CMU数据库(15-445) Lab4-CONCURRENCY CONTROL
Lab4- CONCURRENCY CONTROL
拖了很久终于开始做实验4了。lab4有三个大任务1. Lock Manager、2. DEADLOCK DETECTION 、3. CONCURRENT QUERY EXECUTION。这里20年的lab好像和之前的不太一样记得之前有日志和错误恢复lab的。不过就做这个最新的了。
Task1 LOCK MANAGER
1.1 任务描述
这个任务只需要修改两个文件concurrency/lock_manager.cpp和concurrency/lock_manager.h。这里cmu已经给我们提供了和事物相关的一些函数。在include/concurrency/transaction.h。这里的==锁管理==(下用LM表示)针对于tuple级别。我们需要对lock/unlock请求作出正确的行为。如果出现错误应该抛出异常。
1.2 一些小tips
1. 请仔细阅读位于lock_manager.h内的LockRequestQueue类这会帮助你确定哪些事物在等待一个锁
2. 建议使用std::condition_variable来通知那些等待锁的事物
3. 使用shared_lock_set_和exclusive_lock_set_来区别共享锁和排他锁。这样当TransactionManager想要提交和abort事物的时候。LM就可以合理的释放锁
4. 你应该通读TransactionManager::Abort来了解对于Abort状态的事物。LM是如何释放锁的
==一些参考阅读资料==
1、两个常用的互斥对象:std::mutex(互斥对象),std::shared_mutex(读写互斥对象)
2、三个用于代替互斥对象的成员函数,管理互斥对象的锁(都是构造加锁,析构解锁):std::lock_guard用于管理std::mutex,std::unique_lock与std::shared_lock管理std::shared_mutex。
1.3 具体实现细节
1. 我们需要弄清楚各种锁
X锁(排他锁,Exclusive Locks)
当加X锁的时候,表示我们要写这个tuple。当一个事物拥有排他锁时,其他任何事务必须等到X锁被释放才能对该页进行访问;X锁一直到事务结束才能被释放。下面来看一个例子
T1: update table set column1='hello' where id<1000
T2: update table set column1='world' where id>1000对于这个sql语句而言。加入事物T1先到达。这个过程T1会对id < 1000的记录施加排他锁,但是由于T2的更新和T1并无关系,所以它不会阻塞T2的更新
同样看下面的例子。
T1: update table set column1='hello' where id<1000
T2: update table set column1='world' where id>900如同上例,如果T1先达,T2立刻也到,T1加的排他锁会阻塞T2的update.
对于本实验的实现。我们需要记住。
如果有事物对当前rid加了共享锁。则必须等共享锁释放之后才能再加X锁 如果有事物对当前rid加了X锁之后,则在该X锁释放之前,不会有任何的锁被施加
S锁(共享锁,Shared Locks)
多个事务可封锁一个共享页;任何事务都不能修改该页; 通常是该页被读取完毕,S锁立即被释放。
本实验对于S锁的实现要和U锁结合起来。因此会在下面说明。
U锁(更新锁,Updated Locks)
为了解决死锁。引入了更新锁,看下面的例子
----------------------------------------
T1:
begin tran
select * from table(updlock) (加更新锁)
update table set column1='hello'
T2:
begin tran
select * from table(updlock)
update table set column1='world'
----------------------------------------事物T1加更新锁的意思就是。我现在虽然只想读。但是我要预留一个写的名额,因此当有事物施加U锁之后,其他事物便不能加U锁。比如本例,T1执行select,加更新锁。T2运行,准备加更新锁,但发现已经有一个更新锁在那儿了,只好等。
除此之外,更新锁可以和读操作共存这也是我们这个实验实现时需要重点考虑的
----------------------------------------
T1: select * from table(updlock) (加更新锁)
T2: select * from table(updlock) (等待,直到T1释放更新锁,因为同一时间不能在同一资源上有两个更新锁)
T3: select * from table (加共享锁,但不用等updlock释放,就可以读)
----------------------------------------因此在我们这个实验实现的时候我们需要注意
如果有事物对当前rid加了更新锁。则不允许加X和S锁 当被读取的页将要被更新时,则升级为X锁;U锁要一直到事务结束时才能被释放。
2. 任务一实现上的一些说明
注:不会附上很多代码。(听Andy教授的话)
1. 对于S锁
只需要考虑下面这些情况
如果当前 Lock_queue中有X锁则需要wait如果有其他事物对当前rid加了U锁则需要wait 否则可以加S锁
简单附上一些代码
if (mode == LockMode::SHARED) {
auto shared_wait_for = [&]() { return !lock_queue.upgrading_ && !lock_queue.hasExclusiveLock(txn); };
while (!shared_wait_for()) {
lock_queue.cv_.wait(_lock);
}
txn->GetSharedLockSet()->emplace(rid);
}
lock_queue.hasExclusiveLock(txn)函数
就是用来判断是否有排他锁
inline bool hasExclusiveLock(Transaction *txn) {
std::list<LockRequest>::iterator curr = request_queue_.begin();
for (; curr != request_queue_.end(); curr++) {
if (curr->lock_mode_ == LockMode::EXCLUSIVE) {
return true;
}
}
return false;
}
2. 对于X锁
如果有其他事物加了X锁则wait 如果有其他事物对当前rid加了U锁则需要wait 否则可以加X锁
同样附上一些简单的代码
if (mode == LockMode::EXCLUSIVE) {
auto exclusive_wait_for = [&]() { return !lock_queue.upgrading_ && lock_queue.request_queue_.size() == 1; };
while (!exclusive_wait_for()) {
lock_queue.cv_.wait(_lock);
}
txn->GetExclusiveLockSet()->emplace(rid);
}
和共享锁的实现基本类似
3. 对于U锁
附上带注释的核心逻辑代码。基本可以说明白这个地方
// 标记位更新。表明现在正处于等待update锁阶段
queue.upgrading_ = true;
// 假如说当前的request_queue中只有当前update lock这一个请求。则可以加U锁,否则应该wait
while (lock_table_[rid].request_queue_.size() != 1) {
queue.cv_.wait(unique_lock);
}
// 加X锁。并把标记位重制
queue.request_queue_.back() = LockRequest(txn->GetTransactionId(), LockMode::EXCLUSIVE);
queue.upgrading_ = false;
Task2 DEADLOCK DETECTION
这个任务要求你的LM能够进行死锁检测。死锁检测算法就是最常见的资源分配图算法
下面用cmu课上ppt的例子来看一下这个算法。
核心就是如果事物Ti在等待事物Tj释放锁。则画一条从i-->j的边。如果检测完所有的冲突事务。如果出现环则表示出现了死锁。如果没有环则表示没有死锁。
我们可以发现事务T1正在等待事物T2释放锁

事物T2中对于C的X锁正在等待事物T3的S锁释放
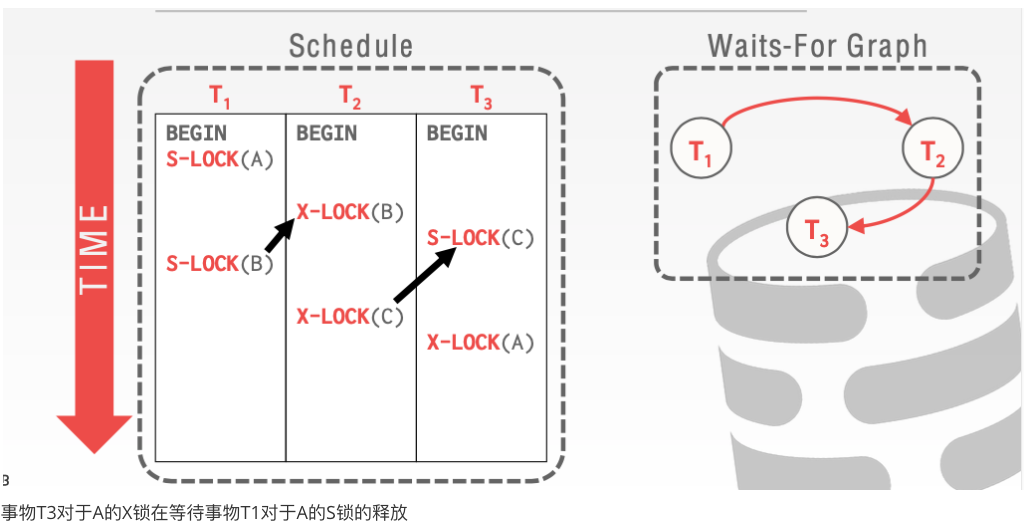
事物T3对于A的X锁在等待事物T1对于A的S锁的释放
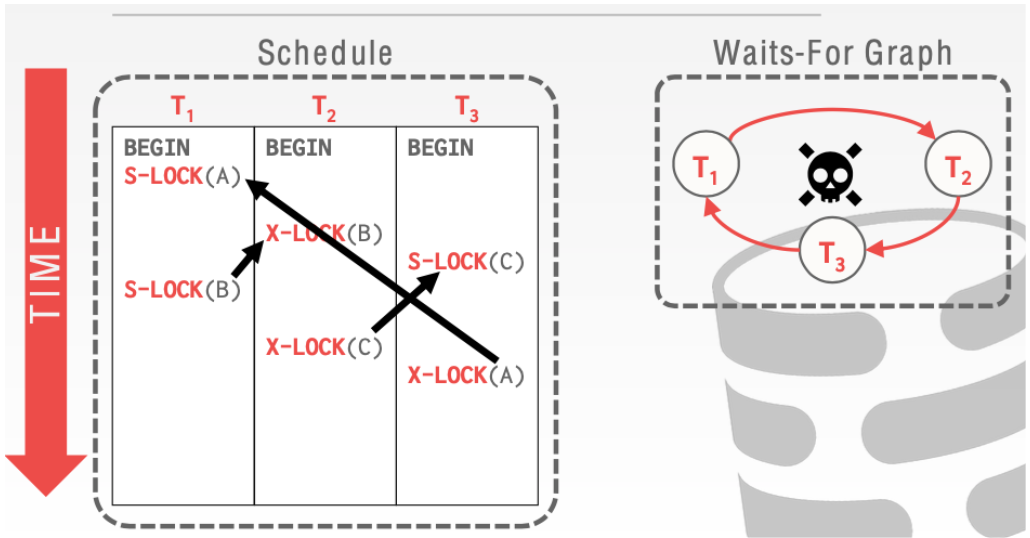
这样形成了一个环就发生了死锁,这个时候就需要abort
2.1 一些来自TA和官网的建议
等待图是一个有向图 你必须有一种方法来通知被abort的等待线程 当你发现一个环的时候,你应该终止yongest的事物来打破死锁。
2.2 具体实现
1. remove和add的操作比较简单
就直接附上代码不说废话
void LockManager::AddEdge(txn_id_t t1, txn_id_t t2) {
for (const auto &txn_id : waits_for_[t1]) {
if (txn_id == t2) {
return;
}
}
waits_for_[t1].push_back(t2);
}
void LockManager::RemoveEdge(txn_id_t t1, txn_id_t t2) {
LOG_DEBUG("we can remove edge");
auto &vec = waits_for_[t1];
for (auto iter = vec.begin(); iter != vec.end(); ++iter) {
if (*iter == t2) {
vec.erase(iter);
return;
}
}
}
2. hasCycle函数
这个函数的实现。就是对于我们上面算法的实现。由于依赖图是一个有向图。因此我们需要知道如何判断一个有向图是否有环。
用简单的dfs就可以实现这一功能。当然除了一个visited数组来判断这个元素是否被遍历过之外。我们还需要另外一个数组recStack用来 keep track of vertices in the recursion stack.
具体的过程就和下图一样
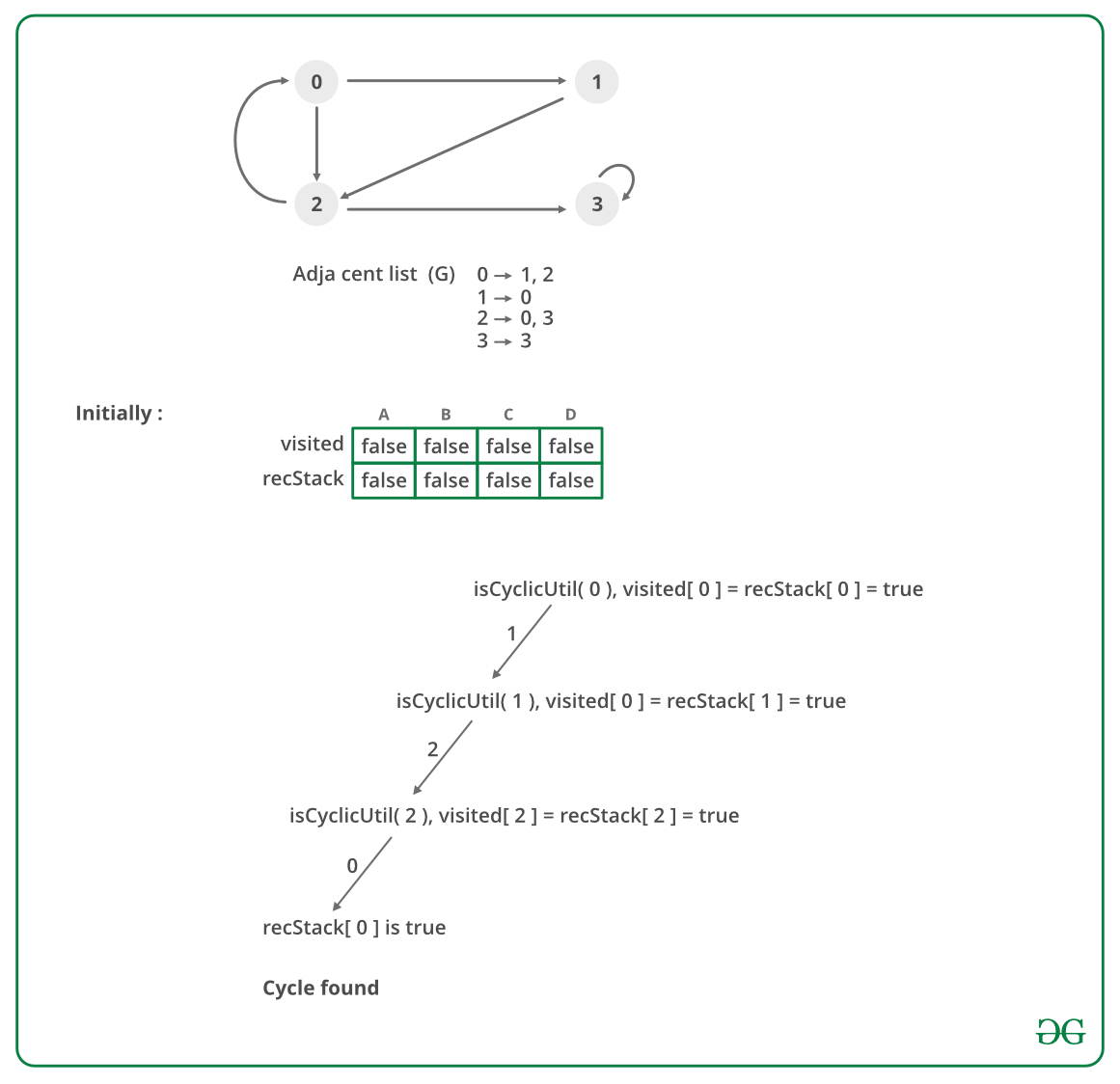
下面附上上面那个算法的代码实习。但是关于本任务需要的代码没有给出
// This function is a variation of DFSUtil() in https://www.geeksforgeeks.org/archives/18212
bool Graph::isCyclicUtil(int v, bool visited[], bool *recStack)
{
if (visited[v] == false)
{
// Mark the current node as visited and part of recursion stack
visited[v] = true;
recStack[v] = true;
// Recur for all the vertices adjacent to this vertex
list<int>::iterator i;
for(i = adj[v].begin(); i != adj[v].end(); ++i)
{
if( !visited[*i] && isCyclicUtil(*i, visited, recStack) )
return true;
else if (recStack[*i])
return true;
}
}
recStack[v] = false; // remove the vertex from recursion stack
return false;
}
3. 对于构建图的补充
因为构建图之前我们要获取所有已经加锁和等待锁的事物id。
这里用两个函数来实现这两个步骤
这里附上找到所有等待锁事物的函数。另一个不再给出。
std::unordered_set<txn_id_t> getWaitingSet() {
std::list<LockRequest>::iterator wait_start;
std::unordered_set<txn_id_t> blocking;
// 遍历找到wait_start的位置
std::list<LockRequest>::iterator curr = request_queue_.begin();
for (; curr != request_queue_.end() && (curr->lock_mode_ == LockMode::SHARED || curr ->lock_mode_ == LockMode::EXCLUSIVE); curr++) {
}
wait_start = curr;
for (; wait_start != request_queue_.end(); wait_start++) {
if (GetTransaction(wait_start->txn_id_)->GetState() != TransactionState::ABORTED) {
blocking.insert(wait_start->txn_id_);
}
}
return blocking;
}
};
Task3
3.1 隔离级别
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
就好比还没确定的消息,你却先知道了发布出去,最后又变更了,这样就发生了错误
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。
3.2 对于seqScan的并发控制
由于对于整个表的遍历。也就是读操作,在并发的情况下可能发生错误。所以必须加以控制
这里附上一些加锁的代码进行解释
首先是对于隔离级别的区分
如果隔离级别为 READ_UNCOMMITTED则不需要加锁如果隔离级别为 READ_COMMITTED或者REPEATABLE_READ则需要判断。如果当前rid没有被加锁。则加上共享锁
Transaction *txn = exec_ctx_->GetTransaction();
LockManager *lock_mgr = exec_ctx_->GetLockManager();
if (lock_mgr != nullptr) {
switch (txn->GetIsolationLevel()) {
case IsolationLevel::READ_UNCOMMITTED:
break;
case IsolationLevel::READ_COMMITTED:
case IsolationLevel::REPEATABLE_READ:
RID r = iter->GetRid();
if (txn->GetSharedLockSet()->empty() && txn->GetExclusiveLockSet()->empty()) {
lock_mgr->LockShared(txn, r);
txn->GetSharedLockSet()->insert(r);
}
break;
}
}
3.3 对于update的并发控制
这个更新比较简单。
主要有下面两个原则
如果当前rid拥有共享锁。当我想要 update的时候需要把它更新成update Lock否则定话如果没有排他锁我们需要加上排他锁
if (lock_mgr != nullptr) {
if (txn->IsSharedLocked(*rid)) {
lock_mgr->LockUpgrade(txn, *rid);
txn->GetSharedLockSet()->erase(*rid);
txn->GetExclusiveLockSet()->insert(*rid);
} else if (txn->GetExclusiveLockSet()->empty()) {
lock_mgr->LockExclusive(txn, *rid);
}
}
对于delete的并发控制和update的完全一样。只需要加入上面的原则即可
总结
总算磕磕绊绊把四个lab都写完了。感谢在知乎和github以及qq群里面得到的各种帮助。后面准备配合这门课的要求把对应章节的书的内容读一下。同时把之前没有写完的上课笔记写完。顺带有时间把前面lab的博客改一下。因为实现方面有了变化。后面就准备开搞下一个lab了。不知道大家是推荐824分布式还是推荐os那。
CMU数据库(15-445) Lab4-CONCURRENCY CONTROL的更多相关文章
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- Optimistic Concurrency VS. Pessimistic Concurrency Control
原创地址:http://www.cnblogs.com/jfzhu/p/4009918.html 转载请注明出处 (一)为什么需要并发控制机制 并发控制机制是为了防止多个用户同时更改同一条数据,也 ...
- 数据访问模式:数据并发控制(Data Concurrency Control)
1.数据并发控制(Data Concurrency Control)简介 数据并发控制(Data Concurrency Control)是用来处理在同一时刻对被持久化的业务对象进行多次修改的系统.当 ...
- Optimistic concurrency control 死锁 悲观锁 乐观锁 自旋锁
Optimistic concurrency control https://en.wikipedia.org/wiki/Optimistic_concurrency_control Optimist ...
- MVCC(Multi-Version Concurrency Control)多版本并发控制机
MVCC(Multi-Version Concurrency Control)是一种多版本并发控制机制.
- Optimistic concurrency control
Optimistic concurrency control https://en.wikipedia.org/wiki/Optimistic_concurrency_control Optimist ...
- CMU数据库(15-445)Lab0-环境搭建
0.写在前面 从这篇文章开始.开一个新坑,记录以下自己做cmu数据库实验的过程,同时会分析一下除了要求我们实现的代码之外的实验自带的一些代码.争取能够对实现一个数据库比较了解.也希望能写进简历.让自己 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- 浅析Postgres中的并发控制(Concurrency Control)与事务特性(上)
转载:https://www.cnblogs.com/flying-tiger/p/9567213.html#4121483#undefined PostgreSQL为开发者提供了一组丰富的工具来管理 ...
随机推荐
- Windows 常用键盘快捷键:
键盘快捷键 通过使用键盘快捷键可以节省时间. Windows 和 Mac 的键盘快捷键 在现代操作系统中和计算机软件程序中,键盘快捷键经常被使用. 使用键盘快捷键能帮您节省很多时间. 基本的快捷键 描 ...
- VSCode 开放式架构的产品实现思路
VSCode 开放式架构的产品实现思路 https://code.visualstudio.com/ 源码 https://github.com/microsoft/vscode https://gi ...
- React 权限管理
React 权限管理 react in depth JWT token access_token & refresh_token access token & refresh toke ...
- css & background-image & full page width & background-size
css & background-image & full page width & background-size https://css-tricks.com/perfec ...
- Android 开发 权限管理
Android 开发 权限管理 https://sspai.com/post/42779 $ adb shell pm list permissions -d -g https://zhuanlan. ...
- H5 直播 & App 直播
H5 直播 & App 直播 polyv 直播 https://github.com/polyv 宝利威 直播 https://www.polyv.net/live/ SDK https:// ...
- API protocols All In One
API protocols All In One SOAP vs. REST vs. JSON-RPC vs. gRPC vs. GraphQL vs. Thrift https://www.mert ...
- 聚焦 2021 NGK 新加坡区块链技术峰会,探讨DeFi未来新生态!
2021年1月31日14时,备受行业关注的"2021 NGK 新加坡区块链技术峰会"如期举行.本次峰会由NGK官方主办,以"DeFi"为主题,探讨了区块链技术革 ...
- 「NGK每日快讯」12.29日NGK第56期官方快讯!
- java放射机制的学习心得
概述 之前在了解Spring的类加载机制的时候,了解了java的反射机制.但是,我对反射理解一直不深.也一直有点疑惑:Spring为什么利用反射创建对象?直接new对象和依靠反射创建对象有什么区别?什 ...