Linux系统编程【3.2】——ls命令优化版和ls -l实现
前情提要
在笔者的上一篇博客Linux系统编程【3.1】——编写ls命令中,实现了初级版的ls命令,但是与原版ls命令相比,还存在着显示格式和无颜色标记的不同。经过笔者近两天的学习,基本解决了这两个问题,且实现了"ls -l",并对于可选参数"-a"和"-l"有了更好的支持(不管-a,-l输入顺序如何,是"ls -a -l",还是"ls -l -a",还是"ls -al",亦或是"ls -ls",出现位置几何,重复与否,都能正确运行)。
ls显示格式的解决
首先,让我们来观察一下原版ls显示的格式:

笔者总结出的原版ls显示规律:
- 1.按序显示
- 2.按照排序规则按列从上往下显示,当前列显示完成后转到下一列继续显示
- 3.每一列都是左对齐的
- 4.每一列的宽度都是该列最长文件名长度加2
- 5.列的数目要尽量保证每一行都被文件名“填充满”,而又不会导致行中最后一个文件名换行
在我们自己实现ls显示时,如何满足这5个规律呢?
对于规律1,笔者已经采用排序算法来满足了。规律3可以采用printf函数中的"%-*s"来满足。其他三条规律好像不太好满足。问题的关键在于,我们不知道要显示的行数和列数,以及每一列的最大字符串长度。为了获得这些数据,接下来介绍笔者琢磨出来的一种算法,姑且将其称为“分栏算法”吧。
分栏算法
问题可以简化为:给你一个已经排序的字符串指针数组,求能满足上述5个规律输出显示这些字符串的行/列数,以及每一列的最大字符串长度。
那么就让我们来构建这样一个函数签名:
由于要返回三个不同数据,所以将其中一个作为返回值,另外两个作为指针传入参数。
1.确定函数返回值:返回行数
2.确定函数参数:字符串指针数组、字符串个数、列数指针、每列的最大字符串长度数组
函数签名如下所示:
int cal_row(char** filenames,int file_cnt,int* cal_col,int* col_max_arr);
"囫囵吞枣"版分栏算法
在函数主体中,先计算出
最少占用字符数 =(每个字符串长度+2)* 总字符串个数
加2是因为在显示时每个字符串后面至少跟两个空格。利用ioctl函数调用,获取当前屏幕宽度(一行能容纳的字符数)。用最少占用字符数除以屏幕宽度,得到一个基准行数。这个基准行数是最少所需行数,因为只有在每个字符串长度都一致,且加2之后的长度能整除屏幕宽度时,才只需要这么少的行数就能装得下。
当字符串之间长度差距较大时,所需的空间就越多。比如同一列中,一个字符串老长了,其他的比较短,为了满足规律4,那么短的字符串后面跟的空格数就大大增加。
获得基准行数之后,预分配基准行数*屏幕宽度的字符数大小,就将字符串一一从上到下(排基准行数行),从左到右排列(列数保存给列数指针),同时对于每一列都获取最大字符串长度(存到每列最大字符串长度数组中),重新计算所占总字符数时,将每一列最大字符串长度乘以行数的值算进去。然后将所占总字符数减去预分配的大小,继续分配足够的行来容纳这个差值。
迭代进行上述步骤,直到所占总字符数不大于预分配的大小。返回最后分配的行数。
如下所示为图解:
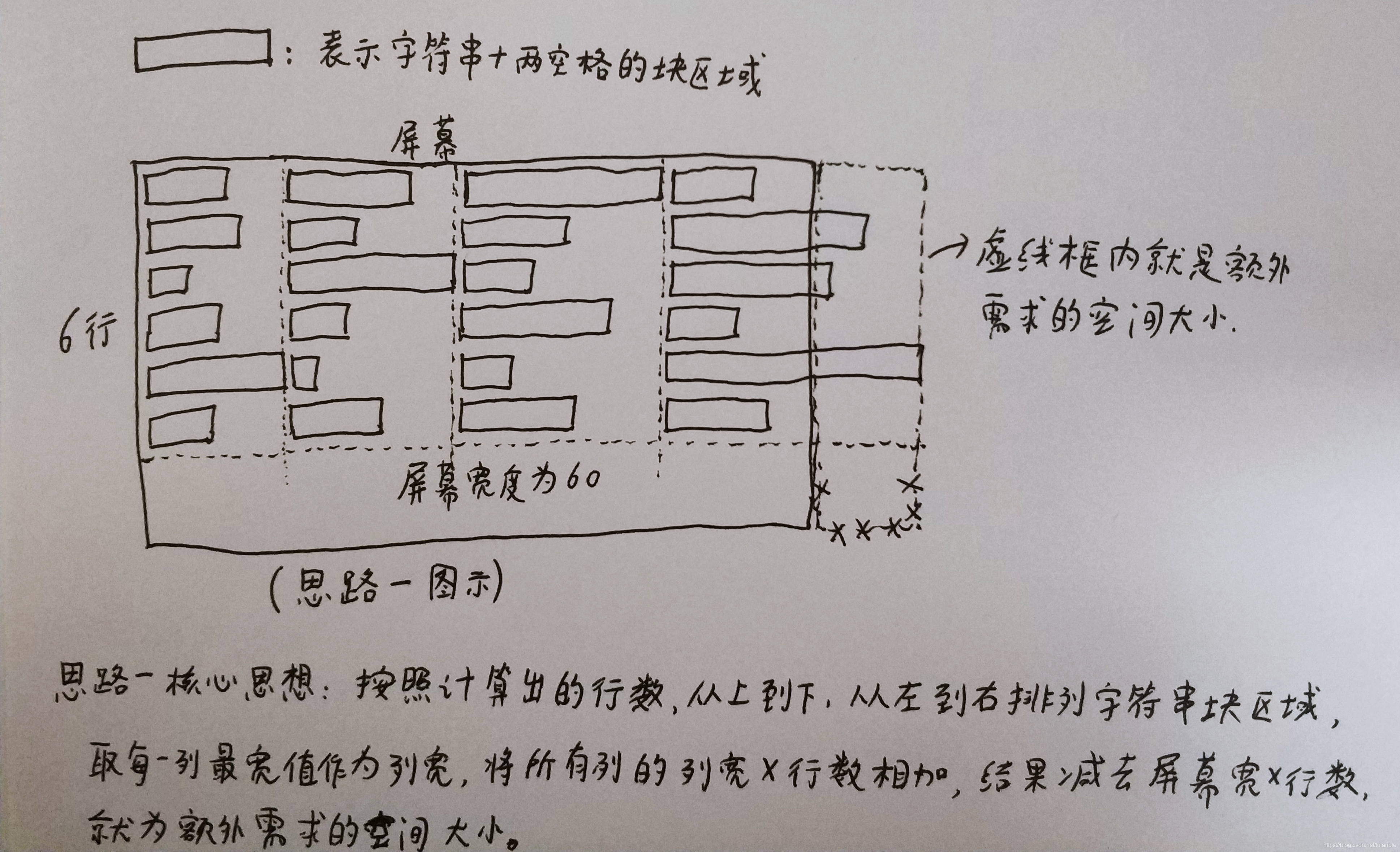
之所以说它是“囫囵吞枣”,是因为在处理超额长度时,直接取最长的那一个代表最后一列的所有字符串长度,一刀切了。这可能导致在某些情况下格式显示不正确。
源代码如下:
int cal_row(char** filenames,int file_cnt,int* cal_col,int* col_max_arr)
{
//获取路径名中的文件名之前的长度
int path_len = strlen(filenames[0]);
while(filenames[0][path_len] != '/'){
--path_len;
}
++path_len;
struct winsize size;
ioctl(STDIN_FILENO,TIOCGWINSZ,&size);
int col = size.ws_col; //获得当前窗口的宽度(字符数)
int col_max = 0;
int cur_file_size = 0;
int filenames_len[file_cnt];
*cal_col = 0;
int i = 0;
//获得每个文件名的字符长度
for(i = 0;i < file_cnt;++i){
filenames_len[i] = strlen(filenames[i]) - path_len;
cur_file_size += (filenames_len[i] + 2); //计算所有文件名字符数加两个空格的总字符数
}
//最小行数,在此基础上迭代
int base_row = cur_file_size / col;
if(cur_file_size % col){
base_row++;
}
int pre_allc_size = 0;
do{
*cal_col = 0;
pre_allc_size = base_row * col;
cur_file_size = 0;
for(i = 0;i < file_cnt;++i){
//当前列的最后一行
if(i % base_row == base_row - 1){
++(*cal_col);
col_max = (filenames_len[i] > col_max) ? filenames_len[i] : col_max;
cur_file_size += (col_max + 2) * base_row;
col_max_arr[*cal_col-1] = col_max;
col_max = 0;
}
//非最后一行
else{
col_max = (filenames_len[i] > col_max) ? filenames_len[i] : col_max;
}
}
//最后一列未满
if(i % base_row){
++(*cal_col);
cur_file_size += (col_max + 2) * (i % base_row);
col_max_arr[*cal_col-1] = col_max;
col_max = 0;
}
int dis = 0;
if(cur_file_size > pre_allc_size){
dis = cur_file_size - pre_allc_size;
}
base_row += (dis / col);
if(dis % col){
++base_row;
}
}while(cur_file_size > pre_allc_size);
return base_row;
}
在进行输出时,从左往右,从上到下打印,后续在代码中体现。
"精打细算"版分栏算法
在计算基准行数时,与"囫囵吞枣"的分栏算法一样。区别就在于对于超额列的处理上。设定一个当前屏幕剩余宽度变量,对于每一个字符串,当其长度超过剩余宽度,则终止排列,所需的额外空间大小为剩余未排列的所有字符串块长度之和。
下图所示为图解:
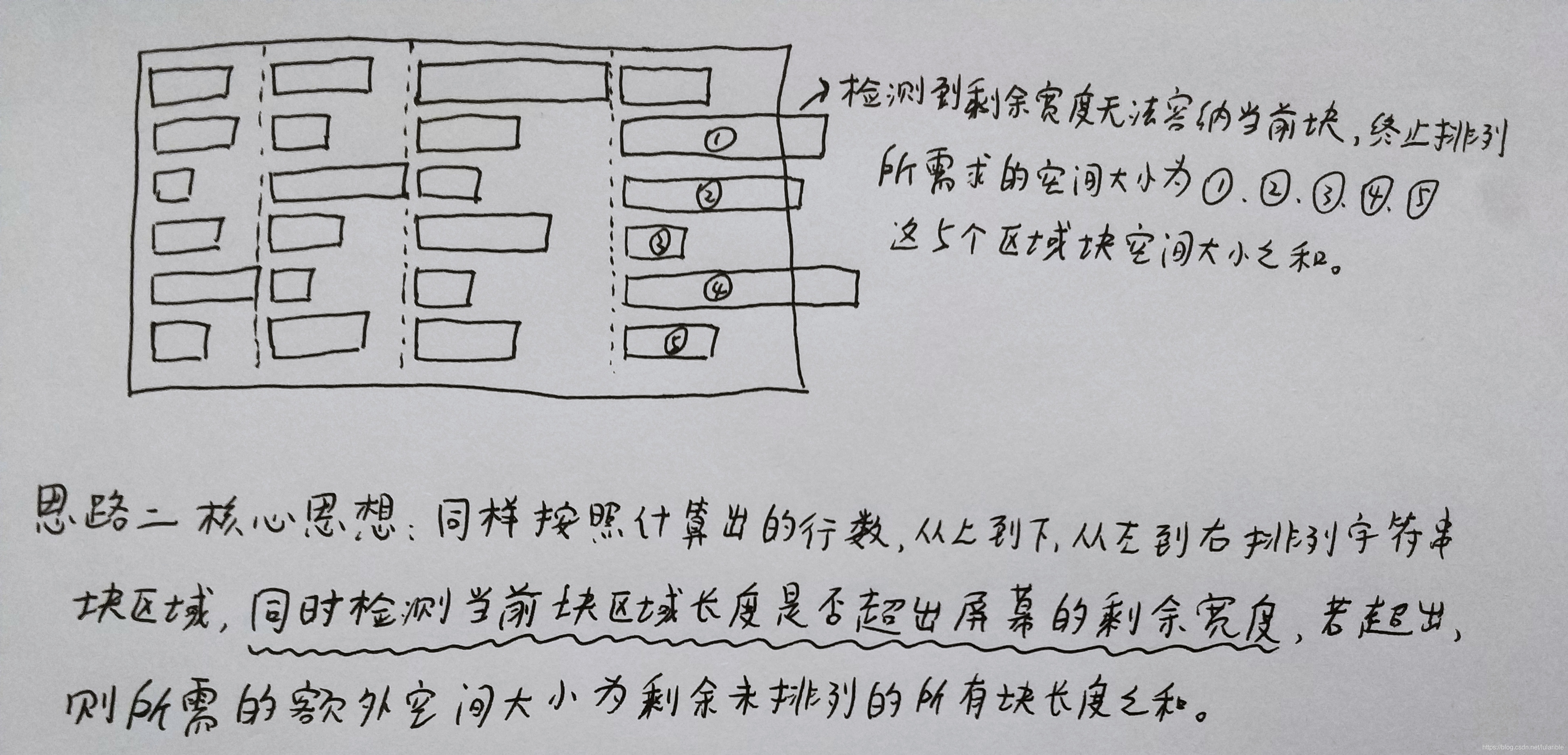
正因为计算超额空间时,算的是每个未排列字符串块长度的真实长度,所以是“精打细算”。并且每次都检测是否超剩余宽度,所以能严格保证最终显示格式的正确性。
源代码如下:
int cal_row(char** filenames,int file_cnt,int* cal_col,int* col_max_arr)
{
//获取路径名中的文件名之前的长度
int path_len = strlen(filenames[0]);
while(filenames[0][path_len] != '/'){
--path_len;
}
++path_len;
struct winsize size;
ioctl(STDIN_FILENO,TIOCGWINSZ,&size);
int col = size.ws_col; //获得当前窗口的宽度(字符数)
int col_max = 0;
int cur_file_size = 0;
int filenames_len[file_cnt];
*cal_col = 0;
int i = 0;
int j = 0;
//获得每个文件名的字符长度
for(i = 0;i < file_cnt;++i){
filenames_len[i] = strlen(filenames[i]) - path_len + 2; //字符串至少带两个空格
/*特殊情况:当最大字符串长度比屏幕宽度大时,直接返回行数:file_cnt,列数:1,最大宽度:最大的字符串长度*/
if(filenames_len[i] > col){
*cal_col = 1;
col_max_arr[0] = filenames_len[i];
return file_cnt;
}
cur_file_size += filenames_len[i];
}
//最小行数,在此基础上迭代
int base_row = cur_file_size / col;
if(cur_file_size % col){
base_row++;
}
int flag_succeed = 0; //标记是否排列完成
//开始排列
while(!flag_succeed){
int remind_width = col; //当前可用宽度
*cal_col = -1;
for(i = 0;i < file_cnt;++i){
/*如果剩余宽度不足以容纳当前字符串,则跳出并分配额外的行空间*/
if(filenames_len[i] > remind_width){
break;
}
//新起的一列
if(i % base_row == 0){
++(*cal_col);
col_max_arr[*cal_col] = filenames_len[i];
}
else{
col_max_arr[*cal_col] = (filenames_len[i] > col_max_arr[*cal_col]) ? filenames_len[i] : col_max_arr[*cal_col];
}
//最后一行,更新剩余的宽度
if(i % base_row == base_row - 1){
remind_width -= col_max_arr[*cal_col];
}
}
//判断是否排列完成
if(i == file_cnt){
flag_succeed = 1;
}
//再分配额外行空间
else{
int extra = 0; //所需额外的字符数
while(i < file_cnt){
extra += filenames_len[i++];
}
if(extra % col){
base_row += (extra / col + 1);
}
else{
base_row += (extra / col);
}
}
}
++(*cal_col); //列标从0开始,所以最后加1
return base_row;
}
分栏效果展示与不足
两种分栏算法的比对
1."囫囵吞枣"版分栏算法和原版ls的对比

前一个是原版ls命令显示效果,后一个是笔者实现的ls03("囫囵吞枣"版)命令显示效果,基本一致。
2."精打细算"版分栏算法和"囫囵吞枣"版分栏算法比对
之前提到过在某些情况下,"囫囵吞枣"版分栏算法格式显示不正确。下图就是一个例子:
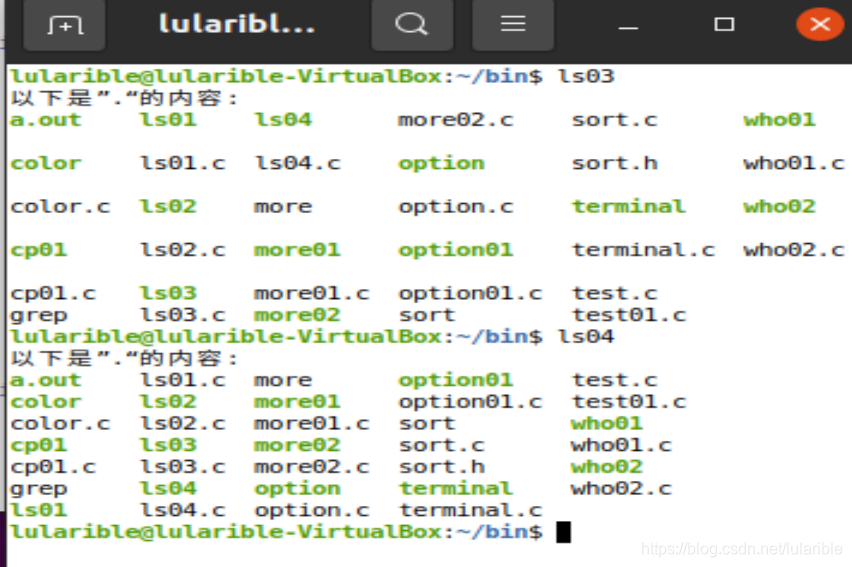
可以看到,"囫囵吞枣(ls03)"显示格式不对,但"精打细算(ls04)"就没问题。所以"精打细算"版分栏算法是"囫囵吞枣"版分栏算法的优化。
不足之处
目前来看,即使是更厉害的"精打细算"版分栏算法,也存在两个主要的不足点。
其一是排序与原版不同,笔者利用的是ASCII值来进行字符串排序的,对于大小写字母,特殊符号和汉字,没有做到像原版ls那样合适。
其二是在显示汉字文件名时,格式不正确,如下所示:
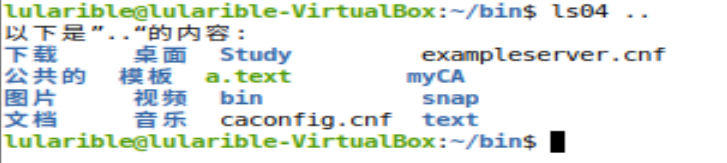
显示出来的存在没有左对齐的列。笔者推测,汉字的字符串单位长度和显示出的所占宽度不是一比一的关系,导致计算时存在偏差。进一步推测,除了汉字,对于其他的特殊符号,只要单位长度和显示出的所占宽度不是一比一,都会存在偏差。如果想要解决这个问题,就要查找这个对应关系,然后进行特定的转换。
ls显示颜色的解决
因为要查找有关颜色方面的信息,笔者通过linux指导信息,确定dircolors这个命令可以给我提供有用的信息,输入:
man dircolors
显示信息如下:
其中有一个选项是:dircolors -p,能够打印出所有默认的颜色信息。我们输入:
dircolors -p > color
">"表示将dircolors -p命令的输出结果保存到color文件中(若没有则自动创建)。
然后输入:
vim color
就可以进入文件查看其中内容了(当然用"more color"命令也行,只是笔者习惯用"vim"命令),如下所示:
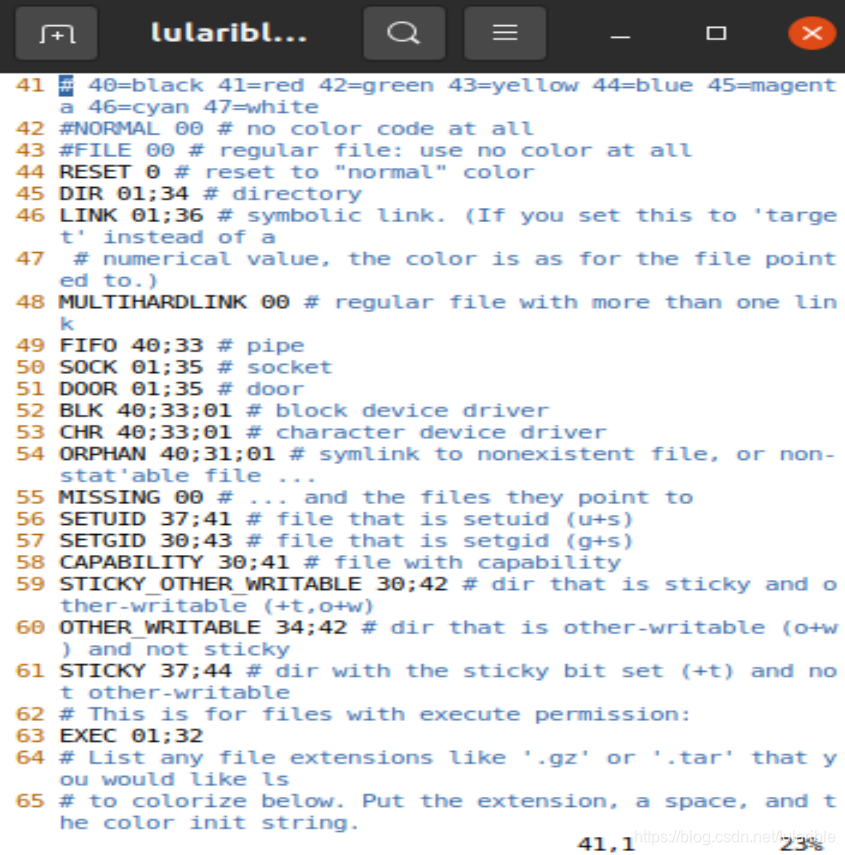
对于每种类型的文件,都给出了默认的颜色值。
其中关于c语言颜色打印,为了防止本文篇幅过长,影响阅读体验,可自行查阅资料,这里随便给出一个链接供参考:
printf打印颜色
接下来的事情就是如何获得指定的文件类型,到这里就引出了下一节内容:ls -l的实现。
ls -l的实现
获取stat结构体内容
首先看一下原版ls -l的输出内容:
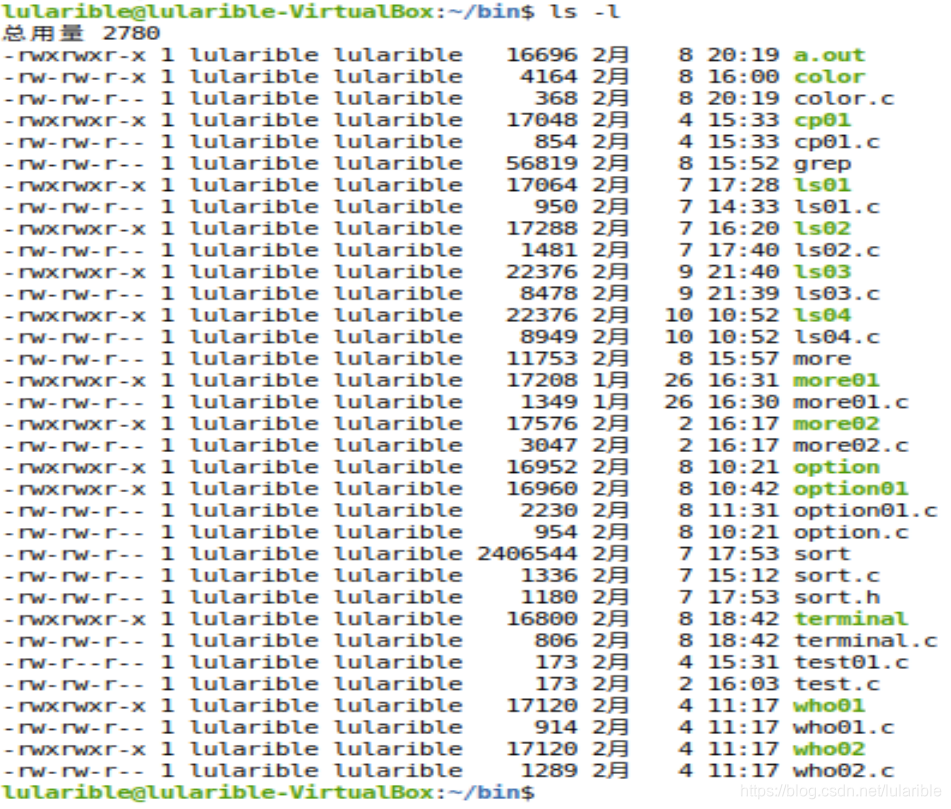
- 第一部分:模式(mode),每行的第一个字符表示文件类型。"-"表示普通文件,"d"表示目录等等。接下来的9个字符表示文件访问权限,分为读权限、写权限和执行权限,又分别针对3种对象:用户、同组用户和其他用户。
- 第二部分:链接数列(links),表示该文件被引用次数。
- 第三部分:文件所有者(owner),表示文件所有者的用户名
- 第四部分:组(group),表示文件所有者所在的组名
- 第五部分:大小(size),表示文件所占字节数
- 第六部分:最后修改时间(laste-modified)
- 第七部分:文件名(name)
如何获得这些信息?笔者通过查阅书籍,知道了一个"stat"函数,能帮助我们拿到上述信息。
输入:
man 2 stat
ps:直接输入man stat得到的是stat(1),是一个终端命令,不是我们想要的,在其中的“SEE ALSO”找到的stat(2)才是我们需要的。
将文件路径传入stat函数,可以获得一个stat类型的结构体,该结构体定义如下:
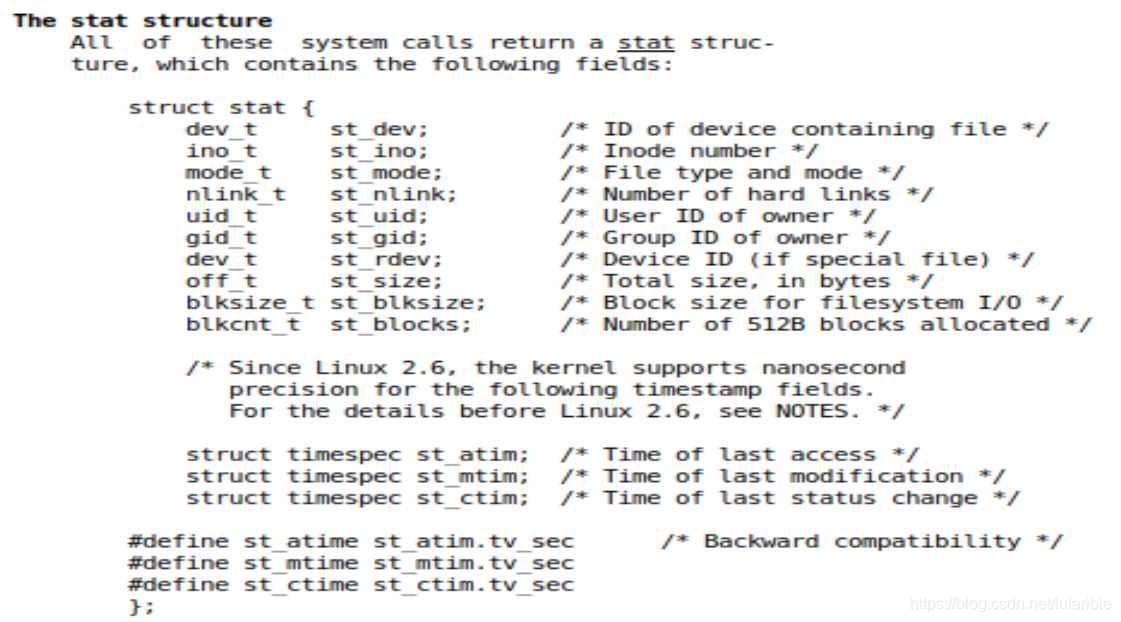
太棒了,我们要的信息它都有!
格式转换
但是不要高兴的太早,如果直接打印这个stat结构体里面的st_mode、st_uid、st_gid和st_mtime,显示的是一些数字,所以还要对它们一一转换成字符串再输出。
st_mode位运算
st_mode实际上是一个16位的二进制数,其结构如下:
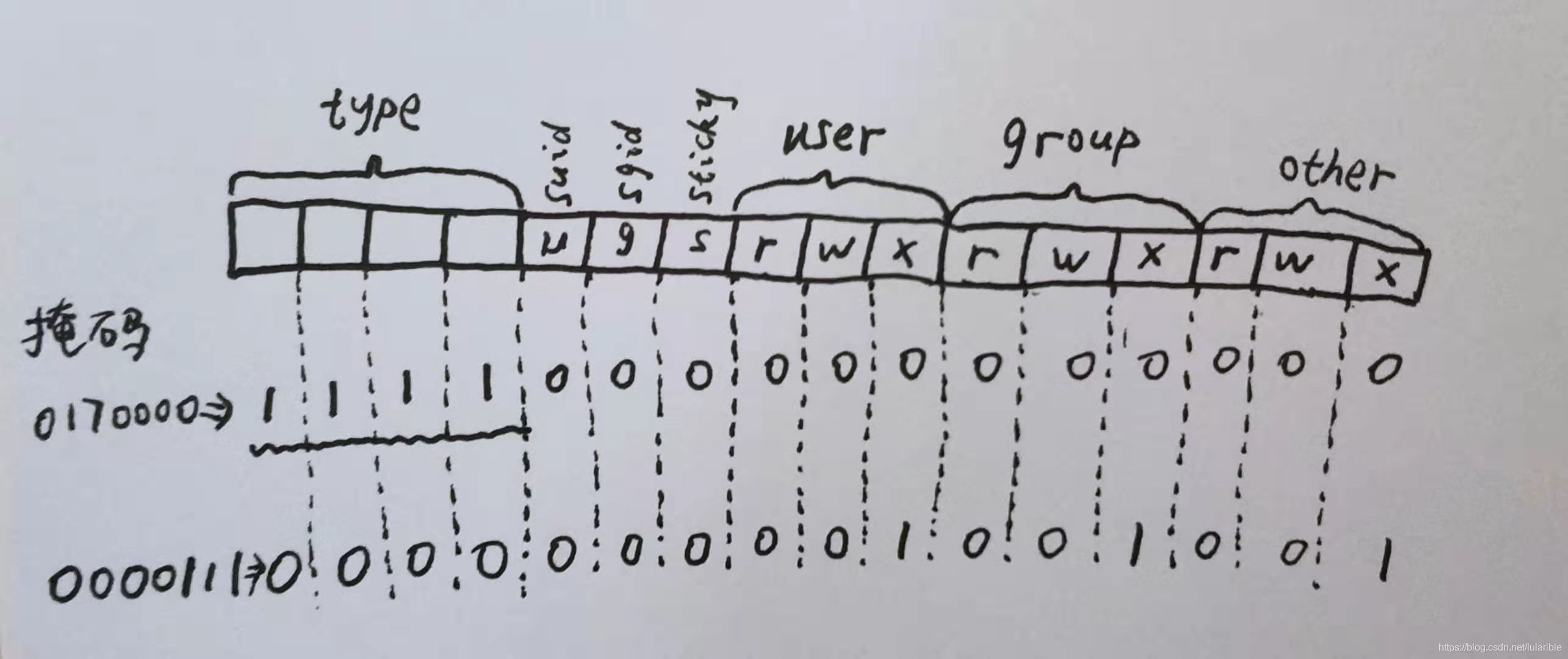
Linux中文件被分为7大类,也就是有7种不同的编码,我们只要提取其中的type位,然后与定义的文件类比对就能知道该文件类型了。同样的,对于权限位,只要此位为1,就置为'r'、'w'或'x',否则置为'-'。
如何判断特定的位的值呢?这里就需要掩码这个东西了,笔者在计算机网络中学过类似的玩意--ip地址掩码。掩码的作用就是将其他位遮挡住,只暴露所需的位。即掩码将其他的位设为0,所需的位设为1,利用"与"运算(&),把待处理的数和掩码相与,将结果与预先存放的数对比看是否一致。
//定义判断文件类型的宏
#define S_ISFIFO(m) (((m)&(0170000))==(0010000))
#define S_ISDIR(m) (((m)&(0170000))==(0040000))
#define S_ISCHR(m) (((m)&(0170000))==(0020000))
#define S_ISBLK(m) (((m)&(0170000))==(0060000))
#define S_ISREG(m) (((m)&(0170000))==(0100000))
#define S_ISLNK(m) (((m)&(0170000))==(0120000))
#define S_ISSOCK(m) (((m)&(0170000))==(0140000))
#define S_ISEXEC(m) (((m)&(0000111))!=(0))
举例来说:上图中第一个掩码是0170000,第一个0表示这个数是八进制的,转换为二进制为1111000000000000,即type位全部为1,假设st_mode为0001000000000000,相与之后得到0001000000000000,即八进制的0100000,查表就知道这是一个regular文件。
同理,上图中第二个掩码是0000111,它把'x'位设为1,其他位为0,与st_mode相与后,如果st_mode中任意一个'x'位为1,那么结果就不等于0,由此可以判断文件是否为可执行文件。
这样,我们就可以利用掩码和预定义的值来协助完成模式字符串的转换。
st_uid/st_gid/st_mtime格式转换
借助getpwuid函数,getgrgid函数和ctime函数分别完成用户名、组名和时间格式的转换。
ls -l效果展示
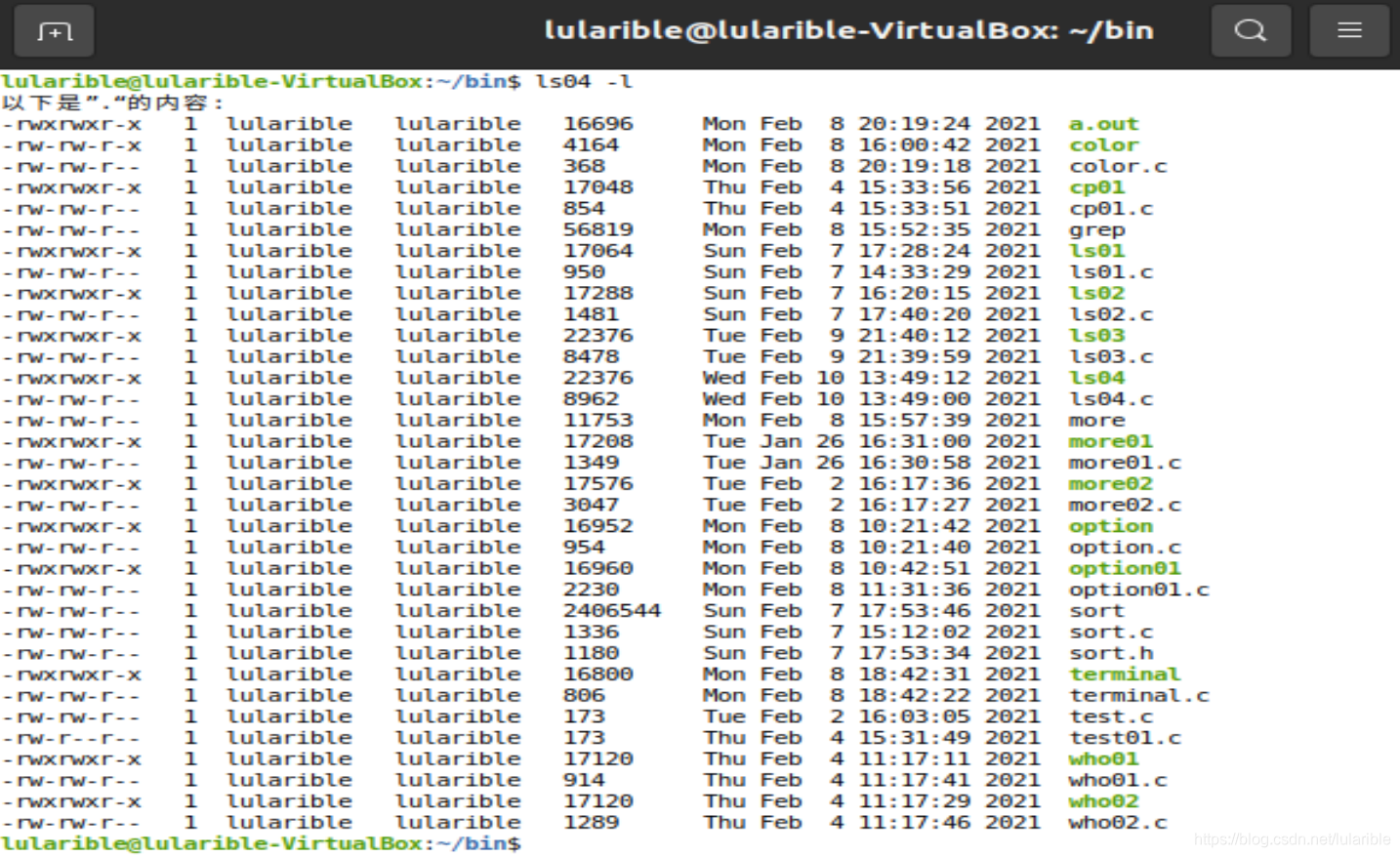
源码
ls可选参数:-a ,-l
/*
* ls04.c
* writed by lularible
* 2021/02/09
* ls -a -l
*/
#include<stdio.h>
#include<stdlib.h>
#include<malloc.h>
#include<sys/types.h>
#include<dirent.h>
#include<string.h>
#include<sys/ioctl.h>
#include<unistd.h>
#include<termios.h>
#include<sys/stat.h>
#include<time.h>
#include</home/lularible/bin/sort.h>
#include<pwd.h>
#include<grp.h>
/*
//定义判断文件类型的宏,系统中已经定义过了,这里写出来供参考
#define S_ISFIFO(m) (((m)&(0170000))==(0010000))
#define S_ISDIR(m) (((m)&(0170000))==(0040000))
#define S_ISCHR(m) (((m)&(0170000))==(0020000))
#define S_ISBLK(m) (((m)&(0170000))==(0060000))
#define S_ISREG(m) (((m)&(0170000))==(0100000))
#define S_ISLNK(m) (((m)&(0170000))==(0120000))
#define S_ISSOCK(m) (((m)&(0170000))==(0140000))
*/
#define S_ISEXEC(m) (((m)&(0000111))!=(0))
//函数声明
void do_ls(const char*); //主框架
void error_handle(const char*); //错误处理
void restored_ls(struct dirent*,const char*); //暂存文件名
void color_print(char*,int,int); //根据文件类型打印不同颜色的文件名
void showtime(long);
void show_with_l(); //显示带-l参数的内容
void show_without_l(); //显示不带-l参数的内容
int cal_row(char**,int,int*,int*); //为分栏算法提供要显示的行/列数
void mode_to_letters(int,char*); //-l中,转换mode属性为字符串
char* uid_to_name(uid_t); //-l中,转换uid为字符串
char* gid_to_name(gid_t); //-l中,转换gid为字符串
//全局变量
int a_flag = 0; //是否带-a参数
int l_flag = 0; //是否带-l参数
char* dirnames[4096]; //暂存目录名
int dir_cnt = 0; //目录个数
char* filenames[4096]; //暂存目录中文件名
int file_cnt = 0;
int main(int argc,char* argv[])
{
//存储文件名和所带参数
while(--argc){
++argv;
//遇到可选参数
if(*argv[0] == '-'){
while(*(++(*argv))){
if(**argv == 'a'){
a_flag = 1;
}
else if(**argv == 'l'){
l_flag = 1;
}
else{
error_handle(*argv);
}
}
}
//遇到目录名
else{
dirnames[dir_cnt++] = *argv;
}
}
if(dir_cnt == 0){
dirnames[dir_cnt++] = ".";
}
sort(dirnames,0,dir_cnt - 1);
//对filenames中文件名,对于不同的可选参数的处理
int i = 0;
DIR* cur_dir;
struct diren* cur_item;
//遍历目录文件
for(i = 0;i < dir_cnt;++i){
printf("以下是”%s“的内容:\n",dirnames[i]);
do_ls(dirnames[i]);
}
}
void do_ls(const char* dir_name)
{
DIR* cur_dir;
struct dirent* cur_item;
file_cnt = 0;
//打开目录
if((cur_dir = opendir(dir_name)) == NULL){
error_handle(dir_name);
}
else{
//读取目录并显示信息
//将文件名存入数组
while((cur_item = readdir(cur_dir))){
restored_ls(cur_item,dir_name);
}
//字典序排序
sort(filenames,0,file_cnt-1);
//输出结果
if(l_flag){
//带-l参数
show_with_l();
}
else{
//不带-l参数
show_without_l();
}
//释放内存
int i = 0;
for(i = 0;i < file_cnt;++i){
free(filenames[i]);
}
//关闭目录
closedir(cur_dir);
}
}
void restored_ls(struct dirent* cur_item,const char* dir_name)
{
char* file_path = (char*)malloc(sizeof(char)*256);
strcpy(file_path,dir_name);
char* result = cur_item->d_name;
strcat(file_path,"/");
strcat(file_path,result);
//当不带-a参数时,隐藏以‘.'开头的文件
if(!a_flag && *result == '.') return;
filenames[file_cnt++] = file_path;
}
void show_without_l()
{
int i = 0;
int j = 0;
struct stat file_info; //保存文件属性的结构体
//分栏算法
int col = 0;
int col_max_arr[256];
int row = cal_row(filenames,file_cnt,&col,col_max_arr);
for(i = 0;i < row;++i){
for(j = 0;j < col;++j){
if((j*row+i) < file_cnt){
if(stat(filenames[j*row+i],&file_info) != -1){
int mode = file_info.st_mode;
color_print(filenames[j*row+i],mode,col_max_arr[j]);
}
else{
error_handle(filenames[j*row+i]);
}
}
}
printf("\n");
}
}
void show_with_l()
{
struct stat info;
char modestr[11];
int i = 0;
for(i = 0;i < file_cnt;++i){
if(stat(filenames[i],&info) == -1){
error_handle(filenames[i]);
}
else{
mode_to_letters(info.st_mode,modestr);
printf("%s",modestr);
printf("%4d ",(int)info.st_nlink);
printf("%-12s",uid_to_name(info.st_uid));
printf("%-12s",gid_to_name(info.st_gid));
printf("%-8ld ",(long)info.st_size);
showtime((long)info.st_mtime);
color_print(filenames[i],info.st_mode,0);
printf("\n");
}
}
}
void showtime(long timeval)
{
char* tm;
tm = ctime(&timeval);
printf("%24.24s ",tm);
}
void color_print(char* pathname,int filemode,int width)
{
//截取路径名中的文件名
char* filename;
int len = strlen(pathname);
while(pathname[len] != '/'){
--len;
}
filename = &pathname[len+1];
if(S_ISDIR(filemode)){
printf("\033[01;34m%-*s\033[0m",width,filename);
}
else if(S_ISLNK(filemode)){
printf("\033[01;36m%-*s\033[0m",width,filename);
}
else if(S_ISFIFO(filemode)){
printf("\033[40;33m%-*s\033[0m",width,filename);
}
else if(S_ISSOCK(filemode)){
printf("\033[01;35m%-*s\033[0m",width,filename);
}
else if(S_ISBLK(filemode)){
printf("\033[40;33;01m%-*s\033[0m",width,filename);
}
else if(S_ISCHR(filemode)){
printf("\033[40;33;01m%-*s\033[0m",width,filename);
}
else if(S_ISREG(filemode)){
if(S_ISEXEC(filemode)){
printf("\033[01;32m%-*s\033[0m",width,filename);
}
else{
printf("%-*s",width,filename);
}
}
else{
printf("%-*s",width,filename);
}
}
int cal_row(char** filenames,int file_cnt,int* cal_col,int* col_max_arr)
{
//获取路径名中的文件名之前的长度
int path_len = strlen(filenames[0]);
while(filenames[0][path_len] != '/'){
--path_len;
}
++path_len;
struct winsize size;
ioctl(STDIN_FILENO,TIOCGWINSZ,&size);
int col = size.ws_col; //获得当前窗口的宽度(字符数)
int col_max = 0;
int cur_file_size = 0;
int filenames_len[file_cnt];
*cal_col = 0;
int i = 0;
int j = 0;
//获得每个文件名的字符长度
for(i = 0;i < file_cnt;++i){
filenames_len[i] = strlen(filenames[i]) - path_len + 2; //字符串至少带两个空格
//特殊情况:当最大字符串长度比屏幕宽度大时,直接返回行数:file_cnt,列数:1,最大宽度:最大的字符串长度
if(filenames_len[i] > col){
*cal_col = 1;
col_max_arr[0] = filenames_len[i];
return file_cnt;
}
cur_file_size += filenames_len[i];
}
//最小行数,在此基础上迭代
int base_row = cur_file_size / col;
if(cur_file_size % col){
base_row++;
}
int flag_succeed = 0; //标记是否排列完成
//开始排列
while(!flag_succeed){
int remind_width = col; //当前可用宽度
*cal_col = -1;
for(i = 0;i < file_cnt;++i){
//如果剩余宽度不足以容纳当前字符串,则跳出并分配额外的行空间
if(filenames_len[i] > remind_width){
break;
}
//新起的一列
if(i % base_row == 0){
++(*cal_col);
col_max_arr[*cal_col] = filenames_len[i];
}
else{
col_max_arr[*cal_col] = (filenames_len[i] > col_max_arr[*cal_col]) ? filenames_len[i] : col_max_arr[*cal_col];
}
//最后一行,更新剩余的宽度
if(i % base_row == base_row - 1){
remind_width -= col_max_arr[*cal_col];
}
}
//判断是否排列完成
if(i == file_cnt){
flag_succeed = 1;
}
//再分配额外行空间
else{
int extra = 0; //所需额外的字符数
while(i < file_cnt){
extra += filenames_len[i++];
}
if(extra % col){
base_row += (extra / col + 1);
}
else{
base_row += (extra / col);
}
}
}
++(*cal_col); //列标从0开始,所以最后要加1
return base_row;
}
void mode_to_letters(int mode,char* str)
{
strcpy(str,"----------"); //文件类型与权限,先占好10个坑位
//这里只转换7种文件类型常见的三种
if(S_ISDIR(mode)) str[0] = 'd';
if(S_ISCHR(mode)) str[0] = 'c';
if(S_ISBLK(mode)) str[0] = 'b';
//权限转换
//当前用户权限
if(mode & S_IRUSR) str[1] = 'r';
if(mode & S_IWUSR) str[2] = 'w';
if(mode & S_IXUSR) str[3] = 'x';
//当前组其他用户权限
if(mode & S_IRGRP) str[4] = 'r';
if(mode & S_IWGRP) str[5] = 'w';
if(mode & S_IXGRP) str[6] = 'x';
//其他
if(mode & S_IROTH) str[7] = 'r';
if(mode & S_IWOTH) str[8] = 'w';
if(mode & S_IXOTH) str[9] = 'x';
}
char* uid_to_name(uid_t uid)
{
struct passwd* pw_ptr;
static char numstr[10];
if((pw_ptr = getpwuid(uid)) == NULL){
sprintf(numstr,"%d",uid);
return numstr;
}
else{
return pw_ptr->pw_name;
}
}
char* gid_to_name(gid_t gid)
{
struct group* grp_ptr;
static char numstr[10];
if((grp_ptr = getgrgid(gid)) == NULL){
sprintf(numstr,"%d",gid);
return numstr;
}
else{
return grp_ptr->gr_name;
}
}
void error_handle(const char* name)
{
perror(name);
}
总结
本次优化了ls显示效果,实现了ls -l。ls -l就是业务多了一点,需要进行多个格式转换处理,算法上无太多磕绊的点,比较通顺。笔者的大部分时间都花费在实现ls的"分栏算法"上,其中的算法逻辑值得研究,而且肯定还有更好的优化算法。看起来很简单的一个ls显示,蕴藏着的技术细节却不少,这就是linux的魅力所在吧。
参考资料
《Understanding Unix/Linux Programming A Guide to Theory and Practice》
欢迎大家转载本人的博客(需注明出处),本人另外还有一个个人博客网站:lularible的个人博客,欢迎前去浏览。
Linux系统编程【3.2】——ls命令优化版和ls -l实现的更多相关文章
- Linux系统编程【3.1】——编写ls命令
ls命令简介 老规矩,直接在终端输入:man ls (有关于man命令的简介可以参考笔者前期博客:Linux系统编程[1]--编写more命令) 可以看到,ls命令的作用是显示目录中的文件名,它带有可 ...
- Linux系统编程【2】——编写who命令
学到的知识点 通过实现who命令,学到了: 1.使用man命令寻找相关信息 2.基于文件编程 3.体会到c库函数与系统调用的不同 4.加深对缓冲技术的理解 who命令的作用 who命令的使用 在控制终 ...
- 读书笔记之Linux系统编程与深入理解Linux内核
前言 本人再看深入理解Linux内核的时候发现比较难懂,看了Linux系统编程一说后,觉得Linux系统编程还是简单易懂些,并且两本书都是讲Linux比较底层的东西,只不过侧重点不同,本文就以Linu ...
- Linux 系统编程 学习:02-进程间通信1:Unix IPC(1)管道
Linux 系统编程 学习:02-进程间通信1:Unix IPC(1)管道 背景 上一讲我们介绍了创建子进程的方式.我们都知道,创建子进程是为了与父进程协作(或者是为了执行新的程序,参考 Linux ...
- Linux 系统编程 学习:04-进程间通信2:System V IPC(1)
Linux 系统编程 学习:04-进程间通信2:System V IPC(1) 背景 上一讲 进程间通信:Unix IPC-信号中,我们介绍了Unix IPC中有关信号的概念,以及如何使用. IPC的 ...
- Linux系统编程@进程通信(一)
进程间通信概述 需要进程通信的原因: 数据传输 资源共享 通知事件 进程控制 Linux进程间通信(IPC)发展由来 Unix进程间通信 基于System V进程间通信(System V:UNIX系统 ...
- Linux C 程序 文件操作(Linux系统编程)(14)
文件操作(Linux系统编程) 创建一个目录时,系统会自动创建两个目录.和.. C语言实现权限控制函数 #include<stdio.h> #include<stdlib.h> ...
- linux系统编程:cp的另外一种实现方式
之前,这篇文章:linux系统编程:自己动手写一个cp命令 已经实现过一个版本. 这里再来一个版本,涉及知识点: linux系统编程:open常用参数详解 Linux系统编程:简单文件IO操作 /*= ...
- 《Linux系统编程(第2版)》
<Linux系统编程(第2版)> 基本信息 作者: (美)Robert Love 译者: 祝洪凯 李妹芳 付途 出版社:人民邮电出版社 ISBN:9787115346353 上架时间:20 ...
随机推荐
- 基础Markdown语法
Markdown语法 1.标题 //标题语法 # 一级标题 ## 二级标题 ### 三级标题 #### 四级标题 ##### 五级标题 ###### 六级标题 一级标题 二级标题 三级标题 四级标题 ...
- libnum报错问题解决
之前在使用python libnum库时报错 附上报错内容 Traceback (most recent call last) : File" D:/python file/ctf/RSA共 ...
- 关于JDK15的简单理解
一.为什么要了解JDK15? 2020年9月15日,Oracle官方发布了JDK15版本,及时关注官方的更新动态,可以让我们在日常开发中更合理的选择更加优秀的工具方法,避免使用一些过时的或一些即将被删 ...
- Jenkins 部署打包文件 并通过SSH上传到 linux服务器
编译 发布 打包成zip文件 dotnet clean : dotnet的命令清除解决方案 dotnet build : dotnet的命令重新生成 dotnet publish .\Hy.MyDem ...
- Java多线程基础知识笔记(持续更新)
多线程基础知识笔记 一.线程 1.基本概念 程序(program):是为完成特定任务.用某种语言编写的一组指令的集合.即指一段静态的代码,静态对象. 进程(process):是程序的一次执行过程,或是 ...
- QTextEdit的paste
By 鬼猫猫 20130117 http://www.cnblogs.com/muyr/ 背景 QTextEdit中粘贴一大段文字时,EasyDraft中粘贴进去的文字们的格式就乱了,处于无格式.还有 ...
- Python内存浅析
Python内存分析 内存机制 转述:内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构. Python的内存机制和Java差不多,分为 ...
- Mybatis报错:Could not find resource mybatis-conf.xml
Mybatis报错:Could not find resource mybatis-conf.xml 报错截图: 报错内容: java.io.IOException: Could not find r ...
- moco框架加入cookies
一.带cookie信息的get请求 注意:cookie是放在request里的,一般登录的场景这些会用到 1.代码 2.接口管理工具添加 注意:cooike的域和路径都要添加 二.带cookie信息的 ...
- (008)每日SQL学习:Oracle Not Exists 及 Not In 使用
今天遇到一个问题,not in 查询失效,我以为是穿越了,仔细查了点资料,原来理解有误! select value from temp_a a where a.id between 1 and 100 ...