等待 Redis 应答 Redis pipeline It's not just a matter of RTT
小结:
1、When pipelining is used, many commands are usually read with a single read() system call, and multiple replies are delivered with a single write() system call.
Using pipelining to speedup Redis queries – Redis https://redis.io/topics/pipelining
Using pipelining to speedup Redis queries
Request/Response protocols and RTT
Redis is a TCP server using the client-server model and what is called a Request/Response protocol.
This means that usually a request is accomplished with the following steps:
- The client sends a query to the server, and reads from the socket, usually in a blocking way, for the server response.
- The server processes the command and sends the response back to the client.
So for instance a four commands sequence is something like this:
- Client: INCR X
- Server: 1
- Client: INCR X
- Server: 2
- Client: INCR X
- Server: 3
- Client: INCR X
- Server: 4
Clients and Servers are connected via a networking link. Such a link can be very fast (a loopback interface) or very slow (a connection established over the Internet with many hops between the two hosts). Whatever the network latency is, there is a time for the packets to travel from the client to the server, and back from the server to the client to carry the reply.
This time is called RTT (Round Trip Time). It is very easy to see how this can affect the performances when a client needs to perform many requests in a row (for instance adding many elements to the same list, or populating a database with many keys). For instance if the RTT time is 250 milliseconds (in the case of a very slow link over the Internet), even if the server is able to process 100k requests per second, we'll be able to process at max four requests per second.
If the interface used is a loopback interface, the RTT is much shorter (for instance my host reports 0,044 milliseconds pinging 127.0.0.1), but it is still a lot if you need to perform many writes in a row.
Fortunately there is a way to improve this use case.
Redis Pipelining
A Request/Response server can be implemented so that it is able to process new requests even if the client didn't already read the old responses. This way it is possible to send multiple commands to the server without waiting for the replies at all, and finally read the replies in a single step.
This is called pipelining, and is a technique widely in use since many decades. For instance many POP3 protocol implementations already supported this feature, dramatically speeding up the process of downloading new emails from the server.
Redis has supported pipelining since the very early days, so whatever version you are running, you can use pipelining with Redis. This is an example using the raw netcat utility:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
This time we are not paying the cost of RTT for every call, but just one time for the three commands.
To be very explicit, with pipelining the order of operations of our very first example will be the following:
- Client: INCR X
- Client: INCR X
- Client: INCR X
- Client: INCR X
- Server: 1
- Server: 2
- Server: 3
- Server: 4
IMPORTANT NOTE: While the client sends commands using pipelining, the server will be forced to queue the replies, using memory. So if you need to send a lot of commands with pipelining, it is better to send them as batches having a reasonable number, for instance 10k commands, read the replies, and then send another 10k commands again, and so forth. The speed will be nearly the same, but the additional memory used will be at max the amount needed to queue the replies for these 10k commands.
It's not just a matter of RTT
Pipelining is not just a way in order to reduce the latency cost due to the round trip time, it actually improves by a huge amount the total operations you can perform per second in a given Redis server. This is the result of the fact that, without using pipelining, serving each command is very cheap from the point of view of accessing the data structures and producing the reply, but it is very costly from the point of view of doing the socket I/O. This involves calling the read() and write() syscall, that means going from user land to kernel land. The context switch is a huge speed penalty.
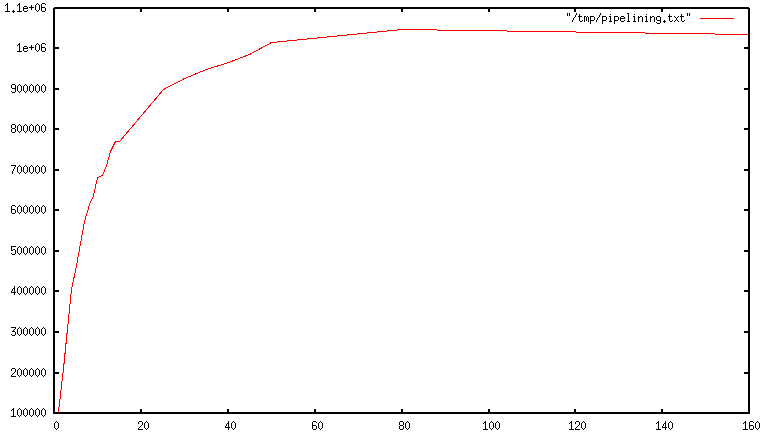
When pipelining is used, many commands are usually read with a single read() system call, and multiple replies are delivered with a single write() system call. Because of this, the number of total queries performed per second initially increases almost linearly with longer pipelines, and eventually reaches 10 times the baseline obtained not using pipelining, as you can see from the following graph:
Some real world code example
In the following benchmark we'll use the Redis Ruby client, supporting pipelining, to test the speed improvement due to pipelining:
require 'rubygems'
require 'redis'
def bench(descr)
start = Time.now
yield
puts "#{descr} #{Time.now-start} seconds"
end
def without_pipelining
r = Redis.new
10000.times {
r.ping
}
end
def with_pipelining
r = Redis.new
r.pipelined {
10000.times {
r.ping
}
}
end
bench("without pipelining") {
without_pipelining
}
bench("with pipelining") {
with_pipelining
}
Running the above simple script will provide the following figures in my Mac OS X system, running over the loopback interface, where pipelining will provide the smallest improvement as the RTT is already pretty low:
without pipelining 1.185238 seconds
with pipelining 0.250783 seconds
As you can see, using pipelining, we improved the transfer by a factor of five.
Pipelining VS Scripting
Using Redis scripting (available in Redis version 2.6 or greater) a number of use cases for pipelining can be addressed more efficiently using scripts that perform a lot of the work needed at the server side. A big advantage of scripting is that it is able to both read and write data with minimal latency, making operations like read, compute, write very fast (pipelining can't help in this scenario since the client needs the reply of the read command before it can call the write command).
Sometimes the application may also want to send EVAL or EVALSHA commands in a pipeline. This is entirely possible and Redis explicitly supports it with the SCRIPT LOAD command (it guarantees that EVALSHA can be called without the risk of failing).
Appendix: Why are busy loops slow even on the loopback interface?
Even with all the background covered in this page, you may still wonder why a Redis benchmark like the following (in pseudo code), is slow even when executed in the loopback interface, when the server and the client are running in the same physical machine:
FOR-ONE-SECOND:
Redis.SET("foo","bar")
END
After all if both the Redis process and the benchmark are running in the same box, isn't this just messages copied via memory from one place to another without any actual latency and actual networking involved?
The reason is that processes in a system are not always running, actually it is the kernel scheduler that let the process run, so what happens is that, for instance, the benchmark is allowed to run, reads the reply from the Redis server (related to the last command executed), and writes a new command. The command is now in the loopback interface buffer, but in order to be read by the server, the kernel should schedule the server process (currently blocked in a system call) to run, and so forth. So in practical terms the loopback interface still involves network-alike latency, because of how the kernel scheduler works.
Basically a busy loop benchmark is the silliest thing that can be done when metering performances in a networked server. The wise thing is just avoiding benchmarking in this way.
https://mp.weixin.qq.com/s/Yv3FJghKtmZ-RKUORuxpMw
云测评 | Redis-pipeline对于性能的提升究竟有多大?
首先来介绍一下今天的主角——Redis Pipelining。该功能是为了解决因为客户端和服务器的网络延迟造成的请求延迟。
Redis Pipelining在很早就出现了,如果你在用较早版本的Redis,那么也能使用这个功能。此功能可以将一系列请求连续发送到Server端,不必等待Server端的返回,而Server端会将请求放进一个有序的管道中,在执行完成后,会一次性将返回值再发送回来。
对于这么神奇的功能,我们怎么能不测一下pipeline对于性能的提升有多大呢?
一、pipeline有多神奇
测试方法:对redis分别用顺序写入和pipeline 的方法写入一个微秒级的时间戳,一共写1W个数据,去看这1W 条数据的执行时间。
测试结果:pipeline写入与顺序写入的所消耗的时间对比。
分析:pipeline和顺序写入最大的区别就是在于pipeline的打包发送数据,网络开销要小很多。在下面的测试中,values很小(20+Byte),而且网络开销也不算大(同乐访问坪山),访问命令也不重(set),但是执行的效率却是天差地别,顺序写入的执行时间是pipeline的16.8倍!而在现网环境下,随着网络开销的增大,values值的增大,重命令的增加,这个比例将变得更加恐怖。
二、对于pipeline读延时问题的优化
腾讯天天快报业务在使用Redis方面非常专业,在批量导入数据的时候就是使用了pipeline,使得数据能够快速的导入。但是在运营过程中我们发现,pipeline一次打包大量的写入的命令阻塞了同proxy的其他业务的读命令,使得其他业务的读命令延时升高。这个时候就不得不想办法优化这个问题。
首先贴出结论:
建议在pipeline写入的时候,参照“打小包,短sleep的”策略写入。这样能够避免pipeline写入时,由于阻塞造成的读延时问题。
为了测试的全面考虑,我们增大了读命令的qps,读命令和写命令都仅有一点点的延时升高,这个是可以接受的。
所以在使用pipeline的时候,参照“打小包,短sleep的”策略,是一个可以选择的方式。
三、测试总结
get set 命令
在get_qps = 6000的时候,pipeline一次打包1000个set命令,每个val大小1K,sleep=0 得到的读写速度都不错,在不算网络开销的情况下,get速度在0.1ms ,set 速度在1ms。
Redis 更加友好的 Pipeline API · Issue #20 · go-kratos/kratos https://github.com/go-kratos/kratos/issues/20
Redis pipeline - 知乎 https://zhuanlan.zhihu.com/p/58608323
mq消息合并:由于mq请求发出到响应的时间,即往返时间, RTT(Round Time Trip),每次提交都要消耗RTT,不支持类似redis的pipeline机制。
Redis pipeline

关于 Redis pipeline
为什么需要 pipeline ?
Redis 的工作过程是基于 请求/响应 模式的。正常情况下,客户端发送一个命令,等待 Redis 应答;Redis 接收到命令,处理后应答。请求发出到响应的时间叫做往返时间,即 RTT(Round Time Trip)。在这种情况下,如果需要执行大量的命令,就需要等待上一条命令应答后再执行。这中间不仅仅多了许多次 RTT,而且还频繁的调用系统 IO,发送网络请求。为了提升效率,pipeline 出现了,它允许客户端可以一次发送多条命令,而不等待上一条命令执行的结果。
实现思路
客户端首先将执行的命令写入到缓冲区中,最后再一次性发送 Redis。但是有一种情况就是,缓冲区的大小是有限制的:如果命令数据太大,可能会有多次发送的过程,但是仍不会处理 Redis 的应答。
实现原理
要支持 pipeline,既要服务端的支持,也要客户端支持。对于服务端来说,所需要的是能够处理一个客户端通过同一个 TCP 连接发来的多个命令。可以理解为,这里将多个命令切分,和处理单个命令一样。对于客户端,则是要将多个命令缓存起来,缓冲区满了就发送,然后再写缓冲,最后才处理 Redis 的应答。
Redis pipeline 的参考资料
在 SpringBoot 中使用 Redis pipeline
基于 SpringBoot 的自动配置,在使用 Redis 时只需要在 pom 文件中给出 spring-boot-starter-data-redis 依赖,就可以直接使用 Spring Data Redis。关于 Redis pipeline 的使用方法,可以阅读 Spring Data Redis 给出的解释。下面,我给出一个简单的例子:
import com.imooc.ad.Application;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.dao.DataAccessException;
import org.springframework.data.redis.connection.StringRedisConnection;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisOperations;
import org.springframework.data.redis.core.SessionCallback;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.test.context.junit4.SpringRunner;
/**
* <h1>Redis Pipeline 功能测试用例</h1>
* 参考: https://docs.spring.io/spring-data/redis/docs/1.8.1.RELEASE/reference/html/#redis:template
* Created by Qinyi.
*/
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {Application.class}, webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class RedisPipelineTest {
/** 注入 StringRedisTemplate, 使用默认配置 */
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
@SuppressWarnings("all")
public void testExecutePipelined() {
// 使用 RedisCallback 把命令放在 pipeline 中
RedisCallback<Object> redisCallback = connection -> {
StringRedisConnection stringRedisConn = (StringRedisConnection) connection;
for (int i = 0; i != 10; ++i) {
stringRedisConn.set(String.valueOf(i), String.valueOf(i));
}
return null; // 这里必须要返回 null
};
// 使用 SessionCallback 把命令放在 pipeline
SessionCallback<Object> sessionCallback = new SessionCallback<Object>() {
@Override
public Object execute(RedisOperations operations) throws DataAccessException {
operations.opsForValue().set("name", "qinyi");
operations.opsForValue().set("gender", "male");
operations.opsForValue().set("age", "19");
return null;
}
};
System.out.println(stringRedisTemplate.executePipelined(redisCallback));
System.out.println(stringRedisTemplate.executePipelined(sessionCallback));
}
}总结:Redis pipeline 的特性以及使用时需要注意的地方
- pipeline 减少了 RTT,也减少了IO调用次数(IO 调用涉及到用户态到内核态之间的切换)
- 如果某一次需要执行大量的命令,不能放到一个 pipeline 中执行。数据量过多,网络传输延迟会增加,且会消耗 Redis 大量的内存。应该将大量的命令切分为多个 pipeline 分别执行。
等待 Redis 应答 Redis pipeline It's not just a matter of RTT的更多相关文章
- 等待 Redis 应答
https://zhuanlan.zhihu.com/p/58608323 mq消息合并:由于mq请求发出到响应的时间,即往返时间, RTT(Round Time Trip),每次提交都要消耗RTT, ...
- Redis 新特性---pipeline(管道)
转载自http://weipengfei.blog.51cto.com/1511707/1215042 Redis本身是一个cs模式的tcp server, client可以通过一个socket连续发 ...
- redis学习笔记 - Pipeline与事务
原文 Redis提供了5种数据结构,但除此之外,Redis还提供了注入慢查询分析,Redis Shell.Pipeline.事务.与Lua脚本.Bitmaps.HyperLogLog.PubSub.G ...
- Jedis客户端即redis中的pipeline批量操作
关注公众号:CoderBuff,回复"redis"获取<Redis5.x入门教程>完整版PDF. <Redis5.x入门教程>目录 第一章 · 准备工作 第 ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- redis/php redis扩展 安装
作者:silenceper 日期:2013-10-03 原文地址: http://silenceper.com/archives/952.html 我是在CentOS 6.3 中进行的. 使用到的软件 ...
- 【Redis】Redis的基本安装及使用
在Linux上安装Redis Redis的安装很简单.基本上是下载.解压.运行安装脚本.我用的Redis版本是3.2.1. [nicchagil@localhost app]$ wget -q htt ...
- vagrant系列教程(四):vagrant搭建redis与redis的监控程序redis-stat(转)
上一篇php7环境的搭建 真是火爆,仅仅两天时间,就破了我之前swagger系列的一片文章,看来,大家对搭建环境真是情有独钟. 为了访问量,我今天再来一篇Redis的搭建.当然不能仅仅是redis的搭 ...
- Redis学习——Redis事务
Redis和传统的关系型数据库一样,因为具有持久化的功能,所以也有事务的功能! 有关事务相关的概念和介绍,这里就不做介绍. 在学习Redis的事务之前,首先抛出一个面试的问题. 面试官:请问Redis ...
随机推荐
- vue3.0自定义指令(drectives)
在大多数情况下,你都可以操作数据来修改视图,或者反之.但是还是避免不了偶尔要操作原生 DOM,这时候,你就能用到自定义指令. 举个例子,你想让页面的文本框自动聚焦,在没有学习自定义指令的时候,我们可能 ...
- spring-quartz整合
摘要 spring ,springboot整合quartz-2.3.2,实现spring管理jobBean 本文不涉及 JDBC存储的方式,springboot yml配置也没有 可自行百度 谷歌 本 ...
- 机器学习 第4篇:数据预处理(sklearn 插补缺失值)
由于各种原因,现实世界中的许多数据集都包含缺失值,通常把缺失值编码为空白,NaN或其他占位符.但是,此类数据集与scikit-learn估计器不兼容,这是因为scikit-learn的估计器假定数组中 ...
- 看完这篇,保证让你真正明白:分布式系统的CAP理论、CAP如何三选二
引言 CAP 理论,相信很多人都听过,它是指: 一个分布式系统最多只能同时满足一致性(Consistency).可用性(Availability)和分区容错性(Partition tolerance) ...
- 用anaconda的pip安装第三方python包
启动anaconda命令窗口: 开始> 所有程序> anaconda> anaconda prompt会得到两行提示: Deactivating environment " ...
- JavaDailyReports10_13
今天完成了课堂测试二的内容要求,开阔了编程的思路,学到了很多程序设计思想,为以后的学习提供了很多帮助. 明天开始继续完善四则运算的程序,并且开始JavaWeb的学习!
- 使用lua+redis解决发多张券的并发问题
前言 公司有一个发券的接口有并发安全问题,下面列出这个问题和解决这个问题的方式. 业务描述 这个接口的作用是给会员发多张券码.涉及到4张主体,分别是:用户,券,券码,用户领取记录. 下面是改造前的伪代 ...
- Mirai qq机器人 c++版sdk(即用c++写mirai)
Mirai机器人c++版 前言 类似教程 本文git,gitee地址 c++开发mirai 原理 大概流程 实现 如何使用 注意事项 常见错误 前言 改分支版本以及过时,暂时不再维护 请看最新版kot ...
- C++把数字排序
C++把数字排序 描述 思路 代码 描述 如题,详细如下: 输入不超过1024个数字,以特殊数字结尾,如(-999),把数字从小到大排序. 思路 目前,我们有两种思路可以写: 1是 在输入的时候,排序 ...
- Navcat连接Mysql报错1521
原因是新版的MySql密码加密算法改变,导致旧版本的Navcat连接报错. 解决方案: 1.升级Navcat 因为只是本地的Mysql,所以没验证这个方法,网传可以,此处不介绍. 2.修改Mysql加 ...