(Sqlserver)sql求连续问题
题目一:
create table etltable(
name varchar(20) ,
seq int,
money int); create table etltarget (
name varchar(20),
min_s int,
max_s int,
sum_money int); insert into etltable values
('A',1,100),
('A',2,200),
('A',3,300),
('A',8,400),
('A',9,500),
('B',1,100),
('B',2,500),
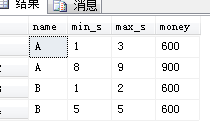
('B',5,600); 目标表结果应该是这样
A 1 3 600
A 8 9 900
B 1 2 600
B 5 5 600 解答:
select name,
min(seq) as min_s,
max(seq) as max_s,
sum(money) as money
from (
select
*,
seq-row_number() over (partition by name order by name) as rn2--连续的差值会相同
from etltable
) a group by name,rn2--连续的差值相同,按照这个分组即可
order by name
题目二:
with aa
as (
select 1 uid, '2015-6-1 8:20:00' as login_time union all
select 1 uid, '2015-6-2 7:20:05' as login_time union all
select 1 uid, '2015-6-3 21:20:30' as login_time union all
select 2 uid, '2015-6-1 8:10:00' as login_time union all
select 2 uid, '2015-6-3 8:20:00' as login_time union all
select 2 uid, '2015-6-4 18:20:00' as login_time union all
select 1 uid, '2015-6-5 9:20:00' as login_time union all
select 1 uid, '2015-6-6 16:20:00' as login_time union all
select 3 uid, '2015-6-1 8:20:00' as login_time union all
select 1 uid, '2015-6-7 12:20:00' as login_time union all
select 1 uid, '2015-6-8 23:20:00' as login_time union all
select 3 uid, '2015-6-2 8:20:00' as login_time union all
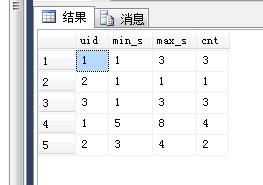
select 3 uid, '2015-6-3 2:20:00' as login_time ) select
uid,min(ds) as min_s,max(ds) as max_s,sum(1) cnt
from (
select * ,
day(login_time) ds,
day(login_time)-row_number() over (partition by uid order by login_time) as rn
from aa
) a
group by uid,rn
(Sqlserver)sql求连续问题的更多相关文章
- 求连续出现5次以上的值,并且取第5次所在id
关键字:求连续出现5次以上的值,并且取第5次所在id 关键字:求在某列连续出现N次值的的数据,并且取第M次出现所在行 需求,求连续出现5次以上的值,并且取第5次所在id SQL SERVER: --测 ...
- 求连续最大子序列积 - leetcode. 152 Maximum Product Subarray
题目链接:Maximum Product Subarray solutions同步在github 题目很简单,给一个数组,求一个连续的子数组,使得数组元素之积最大.这是求连续最大子序列和的加强版,我们 ...
- Sqlserver Sql Agent Job 只能同时有一个实例运行
Sqlserver Sql Agent中的Job默认情况下只能有一个实例在运行,也就是说假如你的Sql Agent里面有一个正在运行的Job叫"Test Job",如果你现在再去启 ...
- 用SQL求1到N的质数和
今天在百度知道中,遇到了一位朋友求助:利用sql求1到1000的质数和.再说今天周五下午比较悠闲,我就在MSSQL 2008中写了出来,现在分享在博客中,下面直接贴代码: declare @num i ...
- 求连续数字的和------------------------------用while的算法思想
前端代码: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.as ...
- SQLSERVER SQL性能优化技巧
这篇文章主要介绍了SQLSERVER SQL性能优化技巧,需要的朋友可以参考下 1.选择最有效率的表名顺序(只在基于规则的优化器中有效) SQLSERVER的解析器按照从右到左的顺序处理F ...
- sqlserver sql优化案例及思路
始sql: SELECT TOP 100 PERCENT ZZ.CREW_NAME AS 机组, ZZ.CREW_ID, AA.年度时间, CC.当月时间, DD.连续七天时间 AS 最近七天 FRO ...
- 一个SQL查询连续三天的流量100以上的数据值【SQql Server】
题目 有一个商场,每日人流量信息被记录在这三列信息中:序号 (id).日期 (date). 人流量 (people).请编写一个查询语句,找出高峰期时段,要求连续三天及以上,并且每天人流量均不少于10 ...
- sql求日期
2.求以下日期SQL: 昨天 select convert(varchar(10),getdate() - 1,120) 明天 select convert(varchar(10),getdate() ...
随机推荐
- 【红日安全-VulnStack】ATT&CK实战系列——红队实战(二)
一.环境搭建 1.1 靶场下载 靶场下载地址:http://vulnstack.qiyuanxuetang.net/vuln/detail/3/ 靶机通用密码: 1qaz@WSX 1.2 环境配置 ...
- Android 音视频开发(一):PCM 格式音频的播放与采集
什么是 PCM 格式 声音从模拟信号转化为数字信号的技术,经过采样.量化.编码三个过程将模拟信号数字化. 采样 顾名思义,对模拟信号采集样本,该过程是从时间上对信号进行数字化,例如每秒采集 44100 ...
- 轻松上手CSS Grid网格布局
今天刚好要做一个好多div格子错落组成的布局,不是田字格,不是九宫格,12个格子这样子,看起来有点复杂.关键的是笔者有点懒,要写那么多div和css真是不想下手啊.多看了两眼,这布局不跟网格挺像吗?c ...
- leetcode Add to List 31. Next Permutation找到数组在它的全排列中的下一个
直接上代码 public class Solution { /* 做法是倒着遍历数组,目标是找到一个数比它前边的数大(即这个数后边的是降序排列),如果找到了那么这个数前边的那个数就是需要改变的最高位, ...
- SpringBoot默认首页配置
@Configuration public class DefaultView extends WebMvcConfigurerAdapter { @Override public void addV ...
- Java中jna的用法
(1)jna是对jni的封装,让java使用者能更好的使用本地的动态库 (2)使用jna需要下载jna的jar包,该jar包就是对jni的封装,所以在调用效率上来讲,jna是要比jni低一点的,不过对 ...
- 使用ImmutableMap简化语句
项目实战 最近接了一个出行权益的需求,回调的状态有十几种,需要转换为进行中,取消,已完成几种状态进行订单状态的展示,使用ImmutableMap可以简化语句,替代使用if-else 语句或者switc ...
- LeetCode232 用栈实现队列
使用栈实现队列的下列操作: push(x) -- 将一个元素放入队列的尾部. pop() -- 从队列首部移除元素. peek() -- 返回队列首部的元素. empty() -- 返回队列是否为空. ...
- ActiceMQ详解
1. MQ理解 1.1 MQ的产品种类和对比 MQ即消息中间件.MQ是一种理念,ActiveMQ是MQ的落地产品. 消息中间件产品 各类MQ对比 Kafka 编程语言:Scala 大数据领域的主流MQ ...
- Docker Hub公共镜像仓库的使用
创建账号并登陆这里是登陆入口 登陆账号 登陆进入之后里面目前仓库,现在去创建一个 下面我选的是公共仓库,别人也可以访问到 在服务器上登陆进来,进行上传镜像到仓库 [root@docker ~]# do ...