Longest common subsequence(LCS)
问题
说明该问题在生物学中的实际意义
Biological applications often need to compare the DNA of two (or more) different organisms. A strand of DNA consists of a string of molecules called bases, where the possible bases are adenine, guanine, cytosine, and thymine(腺嘌呤,鸟嘌呤,胞嘧啶和胸腺嘧啶). Representing each of these bases by its initial letter, we can express a strand of DNA as a string over the finite set {A, C, G, T}. For example, the DNA of one organism may be S1 = ACCGGTCGAGTGCGCGGAAGCCGGCCGAA, and the DNA of another organism may be S2 = GTCGTTCGGAATGCCGTTGCTCTGTAAA. One reason to compare two strands of DNA is to determine how “similar” the two strands are, as some measure of how closely related the two organisms are. We can, and do, define similarity in many different ways. For example, we can say that two DNA strands are similar if one is a substring of the other. In our example, neither S1 nor S2 is a substring of the other. Alternatively, we could say that two strands are similar if the number of changes needed to turn one into the other is small. Yet another way to measure the similarity of strands S1 and S2 is by finding a third strand S3 in which the bases in S3 appear in each of S1 and S2; these bases must appear in the same order, but not necessarily consecutively. The longer the strand S3 we can find, the more similar S1 and S2 are. In our example, the longest strand S3 is GTCGTCGGAAGCCGGCCGAA.
该问题涉及的概念
子序列
given a sequence X = {x1, x2, .... , xm}, another sequence Z = {z1, z2, ... ,zk} is a subsequence of X if there exists a strictly increasing sequence {i1, i1, ... , ik} of indices of X such that for all j = 1, 2, ... , k, we have xij = zj.
子序列要求元素的顺序一致,但是不要求连续。
公共子序列
a sequence Z is a common subsequence of X and Y if Z is a subsequence of both X and Y.
问题形式化定义
Input:
- X = <x1, x2, .... , xm>
- Y = <y1, y2, .... , yn>
Output
- a maximum length common subsequence of X and Y
暴力算法分析
In a brute-force approach to solving the LCS problem, we would enumerate all subsequences of X and check each subsequence to see whether it is also a subsequence of Y, keeping track of the longest subsequence we find. Each subsequence of X corresponds to a subset of the indices {1, 2, ... , m} of X. Because X has 2m subsequences, this approach requires exponential time, making it impractical for long sequences.
动态规划解法
符号定义
To be precise, given a sequence X = <x1, x2, .... , xm>,we define the ith prefix of X, for i = {0, 1,..., m} as Xi = <x1, x2, .... , xi> . For example, if X = {A, B, C, B, D, A, B},then X4 = {A, B, C, B} and X0 is the empty sequence.
优化子结构
Theorem (Optimal substructure of an LCS)
Let X = <x1, x2, .... , xm> and Y = <y1, y2, .... , yn> be sequences, and let Z = {z1, z2, ... ,zk} be any LCS of X and Y.
- If xm = yn, then zk = xm = yn and Zk-1 is an LCS of Xm- 1 and Yn-1.
- If xm != yn, then zk != xm implies that Z is an LCS of Xm-1 and Y.
- If xm != yn, then zk != yn implies that Z is an LCS of X and Yn-1.
Proof
(1)
If zk != xm , then we could append xm = yn to Z to obtain a common subsequence of X and Y of length k + 1, contradicting the supposition that Z is a longest common subsequence of X and Y. Thus, we must have zk = xm = yn .
Now, the prefix Zk-1 is a length-(k-1) common subsequence of Xm-1 and Yn-1. We wish to show that it is an LCS. Suppose for the purpose of contradiction that there exists a common subsequence W of Xm-1 and Yn-1 with length greater than k - 1. Then, appending xm = yn to W produces a common subsequence of X and Y whose length is greater than k, which is a contradiction.
(2)
If zk != xm, then Z is a common subsequence ofXm-1 and Y. If there were a common subsequence W ofXm-1 and Y with length greater than k ,then W would also be a common subsequence of Xm and Y, contradicting the assumption that Z is an LCS of X and Y.
(3)
The proof is symmetric to (2).
子问题重叠性
To find an LCS of X and Y, we may need to find the LCSs of X and Yn-1 and of Xm-1 and Y. But each of these subproblems has the subsubproblem of finding an LCS of Xm-1 and Yn-1. Many other subproblems share subsubproblems.
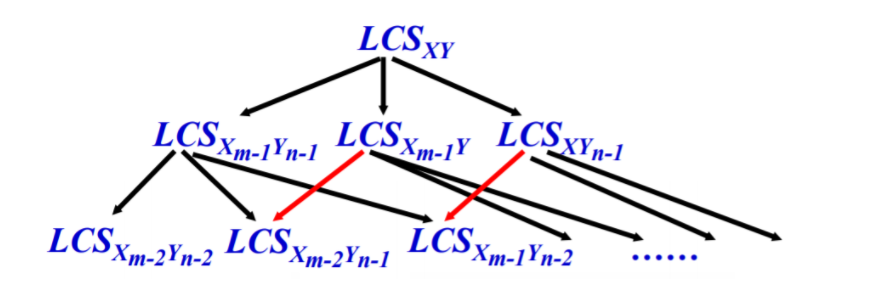
递归的定义优化解的代价
Let us define c[i, j] to be the length of an LCS of the sequences Xi and Yj.
If either i = 0 or j = 0, one of the sequences has length 0, and so the LCS has length 0. The optimal substructure of the LCS problem gives the recursive formula
- c[ i,j ] = 0, if i = 0 或 j = 0
- c[ i,j ] = c[ i-1,j-1] + 1, if i,j >0 且 Xi = Yj
- c[ i,j ] = max{ c[i, j-1], c[i-1, j]}, if i,j >0 且 Xi != Yj
计算优化解的代价算法
bottom-up method

LCS-length_bottomup(X, Y)
m = length(X);
n = length(Y);
For i = 1 To m Do
C[i,0] = 0;
For j = 1 To n Do
C[0,j] = 0;
For i = 1 To m Do
For j = 1 To n Do
If Xi == Yj
Then C[i,j] = C[i-1,j-1]+1;B[i,j] = “”;
Else If C[i-1,j] < C[i,j-1]
Then C[i,j] = C[i-1,j];
B[i,j] = “↑”;
Else
C[i,j] = C[i,j-1];
B[i,j] = “←”;
Return C and B
top-down with memoization
LCS-LENGTH-topdown( X, Y, m ,n )
Let b[0..m][0..n] be an new array
for i = 1 to m
for j = 1 to n
b[i][j] = -1
return LCS-LENGTH-AUX(X, Y, m ,n ,b ,s)
LCS-LENGTH-AUX(X, Y, i ,j ,b ,s)
if b[i][j] != -1
return b[i][j] && s
if i = 0 || j = 0
b[i][j] = 0
else if X[i] == X[j]
b[i][j] = LCS-LENGTH-AUX(X, Y, i-1 ,j-1 ,b ,s) + 1
else
b[i][j] = LCS-LENGTH-AUX(X, Y, i-1 ,j ,b ,s) > LCS-LENGTH-AUX(X, Y, i ,j-1 ,b ,s) ? LCS-LENGTH-AUX(X, Y, i ,j-1 ,b ,s):LCS-LENGTH-AUX(X, Y, i-1 ,j ,b ,s)
return b[i][j]
实际代码
#include<stdio.h>
#include<string.h>
#define M 7
#define N 6
void LCS_length_bottomup(char* x, char* y);
void LCS_length_updown(char* x, char* y);
int LCS_length_AUX(char* x, char* y, int i, int j, int b[M + 1][N + 1], char s[M + 1][N + 1]);
void main() {
char x[M + 1] = { ' ', 'A', 'B', 'C', 'B', 'D', 'A', 'B' };
char y[N + 1] = { ' ','B','D','C','A','B','A' };
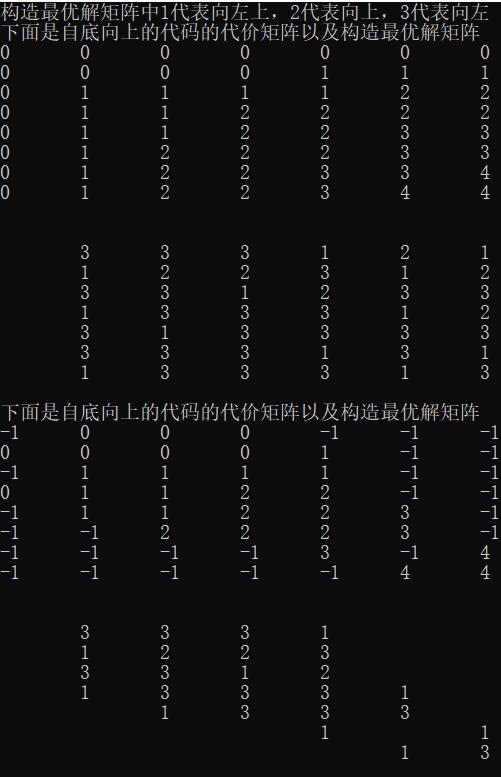
printf("构造最优解矩阵中1代表向左上,2代表向上,3代表向左\n");
printf("下面是自底向上的代码的代价矩阵以及构造最优解矩阵\n");
LCS_length_bottomup(x, y);
printf("下面是自底向上的代码的代价矩阵以及构造最优解矩阵\n");
LCS_length_updown(x, y);
}
void LCS_length_updown(char* x, char* y) {
int b[M + 1][N + 1];
char s[M + 1][N + 1];
memset(b, -1, (M + 1) * (N + 1) * sizeof(int));
memset(s, ' ', (M + 1) * (N + 1) * sizeof(char));
LCS_length_AUX(x, y, M, N, b, s);
for (int i = 0; i <= M; i++) {
for (int j = 0; j <= N; j++) {
printf("%d ", b[i][j]);
}
printf("\n");
}
printf("\n");
for (int i = 0; i <= M; i++) {
for (int j = 0; j <= N; j++) {
printf("%c ", s[i][j]);
}
printf("\n");
}
printf("\n");
}
int LCS_length_AUX(char* x, char* y,int i, int j, int b[M + 1][N + 1], char s[M + 1][N + 1]){
if (b[i][j] != -1) return b[i][j];
if (i == 0 || j == 0) {
b[i][j] = 0;
}
else if (x[i] == y[j]) {
b[i][j] = LCS_length_AUX(x, y, i-1, j-1, b, s) + 1;
s[i][j] = '1';//左上
}
else {
int p = LCS_length_AUX(x, y, i , j - 1, b, s);
int q = LCS_length_AUX(x, y, i - 1, j , b, s);
if (p > q) {
b[i][j] = p;
s[i][j] = '2';//上
}
else {
b[i][j] = q;
s[i][j] = '3';//左
}
}
return b[i][j];
}
void LCS_length_bottomup(char *x, char *y) {
int b[M + 1][N + 1];
char s[M + 1][N + 1];
memset(b, -1, (M + 1) * (N + 1) * sizeof(int));
memset(s, ' ', (M + 1) * (N + 1) * sizeof(char));
for (int i = 0; i <= M; i++)
b[i][0] = 0;
for (int i = 0; i <= N; i++)
b[0][i] = 0;
for (int i = 1; i <= M; i++) {
for (int j = 1; j <= N; j++) {
if (x[i] == y[j]) {
b[i][j] = b[i - 1][j - 1] + 1;
s[i][j] = '1';//左上
}
else if (b[i - 1][j] < b[i][j - 1]) {
b[i][j] = b[i][j - 1];
s[i][j] = '2';//上
}
else {
b[i][j] = b[i - 1][j];
s[i][j] = '3';//左
}
}
}
for (int i = 0; i <= M; i++) {
for (int j = 0; j <= N; j++) {
printf("%d ", b[i][j]);
}
printf("\n");
}
printf("\n");
for (int i = 0; i <= M; i++) {
for (int j = 0; j <= N; j++) {
printf("%c ", s[i][j]);
}
printf("\n");
}
printf("\n");
}
下面是输出结果,极为有趣的是,从这里可以看出这两种构造方法的区别,一种完全遍历,一种只会遍历其需要的单位。
构造优化解算法
Print-LCS(B, X, i, j)
IF i=0 or j=0 THEN Return;
IF B[i, j]=“”
Print-LCS(B, X, i-1, j-1);
Print Xi;
ELSE If B[i, j]=“↑”
THEN Print-LCS(B, X, i-1, j);
ELSE
Print-LCS(B, X, i, j-1)
实际代码:
void Print_LCS(char s[M + 1][N + 1], char* x, int i, int j) {
if (i == 0 || j == 0)
return;
if (s[i][j] == '1') {
Print_LCS(s, x, i - 1, j - 1);
printf("%c ", x[i]);
}
else if (s[i][j] == '2') {
Print_LCS(s, x, i , j - 1);
}
else {
Print_LCS(s, x, i - 1, j);
}
}
这里给出一个例子:
- X = <A, B, C, B, D, A, B>
- Y = <B, D, C, A, B, A>
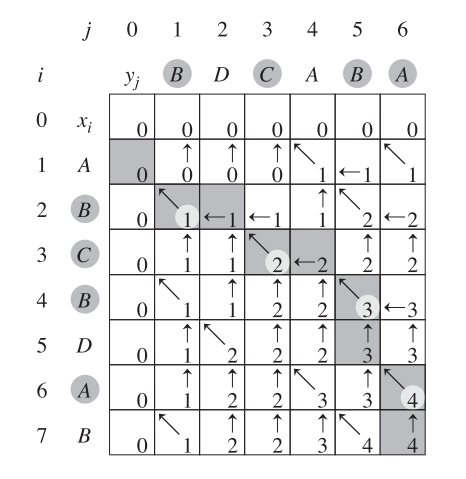
算法复杂度说明
时间复杂度:
- 计算代价的时间:O(mn),每一个单元的填充需要Θ(1)。
- 构造最有解的时间:O(m+n)。
The procedure takes time O(m + n), since it decrements at least one of i and j in each recursive call.
对于代码的改善
Once you have developed an algorithm, you will often find that you can improve on the time or space it uses. Some changes can simplify the code and improve constant factors but otherwise yield no asymptotic improvement in performance. Others can yield substantial asymptotic savings in time and space.
In the LCS algorithm, for example, we can eliminate the b table altogether. Each c[i, j] entry depends on only three other c table entries: c[i-1, j] && c[i, j-1] && c[i-1, j-1]. we can determine in O(1) time which of these three values was used to compute c[i, j] without inspecting table b. Thus, we can reconstruct an LCS in O(m + n) time using a procedure similar to PRINT-LCS. Although we save Θ(mn) space by this method, the auxiliary space requirement for computing an LCS does not asymptotically decrease, since we need Θ(mn) space for the c table anyway. We can, however, reduce the asymptotic space requirements for LCS-LENGTH,
since it needs only two rows of table c at a time: the row being computed and the previous row. This improvement works if we need only the length of an LCS; if we need to reconstruct the elements of an LCS, the smaller table does not keep enough information to retrace our steps in O(m + n) time.
伪代码:2 min(m, n) entries in the c table plus O(1) additional space*
LCS-length_bottomup(X, Y)
m = length(X);
n = length(Y);
let p[0..1][1...min(m,n)] be a new array
for i = 1 to min(m,n) do
p[0,i] = 0
for i = 1 To max(m,n) Do
For j = 1 To min(m,n) Do
If Xi == Yj
Then p[i%2,j] = p[(i-1)%2,j-1]+1;
Else If p[(i-1)%2,j] < C[i%2,j-1]
Then p[i%2,j] = p[(i-1)%2,j];
Else
p[i%2,j] = p[i%2,j-1];
Return p[max(m,n),min(m,n)]
下面是实际代码
#include<stdio.h>
#include<string.h>
#define M 7
#define N 6
void LCS_length_2min(char* x, char* y);
void main() {
char x[M + 1] = { ' ', 'A', 'B', 'C', 'B', 'D', 'A', 'B' };
char y[N + 1] = { ' ','B','D','C','A','B','A' };
LCS_length_2min(x, y);
}
void LCS_length_2min(char* x, char* y) {
// M >= N
int P[2][N + 1];
for (int i = 0; i <= N; i++) {
P[0][i] = 0;
}
P[1][0] = 0;
for (int i = 1; i <= M; i++) {
for (int j = 1; j <= N; j++) {
if (x[i] == y[j]) {
P[i % 2][j] = P[(i - 1) % 2][j - 1] + 1;
}
else if (P[(i - 1) % 2][j] > P[(i) % 2][j - 1]) {
P[i % 2][j] = P[(i - 1) % 2][j];
}
else {
P[i % 2][j] = P[(i) % 2][j - 1];
}
}
}
printf("%d\n", P[M % 2][N]);
}
伪代码: min(m, n) entries in the c table plus O(1) additional space
LCS-length_bottomup(X, Y)
m = length(X);
n = length(Y);
Leftentry = 0;//保存当前计算代价的左上代价
LeftUpentry = 0;//保存当前代价的左代价,其实可以不使用,直接比较p[j-1]和p[j],但是为了保证代码的统一性,即0的情况,故采用一个单独变量
let P[1...min(m,n)] be a new array;
for i = 1 to min(m,n) do
P[i] = 0;
for i = 1 To max(m,n) Do
For j = 1 To min(m,n) Do
If Xi == Yj
Then transition = P[j];
//由于下一次循环需要使用被覆盖的P[j],但又不可以直接赋值到LeftUpentry中,设置过渡变量
P[j] = LeftUpentry + 1;
LeftUpentry = transition;
Leftentry = P[j];
Else If Leftentry < P[j]
Then LeftUpentry = P[j];
Leftentry = P[j];
Else
LeftUpentry = P[j];
P[j] = Leftentry;
Leftentry = P[j];
Leftentry = 0;
LeftUpentry = 0;
Return p[min(m,n)]
下面是实际代码
#include<stdio.h>
#include<string.h>
#define M 7
#define N 6
void LCS_length_min(char* x, char* y);
void main() {
char x[M + 1] = { ' ', 'A', 'B', 'C', 'B', 'D', 'A', 'B' };
char y[N + 1] = { ' ','B','D','C','A','B','A' };
LCS_length_min(x, y);
}
void LCS_length_min(char* x, char* y) {
//M > N
int Leftentry = 0;
int LeftUpentry = 0;
int P[N + 1];
for (int i = 1; i <= N; i++) {
P[i] = 0;
}
for (int i = 1; i <= M; i++) {
for (int j = 1; j <= N; j++) {
if (x[i] == y[j]) {
int trans = P[j];
P[j] = LeftUpentry + 1;
LeftUpentry = trans;
Leftentry = P[j];
}
else if (Leftentry < P[j]) {
Leftentry = P[j];
LeftUpentry = P[j];
}
else {
LeftUpentry = P[j];
P[j] = Leftentry;
Leftentry = P[j];
}
}
//这里为调试信息,可以以原来矩阵的格式打印出来
for (int i = 1; i <= N; i++) {
printf("%d ", P[i]);
}
printf("\n");
Leftentry = 0;
LeftUpentry = 0;
}
printf("%d\n", P[N]);
}
Longest common subsequence(LCS)的更多相关文章
- hdu 1159 Common Subsequence(LCS)
Common Subsequence Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- ZOJ 1733 Common Subsequence(LCS)
Common Subsequence Time Limit: 2 Seconds Memory Limit: 65536 KB A subsequence of a given sequen ...
- poj 1458 Common Subsequence ——(LCS)
虽然以前可能接触过最长公共子序列,但是正规的写应该还是第一次吧. 直接贴代码就好了吧: #include <stdio.h> #include <algorithm> #inc ...
- POJ 1458 Common Subsequence(LCS最长公共子序列)
POJ 1458 Common Subsequence(LCS最长公共子序列)解题报告 题目链接:http://acm.hust.edu.cn/vjudge/contest/view.action?c ...
- UVA 10405 Longest Common Subsequence (dp + LCS)
Problem C: Longest Common Subsequence Sequence 1: Sequence 2: Given two sequences of characters, pri ...
- HDUOJ ---1423 Greatest Common Increasing Subsequence(LCS)
Greatest Common Increasing Subsequence Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536 ...
- HDU 1159:Common Subsequence(LCS模板)
Common Subsequence Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- SPOJ 1811. Longest Common Substring (LCS,两个字符串的最长公共子串, 后缀自动机SAM)
1811. Longest Common Substring Problem code: LCS A string is finite sequence of characters over a no ...
- HDU 1159 Common Subsequence(裸LCS)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1159 Common Subsequence Time Limit: 2000/1000 MS (Jav ...
随机推荐
- Ubuntu中卸载node和npm并重装
1.node 和 npm 卸载不干净 #apt-get 卸载 sudo apt-get remove --purge npm sudo apt-get remove --purge nodejs su ...
- Spring学习(九)--Spring的AOP
1.配置ProxyFactoryBean Spring IOC容器中创建Spring AOP的方法. (1)配置ProxyFactoryBean的Advisor通知器 通知器实现定义了对目标对象进行增 ...
- 【字符串算法】AC自动机
国庆后面两天划水,甚至想接着发出咕咕咕的叫声.咳咳咳,这些都不重要!最近学习了一下AC自动机,发现其实远没有想象中的那么难. AC自动机的来历 我知道,很多人在第一次看到这个东西的时侯是非常兴奋的.( ...
- C\C++中strcat()函数
转载:https://blog.csdn.net/smf0504/article/details/52055971 C\C++中strcat()函数 ...
- 上海hande
HZero UI 一个服务于企业级产品的设计体系,基于『确定』和『自然』的设计价值观和模块化的解决方案,让设计者专注于更好的用户体验. Choerodon UI of React Choerodon ...
- NET Standard中配置TargetFrameworks输出多版本类库
系列目录 [已更新最新开发文章,点击查看详细] 在.NET Standard/.NET Core技术出现之前,编写一个类库项目(暂且称为基础通用类库PA)且需要支持不同 .NET Framew ...
- tuple的增删改查
dict = {"k1": "v1", "k2": "v2", "k3": "v3&quo ...
- Docker笔记2:Docker 镜像仓库
Docker 镜像的官方仓库位于国外服务器上,在国内下载时比较慢,但是可以使用国内镜像市场的加速器(比如阿里云加速器)以提高拉取速度. Docker 官方的镜像市场,可以和 Gitlab 或 GitH ...
- Vue:Vue-Cli 实现的交互式的项目脚手架
一.这份文档是对应 @vue/cli.老版本的 vue-cli 文档请移步https://github.com/vuejs/vue-cli/tree/v2#vue-cli-- Vue CLI 是一个基 ...
- spring redis 配置