epoll源码解析翻译------说使用了mmap的都是骗子
本文地址
//https://www.cnblogs.com/l2017/p/10830391.html
//https://blog.csdn.net/li_haoren
select poll epoll这三个都是对poll机制的封装。
只是select跟poll傻了点
epoll里并没有找到mmap相关的代码。并没有用到内核态内存映射到用户态的技术。但这个技术是存在的。dpdk,跟netmap(绕过内核的tcp/ip协议栈,在用户态协议栈处理。减少中断,上下文切换等开销)就有用到内核态内存映射到用户态技术
这个图不是我的,不知道从哪偷来的。
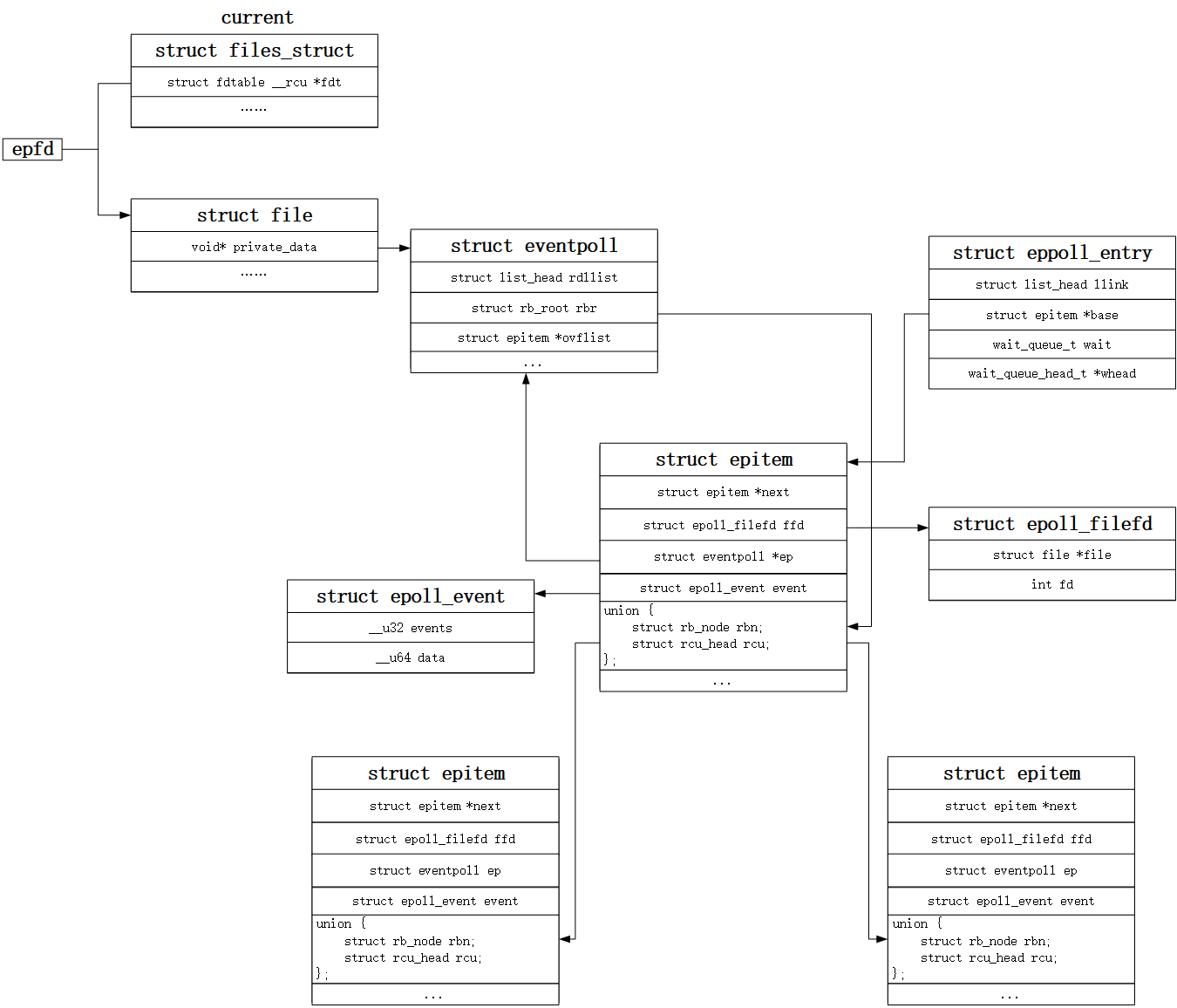
//好像是 linux-5.2
//https://elixir.bootlin.com/linux/v5.2-rc5/source/fs/eventpoll.c
//参考
//https://www.cppfans.org/1418.html
//https://cloud.tencent.com/developer/article/1005481
//http://blog.chinaunix.net/uid-26339466-id-3292595.html
//https://titenwang.github.io/2017/10/05/implementation-of-epoll/
//https://www.jianshu.com/p/aa486512e989
//https://blog.csdn.net/Jammg/article/details/51854436
//https://www.cnblogs.com/lshs/p/6038904.html
//http://blog.lucode.net/linux/epoll-tutorial.html //sys/epoll.h
#ifndef __sigset_t_defined
#define __sigset_t_defined
typedef __sigset_t sigset_t;
#endif /*
错误标志
EINVAL : 无效的标志
EMFILE : 用户打开的文件超过了限制
ENFILE : 系统打开的文件超过了限制
ENOMEM : 没有足够的内存完成当前操作
EBADF : epfd或者fd不是一个有效的文件描述符
EEXIST : op为EPOLL_CTL_ADD,但fd已经被监控
EINVAL : epfd是无效的epoll文件描述符
ENOENT : op为EPOLL_CTL_MOD或者EPOLL_CTL_DEL,并且fd未被监控
ENOMEM : 没有足够的内存完成当前操作
ENOSPC : epoll实例超过了/proc/sys/fs/epoll/max_user_watches中限制的监听数量
EBADF : epfd不是一个有效的文件描述符
EFAULT : events指向的内存无权访问
EINTR : 在请求事件发生或者过期之前,调用被信号打断
EINVAL : epfd是无效的epoll文件描述符
*/
//本文地址 https://www.cnblogs.com/l2017/p/10830391.html
//https://blog.csdn.net/li_haoren
//要传递给epoll_create2的标志,就是那个代替了size的flags
enum
{
EPOLL_CLOEXEC = 02000000,
#define EPOLL_CLOEXEC EPOLL_CLOEXEC
//EPOLL_NONBLOCK 它是fd的一个标识说明,用来设置文件close-on-exec状态的。
//当close-on-exec状态为0时,调用exec时,fd不会被关闭;
//状态非零时则会被关闭,这样做可以防止fd泄露给执行exec后的进程。
EPOLL_NONBLOCK = 04000
#define EPOLL_NONBLOCK EPOLL_NONBLOCK
//创建的epfd会设置为非阻塞
}; enum EPOLL_EVENTS
{
EPOLLIN = 0x001,
//表示关联的fd可以进行读操作了。(包括对端Socket正常关闭)
#define EPOLLIN EPOLLIN
EPOLLPRI = 0x002,
//表示关联的fd有紧急优先事件可以进行读操作了。
#define EPOLLPRI EPOLLPRI
EPOLLOUT = 0x004,
//表示关联的fd可以进行写操作了。
#define EPOLLOUT EPOLLOUT
EPOLLRDNORM = 0x040,
#define EPOLLRDNORM EPOLLRDNORM
EPOLLRDBAND = 0x080,
#define EPOLLRDBAND EPOLLRDBAND
EPOLLWRNORM = 0x100,
#define EPOLLWRNORM EPOLLWRNORM
EPOLLWRBAND = 0x200,
#define EPOLLWRBAND EPOLLWRBAND
EPOLLMSG = 0x400,
#define EPOLLMSG EPOLLMSG
EPOLLERR = 0x008,
//表示关联的fd发生了错误,
//这个事件是默认的 后续代码有 epds.events |= EPOLLERR | EPOLLHUP;
#define EPOLLERR EPOLLERR
EPOLLHUP = 0x010,
//表示关联的fd挂起了,
//这个事件是默认的 后续代码有 epds.events |= EPOLLERR | EPOLLHUP;
#define EPOLLHUP EPOLLHUP
EPOLLRDHUP = 0x2000,
//表示套接字关闭了连接,或者关闭了正写一半的连接。
#define EPOLLRDHUP EPOLLRDHUP
EPOLLONESHOT = (1 << 30),
//设置关联的fd为one-shot的工作方式。
//表示只监听一次事件,如果要再次监听,需要重置这个socket上的EPOLLONESHOT事件。
//使用场合:多线程环境
//如果主线程在epoll_wait返回了套接字conn,之后子线程1在处理conn,主线程回到epoll_wait,
//但还没等到子线程1返回conn又可读了,此时主线程epoll_wait返回,又分配给另一个线程,此时两个线程同时使用一个套接字,这当然是不行的,
//出现了两个线程同时操作一个socket的局面。
//可以使用epoll的EPOLLONESHOT事件实现一个socket连接在任一时刻都被一个线程处理。
//作用:
// 对于注册了EPOLLONESHOT事件的文件描述符,操作系统最多出发其上注册的一个可读,可写或异常事件,且只能触发一次。
//使用:
// 注册了EPOLLONESHOT事件的socket一旦被某个线程处理完毕,
// 该线程就应该立即重置这个socket上的EPOLLONESHOT事件,以确保这个socket下一次可读时,
// (使用该线程的没重置此套接字前即:主线程不允许返回任何关于此套接字的事件,这样就做到同一时刻只可能有一个线程处理该套接字)
// 其EPOLLIN事件能被触发,进而让其他工作线程有机会继续处理这个sockt。
//效果:
// 尽管一个socket在不同事件可能被不同的线程处理,但同一时刻肯定只有一个线程在为它服务,这就保证了连接的完整性,从而避免了很多可能的竞态条件。
//也可以使用add,并忽略epoll_ctl()返回的错误码EEXIST来重置。(??还没试过)
//EPOLLONESHOT优先于水平触发(默认)的处理,即同时设置水平触发和EPOLLONESHOT并不会把epi添加到ready链表。
//如果设置了EPOLLONESHOT标志位,则设置epi->event.events &= EP_PRIVATE_BITS,
//其定义如下#define EP_PRIVATE_BITS (EPOLLWAKEUP | EPOLLONESHOT | EPOLLET),
//后续根据EP_PRIVATE_BITS判断不再加入ep->rdllist或者ep->ovflist。
//注意设置了EPOLLONESHOT触发一次后并没有删除epi,
//因而通过epoll_ctl进行ADD操作后会提示File exists错误。
#define EPOLLONESHOT EPOLLONESHOT
EPOLLET = (1 << 31)
//设置关联的fd为ET的工作方式,epoll的默认工作方式是LT。(LT/ET触发)LT水平触发 ET边缘触发
#define EPOLLET EPOLLET
//LT模式是epoll默认的工作方式
//LT模式状态时,主线程正在epoll_wait等待事件时,请求到了,epoll_wait返回后没有去处理请求(recv),
//那么下次epoll_wait时此请求还是会返回(立刻返回了);
//而ET模式状态下,这次没处理,下次epoll_wait时将不返回(所以我们应该每次一定要处理)
//本质的区别在设置了EPOLLET的fd在wait发送到用户空间之后,会重新挂回到就绪队列中。
//等待下次wait返回(会重新查看每个socket是否真的有数据,并不是挂上去就绪队列了就返回)
//可查找这段代码if (!(epi->event.events & EPOLLET)) 仔细研读 看清楚有个!
}; #define EPOLL_CTL_ADD 1
// 注册目标fd到epfd中,同时关联内部event到fd上
#define EPOLL_CTL_DEL 2
// 从epfd中删除/移除已注册的fd,event可以被忽略,也可以为NULL
#define EPOLL_CTL_MOD 3
// 修改已经注册到fd的监听事件 struct epoll_event
{
uint32_t events;
//指明了用户态应用程序感兴趣的事件类型,比如EPOLLIN和EPOLLOUT等
epoll_data_t data;
} __attribute__((__packed__)); //提供给用户态应用程序使用,一般用于存储事件的上下文,比如在nginx中,该成员用于存放指向ngx_connection_t类型对象的指针
typedef union epoll_data
{
void *ptr;//指定与fd相关的用户数据
int fd; //指定事件所从属的目标文件描述符
uint32_t u32;
uint64_t u64;
} epoll_data_t; extern int epoll_create(int __size) __THROW;
//创建一个epoll实例。 返回新实例的fd。
//__size是历史遗留问题,以前用的是hash,需要给预期大小
//epoll_create()返回的fd应该用close()关闭。
extern int epoll_create1(int __flags) __THROW;
//与epoll_create相同,但带有FLAGS参数。 无用的SIZE参数已被删除。
//例如 EPOLL_CLOEXEC 标志
//epoll_create()返回的fd应该用close()关闭。 extern int epoll_ctl(int __epfd, int __op, int __fd,
struct epoll_event *__event) __THROW;
//epoll实例“epfd”。 成功时返回0,错误时返回-1(“errno”变量将包含特定错误代码)
//“op”参数是上面定义的EPOLL_CTL_ *常量之一。
//“fd”参数是操作的目标。
//“event”参数描述了调用者感兴趣的事件以及任何相关的用户数据。 extern int epoll_wait(int __epfd, struct epoll_event *__events,
int __maxevents, int __timeout);
//等待epoll实例“epfd”上的事件。
//返回值为“events”缓冲区中返回的触发事件数。 如果出错,“errno”变量设置为特定错误代码,则返回-1。
//“events”参数是一个包含触发事件的缓冲区。
//“maxevents”是要返回的最大事件数(通常是“事件”的大小)。
//“timeout”参数指定最长等待时间(以毫秒为单位)(-1 ==无限)。 extern int epoll_pwait(int __epfd, struct epoll_event *__events,
int __maxevents, int __timeout,
__const __sigset_t *__ss);
//与epoll_wait相同,但线程的信号掩码暂时原子替换为作为参数提供的掩码。 //***************************************************************************************************
//分隔符
//fs/eventpoll.c //epoll有三级锁
// 1) epmutex (mutex)
// 2) ep->mtx (mutex)
// 3) ep->wq.lock (spinlock)
//获取顺序是上面的从1到3
//我们需要一个ep->wq.lock(spinlock)自旋锁,因为我们从poll回调内部
//操作对象,这可能是wake_up()触发的,而wake_up()又可能从中断请求上下文中调用。
//所以我们无法在poll回调中sleep,因此我们需要一个自旋锁。必须要非常小心使用的锁,
// 尤其是调用spin_lock_irqsave()的时候, 中断关闭, 不会发生进程调度,
// 被保护的资源其它CPU也无法访问。 这个锁是很强力的, 所以只能锁一些
// 非常轻量级的操作。 //在事件传输循环期间(从内核空间到用户空间),我们可能因为copy_to_user()而终于sleep,
//所以,我们需要一个允许我们sleep的锁。这个锁是mutex(ep->mtx)。它是
//在epoll_ctl(EPOLL_CTL_DEL)期间的事件传输循环期间和eventpoll_release_file()的事件传输循环期间获取。
//eventpoll_release_file是用来清除已经close的fd却还没DEL的(当一个fd被加入到epoll中,然后close(fd),而没有先调用epoll_ctl(EPOLL_CTL_DEL)时) //然后我们还需要一个全局互斥锁来序列化eventpoll_release_file()和ep_free()。
//ep_free在epollfd被close时调用来清理资源
//https://www.cnblogs.com/l2017/
//这个互斥锁是在epoll文件清理路径中由ep_free()获取的,它也可以被eventpoll_release_file()获取,
//将epoll fd插入另一个epoll中也会获得。
//我们这样做是为了让我们遍历epoll树时确保这个插入不会创建epoll文件描述符的闭环,
//这可能导致死锁。我们需要一个全局互斥锁来防止两个fd同时插入(A插到B和B插到A)
//来竞争和构建一个循环,而不需要插入观察它是去。
//当一个epoll fd被添加到另一个epoll fd时,有必要立即获得多个“ep-> mtx”。(最多4层嵌套)
//在这种情况下,我们总是按嵌套顺序获取锁(即在* epoll_ctl(e1,EPOLL_CTL_ADD,e2)之后,e1->mtx将始终在e2->mtx之前获取)。
//由于我们不允许epoll文件描述符的循环,这可以确保互斥锁是有序的。
//为了将这个嵌套传递给lockdep,当走遍epoll文件描述符的树时,我们使用当前的递归深度作为lockdep子键。
//可以删除“ep-> mtx”并使用全局mutex“epmutex”(与“ep-> wq.lock”一起)使其工作,
//但是“ep-> mtx”将使界面更具可扩展性。 需要持有“epmutex”的事件非常罕见,
//而对于正常操作,epoll私有“ep-> mtx”将保证更好的可扩展性。 //介绍RCU
//后面有些变量的命名带有rcu
//RCU(Read - Copy Update),顾名思义就是读 - 拷贝修改,它是基于其原理命名的。
//对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,
//但写者在访问它时首先拷贝一个副本,然后对副本进行修改,
//最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。
//这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
//用于释放内存 //介绍poll机制 //在用户空间应用程序向驱动程序请求数据时,有以下几种方式:
//1、不断查询,条件不满足的情况下就是死循环,非常耗cpu
//2、休眠唤醒的方式,如果条件不满足,应用程序则一直睡眠下去
//3、poll机制,如果条件不满足,休眠指定的时间,休眠时间内条件满足唤醒,条件一直不满足时间到达自动唤醒
//4、异步通知,应用程序注册信号处理函数,驱动程序发信号。类似于QT的信号与槽机制。 //在深入了解epoll的实现之前, 先来了解内核的3个方面.
//https://www.cnblogs.com/watson/p/3543320.html
// 1. 等待队列 waitqueue
// 我们简单解释一下等待队列:
// 队列头(wait_queue_head_t)往往是资源生产者,
// 队列成员(wait_queue_t)往往是资源消费者,
// 当头的资源ready后, 会逐个执行每个成员指定的回调函数,
// 来通知它们资源已经ready了, 等待队列大致就这个意思.
// 2. 内核的poll机制
// 被Poll的fd, 必须在实现上支持内核的Poll技术,
// 比如fd是某个字符设备,或者是个socket, 它必须实现
// file_operations中的poll操作, 给自己分配有一个等待队列头.
// 主动poll fd的某个进程必须分配一个等待队列成员, 添加到
// fd的对待队列里面去, 并指定资源ready时的回调函数.
// 用socket做例子, 它必须有实现一个poll操作, 这个Poll是
// 发起轮询的代码必须主动调用的, 该函数中必须调用poll_wait(),
// poll_wait会将发起者作为等待队列成员加入到socket的等待队列中去.
// 这样socket发生状态变化时可以通过队列头逐个通知所有关心它的进程.
// 这一点必须很清楚的理解, 否则会想不明白epoll是如何
// 得知fd的状态发生变化的.
// 3. epollfd本身也是个fd, 所以它本身也可以被epoll,
// (最多4层嵌套)EP_MAX_NESTS //建议先了解内核的list数据结构以及,不然很多list相关的东西看起来会很奇怪 #define EP_PRIVATE_BITS (EPOLLWAKEUP | EPOLLONESHOT | EPOLLET | EPOLLEXCLUSIVE)
//如果设置了EPOLLONESHOT标志位,则设置epi->event.events &= EP_PRIVATE_BITS,
//后续根据EP_PRIVATE_BITS判断不再加入ep->rdllist或者ep->ovflist。
#define EPOLLINOUT_BITS (EPOLLIN | EPOLLOUT) #define EPOLLEXCLUSIVE_OK_BITS (EPOLLINOUT_BITS | EPOLLERR | EPOLLHUP | \
EPOLLWAKEUP | EPOLLET | EPOLLEXCLUSIVE) #define EP_MAX_NESTS 4//指最多4层epoll嵌套
#define EP_MAX_EVENTS (INT_MAX / sizeof(struct epoll_event))
#define EP_UNACTIVE_PTR ((void *) -1L)
#define EP_ITEM_COST (sizeof(struct epitem) + sizeof(struct eppoll_entry)) //记录file跟fd
struct epoll_filefd {
struct file *file;
int fd;
}; //用于跟踪可能的嵌套调用的结构,用于过深的递归和循环周期,epoll嵌套
struct nested_call_node {
struct list_head llink;
void *cookie;
void *ctx;
}; //此结构用作嵌套调用的收集器,以进行检查最大递归部分和循环周期,epoll嵌套
struct nested_calls {
struct list_head tasks_call_list;
spinlock_t lock;
}; //添加到eventpoll接口的每个文件描述符都有一个链接到“rbr”RB树的epitem结构。
//避免增加此结构的大小,因为服务器上可能有数千个这样的结构,我们不希望存在多个缓存行
//epitem 表示一个被监听的fd
struct epitem {
union {
struct rb_node rbn;
//rb_node, 当使用epoll_ctl()将多个fds加入到某个epollfd时, 内核会用slab分配
//多个epitem与fds对应, 而且它们以红黑树的形式组织起来,
//tree的root保存在eventpoll rbr中.
struct rcu_head rcu;
//用于释放epitem结构,rcu前面有提到
}; struct list_head rdllink;
//对应eventpoll的rdllist
//当epitem对应的fd的存在已经ready的I/O事件,
//则ep_poll_callback回调函数会将该epitem链接到eventpoll中的rdllist循环链表中去, struct epitem *next;
//对应eventpoll的ovflist上
//ovflist是一个临时的就绪单链表。充当单链表的next struct epoll_filefd ffd;
//epitem对应的fd和struct file /* Number of active wait queue attached to poll operations */
int nwait;
//附加到poll轮询中的等待队列(eppoll_entry)个数
//pwqlist里的个数 /* List containing poll wait queues */
struct list_head pwqlist;
//对应eppoll_entry的llink
//双向链表,保存着被监视文件对应的eppoll_entry(等同等待队列),
//按道理应该是一个文件就只有一个等待队列。
//但poll某些文件的时候,需要添加两次等待队列,如/dev/bsg/目录下面的文件。所有不是一个指针而是链表 // 同一个文件上可能会监视多种事件,
// 这些事件可能属于不同的wait_queue中
// (取决于对应文件类型的实现),
// 所以需要使用链表
struct eventpoll *ep;
//当前epitem属于哪个eventpoll struct list_head fllink;
//对应目标file的f_ep_links
//双向链表,用来链接被监视的file。
//被监控的file里有f_ep_link(list头),用来链接所有监视这个文件的epitem(list节点)结构,即把监听该file的epitem串起来
//把一个file加到了两个epoll中(file 的 f_ep_links链表中会有两个epitem的fllink) /* wakeup_source used when EPOLLWAKEUP is set */
struct wakeup_source __rcu* ws;
//?? struct epoll_event event;
//注册的感兴趣的事件,也就是用户空间的epoll_event,这个数据是调用epoll_ctl时从用户态传递过来
}; /*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*
* Access to it is protected by the lock inside wq.
*/
//这个结构存储在file->private_data。是每个epoll fd(epfd)对应的主要数据结构
//eventpoll在epoll_create时创建。
struct eventpoll {
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
struct mutex mtx;
//防止这个结构在使用时被删除
//添加, 修改或者删除监听fd的时候, 以及epoll_wait返回, 向用户空间传递数据时都会持有这个互斥锁,
//所以在用户空间可以放心的在多个线程中同时执行epoll相关的操作, 内核级已经做了保护. wait_queue_head_t wq;
//sys_epoll_wait()使用的等待队列,用于保存有哪些进程在等待这个epoll返回。 /* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
//file->poll()使用的等待队列,这个用于epollfd本身被poll的时候?? struct list_head rdllist;
//对应epitem的rdllist
//用于收集已经就绪了的epitem的对象(有个函数可用于结构内成员变量的地址得到该结构指针,后面会看到)
//链表中的每个结点即为epitem中的rdllink,rdllist中链接的所有rdllink对应的epitem有事件ready struct rb_root_cached rbr;
//用于管理所有epitem(fd)的红黑树(树根)
//查找删除更改都是log(N) struct epitem *ovflist;
//对应epitem的next
//ovflist链表也是用来收集就绪了item对象的,epitem的next就是这个地方用来串成单链表的
//是在对rdllink成员进行扫描操作获取就绪事件返还给用户态时被用来存放扫描期间就绪的事件的。
//因为在对rellist扫描期间需要保证数据的一致性,如果此时又有新的就绪事件发生,那么就需要提供临时的空间来存储 /* wakeup_source used when ep_scan_ready_list is running */
struct wakeup_source *ws;
//?? struct user_struct *user;
//这里保存了一些用户变量, 比如fd监听数量的最大值等等 struct file *file;
//存放对应的file,在create中被创建的那个 /* used to optimize loop detection check */
int visited;
//??
struct list_head visited_list_link;
//??
};
/* Wait structure used by the poll hooks */
//完成一个epitem和ep_poll_callback的关联,同时eppoll_entry会被插入目标文件file的等待头队列中 //在ep_ptable_queue_proc函数中,引入了另外一个非常重要的数据结构eppoll_entry。
//eppoll_entry主要完成epitem和epitem事件发生时的callback(ep_poll_callback)函数之
//间的关联。首先将eppoll_entry的whead指向fd的设备等待队列(waitlist),
//然后初始化eppoll_entry的base变量指向epitem,最后通过add_wait_queue将epo
//ll_entry(wait)挂载到fd的设备等待队列上(waitlist)(把eppoll_entry添加到sk->sk_wq->wait的头部)。
//完成这个动作后,epoll_entry已经被挂载到fd的设备等待队列。
//然后还有一个动作必须完成,就是通过pwq->llink将eppoll_entry挂载到epitem的pwqlist尾部。
struct eppoll_entry {
/* List header used to link this structure to the "struct epitem" */
struct list_head llink;
//对应epitem的pwqlist
//把这个结构跟epitem连接起来,挂载到epitem的pwqlist尾部。
/* The "base" pointer is set to the container "struct epitem" */
struct epitem *base;
//指向epitem
/*
* Wait queue item that will be linked to the target file wait
* queue head.
*/
wait_queue_entry_t wait;
//挂载到fd的设备等待队列上,后面会指定跟ep_poll_callback绑定起来。为唤醒时的回调函数
/* The wait queue head that linked the "wait" wait queue item */
wait_queue_head_t *whead;
//指向fd的设备等待队列头,用于将wait挂载到这个设备等待队列上面。
}; /* Wrapper struct used by poll queueing */
struct ep_pqueue {
poll_table pt;
//??
struct epitem *epi;
}; /*
* Configuration options available inside /proc/sys/fs/epoll/
*/
/* Maximum number of epoll watched descriptors, per user */
static long max_user_watches __read_mostly;
//每个用户的epoll最大监听数
/*
* This mutex is used to serialize ep_free() and eventpoll_release_file().
*/
static DEFINE_MUTEX(epmutex); /* Used to check for epoll file descriptor inclusion loops */
static struct nested_calls poll_loop_ncalls; /* Slab cache used to allocate "struct epitem" */
static struct kmem_cache *epi_cache __read_mostly; /* Slab cache used to allocate "struct eppoll_entry" */
static struct kmem_cache *pwq_cache __read_mostly; /* Visited nodes during ep_loop_check(), so we can unset them when we finish */
static LIST_HEAD(visited_list); /*
* List of files with newly added links, where we may need to limit the number
* of emanating paths. Protected by the epmutex.
*/
static LIST_HEAD(tfile_check_list); static const struct file_operations eventpoll_fops; //判断这个文件是不是epoll文件,利用文件可进行的操作判断
static inline int is_file_epoll(struct file *f)
{
return f->f_op == &eventpoll_fops;
} //设置epitem里的ffd,用做rbtree的键
static inline void ep_set_ffd(struct epoll_filefd *ffd,
struct file *file, int fd)
{
ffd->file = file;
ffd->fd = fd;
} //用于rbtree比较大小
static inline int ep_cmp_ffd(struct epoll_filefd *p1,
struct epoll_filefd *p2)
{
return (p1->file > p2->file ? +1 :
(p1->file < p2->file ? -1 : p1->fd - p2->fd));
} /* Tells us if the item is currently linked */
//监听该fd的就绪链表是否为空
//理解为这个epi是否就绪
static inline int ep_is_linked(struct epitem *epi)
{
return !list_empty(&epi->rdllink);
} //container_of 通过结构体变量中某个成员的首地址进而获得整个结构体变量的首地址。
//container_of(ptr, type, member)
//ptr : 表示结构体中member的地址
//type : 表示结构体类型
//member : 表示结构体中的成员
static inline struct eppoll_entry *ep_pwq_from_wait(wait_queue_entry_t *p)
{
return container_of(p, struct eppoll_entry, wait);
} /* Get the "struct epitem" from a wait queue pointer */
static inline struct epitem *ep_item_from_wait(wait_queue_entry_t *p)
{
return container_of(p, struct eppoll_entry, wait)->base;
} /* Get the "struct epitem" from an epoll queue wrapper */
static inline struct epitem *ep_item_from_epqueue(poll_table *p)
{
return container_of(p, struct ep_pqueue, pt)->epi;
} /* Tells if the epoll_ctl(2) operation needs an event copy from userspace */
//如果是删除事件则不需要event,判断op操作是什么
static inline int ep_op_has_event(int op)
{
return op != EPOLL_CTL_DEL;
} /* Initialize the poll safe wake up structure */
static void ep_nested_calls_init(struct nested_calls *ncalls)
{
INIT_LIST_HEAD(&ncalls->tasks_call_list);
spin_lock_init(&ncalls->lock);
} /**
* ep_events_available - Checks if ready events might be available.
*
* @ep: Pointer to the eventpoll context.
*
* Returns: Returns a value different than zero if ready events are available,
* or zero otherwise.
*/
//检查事件是否就绪
//返回:如果就绪事件可用,则返回不为零的值,否则返回零。
//如果ready链ep->rdllist非空或者ep->ovflist有效,则表示当前有关注的event发生
static inline int ep_events_available(struct eventpoll *ep)
{
return !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR;
} static inline void ep_busy_loop(struct eventpoll *ep, int nonblock)
{
} static inline void ep_reset_busy_poll_napi_id(struct eventpoll *ep)
{
} static inline void ep_set_busy_poll_napi_id(struct epitem *epi)
{
} /**
* ep_call_nested - Perform a bound (possibly) nested call, by checking
* that the recursion limit is not exceeded, and that
* the same nested call (by the meaning of same cookie) is
* no re-entered.
*
* @ncalls: Pointer to the nested_calls structure to be used for this call.
* @max_nests: Maximum number of allowed nesting calls.
* @nproc: Nested call core function pointer.
* @priv: Opaque data to be passed to the @nproc callback.
* @cookie: Cookie to be used to identify this nested call.
* @ctx: This instance context.
*
* Returns: Returns the code returned by the @nproc callback, or -1 if
* the maximum recursion limit has been exceeded.
*/ //(嵌套相关的看不明白想干嘛)
static int ep_call_nested(struct nested_calls *ncalls, int max_nests,
int(*nproc)(void *, void *, int), void *priv,
void *cookie, void *ctx)
{
int error, call_nests = 0;
unsigned long flags;
struct list_head *lsthead = &ncalls->tasks_call_list;
struct nested_call_node *tncur;
struct nested_call_node tnode; spin_lock_irqsave(&ncalls->lock, flags); /*
* Try to see if the current task is already inside this wakeup call.
* We use a list here, since the population inside this set is always
* very much limited.
*/
list_for_each_entry(tncur, lsthead, llink) {
if (tncur->ctx == ctx &&
(tncur->cookie == cookie || ++call_nests > max_nests)) {
/*
* Ops ... loop detected or maximum nest level reached.
* We abort this wake by breaking the cycle itself.
*/
error = -1;
goto out_unlock;
}
} /* Add the current task and cookie to the list */
tnode.ctx = ctx;
tnode.cookie = cookie;
list_add(&tnode.llink, lsthead); spin_unlock_irqrestore(&ncalls->lock, flags); /* Call the nested function */
error = (*nproc)(priv, cookie, call_nests); /* Remove the current task from the list */
spin_lock_irqsave(&ncalls->lock, flags);
list_del(&tnode.llink);
out_unlock:
spin_unlock_irqrestore(&ncalls->lock, flags); return error;
} /*
* As described in commit 0ccf831cb lockdep: annotate epoll
* the use of wait queues used by epoll is done in a very controlled
* manner. Wake ups can nest inside each other, but are never done
* with the same locking. For example:
*
* dfd = socket(...);
* efd1 = epoll_create();
* efd2 = epoll_create();
* epoll_ctl(efd1, EPOLL_CTL_ADD, dfd, ...);
* epoll_ctl(efd2, EPOLL_CTL_ADD, efd1, ...);
*
* When a packet arrives to the device underneath "dfd", the net code will
* issue a wake_up() on its poll wake list. Epoll (efd1) has installed a
* callback wakeup entry on that queue, and the wake_up() performed by the
* "dfd" net code will end up in ep_poll_callback(). At this point epoll
* (efd1) notices that it may have some event ready, so it needs to wake up
* the waiters on its poll wait list (efd2). So it calls ep_poll_safewake()
* that ends up in another wake_up(), after having checked about the
* recursion constraints. That are, no more than EP_MAX_POLLWAKE_NESTS, to
* avoid stack blasting.
*
* When CONFIG_DEBUG_LOCK_ALLOC is enabled, make sure lockdep can handle
* this special case of epoll.
*/ //唤醒等待eventpoll文件就绪的进程
static void ep_poll_safewake(wait_queue_head_t *wq)
{
wake_up_poll(wq, EPOLLIN);
} //把eppoll_entry从等待队列中移除
//解除eppoll_entry跟file的联系。
static void ep_remove_wait_queue(struct eppoll_entry *pwq)
{
wait_queue_head_t *whead;
//rcu前面有介绍到
rcu_read_lock();
/*
* If it is cleared by POLLFREE, it should be rcu-safe.
* If we read NULL we need a barrier paired with
* smp_store_release() in ep_poll_callback(), otherwise
* we rely on whead->lock.
*/
whead = smp_load_acquire(&pwq->whead);
if (whead)
remove_wait_queue(whead, &pwq->wait);
rcu_read_unlock();
} /*
* This function unregisters poll callbacks from the associated file
* descriptor. Must be called with "mtx" held (or "epmutex" if called from
* ep_free).
*/
//移除epitem里所有的eppoll_entry,并释放eppoll_entry内存,回收到slab
static void ep_unregister_pollwait(struct eventpoll *ep, struct epitem *epi)
{
struct list_head *lsthead = &epi->pwqlist;
struct eppoll_entry *pwq; while (!list_empty(lsthead)) {
//用于获取链表中第一个节点所在结构体的首地址
pwq = list_first_entry(lsthead, struct eppoll_entry, llink); list_del(&pwq->llink);
ep_remove_wait_queue(pwq);
kmem_cache_free(pwq_cache, pwq);
}
} //__pm_stay_awake,通知PM core,ws产生了wakeup event,且正在处理,因此不允许系统suspend(stay awake);
//PM 电源管理
//代码中没有这个函数声明的,只是为了容易速览定义。
void __pm_stay_awake(wakeup_source *ws);
/* call only when ep->mtx is held */
static inline struct wakeup_source *ep_wakeup_source(struct epitem *epi)
{
return rcu_dereference_check(epi->ws, lockdep_is_held(&epi->ep->mtx));
} /* call only when ep->mtx is held */
static inline void ep_pm_stay_awake(struct epitem *epi)
{
struct wakeup_source *ws = ep_wakeup_source(epi); if (ws)
__pm_stay_awake(ws);
} static inline bool ep_has_wakeup_source(struct epitem *epi)
{
return rcu_access_pointer(epi->ws) ? true : false;
} /* call when ep->mtx cannot be held (ep_poll_callback) */
static inline void ep_pm_stay_awake_rcu(struct epitem *epi)
{
struct wakeup_source *ws; rcu_read_lock();
ws = rcu_dereference(epi->ws);
if (ws)
__pm_stay_awake(ws);
rcu_read_unlock();
} //释放epitem,将资源放回到slab中
static void epi_rcu_free(struct rcu_head *head)
{
struct epitem *epi = container_of(head, struct epitem, rcu);
kmem_cache_free(epi_cache, epi);
} //释放eventpoll及其拥有的资源
static void ep_free(struct eventpoll *ep)
{
struct rb_node *rbp;
struct epitem *epi; /* We need to release all tasks waiting for these file */
//判断阻塞在eventpoll上的等待进程队列是否为空。
//如果为空的话,等待队列不可用返回0;. 如果不为空,等待队列可用返回1
if (waitqueue_active(&ep->poll_wait))
ep_poll_safewake(&ep->poll_wait); /*
* We need to lock this because we could be hit by
* eventpoll_release_file() while we're freeing the "struct eventpoll".
* We do not need to hold "ep->mtx" here because the epoll file
* is on the way to be removed and no one has references to it
* anymore. The only hit might come from eventpoll_release_file() but
* holding "epmutex" is sufficient here.
*/
mutex_lock(&epmutex); /*
* Walks through the whole tree by unregistering poll callbacks.
*/
//移除监听的fd
for (rbp = rb_first_cached(&ep->rbr); rbp; rbp = rb_next(rbp)) {
epi = rb_entry(rbp, struct epitem, rbn); //移除epitem里所有的eppoll_entry
ep_unregister_pollwait(ep, epi);
//功能是主动放权,等待下一次的调度运行
//https://blog.csdn.net/tiantao2012/article/details/78878092
cond_resched();
} /*
* Walks through the whole tree by freeing each "struct epitem". At this
* point we are sure no poll callbacks will be lingering around, and also by
* holding "epmutex" we can be sure that no file cleanup code will hit
* us during this operation. So we can avoid the lock on "ep->wq.lock".
* We do not need to lock ep->mtx, either, we only do it to prevent
* a lockdep warning.
*/
mutex_lock(&ep->mtx); while ((rbp = rb_first_cached(&ep->rbr)) != NULL) {
epi = rb_entry(rbp, struct epitem, rbn);
//移除eventpoll里所有的epitem
ep_remove(ep, epi);
cond_resched();
}
mutex_unlock(&ep->mtx);
mutex_unlock(&epmutex);
mutex_destroy(&ep->mtx);
free_uid(ep->user); wakeup_source_unregister(ep->ws);
//释放eventpoll
kfree(ep);
}
//close时会调用,关键在ep_free(ep)
static int ep_eventpoll_release(struct inode *inode, struct file *file)
{
struct eventpoll *ep = file->private_data; if (ep)
ep_free(ep); return 0;
} //rdllink就绪链表里是的epitem是否真的有就绪读事件(只要有一个就会返回,且rdllink链表里的第一个是真的可读)
static __poll_t ep_read_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
struct epitem *epi, *tmp;
poll_table pt;
int depth = *(int *)priv;
//pt设置为NULL
init_poll_funcptr(&pt, NULL);
depth++;
//list_for_each_entry_safe(pos, n, head, member),
//它们要求调用者另外提供一个与pos同类型的指针n,
//在for循环中暂存pos下一个节点的地址,避免因pos节点被释放而造成的断链。
//head->rdllink里的链表
list_for_each_entry_safe(epi, tmp, head, rdllink) {
if (ep_item_poll(epi, &pt, depth)) {
return EPOLLIN | EPOLLRDNORM;
}
else {
/*
* Item has been dropped into the ready list by the poll
* callback, but it's not actually ready, as far as
* caller requested events goes. We can remove it here.
*/
//通知PM core,ws没有正在处理的wakeup event,允许系统suspend(relax)
__pm_relax(ep_wakeup_source(epi));
list_del_init(&epi->rdllink);
}
} return 0;
} /*
* Differs from ep_eventpoll_poll() in that internal callers already have
* the ep->mtx so we need to start from depth=1, such that mutex_lock_nested()
* is correctly annotated.
*/
//ep_ptable_queue_proc函数在调用f_op->poll()时会被调用.
//当epoll主动poll某个fd时, 用来将epitem与指定的fd关联起来(将epitem加入到指定文件的wait队列).
//关联的办法就是使用等待队列(waitqueue) //在ep_ptable_queue_proc函数中,引入了另外一个非常重要的数据结构eppoll_entry。ep
//poll_entry主要完成epitem和epitem事件发生时的callback(ep_poll_callback)函数之
//间的关联并挂载到目标文件file的waithead中。首先将eppoll_entry的whead指向目标文件的设备等待队列(waitlist),
//然后初始化eppoll_entry的base变量指向epitem,最后根据EPOLLEXCLUSIVE标识
//如果要求事件发生时只有一个线程被唤醒则调用add_wait_queue_exclusive将epoll_entry挂载到fd的设备等待队列上,
//否则通过add_wait_queue将epoll_entry挂载到fd的设备等待队列上。完成这个动作后,
//epoll_entry已经被挂载到fd的设备等待队列。 //由于ep_ptable_queue_proc函数设置了等待队列的ep_poll_callback回调函数。所以在设
//备硬件数据到来时,硬件中断处理函数中会唤醒该等待队列上等待的进程时,会调用唤
//醒函数ep_poll_callback。
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq; if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) { //初始化等待队列, 指定ep_poll_callback为唤醒时的回调函数,
//当我们监听的fd发生状态改变时, 也就是队列头被唤醒时,
//指定的回调函数将会被调用.(ep_poll_callback)
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
pwq->whead = whead;
pwq->base = epi;
//EPOLLEXCLUSIVE标识会保证一个事件发生时候只有一个线程会被唤醒,以避免多侦听下的“惊群”问题。
//add_wait_queue() 用来将一个进程添加到等待队列
//add_wait_queue_exclusive()将进程插入到队列尾部,同时还设置了 WQ_EXCLUSIVE 标志。
//取值为WQ_FLAG_EXCLUSIVE(=1)表示互斥进程,由内核有选择的唤醒.为0时表示非互斥进程,由内核在
//事件发生时唤醒所有等待进程.
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
//nwait记录了当前epitem加入到了多少个等待队列中
//epitem有可能加入到多个等待队列中。一个file不止一个等待队列。不同事件可能有不同等待队列
epi->nwait++;
}
else {
//如果分配内存失败,则将nwait置为-1,表示发生错误,即内存分配失败,或者已发生错误
epi->nwait = -1;
}
} /*
* This is the callback that is passed to the wait queue wakeup
* mechanism. It is called by the stored file descriptors when they
* have events to report.
*/
//这个是关键性的回调函数, 当我们监听的fd发生状态改变时, 它会被调用,
//参数key被当作一个unsigned long整数使用, 携带的是events.
//主要的功能是将被监视文件的event就绪时,将文件对应的epitem添加到rdlist中并唤醒调用epoll_wait进程。 //前面提到eppoll_entry完成一个epitem和ep_poll_callback的关联,同时eppoll_entry会被插入目标文件file的(private_data)waithead中。
//以scoket为例,当socket数据ready,终端会调用相应的接口函数比如rawv6_rcv_skb,
//此函数会调用sock_def_readable然后,通过sk_has_sleeper判断sk_sleep上是否有等待的进程,
//如果有那么通过wake_up_interruptible_sync_poll函数调用ep_poll_callback。 //文件fd状态改变(buffer由不可读变为可读或由不可写变为可写),导致相应fd上的回调函数ep_poll_callback()被调用。
//ep_poll_callback函数首先会判断是否rdlist正在被使用(通过ovflist是否等于EP_UNACTIVE_PTR),
//如果是那么将epitem插入ovflist。如果不是那么将epitem插入rdlist。
//然后调用wake_up函数唤醒epitem上wq的进程。这样就可以返回到epoll_wait的调用者,将他唤醒。
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
////从等待队列获取epitem。需要知道哪个进程挂载到这个设备
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
//pollflags返回的事件,但并非每个设备都在pollflags中报告事件发生
//pollflags为0也可能发生了事件
__poll_t pollflags = key_to_poll(key);
int ewake = 0; spin_lock_irqsave(&ep->wq.lock, flags); ep_set_busy_poll_napi_id(epi); /*
* If the event mask does not contain any poll(2) event, we consider the
* descriptor to be disabled. This condition is likely the effect of the
* EPOLLONESHOT bit that disables the descriptor when an event is received,
* until the next EPOLL_CTL_MOD will be issued.
*/
//如果事件掩码不包含任何poll(2)事件,我们认为该描述符被禁用。
//这种情况很可能是EPOLLONESHOT位在收到事件时禁用描述符的效果,
//直到发出下一个EPOLL_CTL_MOD解除。
//EPOLLONESHOT标志位
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock; /*
* Check the events coming with the callback. At this stage, not
* every device reports the events in the "key" parameter of the
* callback. We need to be able to handle both cases here, hence the
* test for "key" != NULL before the event match test.
*/
//检查回调附带的事件。 在此阶段,并非每个设备都在回调的“key”参数中报告事件。
//我们需要能够在这里处理这两种情况,因此在事件匹配测试之前测试“key”!= NULL。 //如果pollflags不为0且pollflags没有我们想要的事件,那就肯定没有我们想要的事件。
if (pollflags && !(pollflags & epi->event.events))
goto out_unlock; /*
* If we are transferring events to userspace, we can hold no locks
* (because we're accessing user memory, and because of linux f_op->poll()
* semantics). All the events that happen during that period of time are
* chained in ep->ovflist and requeued later on.
*/ //如果ep->ovflist != EP_UNACTIVE_PTR说明此时正在扫描rdllist链表,
//这个时候会将就绪事件对应的epitem对象加入到ovflist链表暂存起来,
//等rdllist链表扫描完之后在将ovflist链表中的内容移动到rdllist链表中
//在下一次epoll_wait时返回给用户.
//新事件触发的epi插入到ep->ovflist的头部
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
if (epi->ws) {
/*
* Activate ep->ws since epi->ws may get
* deactivated at any time.
*/
__pm_stay_awake(ep->ws);
}
}
goto out_unlock;
} /* If this file is already in the ready list we exit soon */
if (!ep_is_linked(epi)) {
//将该epitem加入到epoll的rdllist就绪链表中
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake_rcu(epi);
} /*
* Wake up ( if active ) both the eventpoll wait list and the ->poll()
* wait list.
*/
//如果等待进程队列不为空的话,唤醒在该epoll上的等待进程
if (waitqueue_active(&ep->wq)) {
if ((epi->event.events & EPOLLEXCLUSIVE) &&
!(pollflags & POLLFREE)) {
switch (pollflags & EPOLLINOUT_BITS) {
case EPOLLIN:
if (epi->event.events & EPOLLIN)
ewake = 1;
break;
case EPOLLOUT:
if (epi->event.events & EPOLLOUT)
ewake = 1;
break;
case 0:
ewake = 1;
break;
}
}
wake_up_locked(&ep->wq);
}
//如果该epoll也被poll(即其他epoll添加了该epoll fd,嵌套epoll), 那就唤醒poll在该epoll上的等待epoll队列
if (waitqueue_active(&ep->poll_wait))
pwake++; out_unlock:
spin_unlock_irqrestore(&ep->wq.lock, flags); /* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait); if (!(epi->event.events & EPOLLEXCLUSIVE))
ewake = 1; if (pollflags & POLLFREE) {
/*
* If we race with ep_remove_wait_queue() it can miss
* ->whead = NULL and do another remove_wait_queue() after
* us, so we can't use __remove_wait_queue().
*/
list_del_init(&wait->entry);
/*
* ->whead != NULL protects us from the race with ep_free()
* or ep_remove(), ep_remove_wait_queue() takes whead->lock
* held by the caller. Once we nullify it, nothing protects
* ep/epi or even wait.
*/
smp_store_release(&ep_pwq_from_wait(wait)->whead, NULL);
} return ewake;
} //通过ep_item_poll把epitem添加到poll钩子中,并获取当前revents。 //ep_item_poll()在epoll_ctl()和epoll_wait()的处理流程中都会调用
//两个流程中的区别在于epoll_ctl(ADD)(具体的就是ep_insert()函数)处理流程中调用ep_item_poll()函数的时候会设置poll_table的_qproc成员为ep_ptable_queue_proc();
//而epoll_ctl(MOD)和epoll_wait()处理流程中则设置为NULL,
//所以epoll_ctl(MOD)和epoll_wait()只会获取就绪事件的掩码。
//而ep_insert()会将epitem对象对应的eppoll_entry对象加入到被监控的目标文件的等待队列中,
//并设置感兴趣事件发生后的回调函数为ep_poll_callback()。 //目标文件的poll回调函数调用完poll_wait()之后会获取对应的就绪事件掩码。
//如果pt的回调函数成员_qproc没有设置,那么目标文件的poll回调函数一般就只会返回对应的就绪事件掩码。
//如果设置了就会执行相应的函数。
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,
int depth)
{
struct eventpoll *ep;
bool locked;
//将pt的_key成员设置为用户态应用程序感兴趣的事件类型,
pt->_key = epi->event.events;
if (!is_file_epoll(epi->ffd.file))
//调用被监控的目标文件的poll回调函数。
//被监控的目标文件的poll回调函数一般会调用poll_wait()函数,
//而poll_wait()又会调用pt的_qproc()回调函数,
return vfs_poll(epi->ffd.file, pt) & epi->event.events; ep = epi->ffd.file->private_data;
poll_wait(epi->ffd.file, &ep->poll_wait, pt);
locked = pt && (pt->_qproc == ep_ptable_queue_proc); return ep_scan_ready_list(epi->ffd.file->private_data,
ep_read_events_proc, &depth, depth,
locked) & epi->event.events;
} //epoll文件的 poll机制
static __poll_t ep_eventpoll_poll(struct file *file, poll_table *wait)
{
struct eventpoll *ep = file->private_data;
int depth = 0; /* Insert inside our poll wait queue */
poll_wait(file, &ep->poll_wait, wait); /*
* Proceed to find out if wanted events are really available inside
* the ready list.
*/
return ep_scan_ready_list(ep, ep_read_events_proc,
&depth, depth, false);
} /* File callbacks that implement the eventpoll file behaviour */
//epoll文件支持的操作 主要是poll
static const struct file_operations eventpoll_fops = {
#ifdef CONFIG_PROC_FS
.show_fdinfo = ep_show_fdinfo,
#endif
.release = ep_eventpoll_release,
.poll = ep_eventpoll_poll,
.llseek = noop_llseek,
}; /*
* This is called from eventpoll_release() to unlink files from the eventpoll
* interface. We need to have this facility to cleanup correctly files that are
* closed without being removed from the eventpoll interface.
*/
//处理那些已经close的监听fd却没从rbt删掉的epitem
void eventpoll_release_file(struct file *file)
{
struct eventpoll *ep;
struct epitem *epi, *next; /*
* We don't want to get "file->f_lock" because it is not
* necessary. It is not necessary because we're in the "struct file"
* cleanup path, and this means that no one is using this file anymore.
* So, for example, epoll_ctl() cannot hit here since if we reach this
* point, the file counter already went to zero and fget() would fail.
* The only hit might come from ep_free() but by holding the mutex
* will correctly serialize the operation. We do need to acquire
* "ep->mtx" after "epmutex" because ep_remove() requires it when called
* from anywhere but ep_free().
*
* Besides, ep_remove() acquires the lock, so we can't hold it here.
*/
mutex_lock(&epmutex);
//file->f_ep_links能得到监听该file的epitem
list_for_each_entry_safe(epi, next, &file->f_ep_links, fllink) {
ep = epi->ep;
mutex_lock_nested(&ep->mtx, 0);
ep_remove(ep, epi);
mutex_unlock(&ep->mtx);
}
mutex_unlock(&epmutex);
}
//分配一个eventpoll结构
static int ep_alloc(struct eventpoll **pep)
{
int error;
struct user_struct *user;
struct eventpoll *ep;
//获取当前进程的一些信息, 比如是不是root啦, 最大监听fd数目啦
user = get_current_user();
error = -ENOMEM;
ep = kzalloc(sizeof(*ep), GFP_KERNEL);
if (unlikely(!ep))
goto free_uid;
//这些都是初始化啦
mutex_init(&ep->mtx);
//初始化进程的等待队列
init_waitqueue_head(&ep->wq);
//初始化自身的等待队列
init_waitqueue_head(&ep->poll_wait);
//初始化就绪链表
INIT_LIST_HEAD(&ep->rdllist);
ep->rbr = RB_ROOT_CACHED;
ep->ovflist = EP_UNACTIVE_PTR;
ep->user = user;
*pep = ep;
return 0;
free_uid:
free_uid(user);
return error;
} /*
* Search the file inside the eventpoll tree. The RB tree operations
* are protected by the "mtx" mutex, and ep_find() must be called with
* "mtx" held.
*/
//通过比较ffd查找出eventpoll中的rbt是否包含这个监听fd
static struct epitem *ep_find(struct eventpoll *ep, struct file *file, int fd)
{
int kcmp;
struct rb_node *rbp;
struct epitem *epi, *epir = NULL;
struct epoll_filefd ffd; ep_set_ffd(&ffd, file, fd);
for (rbp = ep->rbr.rb_root.rb_node; rbp; ) {
epi = rb_entry(rbp, struct epitem, rbn);
kcmp = ep_cmp_ffd(&ffd, &epi->ffd);
if (kcmp > 0)
rbp = rbp->rb_right;
else if (kcmp < 0)
rbp = rbp->rb_left;
else {
epir = epi;
break;
}
}
return epir;
} /*
* This is the callback that is used to add our wait queue to the
* target file wakeup lists.
*/ static void ep_rbtree_insert(struct eventpoll *ep, struct epitem *epi)
{
int kcmp;
struct rb_node **p = &ep->rbr.rb_root.rb_node, *parent = NULL;
struct epitem *epic;
bool leftmost = true; while (*p) {
parent = *p;
epic = rb_entry(parent, struct epitem, rbn);
kcmp = ep_cmp_ffd(&epi->ffd, &epic->ffd);
if (kcmp > 0) {
p = &parent->rb_right;
leftmost = false;
}
else
p = &parent->rb_left;
}
rb_link_node(&epi->rbn, parent, p);
rb_insert_color_cached(&epi->rbn, &ep->rbr, leftmost);
} #define PATH_ARR_SIZE 5
/*
* These are the number paths of length 1 to 5, that we are allowing to emanate
* from a single file of interest. For example, we allow 1000 paths of length
* 1, to emanate from each file of interest. This essentially represents the
* potential wakeup paths, which need to be limited in order to avoid massive
* uncontrolled wakeup storms. The common use case should be a single ep which
* is connected to n file sources. In this case each file source has 1 path
* of length 1. Thus, the numbers below should be more than sufficient. These
* path limits are enforced during an EPOLL_CTL_ADD operation, since a modify
* and delete can't add additional paths. Protected by the epmutex.
*/
static const int path_limits[PATH_ARR_SIZE] = { 1000, 500, 100, 50, 10 };
static int path_count[PATH_ARR_SIZE]; static int path_count_inc(int nests)
{
/* Allow an arbitrary number of depth 1 paths */
if (nests == 0)
return 0; if (++path_count[nests] > path_limits[nests])
return -1;
return 0;
} static void path_count_init(void)
{
int i; for (i = 0; i < PATH_ARR_SIZE; i++)
path_count[i] = 0;
}
//嵌套相关的吧
static int reverse_path_check_proc(void *priv, void *cookie, int call_nests)
{
int error = 0;
struct file *file = priv;
struct file *child_file;
struct epitem *epi; /* CTL_DEL can remove links here, but that can't increase our count */
rcu_read_lock();
//list_for_each_entry的作用就是循环遍历每一个pos中的member子项。
list_for_each_entry_rcu(epi, &file->f_ep_links, fllink)
{
child_file = epi->ep->file;
if (is_file_epoll(child_file)) {
if (list_empty(&child_file->f_ep_links)) {
if (path_count_inc(call_nests)) {
error = -1;
break;
}
}
else {
error = ep_call_nested(&poll_loop_ncalls,
EP_MAX_NESTS,
reverse_path_check_proc,
child_file, child_file,
current);
}
if (error != 0)
break;
}
else {
printk(KERN_ERR "reverse_path_check_proc: "
"file is not an ep!\n");
}
}
rcu_read_unlock();
return error;
} /**
* reverse_path_check - The tfile_check_list is list of file *, which have
* links that are proposed to be newly added. We need to
* make sure that those added links don't add too many
* paths such that we will spend all our time waking up
* eventpoll objects.
*
* Returns: Returns zero if the proposed links don't create too many paths,
* -1 otherwise.
*/
/*reverse_path_check:
好像是嵌套相关的
对于第一层反向检查不限制数目。
对于第2-5层,限制引用数目分别为500、100、50、10,如下变量定义了上限,
其中该变量第一个成员1000仅作占位使用,
并不限制第一层引用总数,
参考path_count_inc。
static const int path_limits[PATH_ARR_SIZE] = { 1000, 500, 100, 50, 10 };
对于5层以上则直接返回错误*/
static int reverse_path_check(void)
{
int error = 0;
struct file *current_file; /* let's call this for all tfiles */
list_for_each_entry(current_file, &tfile_check_list, f_tfile_llink) {
path_count_init();
error = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,
reverse_path_check_proc, current_file,
current_file, current);
if (error)
break;
}
return error;
} static int ep_create_wakeup_source(struct epitem *epi)
{
const char *name;
struct wakeup_source *ws; if (!epi->ep->ws) {
epi->ep->ws = wakeup_source_register("eventpoll");
if (!epi->ep->ws)
return -ENOMEM;
} name = epi->ffd.file->f_path.dentry->d_name.name;
ws = wakeup_source_register(name); if (!ws)
return -ENOMEM;
rcu_assign_pointer(epi->ws, ws); return 0;
} /* rare code path, only used when EPOLL_CTL_MOD removes a wakeup source */
static noinline void ep_destroy_wakeup_source(struct epitem *epi)
{
struct wakeup_source *ws = ep_wakeup_source(epi); RCU_INIT_POINTER(epi->ws, NULL); /*
* wait for ep_pm_stay_awake_rcu to finish, synchronize_rcu is
* used internally by wakeup_source_remove, too (called by
* wakeup_source_unregister), so we cannot use call_rcu
*/
synchronize_rcu();
wakeup_source_unregister(ws);
} /*
* Must be called with "mtx" held.
*/
****************************************************************************** /* Used by the ep_send_events() function as callback private data */
struct ep_send_events_data {
int maxevents;
struct epoll_event __user *events;
int res;
}; //ep_send_events()函数将用户传入的内存简单封装到ep_send_events_data结构中,然后调
//用ep_scan_ready_list()将就绪队列中的事件传入用户空间的内存。用户空间访问这个结
//果,进行处理。
static int ep_send_events(struct eventpoll *ep,
struct epoll_event __user *events, int maxevents)
{
struct ep_send_events_data esed; esed.maxevents = maxevents;
esed.events = events;
//调用ep_scan_ready_list()函数处理epoll对象eventpoll中的rdllist链表。
ep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false);
return esed.res;
} /**
* ep_scan_ready_list - Scans the ready list in a way that makes possible for
* the scan code, to call f_op->poll(). Also allows for
* O(NumReady) performance.
*
* @ep: Pointer to the epoll private data structure.
* @sproc: Pointer to the scan callback.
* @priv: Private opaque data passed to the @sproc callback.
* @depth: The current depth of recursive f_op->poll calls.
* @ep_locked: caller already holds ep->mtx
*
* Returns: The same integer error code returned by the @sproc callback.
*/
//处理就绪链表
//epoll_wait的时候传递函数指针ep_send_events_proc给ep_scan_ready_list,epfd进行poll的时候则传递函数指针ep_read_events_proc??
static __poll_t ep_scan_ready_list(struct eventpoll *ep,
__poll_t(*sproc)(struct eventpoll *,
struct list_head *, void *),
void *priv, int depth, bool ep_locked)
{
__poll_t res;
int pwake = 0;
struct epitem *epi, *nepi;
//LIST_HEAD() -- 生成一个名为txlist的双向链表头节点
LIST_HEAD(txlist); lockdep_assert_irqs_enabled(); /*
* We need to lock this because we could be hit by
* eventpoll_release_file() and epoll_ctl().
*/ if (!ep_locked)
mutex_lock_nested(&ep->mtx, depth); /*
* Steal the ready list, and re-init the original one to the
* empty list. Also, set ep->ovflist to NULL so that events
* happening while looping w/out locks, are not lost. We cannot
* have the poll callback to queue directly on ep->rdllist,
* because we want the "sproc" callback to be able to do it
* in a lockless way.
*/ spin_lock_irq(&ep->wq.lock); //所有监听到events的epitem都已经链到rdllist上了,
//获得rdllist列表,把rdllist上所有的epitem都拷贝到了txlist上,并将rdllist列表重新初始化为空列表。
//此外,将ep-> ovflist设置为NULL,以便在循环w/out锁定时发生的事件不会丢失。
//我们不能让poll回调直接在ep-> rdllist上排队,因
//为我们希望“sproc”回调能够以无锁方式进行。
list_splice_init(&ep->rdllist, &txlist);
ep->ovflist = NULL;
spin_unlock_irq(&ep->wq.lock); /*
* Now call the callback function.
*/
//在这个回调函数里面处理每个epitem *sproc 就是 ep_send_events_proc或者ep_read_events_proc res = (*sproc)(ep, &txlist, priv);
spin_lock_irq(&ep->wq.lock);
/*
* During the time we spent inside the "sproc" callback, some
* other events might have been queued by the poll callback.
* We re-insert them inside the main ready-list here.
*/ //由于在我们扫描处理eventpoll中的rdllist链表的时候可能同时会有就绪事件发生,
//这个时候为了保证数据的一致性,在这个时间段内发生的就绪事件会临时存放在eventpoll对象的ovflist链表成员中,
//待rdllist处理完毕之后,再将ovflist中的内容移动到rdllist链表中,等待下次epoll_wait()的调用。
for (nepi = ep->ovflist; (epi = nepi) != NULL;
nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {
/*
* We need to check if the item is already in the list.
* During the "sproc" callback execution time, items are
* queued into ->ovflist but the "txlist" might already
* contain them, and the list_splice() below takes care of them.
*/ //检测ovflist中的epitem是否真的就绪,如果就绪则将该epitem加到epoll的rdllist链表中
if (!ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
/*
* We need to set back ep->ovflist to EP_UNACTIVE_PTR, so that after
* releasing the lock, events will be queued in the normal way inside
* ep->rdllist.
*/
//ovflist处理完毕,置为EP_UNACTIVE_PTR
ep->ovflist = EP_UNACTIVE_PTR; /*
* Quickly re-inject items left on "txlist".
*/ //上一次没有处理完的epitem, 重新插入到ready list,可能是因为用户空间只取了一部分走
list_splice(&txlist, &ep->rdllist);
__pm_relax(ep->ws); //如果rdllist链表非空,尝试唤醒ep->wq和ep->poll_wait等待队列
if (!list_empty(&ep->rdllist)) {
/*
* Wake up (if active) both the eventpoll wait list and
* the ->poll() wait list (delayed after we release the lock).
*/
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irq(&ep->wq.lock); if (!ep_locked)
mutex_unlock(&ep->mtx); /* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait); return res;
} //当ep_scan_ready_list()函数获取到rdllist链表中的内容之后,
//如果是ep_send_events_proc作为函数指针则会调用ep_send_events_proc()进行扫描处理,
//即遍历txlist链表中的epitem对象,
//针对每一个epitem对象调用ep_item_poll()函数去获取就绪事件的掩码,此时对poll的调用仅仅是取得fd上较新的events(防止之前events被更新),
//如果掩码不为0,说明该epitem对象对应的事件发生了,那么就将其对应的struct epoll_event类型的对象拷贝到用户态指定的内存中(封装在struct epoll_event,从epoll_wait返回)。
//如果掩码为0,则直接处理下一个epitem。
//注意此时在调用ep_item_poll()函数的时候没有设置poll_table的_qproc回调函数成员,所以只会尝试去获取就绪事件的掩码,
//通过ep_item_poll获取revents,相比ep_insert差异在于并不会调用ep_ptable_queue_proc重新注册
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,
void *priv)
{
struct ep_send_events_data *esed = priv;
__poll_t revents;
struct epitem *epi;
struct epoll_event __user *uevent;
struct wakeup_source *ws;
poll_table pt; init_poll_funcptr(&pt, NULL); /*
* We can loop without lock because we are passed a task private list.
* Items cannot vanish during the loop because ep_scan_ready_list() is
* holding "mtx" during this call.
*/
//这里会循环遍历就绪事件对应的item对象组成的链表,依次将链表中item对象
//对应的就绪事件拷贝到用户态,最多拷贝用户态程序指定的就绪事件数目。
for (esed->res = 0, uevent = esed->events;
!list_empty(head) && esed->res < esed->maxevents;) {
//取出第一个成员
epi = list_first_entry(head, struct epitem, rdllink); /*
* Activate ep->ws before deactivating epi->ws to prevent
* triggering auto-suspend here (in case we reactive epi->ws
* below).
*
* This could be rearranged to delay the deactivation of epi->ws
* instead, but then epi->ws would temporarily be out of sync
* with ep_is_linked().
*/
ws = ep_wakeup_source(epi);
if (ws) {
if (ws->active)
__pm_stay_awake(ep->ws);
__pm_relax(ws);
}
//然后从链表里面移除
//list_del_init(entry) 的作用是从双链表中删除entry节点,并将entry节点的前继节点和后继节点都指向entry本身。
list_del_init(&epi->rdllink); //读取events,
//注意events我们ep_poll_callback()里面已经取过一次了, 为啥还要再取?
//1. 我们当然希望能拿到此刻的最新数据, events是会变的~
//2. 不是所有的poll实现, 都通过等待队列传递了events, 有可能某些驱动压根没传必须主动去读取. //虽然这里也会调用ep_item_poll(),但是pt->_qproc这个回调函数并没有设置,
//这种情况下文件对象的poll回调函数就只会去获取就绪事件对应的掩码值,
//因为当pt->_qproc会空时,poll回调函数中调用的poll_wait()什么事情都不做
//就返回,所以poll回调函数就只会去获取事件掩码值。
//通过ep_item_poll获取revents,相比ep_insert差异在于并不会调用ep_ptable_queue_proc重新注册
revents = ep_item_poll(epi, &pt, 1); /*
* If the event mask intersect the caller-requested one,
* deliver the event to userspace. Again, ep_scan_ready_list()
* is holding "mtx", so no operations coming from userspace
* can change the item.
*/
//如果revents不为0,说明确实有就绪事件发生,那么就将就绪事件拷贝到用户态内存中
if (revents) {
//将当前的事件和用户传入的数据都copy给用户空间,
//就是epoll_wait()后应用程序能读到的那一堆数据.
if (__put_user(revents, &uevent->events) ||
__put_user(epi->event.data, &uevent->data)) {
//复制失败则把epi重新插入到ready链表
list_add(&epi->rdllink, head);
ep_pm_stay_awake(epi);
if (!esed->res)
esed->res = -EFAULT;
return 0;
}
esed->res++;
uevent++;
//如果设置了EPOLLONESHOT标志位,则设置epi->event.events &= EP_PRIVATE_BITS,
//后续根据EP_PRIVATE_BITS判断不再加入ep->rdllist或者ep->ovflist。
//注意设置了EPOLLONESHOT触发一次后并没有删除epi,因而通过epoll_ctl进行ADD操作后会提示File exists错误。
if (epi->event.events & EPOLLONESHOT)
epi->event.events &= EP_PRIVATE_BITS; //这个地方就是epoll中特有的EPOLLET边缘触发逻辑的实现,即当一个
//就绪事件拷贝到用户态内存后判断这个事件类型是否包含了EPOLLET位,
//如果没有,则将该事件对应的epitem对象重新加入到epoll的rdllist链
//表中,用户态程序下次调用epoll_wait()返回时就又能获取该epitem了
//下一次epoll_wait时, 会立即返回, 并通知给用户空间.当然如果这个被监听的fds确实没事件也没数据了, epoll_wait会返回一个0,空转一次.
else if (!(epi->event.events & EPOLLET)) { /*
* If this file has been added with Level
* Trigger mode, we need to insert back inside
* the ready list, so that the next call to
* epoll_wait() will check again the events
* availability. At this point, no one can insert
* into ep->rdllist besides us. The epoll_ctl()
* callers are locked out by
* ep_scan_ready_list() holding "mtx" and the
* poll callback will queue them in ep->ovflist.
*/
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
}
}
} return 0;
} static inline struct timespec64 ep_set_mstimeout(long ms)
{
struct timespec64 now, ts = {
.tv_sec = ms / MSEC_PER_SEC,
.tv_nsec = NSEC_PER_MSEC * (ms % MSEC_PER_SEC),
}; ktime_get_ts64(&now);
return timespec64_add_safe(now, ts);
} /**
* ep_poll - Retrieves ready events, and delivers them to the caller supplied
* event buffer.
*
* @ep: Pointer to the eventpoll context.
* @events: Pointer to the userspace buffer where the ready events should be
* stored.
* @maxevents: Size (in terms of number of events) of the caller event buffer.
* @timeout: Maximum timeout for the ready events fetch operation, in
* milliseconds. If the @timeout is zero, the function will not block,
* while if the @timeout is less than zero, the function will block
* until at least one event has been retrieved (or an error
* occurred).
*
* Returns: Returns the number of ready events which have been fetched, or an
* error code, in case of error.
*/ //如果epoll_wait入参定时时间为0, 那么直接通过ep_events_available判断当前是否有用户感兴趣的事件发生,如果有则通过ep_send_events进行处理
//如果定时时间大于0,并且当前没有用户关注的事件发生,则进行休眠,并添加到ep->wq等待队列的头部。 对等待事件描述符设置WQ_FLAG_EXCLUSIVE标志
//ep_poll被事件唤醒后会重新检查是否有关注事件,如果对应的事件已经被抢走,那么ep_poll会继续休眠等待。
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res = 0, eavail, timed_out = 0;
u64 slack = 0;
wait_queue_entry_t wait;//等待队列
ktime_t expires, *to = NULL; lockdep_assert_irqs_enabled();
//如果就绪链表为空则阻塞直到timeout
if (timeout > 0)
{
struct timespec64 end_time = ep_set_mstimeout(timeout); slack = select_estimate_accuracy(&end_time);
to = &expires;
*to = timespec64_to_ktime(end_time);
}
//非阻塞
else if (timeout == 0)
{
timed_out = 1;
spin_lock_irq(&ep->wq.lock);
goto check_events;
} fetch_events:
//是否有就绪事件,或正在扫描处理eventpoll中的rdllist链表
if (!ep_events_available(ep))
ep_busy_loop(ep, timed_out); spin_lock_irq(&ep->wq.lock); //如果监听的fd都没有就绪
if (!ep_events_available(ep)) {
/*
NAPI是linux新的网卡数据处理API,
简单来说,NAPI是综合中断方式与轮询方式的技术。
中断的好处是响应及时,如果数据量较小,则不会占用太多的CPU事件;缺点是数据量大时,
(每个传入数据包发出中断请求(IRQ)来中断内核。)会产生过多中断,
而每个中断都要消耗不少的CPU时间,从而导致效率反而不如轮询高。 轮询是基于中断的处理的替代方法。内核可以定期检查传入网络数据包的到达而不会中断,从而消除了中断处理的开销。
但是,建立最佳轮询频率很重要。轮询过于频繁会反复检查尚未到达的传入数据包,从而浪费CPU资源。
另一方面,轮询过于频繁地通过降低系统对传入数据包的反应性来引入延迟,
并且如果传入数据包缓冲区在处理之前填满,则可能导致数据包丢失。 NAPI是两者的结合,数据量低时采用中断,数据量高时采用轮询。平时是中断方式,当有数据到达时,会触发中断
处理函数执行,中断处理函数关闭中断开始处理。如果此时有数据到达,则没必要再触发中断了,因为中断处理函
数中会轮询处理数据,直到没有新数据时才打开中断。
很明显,数据量很低与很高时,NAPI可以发挥中断与轮询方式的优点,性能较好。如果数据量不稳定,且说高不高
说低不低,则NAPI则会在两种方式切换上消耗不少时间,效率反而较低一些
实现
来看下NAPI和非NAPI的区别:
(1) 支持NAPI的网卡驱动必须提供轮询方法poll()。
(2) 非NAPI的内核接口为netif_rx(),NAPI的内核接口为napi_schedule()。
(3) 非NAPI使用共享的CPU队列softnet_data->input_pkt_queue,NAPI使用设备内存(或者
设备驱动程序的接收环)。
* Busy poll timed out. Drop NAPI ID for now, we can add
* it back in when we have moved a socket with a valid NAPI
* ID onto the ready list.
*/ ep_reset_busy_poll_napi_id(ep); /*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
//OK, 初始化一个等待队列, 准备直接把自己挂起,
//注意current是一个宏, 返回的是一个thread_info结构task字段(我们称之为进程描述符)的变量,task正好指向与thread_info结构关联的那个进程描述符
//代表当前进程进程打开的文件资源保存在进程描述符的files成员里面,所以current->files返回的当前进程打开的文件资源。
//这里把调用了epoll_wait()系统调用等待epoll事件发生的进程(current)加入到ep->wq等待队列中。并设置了默认的回调函数用于唤醒应用程序。
//初始化等待队列节点wait,current表示当前进程。把wait和current绑定在一起。
init_waitqueue_entry(&wait, current);
////挂载到eventpoll的等待队列,等待文件状态就绪或直到超时, 或被信号中断
__add_wait_queue_exclusive(&ep->wq, &wait); for (;;) {
//TASK_INTERRUPTIBLE:进程处于睡眠状态,正在等待某些事件发生。进程可以被信号中断。 //执行ep_poll_callback()唤醒时应当需要将当前进程唤醒,
//这就是我们将任务状态设置为TASK_INTERRUPTIBLE的原因。
//将当前进程设置位睡眠, 但是可以被信号唤醒的状态,
//注意这个设置是"将来时", 此刻还没睡眠 set_current_state(TASK_INTERRUPTIBLE);
/*
* Always short-circuit for fatal signals to allow
* threads to make a timely exit without the chance of
* finding more events available and fetching
* repeatedly.
*/
if (fatal_signal_pending(current)) {
res = -EINTR;
break;
} //有就绪事件,或者超时则退出循环,唤醒
if (ep_events_available(ep) || timed_out)
break;
///有信号产生, 也退出循环,唤醒
if (signal_pending(current)) {
res = -EINTR;
break;
}
//什么都没有,解锁, 睡眠
spin_unlock_irq(&ep->wq.lock); //jtimeout这个时间后, 会被唤醒,
//ep_poll_callback()如果此时被调用,
//那么我们就会直接被唤醒, 不用等时间了...
//ep_poll_callback()的调用时机是由被监听的fd的具体实现(就绪事件), 比如socket或者某个设备驱动来决定的,
//因为等待队列头是他们持有的, epoll和当前进程只是单纯的等待 //睡眠让出处理器
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1; spin_lock_irq(&ep->wq.lock);
}
//从ep->wq等待队列中将调用了epoll_wait()的进程对应的节点移除
__remove_wait_queue(&ep->wq, &wait);
//设置当前进程的状态为RUNNING
__set_current_state(TASK_RUNNING);
}
check_events:
/* Is it worth to try to dig for events ? */ //判断epoll对象的rdllist链表和ovflist链表是否为空,如果不为空,说明有就绪
//事件发生,那么该函数返回1,否则返回0
eavail = ep_events_available(ep); spin_unlock_irq(&ep->wq.lock); /*
* Try to transfer events to user space. In case we get 0 events and
* there's still timeout left over, we go trying again in search of
* more luck.
*/
//如果一切正常, 有event发生, 就开始准备数据copy给用户空间了 //如果有就绪的事件发生,那么就调用ep_send_events()将就绪的事件存放到用户态
//内存中,然后返回到用户态,否则判断是否超时,如果没有超时就继续等待就绪事
//件发生,如果超时就返回用户态。
//从ep_poll()函数的实现可以看到,如果有就绪事件发生,则调用ep_send_events()函数做进一步处理,
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && !timed_out)
//ep_send_events函数向用户空间发送就绪事件。
goto fetch_events; return res;
} /**
* ep_loop_check_proc - Callback function to be passed to the @ep_call_nested()
* API, to verify that adding an epoll file inside another
* epoll structure, does not violate the constraints, in
* terms of closed loops, or too deep chains (which can
* result in excessive stack usage).
*
* @priv: Pointer to the epoll file to be currently checked.
* @cookie: Original cookie for this call. This is the top-of-the-chain epoll
* data structure pointer.
* @call_nests: Current dept of the @ep_call_nested() call stack.
*
* Returns: Returns zero if adding the epoll @file inside current epoll
* structure @ep does not violate the constraints, or -1 otherwise.
*/ //tfile_check_list:保存非epoll文件的fd用于反向检查
//还是看不懂
//检测epfd是否构成闭环或者连续epfd的深度超过5,对应宏EP_MAX_NESTS[4]
//visited_list:表示已经处理过的节点,假设epfd1下挂epfd2和epfd3,而epfd2和epfd3又同时挂epfd4,那么保证epfd只处理一次
//从源码和下面的测试来看这个闭环和深度检测只能从添加的fd向下检测,
//而不能向上检测,因此并不是所有场景都能有效的检测出来,
//如下测试,另外还有一种场景因为会跳过已经visit的节点,所以visit的节点的最大深度也可能会超过5。
static int ep_loop_check_proc(void *priv, void *cookie, int call_nests)
{
int error = 0;
struct file *file = priv;
struct eventpoll *ep = file->private_data;
struct eventpoll *ep_tovisit;
struct rb_node *rbp;
struct epitem *epi; mutex_lock_nested(&ep->mtx, call_nests + 1);
ep->visited = 1;
list_add(&ep->visited_list_link, &visited_list);
for (rbp = rb_first_cached(&ep->rbr); rbp; rbp = rb_next(rbp)) {
epi = rb_entry(rbp, struct epitem, rbn);
if (unlikely(is_file_epoll(epi->ffd.file))) {
ep_tovisit = epi->ffd.file->private_data;
if (ep_tovisit->visited)
continue;
error = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,
ep_loop_check_proc, epi->ffd.file,
ep_tovisit, current);
if (error != 0)
break;
}
else {
/*
* If we've reached a file that is not associated with
* an ep, then we need to check if the newly added
* links are going to add too many wakeup paths. We do
* this by adding it to the tfile_check_list, if it's
* not already there, and calling reverse_path_check()
* during ep_insert().
*/
if (list_empty(&epi->ffd.file->f_tfile_llink))
list_add(&epi->ffd.file->f_tfile_llink,
&tfile_check_list);
}
}
mutex_unlock(&ep->mtx); return error;
} /**
* ep_loop_check - Performs a check to verify that adding an epoll file (@file)
* another epoll file (represented by @ep) does not create
* closed loops or too deep chains.
*
* @ep: Pointer to the epoll private data structure.
* @file: Pointer to the epoll file to be checked.
*
* Returns: Returns zero if adding the epoll @file inside current epoll
* structure @ep does not violate the constraints, or -1 otherwise.
*/ //检测epfd是否构成闭环或者连续epfd的深度超过5,对应宏EP_MAX_NESTS[4]
//visited_list:表示已经处理过的节点,假设epfd1下挂epfd2和epfd3,而epfd2和epfd3又同时挂epfd4,那么保证epfd只处理一次
//从源码和下面的测试来看这个闭环和深度检测只能从添加的fd向下检测,
//而不能向上检测,因此并不是所有场景都能有效的检测出来,
//如下测试,另外还有一种场景因为会跳过已经visit的节点,所以visit的节点的最大深度也可能会超过5。
//通过ep_loop_check检测epfd是否构成闭环或者连续epfd的深度超过5,对应宏EP_MAX_NESTS[4]
static int ep_loop_check(struct eventpoll *ep, struct file *file)
{
int ret;
struct eventpoll *ep_cur, *ep_next; ret = ep_call_nested(&poll_loop_ncalls, EP_MAX_NESTS,
ep_loop_check_proc, file, ep, current);
/* clear visited list */
//visited_list:表示已经处理过的节点,假设epfd1下挂epfd2和epfd3,而epfd2和epfd3又同时挂epfd4,那么保证epfd只处理一次
//tfile_check_list:保存非epoll文件的fd用于反向检查 list_for_each_entry_safe(ep_cur, ep_next, &visited_list,
visited_list_link) {
ep_cur->visited = 0;
list_del(&ep_cur->visited_list_link);
}
return ret;
}
//不懂
static void clear_tfile_check_list(void)
{
struct file *file; /* first clear the tfile_check_list */
while (!list_empty(&tfile_check_list)) {
file = list_first_entry(&tfile_check_list, struct file,
f_tfile_llink);
list_del_init(&file->f_tfile_llink);
}
INIT_LIST_HEAD(&tfile_check_list);
} //创建并初始化数据结构eventpoll,以及创建file实例,并将ep放入file->private。
static int do_epoll_create(int flags)
{
int error, fd;
struct eventpoll *ep = NULL;//主描述符
struct file *file;
//创建存储所有监听事件所需要的eventpoll文件结构,为ep分配内存并进行初始化
error = ep_alloc(&ep);
//epollfd本身并不存在一个真正的文件与之对应, 所以内核需要创建一个
//"虚拟"的文件, 并为之分配真正的struct file结构,而且有真正的fd. 及innode节点
//这里2个参数比较关键:
//eventpoll_fops, fops就是file operations, 就是当你对这个文件(这里是虚拟的)进行操作(比如读)时,
//fops里面的函数指针指向真正的操作实现, epoll只实现了poll和release(就是close)操作,其它文件系统操作都有VFS全权处理了.
//ep, ep就是struct epollevent, 它会作为一个私有数据保存在struct file的private指针里面.(sys_epoll_ctl会取用)
//其实, 就是为了能通过fd找到struct file, 通过struct file能找到eventpoll结构. //得到一个空文件描述符fd
//O_CLOEXEC close-on-exec
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC)); //创建file实例,以及匿名inode节点和dentry等数据结构,epoll可以看成一个文件
//(匿名文件)因此我们可以看到epoll_create会返回一个fd。
//epoll所管理的所有的fd都是放在一个大的结构(红黑树)中, //简要说一下file/dentry/inode,当进程打开一个文件时,内核就会为该进程分配一个file结构,
//表示打开的文件在进程的上下文,然后应用程序会通过一个int类型的文件描述符来访问这个结构,
//实际上内核的进程里面维护一个file结构的数组,而文件描述符就是相应的file结构在数组中的下标。
//dentry结构(称之为“目录项”)记录着文件的各种属性,比如文件名、访问权限等,每个文件都只有一个dentry结构,
//然后一个进程可以多次打开一个文件,多个进程也可以打开同一个文件,
//这些情况,内核都会申请多个file结构,建立多个文件上下文。但是,对同一个文件来说,
//无论打开多少次,内核只会为该文件分配一个dentry。所以,file结构与dentry结构的关系是多对一的。
//同时,每个文件除了有一个dentry目录项结构外,还有一个索引节点inode结构,
//里面记录文件在存储介质上的位置和分布等信息,每个文件在内核中只分配一个inode。
//dentry与inode描述的目标是不同的,一个文件可能会有好几个文件名(比如链接文件),
//通过不同文件名访问同一个文件的权限也可能不同。dentry文件所代表的是逻辑意义上的文件,
//记录的是其逻辑上的属性,而inode结构所代表的是其物理意义上的文件,记录的是其物理上的属性。
//dentry与inode结构的关系是多对一的关系。 //inode节点应该是共享的
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC)); ep->file = file; //建立fd和file的关联关系
fd_install(fd, file); return fd;
} SYSCALL_DEFINE1(epoll_create1, int, flags)
{
return do_epoll_create(flags);
} SYSCALL_DEFINE1(epoll_create, int, size)
{
if (size <= 0)
return -EINVAL;
//之前存fd的底层是哈希表,需要size来指定大小
//新版本改成了红黑树,但为了兼容,还是保留了size。
return do_epoll_create(0);
} //epfd 就是epoll fd
//op ADD,MOD,DEL
//fd 需要监听的描述符
//event 我们关心的events
//添加删除更改fd描述符
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
struct eventpoll *tep = NULL; error = -EFAULT; //错误处理:如果是删除,且epoll_event结构不为NULL则报错
//如果是更改或者添加那就需要把从用户空间将epoll_event结构copy到内核空间
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return; //为了取得epoll的struct file结构,
f = fdget(epfd); //获取被监控的文件描述符对应的struct fd类型的对象
tf = fdget(fd); error = -EPERM;
//poll机制就是给定一段时间,在这一段时间内程序处于睡眠状态一直等待某一个资源,
//它会在两种情况下返回①时间到了②等到了资源。
//...epoll就是封装poll机制,select poll也都是封装poll机制
//判断监听的fd是否支持poll机制
if (!file_can_poll(tf.file))
goto error_tgt_fput; /* Check if EPOLLWAKEUP is allowed */
//EPOLLWAKEUP,不懂
if (ep_op_has_event(op))
ep_take_care_of_epollwakeup(&epds); /*
* We have to check that the file structure underneath the file descriptor
* the user passed to us _is_ an eventpoll file. And also we do not permit
* adding an epoll file descriptor inside itself.
*/
error = -EINVAL;
//epoll不能自己监听自己,可以监听别的epoll,但有条件:不支持独占的监听别的epoll
//判断传入的fd是不是自身,判断epfd是不是epoll文件
if (f.file == tf.file || !is_file_epoll(f.file))
goto error_tgt_fput; /*
* epoll adds to the wakeup queue at EPOLL_CTL_ADD time only,
* so EPOLLEXCLUSIVE is not allowed for a EPOLL_CTL_MOD operation.
* Also, we do not currently supported nested exclusive wakeups.
*/ //EPOLLEXCLUSIVE标识会保证一个事件发生时候只有一个线程会被唤醒,以避免多侦听下的“惊群”问题,
//多线程,以及epoll_create在fork之前的多进程可以使用EPOLLEXCLUSIVE避免惊群
//如果是epoll_create在fork之后的多进程,则要用户自己解决惊群问题
//epoll仅在EPOLL_CTL_ADD时添加到唤醒队列,因此不允许有EPOLLEXCLUSIVE事件时进行EPOLL_CTL_MOD操作。
if (ep_op_has_event(op) && (epds.events & EPOLLEXCLUSIVE)) {
if (op == EPOLL_CTL_MOD)
goto error_tgt_fput;
//目前不支持嵌套epoll的独占唤醒。
if (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||
(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))
goto error_tgt_fput;
} //取到我们的eventpoll结构, 来自epoll_create1()中的分配
ep = f.file->private_data; /*
* When we insert an epoll file descriptor, inside another epoll file
* descriptor, there is the change of creating closed loops, which are
* better be handled here, than in more critical paths. While we are
* checking for loops we also determine the list of files reachable
* and hang them on the tfile_check_list, so we can check that we
* haven't created too many possible wakeup paths.
*
* We do not need to take the global 'epumutex' on EPOLL_CTL_ADD when
* the epoll file descriptor is attaching directly to a wakeup source,
* unless the epoll file descriptor is nested. The purpose of taking the
* 'epmutex' on add is to prevent complex toplogies such as loops and
* deep wakeup paths from forming in parallel through multiple
* EPOLL_CTL_ADD operations.
*/
// 接下来的操作有可能修改数据结构内容, 锁起来
mutex_lock_nested(&ep->mtx, 0);
//感觉是嵌套epoll相关的
//list_empty(&f.file->f_ep_links) 这句的意思是, 看f这个文件有没有被epoll监听
//即f是不是被嵌套的epoll。
//把一个file加到了两个epoll中(file 的 f_ep_links 链表中会有两个epitem的fllink)
if (op == EPOLL_CTL_ADD) {
if (!list_empty(&f.file->f_ep_links) ||
is_file_epoll(tf.file)) {
full_check = 1;
mutex_unlock(&ep->mtx);
mutex_lock(&epmutex);
if (is_file_epoll(tf.file)) {
error = -ELOOP;
if (ep_loop_check(ep, tf.file) != 0) {
clear_tfile_check_list();
goto error_tgt_fput;
}
}
else
list_add(&tf.file->f_tfile_llink,
&tfile_check_list);
mutex_lock_nested(&ep->mtx, 0);
if (is_file_epoll(tf.file)) {
tep = tf.file->private_data;
mutex_lock_nested(&tep->mtx, 1);
}
}
} //上面已经锁好了,可以直接在树上查找
//epoll不允许重复添加fd(在ep的红黑树中查找是否已经存在这个fd)O(lgn)的时间复杂度.
epi = ep_find(ep, tf.file, fd);
error = -EINVAL;
switch (op) {
// 注册新的fd到epfd中
case EPOLL_CTL_ADD:
if (!epi) {
//EPOLLERR该文件描述符发生错误
//EPOLLHUP该文件描述符被挂断
//默认包含POLLERR和POLLHUP事件
epds.events |= EPOLLERR | EPOLLHUP;
//在ep的红黑树中插入这个fd对应的epitm结构体,以及一系列的操作。
error = ep_insert(ep, &epds, tf.file, fd, full_check);
}
else
//已经存在
error = -EEXIST;
if (full_check)
//不懂
clear_tfile_check_list();
break;
// 从epfd中删除一个fd
case EPOLL_CTL_DEL:
if (epi)
//在ep的红黑树中删除这个fd对应的epitm结构体,以及一系列的操作。
error = ep_remove(ep, epi);
else
error = -ENOENT;
break;
// 修改已经注册的fd的监听事件
case EPOLL_CTL_MOD:
if (epi) {
if (!(epi->event.events & EPOLLEXCLUSIVE)) {
epds.events |= EPOLLERR | EPOLLHUP;
error = ep_modify(ep, epi, &epds);
}
}
else
error = -ENOENT;
break;
}
if (tep != NULL)
mutex_unlock(&tep->mtx);
mutex_unlock(&ep->mtx); error_tgt_fput:
if (full_check)
mutex_unlock(&epmutex); fdput(tf);
error_fput:
fdput(f);
error_return: return error;
} /*
* Removes a "struct epitem" from the eventpoll RB tree and deallocates
* all the associated resources. Must be called with "mtx" held.
*/
//从eventpoll里移除某个epitem。
static int ep_remove(struct eventpoll *ep, struct epitem *epi)
{
struct file *file = epi->ffd.file; lockdep_assert_irqs_enabled(); //从poll_wait中移除这个epitem(这个epi不会再唤醒ep)
ep_unregister_pollwait(ep, epi); /* Remove the current item from the list of epoll hooks */
spin_lock(&file->f_lock);
//从file的f_ep_links链表移除epi的fllink结构
list_del_rcu(&epi->fllink);
spin_unlock(&file->f_lock); //从红黑树中移除
rb_erase_cached(&epi->rbn, &ep->rbr); spin_lock_irq(&ep->wq.lock);
if (ep_is_linked(epi))
//从ready链表中移除
list_del_init(&epi->rdllink);
spin_unlock_irq(&ep->wq.lock);
//取消wakeup注册
wakeup_source_unregister(ep_wakeup_source(epi));
/*
* At this point it is safe to free the eventpoll item. Use the union
* field epi->rcu, since we are trying to minimize the size of
* 'struct epitem'. The 'rbn' field is no longer in use. Protected by
* ep->mtx. The rcu read side, reverse_path_check_proc(), does not make
* use of the rbn field.
*/
call_rcu(&epi->rcu, epi_rcu_free); atomic_long_dec(&ep->user->epoll_watches);
//原子long类型自减
return 0;
} //ep_insert()在epoll_ctl()中被调用, 完成往epollfd里面添加一个监听fd的工作
//tfile是fd的struct file结构 //在ep_insert()函数中,epoll会定义一个类型为ep_pqueue的对象,
//该对象包括了epitem成员,以及一个类型为poll_table的对象成员pt。
//在ep_insert()函数中我们会将pt的_qproc这个回调函数成员设置为ep_ptable_queue_proc(),
//这会会将epitem对象对应的eppoll_entry对象加入到被监控的目标文件的等待队列中,
//并在ep_item_poll()函数中将pt的_key成员设置为用户态应用程序感兴趣的事件类型,
//然后调用被监控的目标文件的poll回调函数。 //以socket为例,因为socket有多种类型,如tcp、udp等,所以socket层会实现一个通用的poll回调函数,
//这个函数就是sock_poll()。
//在sock_poll()函数中通常会调用某一具体类型协议对应的poll回调函数,
//以tcp为例,那么这个poll()回调函数就是tcp_poll()。
//当socket有事件就绪时,比如读事件就绪,就会调用sock->sk_data_ready这个回调函数,
//即sock_def_readable(),在这个回调函数中则会遍历socket 文件中的等待队列,
//然后依次调用队列节点的回调函数,在epoll中对应的回调函数就是ep_poll_callback(),
//这个函数会将就绪事件对应的epitem对象加入到epoll对象eventpoll的就绪链表rdllist中,
//这样用户态程序调用epoll_wait()的时候就能获取到该事件, static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
int error, pwake = 0;
__poll_t revents;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
//ep_pqueue主要完成epitem和callback函数的关联。
//然后通过目标文件的poll函数调用callback函数ep_ptable_queue_proc。
//Poll函数一般由设备驱动提供,以网络设备为例,他的poll函数为sock_poll然后根据sock类型调用不同的poll函数如:packet_poll。
//packet_poll在通过datagram_poll调用sock_poll_wait,
//最后在poll_wait实际调用callback函数(ep_ptable_queue_proc)。
lockdep_assert_irqs_enabled();
//获取当前用户已经加入到epoll中监控的文件描述符数量,如果超过了上限,那么本次不加入
user_watches = atomic_long_read(&ep->user->epoll_watches);
//原子long类型读取 //查看是否达到当前用户的最大监听数
if (unlikely(user_watches >= max_user_watches))
return -ENOSPC;
//从slab中分配一个epitem来保存加入的fd
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM; //相关成员的初始化,都是内核数据结构LIST的一些函数
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
//将epoll对象挂载到该fd的epitem结构的ep成员中(用来找到对应的epoll对象)
epi->ep = ep;
//设置被监控的文件描述符及其对应的文件对象到epitem的ffd成员中
ep_set_ffd(&epi->ffd, tfile, fd);
//保存fd感兴趣的事件对象
epi->event = *event;
epi->nwait = 0;
//这个指针的初值不是NULL
epi->next = EP_UNACTIVE_PTR;
//根据EPOLLWAKEUP标志注册wake up
if (epi->event.events & EPOLLWAKEUP) {
error = ep_create_wakeup_source(epi);
if (error)
goto error_create_wakeup_source;
}
else {
RCU_INIT_POINTER(epi->ws, NULL);
} epq.epi = epi; // 安装poll回调函数
//将ep_ptable_queue_proc注册到epq.pt中的qproc。
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc); /*
* Attach the item to the poll hooks and get current event bits.
* We can safely use the file* here because its usage count has
* been increased by the caller of this function. Note that after
* this operation completes, the poll callback can start hitting
* the new item.
*/
//调用poll函数来获取当前事件位,其实是利用它来调用注册函数ep_ptable_queue_proc(poll_wait中调用)。
//如果fd是套接字,f_op为socket_file_ops,poll函数是sock_poll()。如果是TCP套接字的话,进而会调用
//到tcp_poll()函数。此处调用poll函数查看当前文件描述符的状态,存储在revents中。
//在poll的处理函数(tcp_poll())中,会调用sock_poll_wait(),
//在sock_poll_wait()中会调用到epq.pt.qproc指向的函数,
//也就是ep_ptable_queue_proc()。 //返回值表示该文件描述符感兴趣的事件。如果感兴趣的事件没有发生,则为0
//通过ep_item_poll把epitem添加到poll钩子中,并获取当前revents。
//最终会通过ep_ptable_queue_proc函数把eppoll_entry添加到sk->sk_wq->wait的头部,
//并通过pwq->llink添加到epi->pwqlist的尾部。
revents = ep_item_poll(epi, &epq.pt, 1); /*
* We have to check if something went wrong during the poll wait queue
* install process. Namely an allocation for a wait queue failed due
* high memory pressure.
*/
error = -ENOMEM;
if (epi->nwait < 0)
goto error_unregister; /* Add the current item to the list of active epoll hook for this file */
spin_lock(&tfile->f_lock);
//把epitem插入到f_ep_links链表的尾部
list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links);
spin_unlock(&tfile->f_lock); /*
* Add the current item to the RB tree. All RB tree operations are
* protected by "mtx", and ep_insert() is called with "mtx" held.
*/
//将epitem插入到对应的eventpoll中
ep_rbtree_insert(ep, epi);
// 将该epitem插入到ep的红黑树中 /* now check if we've created too many backpaths */
error = -EINVAL;
//通过reverse_path_check进行反向检查
if (full_check && reverse_path_check())
goto error_remove_epi; /* We have to drop the new item inside our item list to keep track of it */
spin_lock_irq(&ep->wq.lock); /* record NAPI ID of new item if present */
ep_set_busy_poll_napi_id(epi); /* If the file is already "ready" we drop it inside the ready list */
// revents & event->events: 刚才fop->poll的返回值中标识的事件有用户event关心的事件发生
//如果要监视的文件状态已经就绪并且还没有加入到就绪队列中,则将当前的epitem加入到就绪
//队列中。如果有进程正在等待该文件的状态就绪,则尝试唤醒epoll_wait进程wake_up_locked(&ep->wq);
//以及file->poll()等待进程ep_poll_safewake(&ep->poll_wait) if (revents && !ep_is_linked(epi)) {
//将当前的epitem加入到rdllist中去
list_add_tail(&epi->rdllink, &ep->rdllist); ep_pm_stay_awake(epi); /* Notify waiting tasks that events are available */ //waitqueue_active(q) 等待队列q中有等待的进程返回1,否则返回0。
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq); //如果有进程等待eventpoll文件本身的事件就绪(该eventpoll也被其他eventpoll poll住了),则增加临时变量pwake的值,
//pwake的值不为0时,在释放lock后,会唤醒等待进程
if (waitqueue_active(&ep->poll_wait))
pwake++;
} spin_unlock_irq(&ep->wq.lock);
//增加当前用户加入epoll中的文件描述符个数
//原子long类型自增
atomic_long_inc(&ep->user->epoll_watches); /* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait);
//唤醒等待eventpoll文件状态就绪的进程
return 0; error_remove_epi:
spin_lock(&tfile->f_lock);
list_del_rcu(&epi->fllink);
spin_unlock(&tfile->f_lock); rb_erase_cached(&epi->rbn, &ep->rbr); error_unregister:
ep_unregister_pollwait(ep, epi); /*
* We need to do this because an event could have been arrived on some
* allocated wait queue. Note that we don't care about the ep->ovflist
* list, since that is used/cleaned only inside a section bound by "mtx".
* And ep_insert() is called with "mtx" held.
*/
spin_lock_irq(&ep->wq.lock);
if (ep_is_linked(epi))
list_del_init(&epi->rdllink);
spin_unlock_irq(&ep->wq.lock); wakeup_source_unregister(ep_wakeup_source(epi)); error_create_wakeup_source:
kmem_cache_free(epi_cache, epi); return error;
} /*
* Modify the interest event mask by dropping an event if the new mask
* has a match in the current file status. Must be called with "mtx" held.
*/ static int ep_modify(struct eventpoll *ep, struct epitem *epi,
const struct epoll_event *event)
{
int pwake = 0;
poll_table pt; lockdep_assert_irqs_enabled(); init_poll_funcptr(&pt, NULL); /*
* Set the new event interest mask before calling f_op->poll();
* otherwise we might miss an event that happens between the
* f_op->poll() call and the new event set registering.
*/ //更新epi->event.events和epi->event.data
epi->event.events = event->events; /* need barrier below */
epi->event.data = event->data; /* protected by mtx */
// 根据EPOLLWAKEUP更新wake up
if (epi->event.events & EPOLLWAKEUP) {
if (!ep_has_wakeup_source(epi))
ep_create_wakeup_source(epi);
}
else if (ep_has_wakeup_source(epi)) {
ep_destroy_wakeup_source(epi);
} /*
* The following barrier has two effects:
*
* 1) Flush epi changes above to other CPUs. This ensures
* we do not miss events from ep_poll_callback if an
* event occurs immediately after we call f_op->poll().
* We need this because we did not take ep->wq.lock while
* changing epi above (but ep_poll_callback does take
* ep->wq.lock).
*
* 2) We also need to ensure we do not miss _past_ events
* when calling f_op->poll(). This barrier also
* pairs with the barrier in wq_has_sleeper (see
* comments for wq_has_sleeper).
*
* This barrier will now guarantee ep_poll_callback or f_op->poll
* (or both) will notice the readiness of an item.
*/
//刷新内存屏障smp_mb
//以下障碍有两个影响:
//1)将epitem以上的刷新更改为其他CPU。这确保了在我们调用f_op-> poll()之后立即发生事件时,我们不会错过ep_poll_callback中的事件。
//我们需要这个,因为在更改上面的epitem时我们没有使用ep-> wq.lock(但是ep_poll_callback确实需要ep-> wq.lock)。
//2)我们还需要确保在调用f_op-> poll()时不会错过_past_事件。
//此屏障还与wq_has_sleeper中的屏障配对(请参阅wq_has_sleeper的注释)。
//此障碍现在将确保ep_poll_callback或f_op-> poll(或两者)将注意到程序的准备情况。
smp_mb(); /*
* Get current event bits. We can safely use the file* here because
* its usage count has been increased by the caller of this function.
* If the item is "hot" and it is not registered inside the ready
* list, push it inside.
*/
//如果获取到的revents中有用户关注的事件,并且epitem未在rdllink链表中,
//那么把epi插入ready链表尾部 list_add_tail(&epi->rdllink, &ep->rdllist);
//并尝试唤醒epoll_wait进程wake_up_locked(&ep->wq);以及file->poll()等待进程ep_poll_safewake(&ep->poll_wait)
if (ep_item_poll(epi, &pt, 1)) {
spin_lock_irq(&ep->wq.lock);
if (!ep_is_linked(epi)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi); /* Notify waiting tasks that events are available */
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
spin_unlock_irq(&ep->wq.lock);
} /* We have to call this outside the lock */
if (pwake)
ep_poll_safewake(&ep->poll_wait); return 0;
}
/*
* Implement the event wait interface for the eventpoll file. It is the kernel
* part of the user space epoll_wait(2).
*/
static int do_epoll_wait(int epfd, struct epoll_event __user *events,
int maxevents, int timeout)
{
int error;
struct fd f;
struct eventpoll *ep; /* The maximum number of event must be greater than zero */
if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)
return -EINVAL;
//内核用户传数据都是要复制的,不能直接弄个指针、引用进来 //检查用户空间传入的events指向的内存是否可写。
if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event)))
return -EFAULT; /* Get the "struct file *" for the eventpoll file */
//获取epoll的struct file
//再通过对应的struct file获得eventpoll */
f = fdget(epfd);
if (!f.file)
return -EBADF; /*
* We have to check that the file structure underneath the fd
* the user passed to us _is_ an eventpoll file.
*/
error = -EINVAL;
//检查一下它是不是一个真正的epoll 是不是eventpoll file.
//判断用户态传进来的fd是不是epfd,即通过判断文件对象的操作回调是不是eventpoll_fops
if (!is_file_epoll(f.file))
goto error_fput; /*
* At this point it is safe to assume that the "private_data" contains
* our own data structure.
*/
// 根据private_data得到eventpoll结构
ep = f.file->private_data; //睡眠,挂到了这个epoll的等待队列上,等待事件到来或者超时(真正的ep_poll)
error = ep_poll(ep, events, maxevents, timeout);
//获取就绪的事件数,返回给用户态应用程序
error_fput:
fdput(f);
return error;
} SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
return do_epoll_wait(epfd, events, maxevents, timeout);
} /*
* Implement the event wait interface for the eventpoll file. It is the kernel
* part of the user space epoll_pwait(2).
*/ SYSCALL_DEFINE6(epoll_pwait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout, const sigset_t __user *, sigmask,
size_t, sigsetsize)
{
int error;
sigset_t ksigmask, sigsaved; /*
* If the caller wants a certain signal mask to be set during the wait,
* we apply it here.
*/
//信号的等待与阻塞:
// 如果一个进程正在处理类型为k的信号,那么此时当另一个k信号到的时候,
//进程的pending位向量(待处理信号集)的第k位会被设置。
//但这个刚到的k信号不会被立即处理,直到handler程序返回。
// 如果此时又来了一个k信号,那么由于此前pending位向量已被设置,所以这个信号会被丢弃。
// 一旦进程接收了信号k,那么内核就会清除pending的第k位。
// blocked位向量(被阻塞信号集)维护着进程阻塞的信号,在这里设置的信号不会被进程接收处理。
// 所以我们知道,pending & ~blocked 的结果指示了进程将要去接收处理的信号集。 //设置信号用的,在睡眠的过程中防止被唤醒???
if (sigmask) {
if (sigsetsize != sizeof(sigset_t))
return -EINVAL;
if (copy_from_user(&ksigmask, sigmask, sizeof(ksigmask)))
return -EFAULT;
sigsaved = current->blocked;
set_current_blocked(&ksigmask);
}
//真正的epoll_wait
error = do_epoll_wait(epfd, events, maxevents, timeout); /*
* If we changed the signal mask, we need to restore the original one.
* In case we've got a signal while waiting, we do not restore the
* signal mask yet, and we allow do_signal() to deliver the signal on
* the way back to userspace, before the signal mask is restored.
*/
//如果我们更改了信号掩码,我们需要恢复原始信号掩码。
//在恢复信号掩码之前,如果我们在等待时有信号,我们允许do_signal()在回来的路上发送信号 ,到用户空间。
//恢复之前的信号集 //ep_poll()检查signal_pending()并负责在有信号时将errno设置为 - EINTR。
if (sigmask) {
//EINTR : 在请求事件发生或者过期之前,调用被信号打断
if (error == -EINTR) {
memcpy(¤t->saved_sigmask, &sigsaved,
sizeof(sigsaved));
set_restore_sigmask();
}
else
set_current_blocked(&sigsaved);
}
return error;
} static int __init eventpoll_init(void)
{
struct sysinfo si;
//取得内核信息
si_meminfo(&si);
/*
* Allows top 4% of lomem to be allocated for epoll watches (per user).
*/
//内存页的大小 PAGE_SHIFT
//(si.totalram - si.totalhigh)低端内存页面数
//最多占用4%的低端内存
//即低端内存的%4可用于建立事件监控 //内核将4GB的虚拟地址空间分割为用户空间和内核空间,
//在二者的上下文中使用同样的映射。
//一个典型的分割是将3GB分配给用户空间,1GB分配给内核空间。
//内核代码和数据结构必需与这样的空间相匹配,
//但是占用内核地址空间最大的部分是物理内存的虚拟映射。
//内核无法直接操作没有映射到内核地址空间的内存。
//换句话说,内核对任何内存的访问,都需要使用自己的虚拟地址(内核仅有1GB地址空间)。
//因此许多年来,由内核所能处理的最大物理内存数量,就是将映射至虚拟地址内核部分的大小(1GB)
//,再减去内核代码自身所占用的空间。因此,基于x86的linux系统所能使用的最大物理内存,会比1GB小一点。 //为了使32位的处理器可以在大于4GB的物理空间寻址,
//处理器增添了“地址扩展”特性。
//然而有多少内存可以直接映射到逻辑地址的限制依然存在。
//只有内存的低端部分拥有逻辑地址,剩余部分(高端内存)没有逻辑地址。
//因此在访问特定的高端内存页前,内核必需建立明确的虚拟映射,
//使该页可在内核地址空间中被访问。因此许多内核数据结构必须被放置在低端内存中;
//而高端内存更趋向于为用户空间进程页所保留
ep_send_events_proc //在linux(32位系统)中,地址空间映射是这样的,把0xc0000000~0xffffffff这1GB内
//核地址空间划分成2个部分低端的796MB + 高端的128MB,低端796MB就使用f映射,直
//接映射到物理内存的前796MB上,而高端128MB就用来随时变更g来映射到物理内存超过
//796MB的范围上
//64位的系统,不存在问题,因为内核地址空间够了 //一、高端内存和低端内存的划分 //Linux物理内存空间分为DMA内存区(DMA Zone)、低端内存区(Normal Zone)与高端内存
//区(Highmem Zone)三部分。DMA Zone通常很小,只有几十M,低端内存区与高端内存区的划分来源于Linux内核空间大小的限制。 //二、来源: //过去,CPU的地址总线只有32位, 32的地址总线无论是从逻辑上还是从物理上都只能描
//述4G的地址空间(232=4Gbit),在物理上理论上最多拥有4G内存(除了IO地址空间,
//实际内存容量小于4G),逻辑空间也只能描述4G的线性地址空间。 //为了合理的利用逻辑4G空间,Linux采用了3:1的策略,即内核占用1G的线性地址空间
//,用户占用3G的线性地址空间。所以用户进程的地址范围从0~3G,内核地址范围从3G~
//4G,也就是说,内核空间只有1G的逻辑线性地址空间。 //如果Linux物理内存小于1G的空间,通常内核把物理内存与其地址空间做了线性映射,
//也就是一一映射,这样可以提高访问速度。但是,当Linux物理内存超过1G时,线性访
//问机制就不够用了,因为只能有1G的内存可以被映射,剩余的物理内存无法被内核管理
//,所以,为了解决这一问题,Linux把内核地址分为线性区和非线性区两部分,线性区
//规定最大为896M,剩下的128M为非线性区。从而,线性区映射的物理内存成为低端内存
//,剩下的物理内存被成为高端内存。与线性区不同,非线性区不会提前进行内存映射,
//而是在使用时动态映射。 //三、例子 //假设物理内存为2G,则低段的896M为低端内存,通过线性映射给内核使用,其他的1128
//M物理内存为高端内存,可以被内核的非线性区使用。由于要使用128M非线性区来管理
//超过1G的高端内存,所以通常都不会映射,只有使用时才使kmap映射,使用完后要尽快
//用kunmap释放。 //对于物理内存为1G的内核,系统不会真的分配896M给线性空间,896M最大限制。下面是
//一个1.5G物理内存linux系统的真实分配情况,只有721M分配给了低端内存区,如果是
//1G的linxu系统,分配的就更少了。 //MemTotal 1547MB //HighTotal 825MB //LowTotal 721MB //申请高端内存时,如果高端内存不够了,linux也会去低端内存区申请,反之则不行。
max_user_watches = (((si.totalram - si.totalhigh) / 25) << PAGE_SHIFT) / EP_ITEM_COST;
BUG_ON(max_user_watches < 0); /*
* Initialize the structure used to perform epoll file descriptor
* inclusion loops checks.
*/
ep_nested_calls_init(&poll_loop_ncalls); #ifdef CONFIG_DEBUG_LOCK_ALLOC
/* Initialize the structure used to perform safe poll wait head wake ups */
ep_nested_calls_init(&poll_safewake_ncalls);
#endif /*
* We can have many thousands of epitems, so prevent this from
* using an extra cache line on 64-bit (and smaller) CPUs
*/
//BUILD_BUG_ON如果条件为真则引起一个编译时错误。
BUILD_BUG_ON(sizeof(void *) <= 8 && sizeof(struct epitem) > 128); //(slab分配器)分配内存用来存放struct epitem
epi_cache = kmem_cache_create("eventpoll_epi", sizeof(struct epitem),
0, SLAB_HWCACHE_ALIGN | SLAB_PANIC | SLAB_ACCOUNT, NULL); //(slab分配器)分配内存用来存放struct eppoll_entry。
pwq_cache = kmem_cache_create("eventpoll_pwq",
sizeof(struct eppoll_entry), 0, SLAB_PANIC | SLAB_ACCOUNT, NULL); return 0;
}
fs_initcall(eventpoll_init); //epoll_create
//从slab缓存中创建一个eventpoll对象, 并且创建一个匿名的fd跟fd对应的file对象,
//即每个epoll实例都有一个file对象,以及一个匿名的inode
//而eventpoll对象保存在struct file结构的private指针中, 并且返回,
//该fd对应的file operations只是实现了poll跟release操作
//创建eventpoll对象的初始化操作
//获取当前用户信息, 是不是root, 最大监听fd数目等并且保存到eventpoll对象中
//初始化等待队列, 初始化就绪链表, 初始化红黑树的头结点
//
//epoll_ctl操作
//如果是add mod将epoll_event结构拷贝到内核空间中
//并且判断加入的fd是否支持poll结构(epoll, poll, selectI / O多路复用必须支持poll操作).
//并且从epfd->file->privatedata获取event_poll对象, 根据op区分是添加删除还是修改,
//首先在eventpoll结构中的红黑树查找是否已经存在了相对应的fd, 没找到就支持插入操作, 否则报重复的错误.
//相对应的修改, 删除类似。 //插入操作时, 会创建一个与fd对应的epitem结构, 并且初始化相关成员, 比如保存监听的fd跟file结构之类的(ffd)
//重要的是指定了调用poll_wait时的回调函数用于数据就绪时唤醒进程,
//(其内部, 初始化设备的等待队列, 将该进程注册到等待队列)完成这一步, 我们的epitem就跟这个socket关联起来了,
//当它有状态变化时,会通过ep_poll_callback()来通知.
//最后调用加入的fd的file operation->poll函数(最后会调用poll_wait操作)用于完成注册操作.
//最后将epitem结构添加到红黑树中
//
//epoll_wait操作
//计算睡眠时间(如果有), 判断eventpoll对象的链表是否为空, 不为空那就干活不睡眠.并且初始化一个等待队列, 把自己挂上去, 设置自己的进程状态
//为可睡眠状态.判断是否有信号到来(有的话直接被中断醒来, ), 如果啥事都没有那就调用schedule_timeout进行睡眠, 如果超时或者被唤醒, 首先从自己初始化的等待队列删除
//, 然后开始拷贝资源给用户空间了
//拷贝资源则是先把就绪事件链表转移到中间链表, 然后挨个遍历拷贝到用户空间,
//并且挨个判断其是否为水平触发, 是的话再次插入到就绪链表
epoll源码解析翻译------说使用了mmap的都是骗子的更多相关文章
- 实战录 | Kafka-0.10 Consumer源码解析
<实战录>导语 前方高能!请注意本期攻城狮幽默细胞爆表,坐地铁的拉好把手,喝水的就建议暂时先别喝了:)本期分享人为云端卫士大数据工程师韩宝君,将带来Kafka-0.10 Consumer源 ...
- redux源码解析(深度解析redux+异步demo)
redux源码解析 1.首先让我们看看都有哪些内容 2.让我们看看redux的流程图 Store:一个库,保存数据的地方,整个项目只有一个 创建store Redux提供 creatStore 函数来 ...
- dcraw源码解析
dcraw源码解析 Author:Maddock Date:2015-04-22 转载请注明出处: 首先吐槽一点: 程序中使用了相当多的全局变量, 看的人头大.全局变量的坏处参看 http://wen ...
- Android AsyncTask 源码解析
1. 官方介绍 public abstract class AsyncTask extends Object java.lang.Object ↳ android.os.AsyncTask&l ...
- Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例
概要 这一章,我们对TreeMap进行学习.我们先对TreeMap有个整体认识,然后再学习它的源码,最后再通过实例来学会使用TreeMap.内容包括:第1部分 TreeMap介绍第2部分 TreeMa ...
- 黄聪:WordPress动作钩子函数add_action()、do_action()源码解析
WordPress常用两种钩子,过滤钩子和动作钩子.过滤钩子相关函数及源码分析在上篇文章中完成,本篇主要分析动作钩子源码. 然而,在了解了动作钩子的源码后你会发现,动作钩子核心代码竟然跟过滤钩子差不多 ...
- Retrofit2 源码解析
原文链接:http://bxbxbai.github.io/2015/12/13/retrofit2-analysis/ 公司里最近做的项目中网络框架用的就是Retrofit,用的多了以后觉得这个框架 ...
- 给jdk写注释系列之jdk1.6容器(4)-HashMap源码解析
前面了解了jdk容器中的两种List,回忆一下怎么从list中取值(也就是做查询),是通过index索引位置对不对,由于存入list的元素时安装插入顺序存储的,所以index索引也就是插入的次序. M ...
- TreeMap源码解析
1.TreeMap介绍 TreeMap是一个通过红黑树实现有序的key-value集合. TreeMap继承AbstractMap,也即实现了Map,它是一个Map集合 TreeMap实现了Navig ...
随机推荐
- win10的cortana搜索显示空白
解决方法:重置应用 问题原因:待查明 然后,我们往下拉
- redhat系统服务器重启后提示An error occurred during the file system check.
问题描述 浪潮一台NF8480M3外观红灯报警,鉴于无法登陆带外,只能对服务器进行断电重启操作 问题现象 重启后进入开机过程并报错,报错如下内容及图片如下所示,正常来说进入此界面后直接输入root密码 ...
- post 和php://input 转
$_POST['paramName'] 获取通过表单(multipart/form-data)提交的数据.但有时客户端会直接将请求数据以字符串的形式都放到 body 里传递过来,那么服务端就需要使用 ...
- linux(centos8):kubernetes安装的准备工作
一,安装docker-ce19.03.11 1,卸载podman [root@kubemaster ~]# dnf remove podman podman是红帽系os自带的容器,卸载是为了避免冲突 ...
- 面试官:为什么MySQL的索引要使用B+树,而不是其它树?比如B树?
InnoDB的一棵B+树可以存放多少行数据? 答案:约2千万 为什么是这么多? 因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构.数据组织方式说起. 计算机在存储数据的时候,有最小 ...
- jinjia2语言
金家兔 网站: https://jinja.palletsprojects.com/en/2.11.x/ #Jinja is Beautiful {% extends "layout.htm ...
- xib使用
xib和storyboard都可以建立应用程序的视图.他们的主要区别在于,xib用于创建应用程序的局部视图,storyboard用于创建应用程序的整体视图. xib是storyboard的前身. xi ...
- 第12天 | 12天搞定Python,让excel飞起来
学了10多天Python基础知识了,是时候来点硬货了,看过<第1天 | 12天搞定Python,告诉你有什么用?>的老铁都知道,Python可用的领域挺多的.只是我长期待在企业,所以只能说 ...
- 用一道模板题理解多源广度优先搜索(bfs)
题目: //多元广度优先搜索(bfs)模板题详细注释题解(c++)class Solution { int cnt; //新鲜橘子个数 int dis[10][10]; //距离 int dir_x[ ...
- 联赛模拟测试24 D. 你相信引力吗 单调栈
题目描述 分析 因为跨过最大值的区间一定是合法的,所以我们人为地把最大值放在最左边 我们要统计的就是在最大值右边单调不降的序列,可以用单调栈维护 需要特殊处理相同的情况 代码 #include< ...