聊聊自学大数据flume中容易被人忽略的细节

前言:老刘不敢保证说的有多好,但绝对是非常良心地讲述自学大数据开发路上的一些经历和感悟,保证会讲述一些不同于别人技术博客的细节。
01 自学flume的细节
老刘现在想写点有自己特色的东西,讲讲自学大数据遇到的一些事情,保证讲一些别人技术博客里忽略的知识点。
很多自学编程的人都会有一个问题,特别是研二即将找工作的小伙伴,因为马上就要找工作了,自学时间不多了,所以在自学的路上,常常会忽略很多细小但很重要的知识点,很多伙伴都是直接背一些机构的资料。
自己没有静下心来好好研究各个知识点,也没有考虑这些机构写的知识点的对错,完全照搬资料上的知识点,没有形成自己的理解,这是非常危险的!
从今天开始,老刘就来给大家讲讲自学大数据开发路上的那些容易被人忽略的细节,让大家对知识点形成自己的理解。
1、什么是flume?
在解释什么是flume这类知识点上,很多机构的资料或者网上的技术博客讲的都不好,很多培训机构的资料是这样形容的“Flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统”。
一般都会觉得这句话没啥问题,但是好好想想,这句话是不是相当于这个场景,男女相亲,男方说我有车有房,但是没有说是什么车,什么房,自行车也是车,租的房也是房啊!所以在说有车有房的时候,一定要拿出确凿的证据。
所以呢,当面试的时候,直接说flume是一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统是非常没有说服力的,非常典型的照搬资料,没有自己的理解。
它是如何做到高可用,高可靠,分布式也需要讲一讲,这样才觉得可靠!这就是老刘说的和别人不一样的地方,真的良心分享!
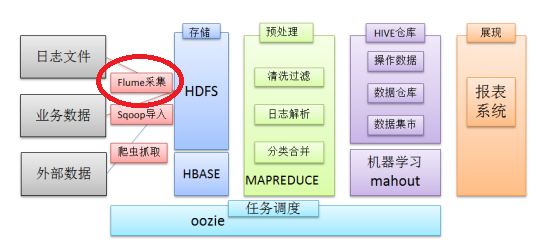
老刘觉得可以这样说在一个完整的离线大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架。
其中,flume就是一个日志采集、聚合和传输系统的开源框架,它的高可用、高可靠、分布式这些特点,一般都是通过部署多个服务器,然后在每个服务器上部署flume agent模式形成的,并且flume通过事务机制保证了数据传输的完整性和准确性,flume事务在后面讲。
flume的概念就讲这么多,这样说的目的主要是不想让大家照搬机构资料的内容,自己多想想,要有自己的理解。
2、flume架构

看到这个架构图,老刘直接先说说flume是怎么工作的?
外部数据源以特定格式向flume发送events事件,当source接收到events时,它将其存储到一个或多个channel,channel会一直保存events直到它被sink消费。sink的主要功能是从channel中读取events,并将其存入外部存储系统或转发到下一个source,成功后再从channe移除events。
接着讲讲各个组件agent、source、channe、sink。
agent
它是一个JVM进程,它以事件的形式将数据从源头送至目的。
source
它是一个采集组件,用来获取数据。
channel
它是一个传输通道组件,用来缓存数据,用于从将source的数据传递到sink。
sink它
是一个下沉组件,它将数据发送给最终的存储系统或者下一个agent。
3、flume事务
flume事务是非常非常重要的,之前就说过通过flume事务,实现了传输数据的完整性和准确性。
先看看这张图:
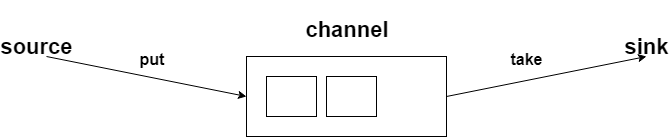
flume它有两个事务,分别是put事务、take事务。
put事务的步骤分为两步:
doput,它先将此数据写入到临时缓冲区putlist里面;
docommit,它会去检查channel里面有没有空位置,如果有空位置就会传入数据;如果channel里面没有空位置,那就会把数据回滚到putlist里面。
take事务也分为两步:
dotake,它会将数据读取到临时缓冲区takelist,并把数据传到hdfs上;
docommit,它会去判断数据是否上传成功,若成功那么就会清除临时缓冲区takelist里的数据;若不成功,比如hdfs发生崩溃啥的,那就会回滚数据到channel里面。
通过讲述两个事务的步骤,是不是就知道了为什么flume会保证传输数据的完整和准确。
老刘总结一下就是,数据在传输到下一个节点时,假设接收节点出现异常,比如网络异常之类的,那就会回滚这一批数据,因此就会导致数据重发。
那在同一个节点内,source写入数据到channel,数据在一个批次内出现异常,那就会不写入到channel中,已经接收到的部分数据会被直接抛弃,靠上一个节点重发数据。
通过这两个事务,flume就提高了数据传输的完整性、准确性。
4、flume实战
这部分是flume最重要的,作为一个日志采集框架,flume的应用比它的概念还要重要,一定要知道flume要怎么用!老刘最开始压根就没看这部分,光看知识点了,现在才发现实战的重要性!
但是flume实战案例数不胜数,我们难道要记住每一个案例吗?
当然不是,这个flume案例我们可以根据官网里的配置文件进行配置,如下图:
看左下角蓝色方框里的内容,就可以查询到相关配置文件。在这里老刘有句话说,如果想学习一个新的框架,咱们的学习资料就是官网,通过官网学习,不仅能提升技术,还能提高英语,且不美滋滋!
现在开始讲案例,第一个是采集文件到HDFS,需求就是监控一个文件如果有新增的内容就把数据采集到HDFS上。
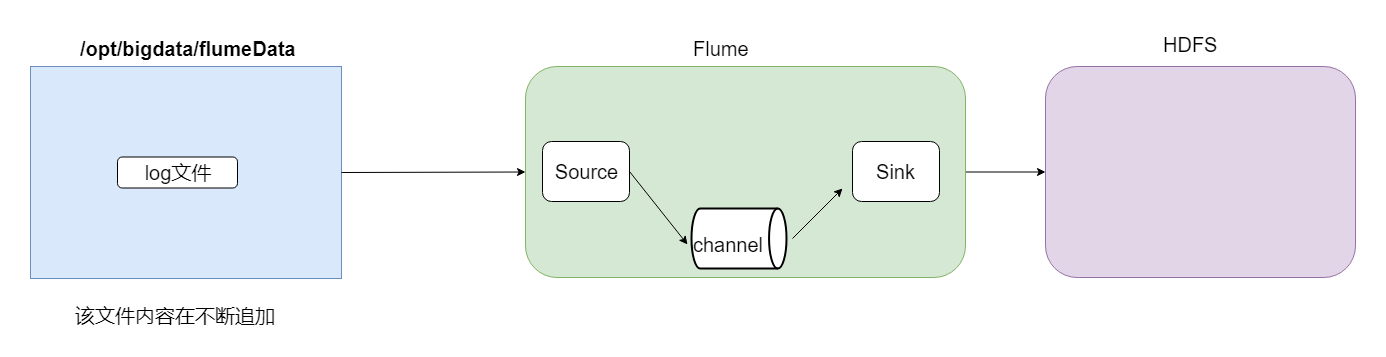
根据官网资料,flume配置文件开发需要在flume安装目录下创建一个文件夹,后期存放flume开发的配置文件。
根据需求的描述,source的配置应该选择为exec;为了保证数据不丢失,channel的配置应该选择file;sink的配置应该选择为hdfs。
这样虽然已满足需求,但是我们做数据开发,肯定会存在非常多的小文件,一定要做相关的优化。例如,文件小,文件多怎么解决?文件目录多怎么解决?
所以我们还要选择一些参数来控制参数和目录。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 #配置source
#指定source的类型为exec,通过unix命令来传输结果数据
a1.sources.r1.type = exec
#监控这个文件,有新的数据产生就不断采集
a1.sources.r1.command = tail -F /opt/bigdata/flumeData/tail.log
#指定source的数据流入到channel中
a1.sources.r1.channels = c1 #配置channel
#选择file,就是保证数据不丢失,即使出现火灾或者洪灾
a1.channels.c1.type = file
#设置检查点目录--该目录是记录下event在数据目录下的位置
a1.channels.c1.checkpointDir=/kkb/data/flume_checkpoint
#数据存储所在的目录
a1.channels.c1.dataDirs=/kkb/data/flume_data #配置sink
a1.sinks.k1.channel = c1
#指定sink类型为hdfs
a1.sinks.k1.type = hdfs
#指定数据收集到hdfs目录
a1.sinks.k1.hdfs.path = hdfs://node01:9000/tailFile/%Y-%m-%d/%H%M
#指定生成文件名的前缀
a1.sinks.k1.hdfs.filePrefix = events- #是否启用时间上的”舍弃” -->控制目录
a1.sinks.k1.hdfs.round = true
#时间上进行“舍弃”的值
# 如 12:10 -- 12:19 => 12:10
# 如 12:20 -- 12:29 => 12:20
a1.sinks.k1.hdfs.roundValue = 10
#时间上进行“舍弃”的单位
a1.sinks.k1.hdfs.roundUnit = minute # 控制文件个数
#60s或者50字节或者10条数据,谁先满足,就开始滚动生成新文件
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 50
a1.sinks.k1.hdfs.rollCount = 10 #每个批次写入的数据量
a1.sinks.k1.hdfs.batchSize = 100 #开始本地时间戳--开启后就可以使用%Y-%m-%d去解析时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
第二个是采集目录到HDFS,如果一个目录中不断产生新的文件,就需要把目录中的文件不断地进行数据传输到HDFS上。
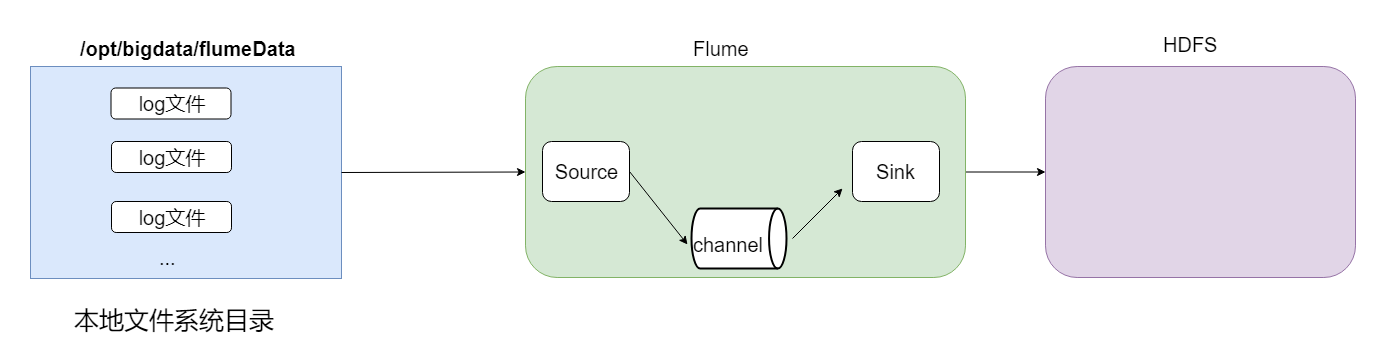
采集目录的话,source的配置一般采用spooldir;channel的配置可以设置为file,也可以设置为别的,一般为memory;sink的配置还是设置为hdfs。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 配置source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /opt/bigdata/flumeData/files
# 是否将文件的绝对路径添加到header
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 #配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 #配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs://node01:9000/spooldir/%Y-%m-%d/%H%M
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 50
a1.sinks.k1.hdfs.rollCount = 10
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
最后再说一个两个agent串联,就是第一个agent负责监控某个目录中新增的文件进行数据收集,通过网络发送到第二个agent当中去,第二个agent负责接收第一个agent发送的数据,并将数据保存到hdfs上面去。
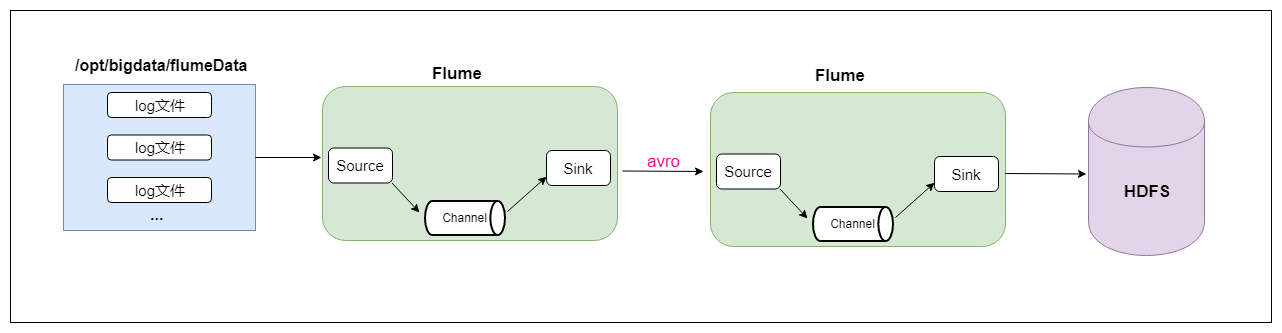
虽然是两个agent串联,但只要看了官网的配置文件以及经过之前的两个案例,这两个agent串联难度也是很一般的。
首先是agent的配置文件是这样的:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 配置source
##注意:不能往监控目中重复丢同名文件
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /opt/bigdata/flumeData/files
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 #配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 #配置sink
a1.sinks.k1.channel = c1
#AvroSink是用来通过网络来传输数据的,可以将event发送到RPC服务器(比如AvroSource)
a1.sinks.k1.type = avro #node02 注意修改为自己的hostname
a1.sinks.k1.hostname = node02
a1.sinks.k1.port = 4141
agent2的配置文件是这样的:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 #配置source
#通过AvroSource接受AvroSink的网络数据
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
#AvroSource服务的ip地址
a1.sources.r1.bind = node02
#AvroSource服务的端口
a1.sources.r1.port = 4141 #配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 #配置sink
a1.sinks.k1.channel = c1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://node01:9000/avro-hdfs/%Y-%m-%d/%H-%M
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.rollInterval = 60
a1.sinks.k1.hdfs.rollSize = 50
a1.sinks.k1.hdfs.rollCount = 10
a1.sinks.k1.hdfs.batchSize = 100
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本
a1.sinks.k1.hdfs.fileType = DataStream
最后运行的时候,先启动node02上的flume,然后在启动node01上的flume。
02 flume细节的总结
老刘这次讲了flume的四个容易被忽略的细节,就是想提醒自学的小伙伴们要注意细节,绝对不能完全照搬资料上说的内容,对每个知识点一定要有自己的理解。
最后,如果觉得有哪里写的不好或者有错误的地方,可以联系公众号:努力的老刘,进行交流。希望能够对大数据开发感兴趣的同学有帮助,希望能够得到同学们的指导。
如果觉得写的不错,给老刘点个赞!
聊聊自学大数据flume中容易被人忽略的细节的更多相关文章
- Hbase和Hive在大数据架构中处在不同位置
先放结论:Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用.一.区别:Hbase: Hadoop database ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---Flume 简介及基本使用
一.Flume简介 Apache Flume 是一个分布式,高可用的数据收集系统.它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集.Flume 分为 NG 和 OG ( ...
- 大数据SQL中的Join谓词下推,真的那么难懂?
听到谓词下推这个词,是不是觉得很高大上,找点资料看了半天才能搞懂概念和思想,借这个机会好好学习一下吧. 引用范欣欣大佬的博客中写道,以前经常满大街听到谓词下推,然而对谓词下推却总感觉懵懵懂懂,并不明白 ...
- kappa系数在大数据评测中的应用
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/7091315.html 前言 最近打算把翻译质量的人工评测好 ...
- 大数据项目中的Oracle查询优化
今天发现自己之前写的一些SQL查询在执行效率方面非常不理想,于是尝试做了些改进. 需求为查询国地税表和税源表中,国税有而税源没有的条目数,之前的查询如下: SELECT COUNT(NAME) FRO ...
- 大数据项目中js中代码和java中代码(解决Tomcat打印日志中文乱码)
Idea2018中集成Tomcat9导致OutPut乱码找到tomcat的安装目录,打开logging.properties文件,增加一行代码,覆盖默认设置,将日志编码格式修改为GBK.java.ut ...
- 自学大数据(hadoop)小插曲__虚拟机工具
安装VMware Tools VMware 版本:10.0.1 ubuntu(linux) 版本:16.04 LTS 序言:本来第一天可以访问共享文件夹,第二天重新安装了四个ubuntu,可惜确无法访 ...
- 入门大数据---Flume的搭建
一.下载并解压到指定目录 崇尚授人以渔的思想,我说给大家怎么下载就行了,就不直接放连接了,大家可以直接输入官网地址 http://flume.apache.org ,一般在官网的上方或者左边都会有Do ...
随机推荐
- 2. git命令行操作之本地库操作
2.1 本地库初始化 git init 命令 用于创建一个空的Git本地仓库或重新初始化一个现有本地仓库 注:.git目录中存放的是本地库相关的子目录和文件,不要删除也不要随意修改 git confi ...
- HHKB Programming Contest 2020 D - Squares 题解(思维)
题目链接 题目大意 给你一个边长为n的正方形和边长为a和b的正方形,要求把边长为a和b的正方形放在长度为n的正方形内,且没有覆盖(可以相邻)求有多少种放法(mod 1e9+7) 题目思路 这个思路不是 ...
- Linux的硬盘挂载
一·前言 我朋友买了一个香港的服务器,可用总容量为60G,实际只有15.4G,剩下的容量需要硬盘挂载.他尝试无果,向我求助.我帮他解决了问题,想回顾一下整理写此随笔. 二·运行环境 Linux系统版本 ...
- jquery动态生成的select下拉框,怎么设置默认的选中项?
这两天都被这问题困扰,可能是我不太懂前端.我做layui表格行编辑,点击编辑按钮弹出layer,里边有一个民族的下拉框不能直接显示后台传过来的值.我把民族数组用jquery添加到了select里边,可 ...
- LeetCode 019 Remove Nth Node From End of List
题目描述:Remove Nth Node From End of List Given a linked list, remove the nth node from the end of list ...
- CentOS 7下安装Docker
安装一些必要的系统工具: sudo yum install -y yum-utils device-mapper-persistent-data lvm2 添加软件源信息: sudo yum-conf ...
- Docker实战 | 第二篇:IDEA集成Docker插件实现一键自动打包部署微服务项目,一劳永逸的技术手段值得一试
一. 前言 大家在自己玩微服务项目的时候,动辄十几个服务,每次修改逐一部署繁琐不说也会浪费越来越多时间,所以本篇整理通过一次性配置实现一键部署微服务,实现真正所谓的一劳永逸. 二. 配置服务器 1. ...
- 老猿学5G扫盲贴:3GPP规范中与计费相关的主要规范文档列表及下载链接
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在<老猿学5G扫盲贴:3GPP规范中部分与计 ...
- PyQt(Python+Qt)实战:使用QCamera、QtMultimedia等实现摄像头拍照
一.概述 在PyQt中,可以使用QCamera.QCameraViewfinder.QCameraViewfinderSettings等一系列多媒体操作相关类实现摄像头操作.用这些类不足50行代码+U ...
- OutputFormat---自定义输出方式
简介 可以自定义输出的格式和文件,例如包含某字段的输出到一个指定文件,不包含某字段的输出到另一个文件. 案例 数据 www.nevesettle.com www.baidu.com www.qq.co ...