumptions<27')['consumptions'].plot.hist(bins=15,title='consumptions',xlim=(0,27))
plt.subplot(1,3,2)
user_grouped.query('order_amount<1312')['order_amount'].plot.hist(bins=30,title='order_amount')
plt.subplot(1,3,3)
user_grouped.query('order_products<95')['order_products'].plot.hist(bins=30,title='order_products')
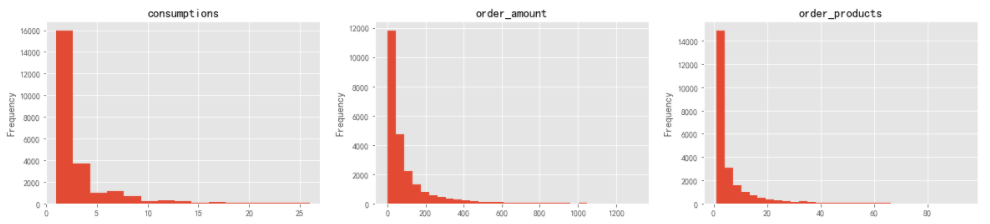
过滤掉极值之后,从用户消费次数、消费金额、订单商品量分布直方图可以明显看出:数据大多数集中在低值区,反映大部分用户消费水平一般,贡献价值一般。符合“长尾型”消费类数据分布特征。
(3)用户人数累计消费金额占比
user_cumsum = user_grouped.sort_values(['order_amount']).apply(lambda x:x.cumsum()/x.sum())
user_cumsum.reset_index()['order_amount'].plot(xticks=(range(0,25000,2500)),title='用户人数累计消费金额占比')
plt.xlabel('人数')
plt.ylabel('占比')

由上图可知:
50%的用户(总共有23570名用户)仅贡献了15%的消费额度,70%的用户仅贡献了20%的消费额度,85%的用户仅贡献了40%的消费额度,而前3570(占比15%)多用户就贡献了60%的消费额度。可以重点关注一下这15%客户更多相关数据,总结用户特征,挖掘更多消费机会。
(4)用户消费金额和订单商品量之间相关性分析
user_grouped.query('order_amount<8000').plot.scatter(x='order_products',y='order_amount',title='用户消费金额和商品购买量散点分布')
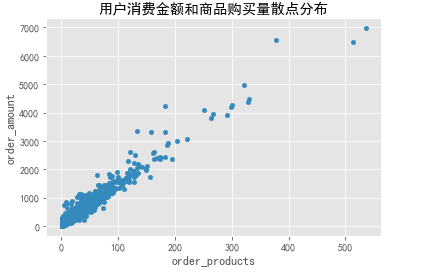
由散点分布图可以看出:
用户的消费金额和订单商品量几乎成线性关系:购买的商品越多,消费金额越大。反映该网站的商品比较单一,或者单价比较稳定。在不影响主商品的前提下,可以考虑一些辅助商品铺设。
4.2.2.2 用户消费行为分析
(1)用户第一次消费(首购)和最后一次消费时间分布(按月)
# 用户初次消费时间分布:统计每个用户消费的时间最小值,再计算相同日期的频数
df.groupby('user_id')['order_dt'].min().value_counts().plot(title='用户初次消费时间分布图')
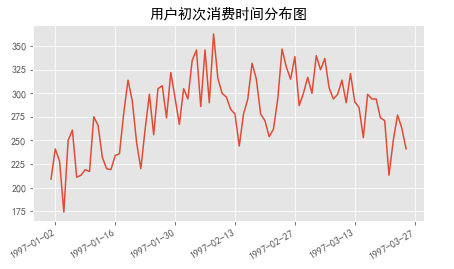
由初次消费分布图可知:
用户初次购买时间集中在前三个月,其中2月9日到2月25日之间有波动。可能是该网站做了推广或者明星集中发专辑,导致大量新用户涌入网站购买CD。
# 用户最后一次消费时间分布
df.groupby('user_id')['order_dt'].max().value_counts().plot(title='用户最后一次消费时间分布图')
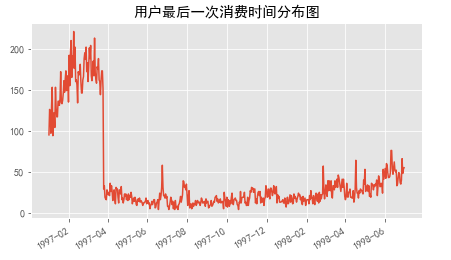
由末次消费分布图上图可知:
- 用户最后一次消费也集中在前三个月,反映有大量用户在三个月内就流失掉了;
- 首购和最后一次消费都集中前三个月,可能是这部分新增用户在前三月就流失掉了。可能是著名明星集中发专辑,新增用户对其他CD专辑不感兴趣。(这部分新用户是某类明星的粉丝)
- 随时间递增,最后一次消费人数也在缓慢递增,用户流失呈上升趋势。可能是运营没跟上,老用户忠诚度也下降了。
从这里简要看出,要提高网站的销售金额,有两个关键点:
- 第一,分析新增用户的购物喜好,推送同类或类似风格产品,确保在用户流失之前留住用户;
- 第二,分配合理资源维护老用户,给老用户做合理的引导消费通知。
(2)新老用户占比分析
仅消费一次的用户占比
# 仅消费一次的用户占比=消费一次的用户人数/总用户数
user_grouped[user_grouped['consumptions']==1]['consumptions'].count()/user_grouped['consumptions'].count()
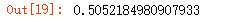
结果表明:有一半用户只消费了一次。
注意:这里不能用第一次和最后一次消费日期相同,来判断该用户只消费了一次,因为有可能同一天该用户消费了两次。这样算出来的指标应该叫‘仅消费一天的用户占比’,不过两者结果相差应该不是很大。
每月新用户占比
4.3用户分层分析
4.3.1FRM模型对用户分层
R(Recency,近度/最近一次消费)F(Frequency,消费频次)M(Monetary,消费金额)
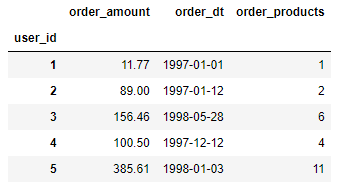
# 首先,数据透视表求出用户的最近一次消费时间、消费次数,消费总金额
rfm = df.pivot_table(index='user_id',
values=['order_dt','order_products','order_amount'],
aggfunc={'order_dt': 'max',
'order_products': 'count',
'order_amount': 'sum'})
rfm.head()
# 其次,计算R值:最近一次消费(距今天数),数据比较久远,这里选择order_dt的最大值为‘今天’
# 时间格式相减,得到xxx days,需要除以一个单位'D'
rfm['R'] = (rfm.order_dt-rfm.order_dt.max())/np.timedelta64(1,'D')
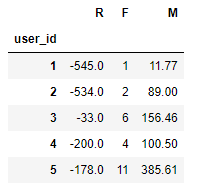
rfm = rfm.rename(columns={'order_amount': 'M', 'order_products': 'F'})[['R','F','M']]
rfm.head()
# 根据判断阈值(这里选择每列均值作为阈值),添加客户分层标签字段
# 定义用户分层函数
def rfm_level(data):
# 和阈值(均值)做对比:高于阈值赋值为1,低于阈值赋值为0
level = data.apply(lambda x:'1' if x>=0 else '0')
# 构建分类字典
d = {
'111': '重要价值客户',
'011': '重要保持客户',
'101': '重要发展客户',
'001': '重要挽留客户',
'110': '一般价值客户',
'010': '一般保持用户',
'100': '一般发展客户',
'000': '一般挽留客户'
}
# 拼接字符串
label = level.R + level.F + level.M
# 各行根据拼接字符串的结果(键),返回客户类型(值)
return d[label]
# 逐行传入
rfm['label'] = (rfm-rfm.mean()).apply(rfm_level,axis=1)
rfm.head()

plt.figure(figsize=(12,6),dpi=80)
plt.subplot(1,2,1)
rfm.label.value_counts().plot.pie(autopct='%3.1f%%',title='RFM模型分层用户人数占比图')
plt.subplot(1,2,2)
rfm.groupby('label').M.sum().plot.pie(autopct='%3.1f%%',title='RFM模型分层用户消费金额占比图')
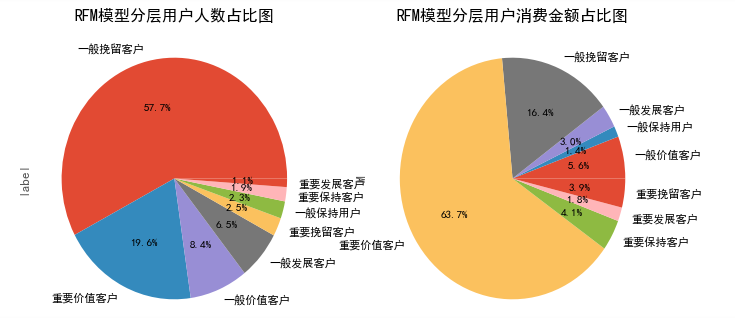
由上图可知:
- ‘一般挽留客户’人数占比最多,达到57.7%。但贡献的消费金额仅占比16.4%
- ‘重要价值客户’人数占比为19.6%,贡献消费占比却达到了63.7%
此次分析中,R、F、M三个维度的阈值是依据各自的平均值选定,实际业务要根据不同场景设定合适的阈值,切莫不要为了数据好看划分等级。在资源的有限情况下,尽量用小部分的用户覆盖大部分的额度。在运营策略上,应结合用户分层的结果,针对不同的用户分类用户制定不同的运营策略:
- 针对重要价值客户,应保持好现状;
- 针对重要发展客户,由于其价值高但是频次低,应采取合适的策略来刺激其消费频率;
- 针对重要保持用户,应采取合适的策略来将其召回,留住该用户;
- 针对重要挽留用户,召回他并刺激其消费;
- 针对一般价值用户,可以通过发放大额面值优惠券等方式刺激消费力度;
- 其余几类用户都要在考虑成本、资源的情况下采取相应的策略召回、刺激消费。
4.3.2根据消费状态对用户分层
用户分层的目的在于区分不同价值的用户,对不同价值的用户、不同阶段的用户采用精准、细化的运营方案。在实际业务场景中,常常把用户分为新客,不活跃用户,活跃用户,回流用户。
指标口径说明:
- 新用户:时间窗口内,首次消费的用户。
- 不活跃用户(流失用户):时间窗口内,未消费的老客。
- 活跃用户:本时间窗口内有消费,上一个时间窗口也有消费的用户。
- 回流用户:上一个时间窗口中没有消费,而在当前时间窗口内有过消费的老客。
# 首先,以月份为统计窗口,制作透视表:得到每个月用户的消费次数
# 缺失值NaN(该月份无消费记录)用0填充
pivoted_counts = df.pivot_table(index='user_id',
columns='month',
values='order_dt',
aggfunc='count').fillna(0)
pivoted_counts.head()
上面的NaN值用0填充:0不一定代表本月没有消费,也有可能该用户在当月没有注册,为了判断该用户在当月是否为新用户,还需用自定义函数来判断。
# 然后,自定义用户分层函数
def user_status(data):
'''
unreg:未注册用户
new:新用户
unactive:不活跃用户(流失用户)
active:活跃用户
return:回流用户
'''
status = []
# 判断第一月是否为新用户
if data[0] == 0:
status.append('unreg')
else:
status.append('new')
# 循环判断每一个月的用户状态
for i in range(17):
# 若本月未消费
if data[i+1]==0:
# 上一个月也未消费,则本月为未注册用户
if status[i] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
# 本月消费
else:
# 上一月为未注册用户,则本月为新用户
if status[i] == 'unreg':
status.append('new')
# 上一月为不活跃用户,则本月为回流用户
elif status[i] == 'unactive':
status.append('return')
# 上一月消费,本月也消费,则本月为活跃用户
else:
status.append('active')
return pd.Series(status,index=data.index)
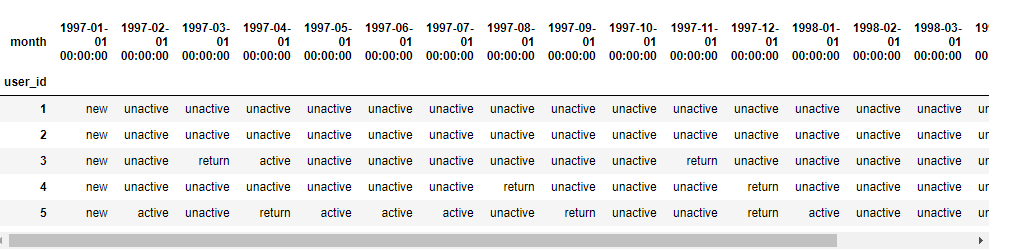
pivoted_user_status = pivoted_counts.apply(user_status, axis=1)
pivoted_user_status.head()
# 统计每个月不同状态的用户数
# 把未注册unreg替换为NaN值,count不会计数
user_status_counts = pivoted_user_status.replace('unreg',np.NaN).apply(pd.value_counts)
user_status_counts

# 绘制不同类型用户数量随时间变化的曲线
user_status_counts.T.plot(figsize=(10, 4),title='不同类型用户数量随时间变化的曲线图',grid=False)
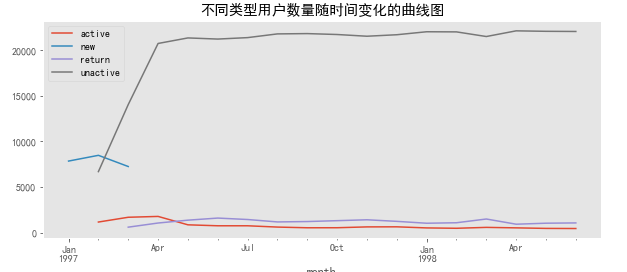
由上图可知:
- 前三个月新用户大量涌入,后期没有新增;
- 后期不活跃用户数量非常多,基本每个月20000人以上;
- 活跃用户前几月较多,后期逐渐下降;
- 回流用户基本保持1000左右。
在实际业务中,活跃用户和回流用户是真正意义上消费的用户,是运营应该重点关注的高价值群体。
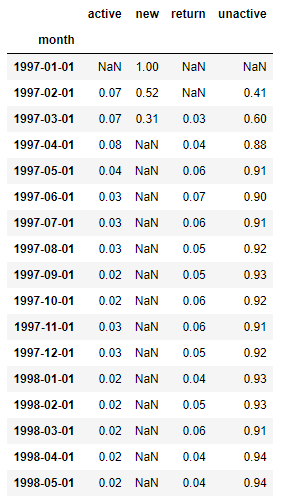
#计算每个月各类用户占比
user_status_counts.T.apply(lambda x: x/x.sum(), axis=1).round(2)
4.4用户生命周期分析
(1)用户生命周期分布直方图
用户生命周期定义:第一次消费至最后一次消费的时间差。
延长用户的生命周期,在用户生命周期内获取更多价值,是用户运营的目标。
# LTV:生命周期总价值,即生命周期内消费的总金额
user_LTV = df.groupby(['user_id']).agg({'order_amount': 'sum'})
user_LTV['lifetime'] = (df.groupby(['user_id'])['order_dt'].max()-df.groupby(['user_id'])['order_dt'].min())/np.timedelta64(1, 'D')
user_LTV.head()
前面分析中,有一半以上的用户只消费1次,再进行用户生命周期分析时,需要过滤掉这部分用户再分析才具有实际意义。因为只消费1次的用户生命周期为0,会把整体数据拉低,而且大部分一次性用户创造的价值很小,对后期用户运营没有显著的帮助。
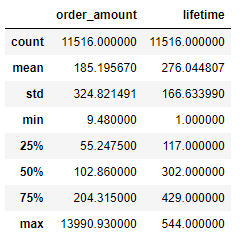
# 用户生命周期描述性统计:排除只消费1次的用户
user_LTV_query = user_LTV[user_LTV['lifetime'] > 0]
user_LTV_query.describe()
#绘制分布直方图
user_LTV_query['lifetime'].plot.hist(bins=40,figsize=(10, 6),title='CDNOW用户生命周期分布直方图')

由描述性统计和分布直方图可以看出:
- 消费2次以上用户平均生命周期为276天;
- 分布直方图呈现双峰趋势,大体可以分为三段:
- [0-30]天,有部分用户虽然消费超过两次,但是无法持续,运营应该在30天内做出对策,延长用户生命周期;
- [50-350]天,属于普通型生命周期,这部分用户是有消费欲望的,可以根据其特点推出针对性营销策略;
- [>350]天,属于网站的忠诚用户,要用心维护,稳定销量。
(2)用户生命周期和用户生命周期总价值相关性
plt.scatter(x=user_LTV_query['lifetime'],y=user_LTV_query['order_amount'])

user_LTV_query = user_LTV_query.query('order_amount < 4000')
plt.scatter(x=user_LTV_query['lifetime'],y=user_LTV_query['order_amount'])
plt.title('用户生命周期和用户生命周期总价值散点图')

由上散点分布图可知:
用户生命周期和用户生命周期总价值无线性相关关系,但是有一部分生命周期超过350天的用户,贡献的消费金额明显高于生命周期偏低的用户。
4.5用户留存分析
用户在某段时间内开始使用应用,经过一段时间后,仍然继续使用该应用的用户,被认作是留存用户。这部分用户占当时新增用户的比例即是留存率,会按照每隔1单位时间(例日、周、月)来进行统计。留存用户和留存率体现了用户的质量和运营保留用户的能力。
# 获取用户留存数据表
# 获取用户的激活日期reg_dt:这里指第一次消费日期
reg_dt = df.groupby('user_id')['order_dt'].min().reset_index().rename(columns={'order_dt': 'reg_dt'})
# 内连接
user_retention = pd.merge(left=df,right=reg_dt,how='inner',on='user_id')[['user_id','order_amount','reg_dt','order_dt']]
user_retention['第n天活跃'] = (user_retention['order_dt'] - user_retention['reg_dt']).apply(lambda x: x.days)
# # 对活跃天数进行分箱
bins = [0, 3, 7, 15, 30, 60, 90, 180, 365]
user_retention['活跃天数区间'] = pd.cut(user_retention['第n天活跃'], bins=bins)
user_retention.head(10)
# 数据透视,获取用户维度留存表
user_retention_pivoted = user_retention.pivot_table(index='user_id', columns='活跃天数区间',values='order_amount',aggfunc=sum,dropna=False)
user_retention_pivoted.head(10)
# 统计各个时间段用户的消费比列:即首次消费后,有多少用户比例在各个时间段再次消费
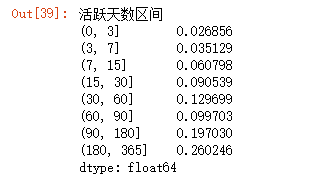
retention = user_retention_pivoted.count()/len(user_retention_pivoted)
retention
```python
retention.plot.bar(title = '各个时间段用户的再次消费人数占比')
```
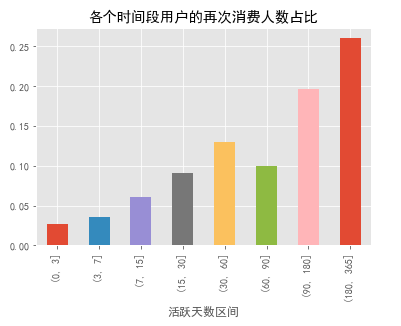
由上柱状图可知:
- 约有2.7%的用户在第一次消费后,次日至3日内再次消费;
- 3.6%的用户在3至7日消费;
- 约20%的用户在第一次消费三个月至半年内有过消费记录;
- 约26%的用户在半年后至一年内购买过。
可见,CD商品购买不属于高频行为。从运营角度看,在促活新用户的时,更要注重培养老用户的忠诚度。
# 统计用户在第一次消费后,再后续时间段的平均消费
user_retention_pivoted.mean()

4.5用户购买周期分析
# 计算用户的相邻两个订单的时间间隔,shift函数是对数据进行错位,所有数据会往下平移一下
order_dt_diff = user_retention.groupby('user_id').apply(lambda x: x.第n天活跃 - x.第n天活跃.shift(1))
order_dt_diff.head(10)

```python
# 用户消费时间间隔描述性统计
order_dt_diff.describe()
```

用户平均消费时间间隔为69天(极值影响)。在运营策略中,可以大概理解为,想要召回用户消费,在60天左右的时间间隔可以做一些好的运营策略或推荐。
```python
# 用户消费时间间隔分布直方图
order_dt_diff.plot.hist(bins=50,title='用户消费时间间隔分布直方图')
```

由用户消费时间间隔分布直方图,可以看出:
直方图呈现长尾分布,大部分用户的消费时间间隔很短,在用户第一次消费后,将时间召回点设为消费后立即赠送优惠券,消费后15天询问用户CD怎么样,消费后20天提醒优惠券到期,消费后60天短信推送,以实现用户粘性增加,并不断刺激用户消费。
4.6复购率和回购率分析
指标说明:(这里时间窗口为月)
- 复购率:在单位时间窗口内多次(2次及以上)消费的用户在总消费用户的占比。
- 回购率:在某单位时间窗口内消费的用户,在下一单位时间窗口仍消费的占比。
# 计算每个月用户的消费次数
pivoted_counts.head()
(1)复购率分析
# 消费次数:>1表示消费两次以上,>=1表示有消费
month_buy_rate = pd.DataFrame((pivoted_counts>1).sum()/(pivoted_counts>=1).sum(),columns=['复购率'])
month_buy_rate.head()
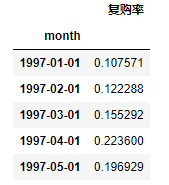
month_buy_rate.plot(figsize=(10,4),title='复购率月趋势图')
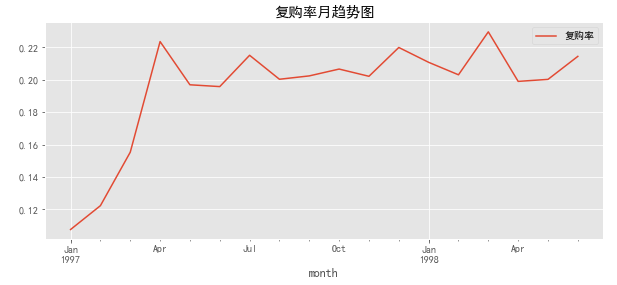
由复购率月趋势图可知:
- 前三个月,由于新用户涌入,导致复购率偏低,新客在短时间内只购买了一次
- 随着时间的推移,留下的都是少量忠诚用户(2000人),复购率稳定在20%左右。
(2)回购率分析
# 定义函数判断用户是否回购:本月消费,下月也消费,则表示用户回购
def func_purchase(data):
status = []
# 判断前17个月
for i in range(data.count()-1):
# 本月有消费
if data[i] > 0:
# 下个月也消费,则为回购,即为1
if data[i+1] > 0:
status.append(1)
# 下个月不消费,不回购,记为0
else:
status.append(0)
# 本月无消费,赋予为NaN,count不统计
else:
status.append(np.nan)
# 最后一个月补充为NaN,因为没有下一月数据,无法判断是否回购
status.append(np.nan)
return pd.Series(status,index=data.index)
# axis=1,按行逐用户传入
purchase = pivoted_counts.apply(func_purchase,axis=1)
purchase.head()
# 计算回购率
purchase_rate = pd.DataFrame(purchase.sum()/purchase.count(),columns=['回购率'])
purchase_rate.head()
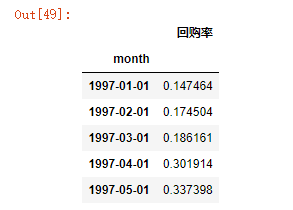
purchase_rate.plot(figsize=(10,4),title='回购率月趋势图')
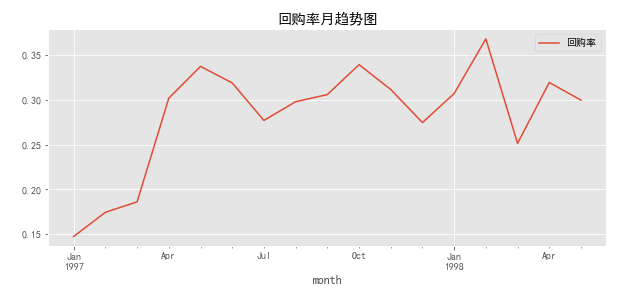
由回购率月趋势图可知:
- 前三个月,新用户涌入,新用户回购率在16%左右,大部分新客户只在当月购买了一次,新客户质量不佳;
- 后回购率稳定在30%左后,波动较大(10%之间)
五、案例总结
用实战玩转pandas数据分析(一)——用户消费行为分析(python)的更多相关文章
- kaggle之数据分析从业者用户画像分析
数据为kaggle社区发布的数据分析从业者问卷调查分析报告,其中涵盖了关于该行业不同维度的问题及调查结果.本文的目的为提取有用的数据,进行描述性展示.帮助新从业的人员更全方位地了解这个行业. 参考学习 ...
- QQ空间玩吧HTML5游戏引擎使用比例分析
GameLook报道/“Cocos 2015开发者大会(春季)”于4月2日在国家会议中心圆满落下帷幕.在会上全新的3D编辑器,Cocos Runtime等产品重磅公布,给业界带来了Cocos这款国产引 ...
- Hadoop项目实战-用户行为分析之应用概述(三)
1.概述 本课程的视频教程地址:<项目工程准备> 本节给大家分享的主题如下图所示: 下面我开始为大家分享今天的第三节的内容——<项目工程准备>,接下来开始分享今天的内容. 2. ...
- Hadoop项目实战-用户行为分析之应用概述(一)
1.概述 本课程的视频教程地址:<Hadoop 回顾> 好的,下面就开始本篇教程的内容分享,本篇教程我为大家介绍我们要做一个什么样的Hadoop项目,并且对Hadoop项目的基本特点和其中 ...
- 动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题
动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题 D3 ...
- PANDAS 数据分析初学者教程
Pandas 初学者教程 2018-05-19 六尺巷人 对于数据科学家,无论是数据分析还是数据挖掘来说,Pandas是一个非常重要的Python包.它不仅提供了很多方法,使得数据处理非常 ...
- 【python数据分析实战】电影票房数据分析(一)数据采集
目录 1.获取url 2.开始采集 3.存入mysql 本文是爬虫及可视化的练习项目,目标是爬取猫眼票房的全部数据并做可视化分析. 1.获取url 我们先打开猫眼票房http://piaofang.m ...
- 【python数据分析实战】电影票房数据分析(二)数据可视化
目录 图1 每年的月票房走势图 图2 年票房总值.上映影片总数及观影人次 图3 单片总票房及日均票房 图4 单片票房及上映月份关系图 在上一部分<[python数据分析实战]电影票房数据分析(一 ...
- 【Python数据分析】用户通话行为分析
主要工作: 1.对从网上营业厅拿到的用户数据.xls文件,通过Python的xlrd进行解析,计算用户的主叫被叫次数,通话时间,通话时段. 2.使用matplotlib画图包,将分析的结果直观的绘制出 ...
随机推荐
- OpenStack服务默认端口号
在某些部署中,例如已设置限制性防火墙的部署,您可能需要手动配置防火墙以允许OpenStack服务流量. 要手动配置防火墙,您必须允许通过每个OpenStack服务使用的端口的流量.下表列出了每个Ope ...
- Ubuntu 下更改pip源使用清华源
一.新建目录 sudo -s mkdisk ~./pip vim ~./pip/pip.conf 二.复制下面代码,并保存 [global] index-url = https://pypi.tuna ...
- 恕我直言!!!对于Maven,菜鸟玩dependency,神仙玩plugin
打包是一项神圣.而庄严的工作.package意味着我们离生产已经非常近了.它会把我们之前的大量工作浓缩成为一个.或者多个文件.接下来,运维的同学就可以拿着这些个打包文件在生产上纵横四海了. 这么一项庄 ...
- js load more select
js load more select searchable scroll load more append to list refs xgqfrms 2012-2020 www.cnblogs.co ...
- DLL & Dynamic-link library
DLL & Dynamic-link library 动态链接库 .dll 动态链接库(英语:Dynamic-link library,缩写为 DLL)是微软公司在微软视窗操作系统中实现共享函 ...
- js closures all in one
js closures all in one setTimeout 闭包,log(i, arr[¡]) var, let, closures, IIFE "use strict"; ...
- user tracker with ETag
user tracker with ETag 用户追踪, without cookies clear cache bug 实现原理 HTTP cache hidden iframe 1px image ...
- chrome device remote debug
chrome device remote debug chrome://inspect/#devices chrome inspect devices Android chrome MIDI / MT ...
- svg rect to polygon points & points order bug
svg rect to polygon points & points order bug https://codepen.io/xgqfrms/pen/vYOWjYr?editors=100 ...
- asm FPU 寄存器
TOP-- TOP++ 顶部 ST(0) ST(1) ST(2) ST(3) ST(4) ST(5) ST(6) ST(7) 底部 指令后的注释通常是执行后的结果 push section .data ...