python beautifulsoup基本用法-文档结构
一、BeautifulSoup概述
BeautifulSoup是python的一个库,用于接收一个HTML或XML字符串并对其进行格式化,然后使用提供的方法快速查找指定元素。
使用BeautifulSoup需要先安装,安装了python后直接在cmd窗口通过pip3 install BeautifulSoup即可。
BeautifulSoup还需要配合使用解析器对字符串进行解析,主要的几种解析器如下,常用的为lxml(也需要先安装)。
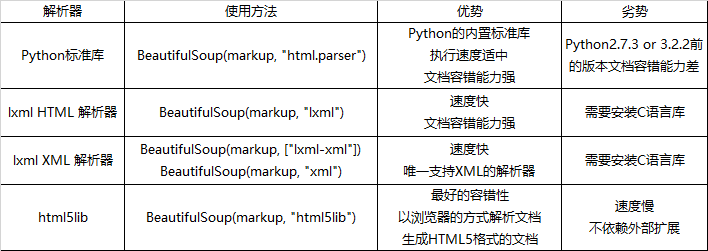
基本使用方法
import requests
import lxml
from bs4 import BeautifulSoup
doc = requests(url)
soup = BeautifulSoup(doc,'lxml)'
以下示例
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</body>
</html>
格式化输出prettify()
prettify()方法可将BeautifulSoup的文档树格式化后以Unicode编码输出,每个XML/HTML标签都独占一行。
h = '''<title> <b>猫和老鼠</b> </title>'''
s = BeautifulSoup(h,'lxml')
print(s.prettify())
# <html>
# <head>
# <title>
# <b>
# 猫和老鼠
# </b>
# </title>
# </head>
# </html>
prettify()格式化输出
二、BeautifulSoup的对象
BeautifulSoup将复杂的XML或HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种,Tag、NavigableString、BeautifulSoup和Comment。
1.Tag对象
Tag对象即XML或HTML原生的标签,例如title、p、div等等,类型为class 'bs4.element.Tag,Tag对象有两个重要的属性name和attrs。
- soup.tagname 获取第一个符合要求的tag标签
- soup.tagname.name 获取第一个符合要求的tag标签的名称
- soup.tagname.attrs 获取第一个符合要求的tag标签的属性,结果为字典,key为属性名称value为属性值
获取和查看Tag对象
print(soup.title) #<title>The Dormouse's story</title>
print(soup.p) #<b>The Dormouse's story</b>
print(type(soup.a)) #<class 'bs4.element.Tag'>
获取Tag对象的名称和属性
print(soup.p.name) # p
print(soup.p.attrs) #{'class': 'newTitle', 'name': 'dromouse'}
修改、增加和删除Tag对象的属性,被改变的是是通过BeautifulSoup得到的对象,可通过打印soup对象来查看变化
增加和修改属性:soup.tagname[属性],删除Tag对象的属性:del soup.tagname[属性]
soup.p['class'] = 'newTitle' #设置一个存在的属性,该属性会被修改
soup.p['newClass'] = 'newClass' #设置一个不存在的属性,该属性会被增加
del soup.p['newClass'] #删除上一步增加的属性
2.NavigableString对象
NavigableString表示标签的文本值,获得了Tag对象,再通过Tag对象.string属性获取NavigableString文本。
print(soup.p.string) #The Dormouse's story
print(type(soup.p.string)) #<class 'bs4.element.NavigableString'>
soup.p.string = "The Dormouse's Story" #修改文本值
要获取标签的文本值,还可通过.text属性或者.get_text()方法,该方法得到的结果就不是NavigableString对象了,直接是字符串,即使一个标签内有多个文本值得到的结果也是一个字符串。
print(soup.p.text) #The Dormouse's story
print(soup.p.get_text()) #The Dormouse's story
print(type(soup.b.get_text())) #<class 'str'>
print(type(soup.body.get_text())) #<class 'str'>
3.BeautifulSoup对象
BeautifulSoup对象表示文档的全部内容,可以当作是一个特殊的Tag对象。
print(type(soup)) #<class 'bs4.BeautifulSoup'>
print(soup.name) #[document]
print(soup.attrs) #{}空字典
4.comment对象
Comment对象即文档中的注释,是一个特殊类型的NavigableString对象,但是对其打印输出时也不会显示注释符号。我们查看第一个文本内容备注是的a标签如下。
print(soup.a.string) #Elsie
print(type(soup.a.string)) #<class 'bs4.element.Comment'>
三、文档树结构
1.直接子节点.contents与.children
直接子节点是指一个节点下的直接tag对象,可用obj.contents和obj.children表示。需要注意的是,父节点与子tag之间的换行符会被当作子节点,各个子tag之间的换行符也会被当作一个子节点,且为NavigableString对象。只有Tag对象和BeautifulSoup对象有直接子节点。
①.contents
.contents的结果为一个列表,列表中各元素为直接子节点
print(soup.body.contents) #第1个元素为换行符\n,第2个为p标签,第3个为\n,第4个为p,第5个为\n,第5个为p,第7个为\n
print(len(soup.body.contents)) #
②.children
.children的结果为一个列表迭代器,通过循环得到的内容与.contents列表各元素对应相同。
print(soup.body.children) #<list_iterator object at 0x000001BE2A673F28>
for c in soup.body.children:
print(c)
2.所有子节点.descendants
.descendants的结果为一个生成器,可通过循环得到所有子节点,它会获取所有的tag对象,再对tag对象进行递归循环直至获取到tag对象的文本(NavigableString对象)。
print(soup.p.descendants)
for d in soup.p.descendants:
print(d)
# <generator object Tag.descendants at 0x000001BE2A5B48B8>
# <b>The Dormouse's story</b>
# The Dormouse's story
3.单个节点内容.string
如果一个标签内不再有标签,或者标签内只有层层递进的唯一标签(注意换行符也是标签),.string会返回最里面的文本内容。
例如可以通过soup.b.string获取b标签的文本内容,并且由于第一个p标签内只有b标签,因此通过soup.p.string也可以获取到b标签的文本内容,但是由于body内有多个标签,.string无法确定由哪个标签去调用因而返回None。
print(soup.p.string) #The Dormouse's story
print(soup.b.string) #The Dormouse's story
print(soup.body.string) #None
4.多个节点内容.strings与.stripped_strings
通过.strings可获取一个节点下所有子节点的文本内容,类型为生成器,此时换行符会显示为空行
print(soup.body.strings)
for s in soup.body.strings:
print(s) #\n会显示为空白行
通过.stripped_strings可以过滤掉空行和多余的空格
for s in soup.body.stripped_strings:
print(s)
5.直接父节点.parent
tag对象的直接父节点为上层tag对象,NavigableString对象即文本值的直接父节点为其所在的tag对象。
print(soup.p.b.parent) #<p class="newTitle" name="dromouse"><b>The Dormouse's story</b></p>
print(soup.p.b.string.parent.name) #b
6.所有父节点.parents
.parents得到的结果为一个生成器,通过.parents可以得到tag对象或文本值的所有上层父节点,html也是节点,除了BeautifulSoup之外的所有对象的最上层父节点都是[document]。
print(soup.b.parents) #<generator object PageElement.parents at 0x000001DC9E8DAB10>
for p in soup.b.parents:
print(p.name)
# p
# body
# html
# [document]
7.相邻兄弟节点.next_sibling与.prev_sibling
与某一节点处于同一层级的前一个或后一个节点,.next_sibling表示下一个兄弟节点,.prev_sibling表示上一个兄弟节点,如果上一个或下一个节点不存在则返回 None。由于空白或者换行也会被视作一个节点,因此实际文档中的tag的 .next_sibling 和 .prev_sibling得到的结果可能是空白或者换行。
print(soup.p.next_sibling) #空白行
print(soup.p.prev_sibling) #None
print(type(soup.p.next_sibling)) #<class 'bs4.element.NavigableString'>
print(type(soup.p.prev_sibling)) #<class 'NoneType'>
对于第一个p标签来说,由于后面存在相邻的p标签,但是两个p之间有换行,所以next_sibling显示为空行,且类型为<class 'bs4.element.NavigableString'>;但是由于前面没有相邻的p标签,所以prev_sibling结果为None(不能认为是换行符),且类型为NoneType。
8.所有兄弟节点.next_siblings与.prev_siblings
.next_siblings和.prev_siblings表示当前节点后面所有、前面所有的兄弟节点,是一个生成器对象,可通过循环得到所有节点。
print(soup.p.next_siblings) #<generator object PageElement.next_siblings at 0x000001DCA142F6D8>
print(soup.p.prev_siblings) #None
for i in soup.p.next_siblings:
print(i.name)
9.前后节点.next_element与.prev_element
.next_element与.prev_element针对所有节点,不分层级关系。
print(soup.p.next_element) #<b>The Dormouse's story</b>
print(soup.p.prev_element) #None
10.所有前后节点.next_elements与.prev_elements
print(soup.p.next_elements) #<b>The Dormouse's story</b>
print(soup.p.prev_elements) #None
for l in soup.p.next_elements:
print(l)
python beautifulsoup基本用法-文档结构的更多相关文章
- python beautifulsoup基本用法-文档搜索
以如下html段落为例进行介绍 <html> <head> <title>The Dormouse's story</title> </head& ...
- 使用sphinx快速为你python注释生成API文档
sphinx简介sphinx是一种基于Python的文档工具,它可以令人轻松的撰写出清晰且优美的文档,由Georg Brandl在BSD许可证下开发.新版的Python3文档就是由sphinx生成的, ...
- 使用sphinx为python注释生成docAPI文档
sphinx简介 sphinx是一种基于Python的文档工具,它可以令人轻松的撰写出清晰且优美的文档,由Georg Brandl在BSD许可证下开发. 新版的Python3文档就是由sphinx生成 ...
- HTML5的文档结构和新增标签
一.HTML5 文档结构1.第一步:打开 开发工具,打开指定文件夹:2.第二步:保存 index.html 文件到磁盘中,.html 是网页后缀:3.第三步:开始编写 HTML5 的基本格式.< ...
- python快速生成注释文档的方法
python快速生成注释文档的方法 今天将告诉大家一个简单平时只要注意的小细节,就可以轻松生成注释文档,也可以检查我们写的类方法引用名称是否重复有问题等.一看别人专业的大牛们写的文档多牛多羡慕,不用担 ...
- Win 10 开发中Adaptive磁贴模板的XML文档结构,Win10 应用开发中自适应Toast通知的XML文档结构
分享两篇Win 10应用开发的XML文档结构:Win 10 开发中Adaptive磁贴模板的XML文档结构,Win10 应用开发中自适应Toast通知的XML文档结构. Win 10 开发中Adapt ...
- Mongodb:修改文档结构后出现错误:Element '***' does not match any field or property of class ***.
Mongodb:修改文档结构后出现错误:Element '***' does not match any field or property of class ***. Mongodb是一种面向文档的 ...
- 读取XML文档结构并写入内容
1.在项目中新建XML文档结构.xsd文件,在其中添加相应的节点. 2.读取文档结构并写入内容 string initFileName = @"D:\Config.xml"; Da ...
- MFC开发上位机到底用Dialog结构还是文档结构?
最近要跟着导师一起开发一款大型上位机.MFC新人在考虑用对话框结构还是文档结构. 虽然说书上说大型结构的软件都需要文档结构,但是目前来看,对话框可以实现功能,并且对话框的程序更小一些,节省资源加载速度 ...
随机推荐
- "该公众号暂时无法提供服务,请稍后再试"的问题
倒腾了好久,对微信公众号也不是很熟悉.不知道怎么看问题,php学的也不久. 1.定位问题. 网上找了很久,最后找到两种定位问题的方式. a.https://blog.csdn.net/qq_28506 ...
- 堆/题解 P3378 【【模板】堆】
概念: 堆就是一颗二叉树,满足父亲节点总是比儿子节点大(小).因此,堆也分为大根堆和小根堆,大根堆就是父亲节点比儿子节点大,小根堆正好相反.注意加粗的地方,是每一个节点哦!!!!! 还是直接看例题吧, ...
- Lists.newArrayList() 和 new ArrayList()的区别?
什么是创建List字符串的最好构造方法?是Lists.newArrayList()还是new ArrayList()? 还是个人喜好? Lists和Maps是两个工具类, Lists.newArray ...
- vs2017+opencv3.4.0的配置方法
1.尝试了这个博客的方法: https://blog.csdn.net/u014574279/article/details/50909425/ 结果: 无法打开文件“opencv_ml2410d.l ...
- 资深前端工程师带你认识网页后缀html、htm、shtml、shtm有什么区别?
每一个网页或者说是web页都有其固定的后缀名,不同的后缀名对应着不同的文件格式和不同的规则.协议.用法,最常见的web页的后缀名是.html和.htm,但这只是web页最基本的两种文件格式,今天我们来 ...
- 一起来看 HTML 5.2 中新的原生元素 <dialog>
不到一个月前,HTML 5.2 正式成为 W3C 的推荐标准(REC),其中,推出了一个新的原生模态对话框元素 <dialog>,乍一看,可能感觉它就是一个新增的元素,然而,作者最近在玩的 ...
- Django---进阶5
目录 单表操作 必知必会13条 测试脚本 查看内部sql语句的方式 神奇的双下划线查询 一对多外键增删改查 多对多外键增删改查 正反向的概念 多表查询 子查询(基于对象的跨表查询) 联表查询(基于双下 ...
- day18 作业
目录 1.编写课上讲解的有参装饰器准备明天默写 2.在文件开头声明一个空字典,然后在每个函数前加上装饰器,完成自动添加到字典的操作 3.编写日志装饰器,实现功能如:一旦函数f1执行,则将消息2017- ...
- 深入学习JavaScript数据类型
数据类型是我们学习JavaScript时最先接触的东西,它是JavaScript中最基础的知识,这些知识看似简单,但实则有着许多初学者甚至是部分学习了多年JavaScript的老手所不了解的知识. 数 ...
- HDFS客户端环境准备
一.下载Hadoop jar包至非中文路径 下载链接:https://hadoop.apache.org/releases.html 解压至非中文路径 二.配置Hadoop环境变量 配置HADOOP_ ...