CDH+Kylin三部曲之二:部署和设置
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
本文是《CDH+Kylin三部曲》系列的第二篇,上一篇《CDH+Kylin三部曲之一:准备工作》已将所需的机器和文件准备完毕,可以部署CDH和Kylin了;
执行ansible脚本部署CDH和Kylin(ansible电脑)
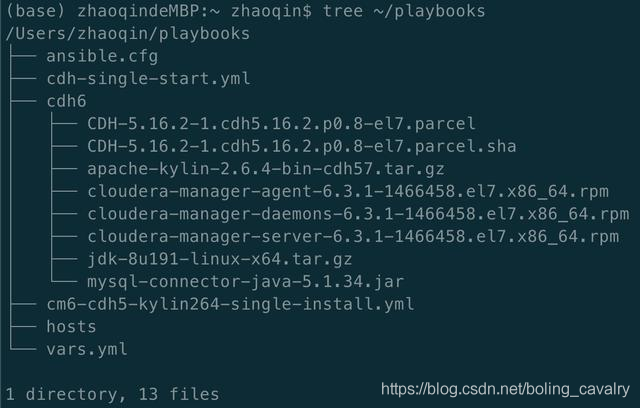
- 进入ansible电脑的~/playbooks目录,经过上一篇的准备工作,该目录下应该是下图这些内容:
- 检查ansible远程操作CDH服务器是否正常,执行命令ansible deskmini -a "free -m",正常情况下显示CDH服务器的内存信息,如下图:

- 执行命令开始部署:ansible-playbook cm6-cdh5-kylin264-single-install.yml
- 整个部署过程涉及在线安装、传输大文件等耗时的操作,请耐心等待(半小时左右),如果部署期间出错退出(例如网络问题),只需重复执行上述命令即可,ansible保证了操作的幂等性;
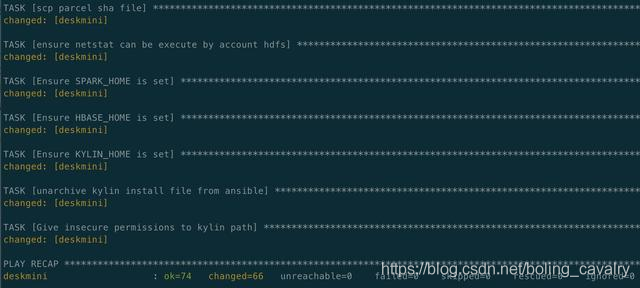
- 部署成功如下图所示:
重启CDH服务器
由于修改了selinux和swap的设置,需要重启操作系统才能生效,因此请重启CDH服务器;
执行ansible脚本启动CDH服务(ansible电脑)
- 等待CDH服务器重启成功;
- 登录ansible电脑,进入~/playbooks目录;
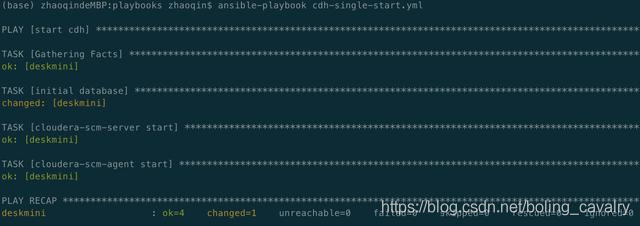
- 执行初始化数据库和启动CDH的脚本:ansible-playbook cdh-single-start.yml
- 启动完成输出如下信息:
- ssh登录CDH服务器,执行此命令观察CDH服务的启动情况:tail -f /var/log/cloudera-scm-server/cloudera-scm-server.log,看到下图红框中的内容时,表示启动完成,可以用浏览器登录了:

设置(浏览器操作)
现在CDH服务已经启动了,可以通过浏览器来操作:
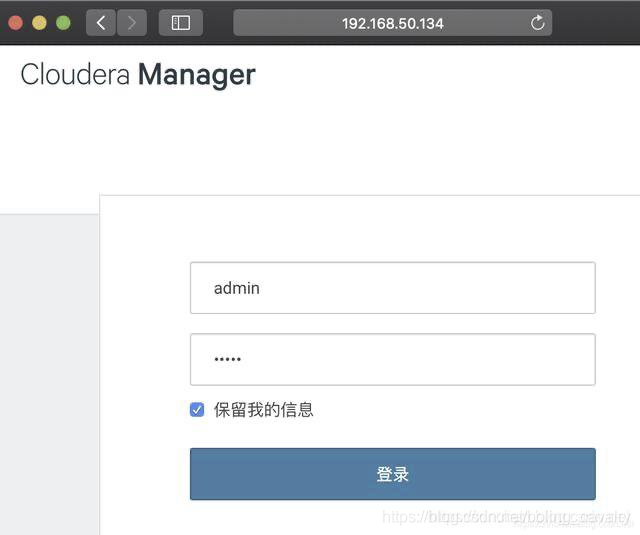
- 浏览器访问:http://192.168.50.134:7180 ,如下图,账号密码都是admin:
- 一路next,在选择版本页面选择60天体验版:
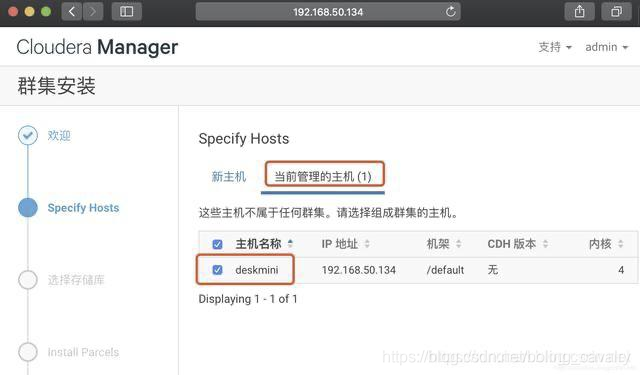
- 选择主机页面可见CDH服务器(deskmini):
- 在选择CDH版本的页面,请选择下图红框中的5.16.2-1:

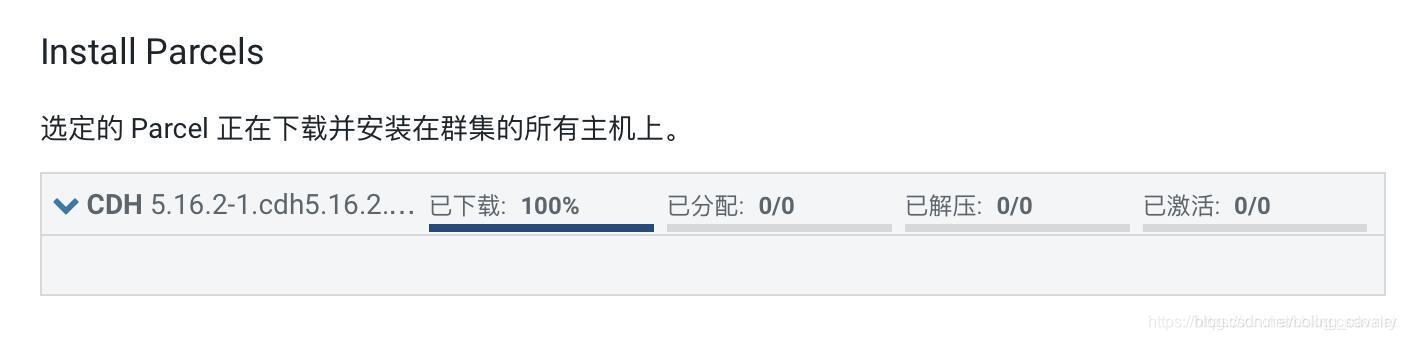
- 进入安装Parcel的页面,由于提前上传了离线parcle包,因此下载进度瞬间变成百分之百,此时请等待分配、解压、激活的完成:
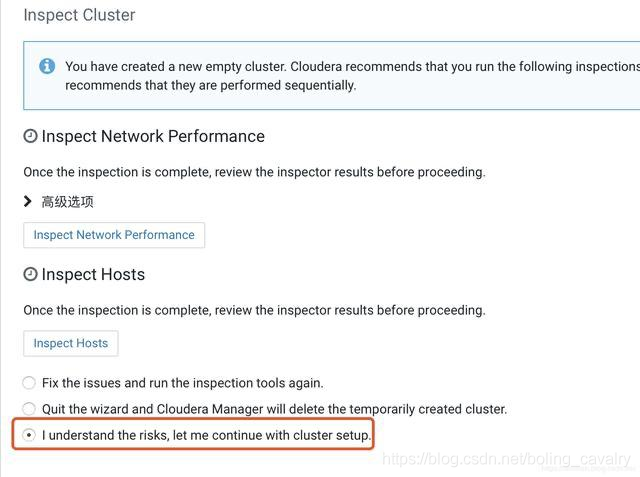
- 接下来有一些推荐操作,这里选择如下图红框,即可跳过:
- 接下来是选择服务的页面,我选择了自定义服务,然后选择了HBase、HDFS、Hive、Hue、Oozie、Spark、YARN、Zookeeper这八项,可以满足运行Kylin的需要:
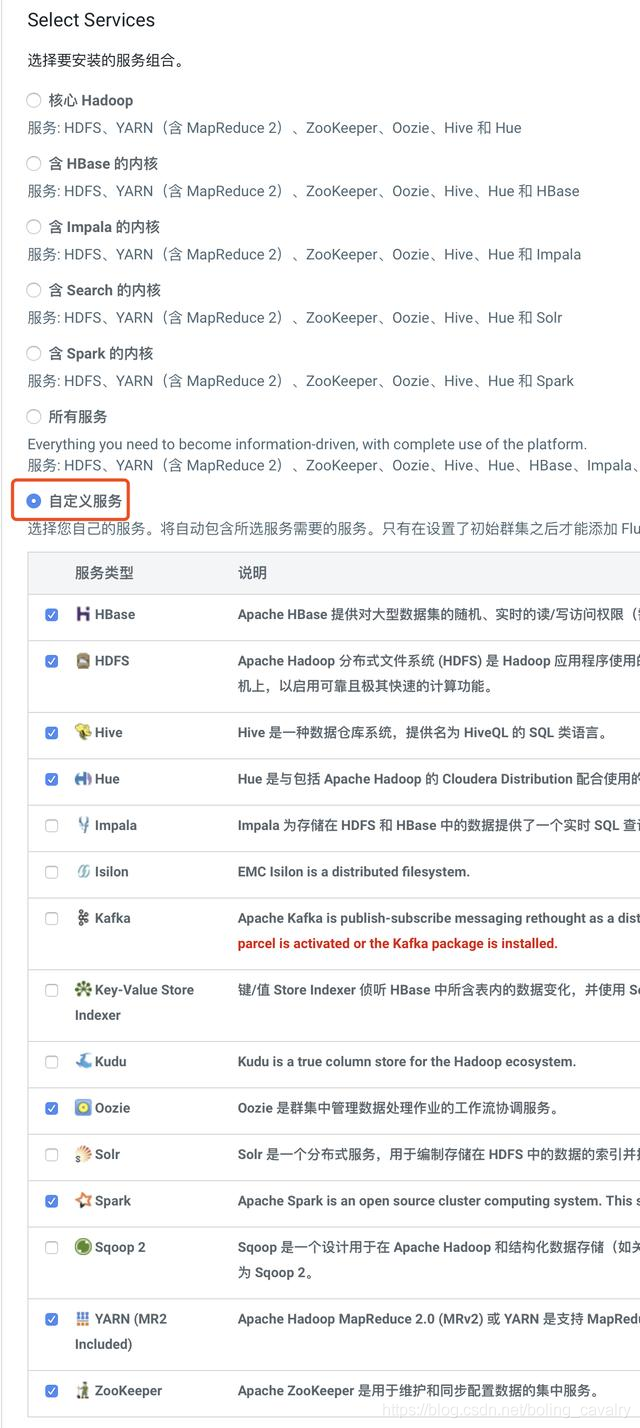
- 在选择主机的页面,都选择CDH服务器:
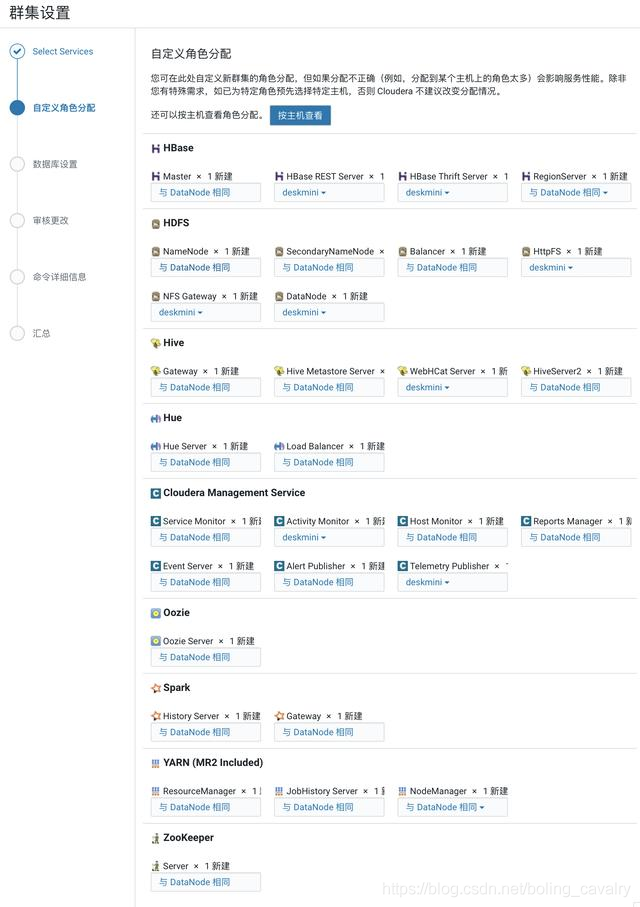
- 接下来是数据库设置的页面,您填写的内容必须与下图保持一致,即主机名为localhost,Hive的数据库、用户、密码都是hive,Activity Monitor的数据库、用户、密码都是amon,Reports Manager的数据库、用户、密码都是rman,Oozie Server的数据库、用户、密码都是oozie,Hue的数据库、用户、密码都是hue,这些内容在ansible脚本中已经固定了,此处的填写必须保持一致:

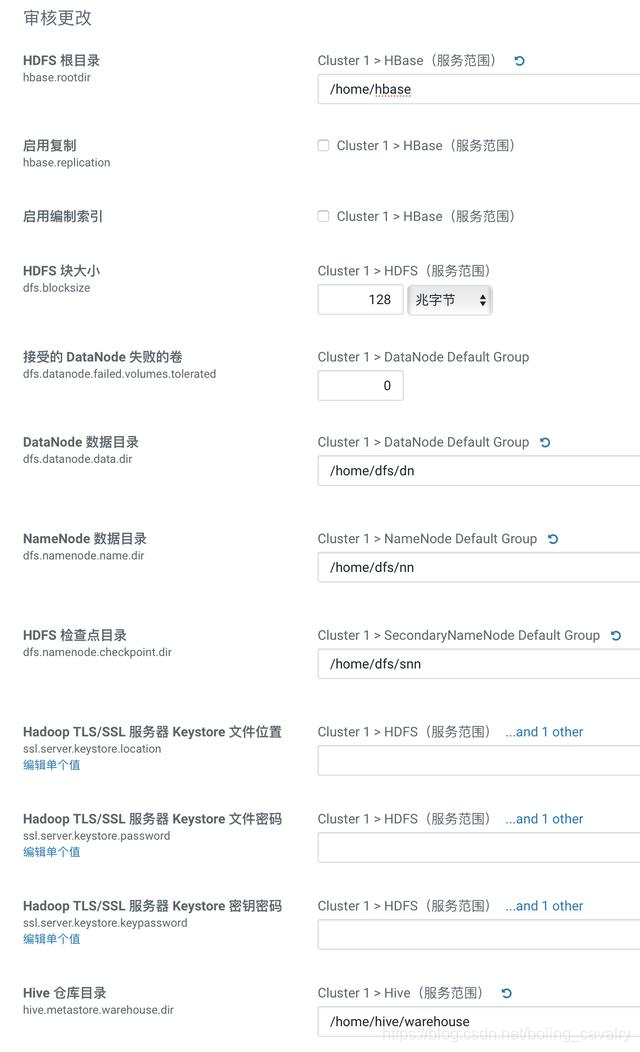
- 在设置参数的页面,请按照您的硬盘实际情况设置,我这里/home目录下空间充足,因此存储位置都改为/home目录下:
- 等待服务启动:
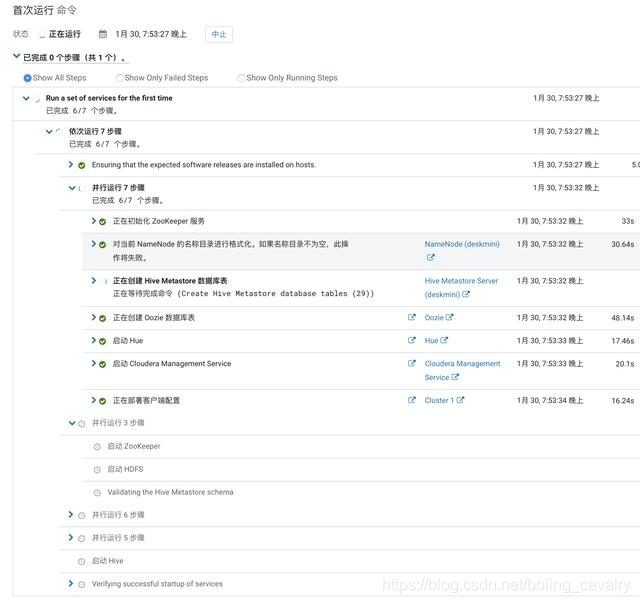
- 各服务启动完成:
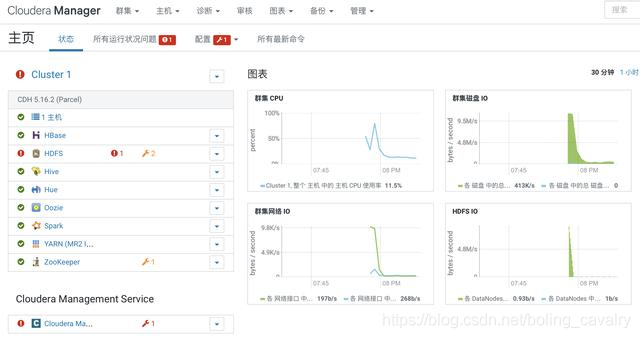
HDFS设置
- 如下图红框所示,HDFS服务存在问题:
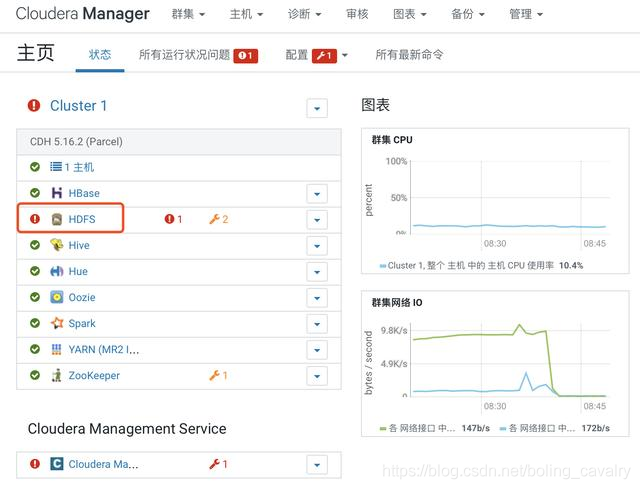
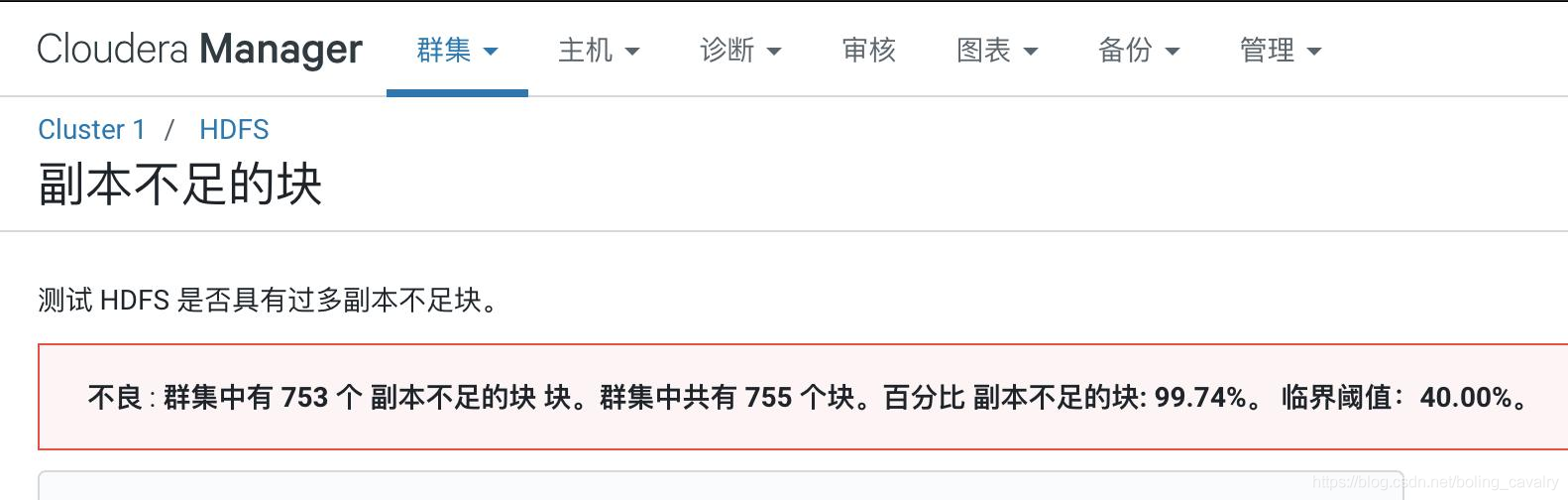
- 点击上图中红色感叹号可见问题详情,如下图,是常见的副本问题:
- 操作如下图,在HDFS的参数设置页面,将dfs.replication的值设置为1(只有一个数据节点):
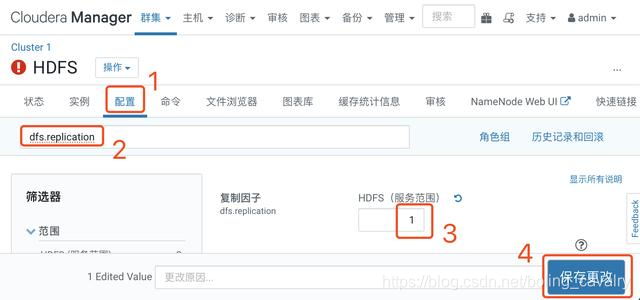
- 经过上述设置,副本数已经调整为1,但是已有文件的副本数还没有同步,需要重新做设置,SSH登录到CDH服务器上;
- 执行命令su - hdfs切换到hdfs账号,再执行以下命令即可完成副本数设置:
hadoop fs -setrep -R 1 /
- 回到网页,重启HDFS服务,如下图:
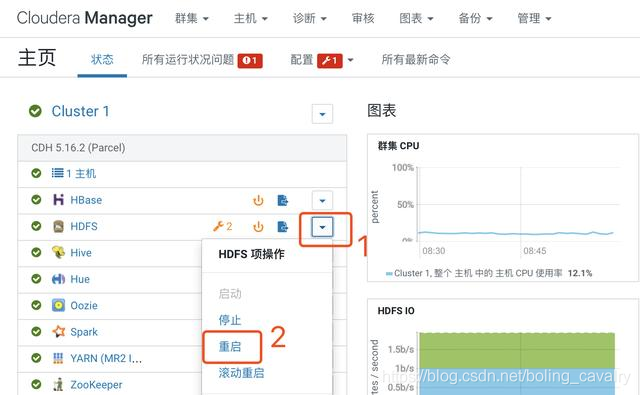
- 重启后HDFS服务正常:
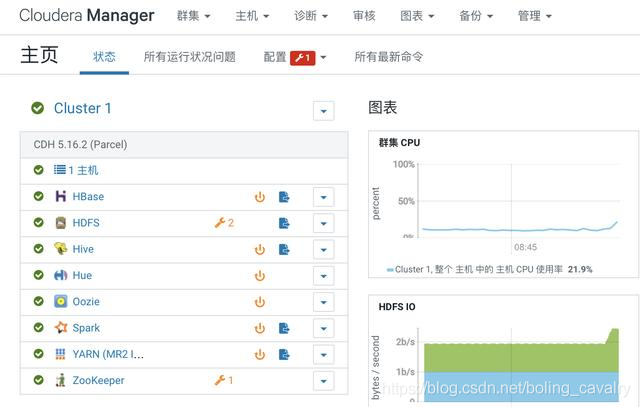
YARN设置
默认的YARN参数是非常保守的,需要做一些设置才能顺利执行Spark任务:
- 进入YARN管理页;
- 如下图所示,检查参数yarn.nodemanager.resource.cpu-vcores的值,该值必须大于1,否则提交Spark任务后YARN不分配资源执行任务,(如果您的CDH服务器是虚拟机,当CPU只有单核时,则此参数就会被设置为1,解决办法是先提升虚拟机CPU核数,再来修改此参数):
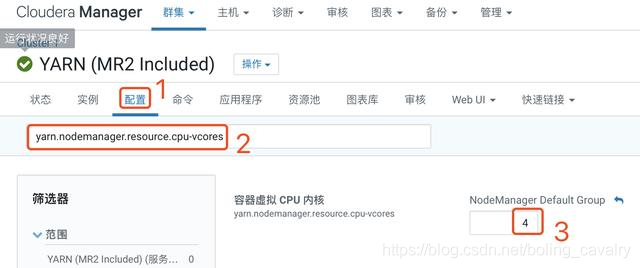
- yarn.scheduler.minimum-allocation-mb:单个容器可申请的最小内存,我这里设置为1G
- yarn.scheduler.maximum-allocation-mb:单个容器可申请的最大内存,我这里设置为8G
- yarn.nodemanager.resource.memory-mb:节点最大可用内存,我这里设置为8G
- 上述三个参数的值,是基于我的CDH服务器有32G内存的背景,请您按照自己硬件资源自行调整;
- 设置完毕后重启YARN服务,操作如下图所示:
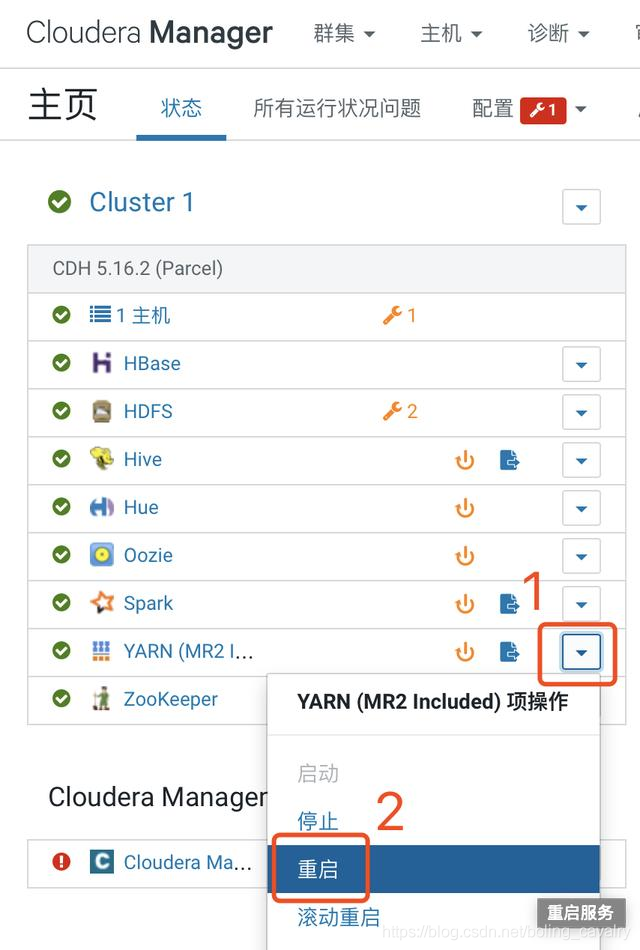
Spark设置(CDH服务器)
需要在Spark环境准备一个目录以及相关的jar,否则Kylin启动会报错(提示spark not found, set SPARK_HOME, or run bin/download-spark.sh),以root身份SSH登录CDH服务器,执行以下命令:
mkdir $SPARK_HOME/jars \
&& cp $SPARK_HOME/assembly/lib/*.jar $SPARK_HOME/jars/ \
&& chmod -R 777 $SPARK_HOME/jars
启动Kylin(CDH服务器)
- SSH登录CDH服务器,执行su - hdfs切换到hdfs账号;
- 按照官方推荐,先执行检查环境的命令:$KYLIN_HOME/bin/check-env.sh
- 检查通过的话控制台输出如下:

- 启动Kylin:$KYLIN_HOME/bin/kylin.sh start
- 控制台输出以下内容说明启动Kylin成功:
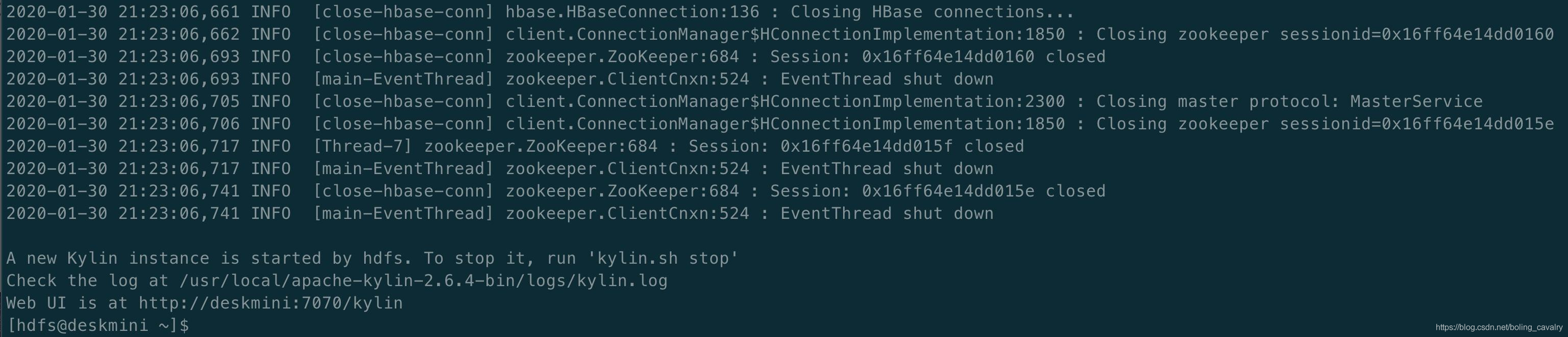
登录Kylin
- 浏览器访问:http://192.168.50.134:7070/kylin,如下图,账号ADMIN,密码KYLIN(账号和密码都是大写):
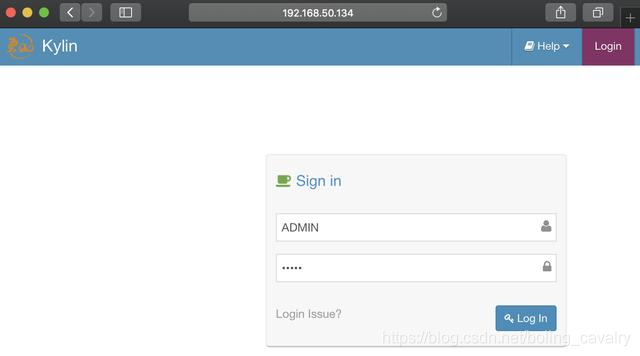
- 登录成功,可以使用了:
至此,CDH和Kylin的部署、设置、启动都已完成,Kylin已经可用了,在下一篇文章中,我们就在此环境运行Kylin的官方demo,体验Kylin;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
CDH+Kylin三部曲之二:部署和设置的更多相关文章
- CDH+Kylin三部曲之三:Kylin官方demo
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- CDH+Kylin三部曲之一:准备工作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- CDH5部署三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink on Yarn三部曲之二:部署和设置
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- kubernetes下的Nginx加Tomcat三部曲之二:细说开发
本文是<kubernetes下的Nginx加Tomcat三部曲>的第二章,在<kubernetes下的Nginx加Tomcat三部曲之一:极速体验>一文我们快速部署了Nginx ...
- 手把手教从零开始在GitHub上使用Hexo搭建博客教程(二)-Hexo参数设置
前言 前文手把手教从零开始在GitHub上使用Hexo搭建博客教程(一)-附GitHub注册及配置介绍了github注册.git相关设置以及hexo基本操作. 本文主要介绍一下hexo的常用参数设置. ...
- [原]CentOS7安装Rancher2.1并部署kubernetes (二)---部署kubernetes
################## Rancher v2.1.7 + Kubernetes 1.13.4 ################ ##################### ...
- Docker下实战zabbix三部曲之二:监控其他机器
在上一章<Docker下实战zabbix三部曲之一:极速体验>中,我们快速安装了zabbix server,并登录管理页面查看了zabbix server所在机器的监控信息,但是在实际场景 ...
- Flink的DataSource三部曲之二:内置connector
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- JVM运行时数据区--Java虚拟机栈
虚拟机栈的背景 由于跨平台性的设计,java的指令都是根据栈来设计的.不同平台CPU架构不同,所以不能设计为基于寄存器的. 根据栈设计的优点是跨平台,指令集小,编译器容易实现,缺点是性能下降,实现同样 ...
- python自动保存百度网盘资源,一定要看
觉得有帮助的别忘了关注一下知识图谱与大数据公众号 开始 在上一文中,我们保存了百度云盘的地址和提取码,但是这种分享链接很容易被屏蔽,最好的做法就是保存资源到自己的网盘,不过采集的链接有上万个,人肉保存 ...
- Win10 搭建FTP环境,并使用Java实现上传,下载,删除
测试的环境一般都是在自己电脑上面装的,现在一般都使用Win10开发 搭建FTP: 第一步:打开控制面板:点击程序 第二步: 第三步: 然后点击确认后等待完成 完成后在启动中找到IIS管理器 打开 在网 ...
- PyCharm2018.3.5下载和安装及永久破解详解(成功案例)
靓仔靓女,你是否在网上找了很多的方法都破解不了PyCharm,是有原因的!无论什么编程工具都不要下载近一到/两年内的版本,人家即把网上的一些破解方法修复了,而且还在测试阶段,不稳定就完事了我装的是20 ...
- 提交 linux kernel 补丁流程备忘录
1. 订阅 linux 邮件列表 linux 邮件列表 Kernel Mailing Lists 是所有 linux kernel 开源贡献者协同工作的平台,可以通过向 VGER.KERNEL.ORG ...
- is_mobile()判断手机移动设备
is_mobile()判断手机移动设备.md is_mobile()判断手机移动设备 制作响应式主题时会根据不同的设备推送不同的内容,是基于移动设备网络带宽压力,避免全局接收pc端内容. functi ...
- log4net 纯代码配置
当需要输出的日志很多的时候,每次修改config都很麻烦,于是想可不可以动态生成. 网上找的案例都是获取单个appender/logger的,此处例子是任意logger,appender相同 log4 ...
- 软件定义网络实验记录⑤--OpenFlow 协议分析和 OpenDaylight 安装
一.实验目的 回顾 JDK 安装配置,了解 OpenDaylight 控制的安装,以及 Mininet 如何连接: 通过抓包获取 OpenFlow 协议,验证 OpenFlow 协议和版本,了解协议内 ...
- 普利姆算法(prim)
普利姆算法(prim)求最小生成树(MST)过程详解 (原网址) 1 2 3 4 5 6 7 分步阅读 生活中最小生成树的应用十分广泛,比如:要连通n个城市需要n-1条边线路,那么怎么样建设才能使工程 ...
- 031 01 Android 零基础入门 01 Java基础语法 03 Java运算符 11 运算符的优先级
031 01 Android 零基础入门 01 Java基础语法 03 Java运算符 11 运算符的优先级 本文知识点:Java中运算符的优先级 运算符的优先级问题 前面学习了很多的运算符,如果这些 ...