Djano之数据库--ORM
一、建立数据库模型类
1.在model里创建模型类。(继承models.Model)
- 1 class Order(models.Model):
- 2 TYPE_CHOICE = (
- 3 (0, u"普通运单"),
- 4 (1, u"绑定关系"),
- 5 (2, u"库房读取")
- 6 )
- 7 mac = models.CharField(max_length=TEXT_LEN, blank=True)
- 8 device = models.ForeignKey(IotDevice, related_name='device_orders', blank=True, null=True)#外键
- 9 operation = models.SmallIntegerField(choices=TYPE_CHOICE, null=True, blank=True)#存贮信息对应的关系
- 10 is_abnormal = models.BooleanField(default=0, verbose_name=u"是否超温")
- 创建模型类
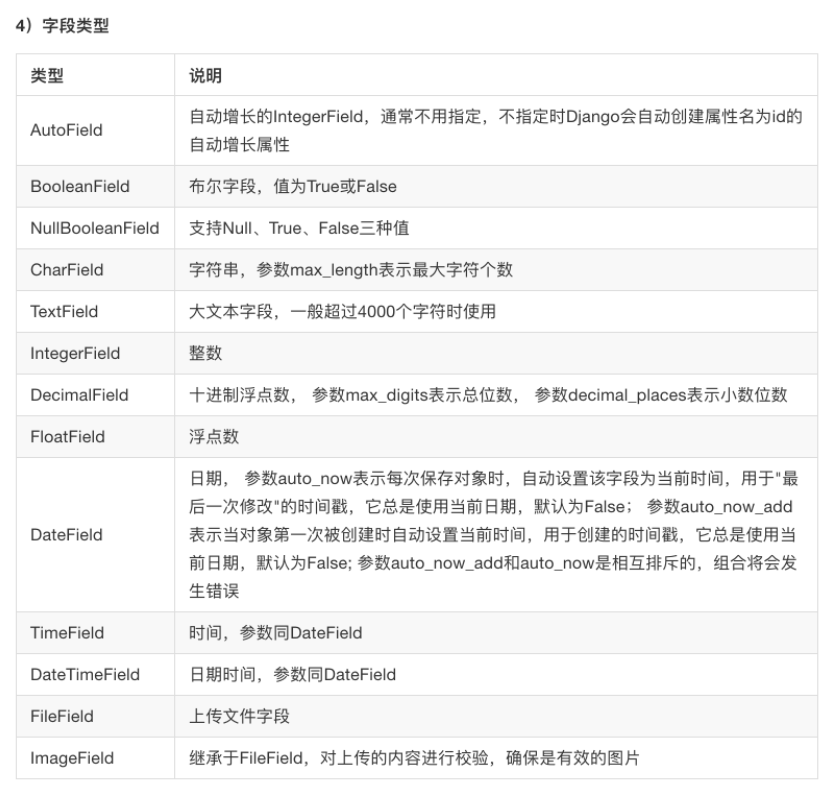
模型里数据可用字段类型

外键设置



二、数据的增加
- 1 book = BookInfo(
- 2 btitle='西游记',
- 3 bput_date=date(1988,1,1),
- 4 bread=10,
- 5 bcomment=10
- 6 )
- 7 book.save()
- 方法一
- 1 HeroInfo.objects.filter(id=14).delete()
五、数据库的查询
1.基本查询:
book = BookInfo.objects.get(btitle='西游记') #单一查询,如果结果不存在报错
book = BookInfo.objects.all(btitle='西游记') #查询多个结果,有多少返回多少,不存在返回None
book = BookInfo.objects.count(btitle='西游记' #查询结果的数量
book = BookInfo.objects.exclude(btitle='西游记') #查询结果取反
2.模糊查询:
a.contains 是否包含
book = BookInfo.objects.filter(btitle__contains='记') #查询结果包含‘记’的
b.startswith,endswith 以指定值开头或结尾
book = BookInfo.objects.filter(btitle__startswith='西') #查询以‘西’开头的
book = BookInfo.objects.filter(btitle__endswith='记') #查询以‘记’结尾的
3.空查询:
isnull 是否为空
book = BookInfo.object.filter(bititle__isnull=Flase) #查询bititle不为空
4.范围查询:
in 在范围内
range 相当于between...and...
book = BookInfo.object.filter(id__in = [1,5,13,24]) #查询id为1或5或13或24
book = BookInfo.object.filter(id__range = [10,20]) #查询范围为10-20的id
5.比较查询:
gt 大于
gte 大于等于
lt 小于
lte 小于等于
exclude 不等于
book = BookInfo.object.filter(id__gt =10) #查询id大于10的
book = BookInfo.object.exclude(id = 10) #查询id不等于的10的
6.日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
book = BookInfo.object.filter(bpub_date__year = 1977) #查询1977年出版的书
book = BookInfo.object.filter(bpub_date__gt =date(1977,1,1)) #查询1977年1月1日以后出版的书
7.F对象和Q对象
比较两个字段对象之间的关系用F对象。(F对象可以进行运算)
book = BookInfio.Object.filter(bread__gte=F('bcomment')) #查询阅读量等于评论量的对象
book = BookInfio.Object.filter(bread__gte=F('bcomment') * 2 )
与逻辑运算符连用使用Q对象。 或( | ) 与( & ) 非( ~ )
book = BookInfo.Object.filter(Q(bread__gte=20) | Q(pk__lt=3)) #查询阅读量为20或者id为3的对象
8.聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg 平均,Count 数量,Max 最大,Min 最小,Sum 求和
book = BookInfo.Object.aggregate(Sum('bread')) #求阅读量的和
9.排序
使用order_by对结果进行排序
book=BookInfo.object.all().order_by('bread') #按阅读量的升序排列
book=BookInfo.object.all().order_by('-bread') #按阅读量的降序排列
10.关联查询
一对多模型
一到多的访问语法:一对应的模型类对象.多对应的模型类名小写_set
b = BookInfo.object.filter(id = 1)
b.heroinfo_set.all() #查询book_id = 1的书里的所有英雄
(一本书里有多个英雄,一个英雄只能存在一本书里。表关系为一对多,英雄表里外键关联书id,英雄表里的存放多个书id。英雄表为多,书表为一。)
多到一的访问语法:多对应的模型类对象.多对应的模型类中的关系类属性名
h = HeroInfo.object.filter(id = 1)
h.hbook #查询英雄id = 1的书是哪本。
方向查询除了可以使用模型类名_set,还有一种是在建立模型类的时候使用related_name来指定变量名。
hbook= model.ForeignKey(HeroInfo,on_delete=model.CACADE,null=Ture,related_name='heros')
b.herose.all()
六、多对多表操作
1、建多对多表
- class Student(models.Model):
- name = models.CharField(max_length=32)
- # 老师类
- class Teacher(models.Model):
- name = models.CharField(max_length=32)
- stu = models.ManyToManyField(to='Student',related_name='teacher') #让django帮助建立多对多关系表
- model.py
2、数据的增删改查
- class ManyToManyTest(APIView):
- def get(self, request):
- # 方法一:在建立manytomany的models里查数据
- # teacherobj = models.Teacher.objects.get(id=2)
- # data = teacherobj.stu.all()
- # data_list = []
- # for i in data:
- # data_dic={
- # "student_name":i.name,
- # "teacher_name":teacherobj.name
- # }
- # data_list.append(data_dic)
- # return Response(data_list)
- # 方法二:在未建立manytomany的models里查数据
- studentobj = models.Student.objects.get(id=2)
- data = studentobj.teacher_set.all()
- data_list = []
- for i in data:
- data_dic = {
- "student_name": studentobj.name,
- "teacher_name": i.name
- }
- data_list.append(data_dic)
- return Response(data_list)
- def post(self, request):
- # 方法一:在建立manytomany的models里添加数据,(一条,一个对象)
- # teacherobj = models.Teacher.objects.filter(id=1).first()
- # studentobj = models.Student.objects.filter(id=2).first()
- # teacherobj.stu.add(studentobj)
- # return Response({
- # "status": 200
- # })
- #方法二:在未建立manytomany的models里添加数据,(一条,一个对象)
- teacherobj = models.Teacher.objects.all()
- studentobj = models.Student.objects.filter(id=2).first()
- studentobj.teacher_set.set(teacherobj)
- return Response({
- "status": 200
- })
- def put(self, request):
- # 方法一:在建立manytomany的models里修改数据,参数只能是可迭代对象
- teacherobj = models.Teacher.objects.filter(id=3).first()
- studentobj = models.Student.objects.filter(id=2)
- teacherobj.stu.set(studentobj)
- return Response({
- "status": 200
- })
- #方法二:在未建立manytomany的models里修改数据,参数只能是可迭代对象
- # teacherobj = models.Teacher.objects.all()
- # studentobj = models.Student.objects.filter(id=2).first()
- # studentobj.teacher_set.set(teacherobj)
- # return Response({
- # "status": 200
- # })
- def delete(self, request):
- # 方法一:在建立manytomany的models里删除数据,(一条,一个对象)
- # teacherobj = models.Teacher.objects.filter(id=1).first()
- # studentobj = models.Student.objects.filter(id=2).first()
- # teacherobj.stu.remove(studentobj)
- # return Response({
- # "status": 200
- # })
- #方法二:在未建立manytomany的models里删除数据,(多条,可迭代对象)
- teacherobj = models.Teacher.objects.all()
- studentobj = models.Student.objects.filter(id=2).first()
- studentobj.teacher_set.remove(*teacherobj)
- return Response({
- "status": 200
- })
- views.py
Djano之数据库--ORM的更多相关文章
- Android 开源项目android-open-project工具库解析之(一) 依赖注入,图片缓存,网络相关,数据库orm工具包,Android公共库
一.依赖注入DI 通过依赖注入降低View.服务.资源简化初始化.事件绑定等反复繁琐工作 AndroidAnnotations(Code Diet) android高速开发框架 项目地址:https: ...
- LitepalNewDemo【开源数据库ORM框架-LitePal2.0.0版本的使用】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 本Demo使用的是LitePal2.0.0版本,对于旧项目如何升级到2.0.0版本,请阅读<赶快使用LitePal 2.0版本 ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
- tornado 06 数据库—ORM—SQLAlchemy——基本内容及操作
tornado 06 数据库—ORM—SQLAlchemy——基本内容及操作 一. ORM #在服务器后台,数据是要储存在数据库的,但是如果项目在开发和部署的时候,是使用的不同的数据库,该怎么办?是不 ...
- tornado 07 数据库—ORM—SQLAlchemy—查询
tornado 07 数据库—ORM—SQLAlchemy—查询 引言 #上节课使用query从数据库查询到了结果,但是query返回的对象是直接可用的吗 #在query.py内输入一下内容 from ...
- django 操作数据库--orm(object relation mapping)---models
思想 django为使用一种新的方式,即:关系对象映射(Object Relational Mapping,简称ORM). PHP:activerecord Java:Hibernate C#:Ent ...
- 数据库ORM框架GreenDao
常用的数据库: 1). Sql Server2). Access3). Oracle4). Sysbase5). MySql6). Informix7). FoxPro8). PostgreSQL9) ...
- Android 学习笔记之AndBase框架学习(五) 数据库ORM..注解,数据库对象映射...
PS:好久没写博客了... 学习内容: 1.DAO介绍,通用DAO的简单调度过程.. 2.数据库映射关系... 3.使用泛型+反射+注解封装通用DAO.. 4.使用AndBase框架实现对DAO的调用 ...
- 基于.NET C#的 sqlite 数据库 ORM 【Easyliter】
因为工作原因经常用到SQLITE数据库,但又找不到好用的ORM所以自个整理了一个简单好用的轻量极ORM框架:Easyliter 功能介绍: 1.支持SQL语句操作 2.支持 List<T> ...
随机推荐
- 手撸Mysql原生语句--多表
在开始之前,我们需要建立表,做建表和数据的准备的工作. 1.建表 create table department( id int, name varchar(20) ); create table e ...
- 2020 巅峰极客 WP_ Re
第一题:virus 是一个win32 的题,没给加壳. 主函数: int __cdecl main(int argc, const char **argv, const char **envp) { ...
- Spark Parquet详解
Spark - Parquet 概述 Apache Parquet属于Hadoop生态圈的一种新型列式存储格式,既然属于Hadoop生态圈,因此也兼容大多圈内计算框架(Hadoop.Spark),另外 ...
- Activiti工作流系统环境搭建
一.创建Activiti工程,并导入Activiti包及数据库驱动包 二.用代码方式创建 流程引擎 1 @Test 2 public void createProcessEngineWithCode( ...
- Centos-转换或复制文件-dd
dd 转换或复制文件,同时可以对设备进行备份 相关选项 if 输入文件,可以是设备 of 输出文件,可以是输出设备 bs 指定一个block大小,默认为 512字节 count 指定bs数量
- 抛弃vue-webpack-template,踩坑Vue-Cli创建vue项目
官方指导网站https://cli.vuejs.org/ 一.全局安装@vue/cli //本人包管理工具使用yarn yarn global add @vue/cli 安装完成 二.创建vue项目 ...
- BUUCTF-[极客大挑战 2019]BabySQL 1 详解
打开靶机 应该是love sql惹的事吧,来了个加强版本的sql注入,不过我们先输入账号密码看有什么反应 整一手万能密码,闭合双引号?username=admin&password=admin ...
- Rust之路(1)
[未经书面许可,严禁转载]-- 2020-10-09 -- 正式开始Rust学习之路了! 思而不学则罔,学而不思则殆.边学边练才能快速上手,让我们先来个Hello World! 但前提是有Rust环境 ...
- if-else和if if的对比
- 使用Spring Boot创建docker image
目录 简介 传统做法和它的缺点 使用Buildpacks Layered Jars 自定义Layer 简介 在很久很久以前,我们是怎么创建Spring Boot的docker image呢?最最通用的 ...