理解Word2Vec
一、简介
Word2vec 是 Word Embedding 的方法之一,属于NLP 领域。它是将词转化为「可计算」「结构化」的向量的过程。它是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec 在整个 NLP 里的位置可以用下图表示:
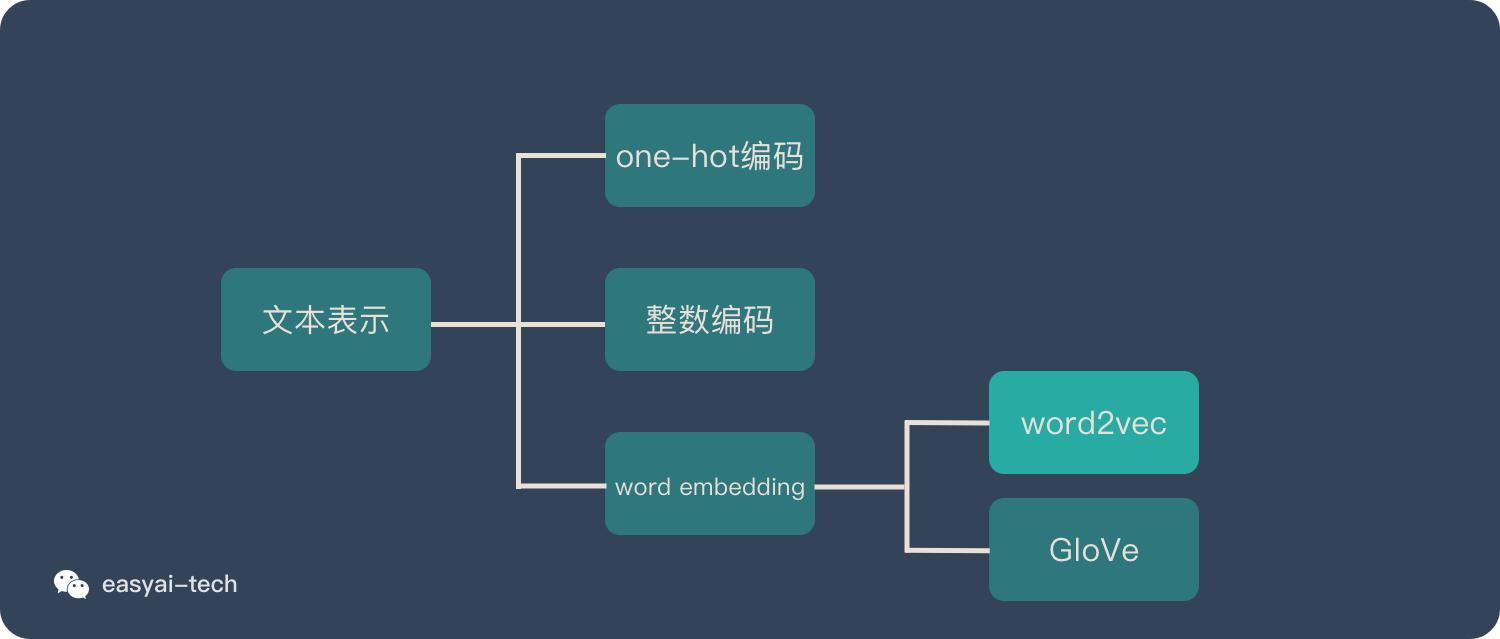
二、词向量(Word Embedding)
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。这一步解决的是“将现实问题转化为数学问题”,是人工智能非常关键的一步。
自然语言处理(NLP)相关任务中,要将自然语言交给机器学习中的算法来处理,通常需要首先将语言数学化,因为机器不是人,机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式了。
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词表示成一个向量。主要有两种表示方式:One-Hot Representation(独热编码) 和 Distributed Representation。
2.1 One-Hot Representation
一种最简单的词向量方式是 One-Hot-Representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置。举个例子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 ···]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 ···]
每个词都是茫茫 0 海中的一个 1。
这种 One-Hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
但这种词表示有两个缺点:(1)容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时;(2)不能很好地刻画词与词之间的相似性(术语好像叫做“词汇鸿沟”):任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
所以会寻求发展,用另外的方式表示,就是下面这种。
2.2 Distributed Representation
另一种就是Distributed Representation 这种表示,它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的缺点。其基本想法是直接用一个普通的向量表示一个词,这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, ···],也就是普通的向量表示形式。维度以 50 维和 100 维比较常见。
当然一个词怎么表示成这样的一个向量是要经过一番训练的,训练方法较多,word2vec是其中一种,在后面会提到,这里先说它的意义。还要注意的是每个词在不同的语料库和不同的训练方法下,得到的词向量可能是不一样的。词向量一般维数不高,很少有人闲着没事训练的时候定义一个10000维以上的维数,所以用起来维数灾难的机会相对于One-Hot representation表示就大大减少了。
由于是用向量表示,而且用较好的训练算法得到的词向量的向量一般是有空间上的意义的,也就是说,将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上的词向量之间的距离度量也可以表示对应的两个词之间的“距离”。所谓两个词之间的“距离”,就是这两个词之间的语法,语义之间的相似性。
一个比较爽的应用方法是,得到词向量后,假如对于某个词A,想找出这个词最相似的词,这个场景对人来说都不轻松,毕竟比较主观,但是对于建立好词向量后的情况,对计算机来说,只要拿这个词的词向量跟其他词的词向量一一计算欧式距离或者cos距离,得到距离最小的那个词,就是它最相似的。这样的特性使得词向量很有意义,自然就会吸引比较多的人去研究,前有Bengio发表在JMLR上的论文《A Neural Probabilistic Language Model》,又有Hinton的层次化Log-Bilinear模型,还有google的TomasMikolov 团队搞的word2vec,等等。词向量在机器翻译领域的一个应用,就是google的TomasMikolov 团队开发了一种词典和术语表的自动生成技术,该技术通过向量空间,把一种语言转变成另一种语言,实验中对英语和西班牙语间的翻译准确率高达90%。
介绍算法工作原理的时候举了一个例子:考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 E 和 S。从英语中取出五个词 one,two,three,four,five,设其在 E 中对应的词向量分别为 v1,v2,v3,v4,v5,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量 u1,u2,u3,u4,u5,在二维平面上将这五个点描出来,如下图左图所示。类似地,在西班牙语中取出(与 one,two,three,four,five 对应的) uno,dos,tres,cuatro,cinco,设其在 S 中对应的词向量分别为 s1,s2,s3,s4,s5,用 PCA 降维后的二维向量分别为 t1,t2,t3,t4,t5,将它们在二维平面上描出来(可能还需作适当的旋转),如下图右图所示:

观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
三、word2vec
word2vec模型其实就是简单化的神经网络。我们就需要训练神经网络语言模型,这个模型的输出我们不关心,我们关心的是模型中第一个隐含层中的参数权重,这个参数矩阵就是我们需要的词向量。

输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words) 与Skip-Gram两种模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。


3.1 CBOW(Continuous Bag-of-Words)
CBOW通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

CBOW的训练模型如下图所示:

1、输入层:上下文单词的one hot. {假设单词向量空间dim为V,上下文单词个数为C}
2、所有one hot分别乘以共享的输入权重矩阵W. {VN矩阵,N为自己设定的数,初始化权重矩阵W}
3、所得的向量 {因为是one hot所以为向量} 相加求平均作为隐层向量, size为1N.
4、乘以输出权重矩阵W' {NV}
5、得到向量 {1V} 激活函数处理得到V-dim概率分布 {PS: 因为是one hot嘛,其中的每一维斗代表着一个单词}
6、概率最大的index所指示的单词为预测出的中间词(target word)与true label的one hot做比较,误差越小越好(根据误差更新权重矩阵)
所以,需要定义loss function(一般为交叉熵代价函数),采用梯度下降算法更新W和W'。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实聪明的你已经看出来了,其实这个look up table就是矩阵W自身),也就是说,任何一个单词的one hot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
举个栗子:

窗口大小是2,表示选取coffe前面两个单词和后面两个单词,作为input词。

假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
3.2 Skip-Gram
从直观上理解,Skip-Gram用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。首先我们选句子中间的一个词作为我们的输入词,例如我们选取“dog”作为input word;有了input word以后,我们再定义一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量。如果我们设置skip_window=2,那么我们最终获得窗口中的词(包括input word在内)就是['The', 'dog','barked', 'at']。skip_window=2代表着选取左input word左侧2个词和右侧2个词进入我们的窗口,所以整个窗口大小span=2x2=4。另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,我们将会得到两组 (input word, output word) 形式的训练数据,即 ('dog', 'barked'),('dog', 'the')。
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。这句话有点绕,我们来看个栗子。第二步中我们在设置skip_window和num_skips=2的情况下获得了两组训练数据。假如我们先拿一组数据 ('dog', 'barked') 来训练神经网络,那么模型通过学习这个训练样本,会告诉我们词汇表中每个单词是“barked”的概率大小。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个栗子,如果我们向神经网络模型中输入一个单词“中国“,那么最终模型的输出概率中,像“英国”, ”俄罗斯“这种相关词的概率将远高于像”苹果“,”蝈蝈“非相关词的概率。因为”英国“,”俄罗斯“在文本中更大可能在”中国“的窗口中出现。我们将通过给神经网络输入文本中成对的单词来训练它完成上面所说的概率计算。
下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。Training Samples(输入, 输出):

再次提醒,最终我们需要的是训练出来的权重矩阵。
四、训练注意事项
我们发现Word2Vec模型是一个超级大的神经网络(权重矩阵规模非常大)。举个栗子,我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入-隐层权重矩阵和隐层-输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难(太凶残了)。
下面主要介绍两种方法优化训练过程:
1、负采样(negative sampling)
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。至于具体的细节我在这里就不在介绍了。
2、层序softmax
层序softmax也是解决这个问题的一种方法。这里也不做详细介绍。
五、总结
最后强调一下,word2vec一个NLP工具,它可以将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。word2vec主要包含两个模型Skip-gram和CBOW。以及两种高效的训练方法负采样,层序softmax。
参考:
https://easyai.tech/ai-definition/word2vec/
https://www.cnblogs.com/sxron/articles/5123790.html
https://blog.csdn.net/yu5064/article/details/79601683
https://www.jianshu.com/p/471d9bfbd72f
理解Word2Vec的更多相关文章
- 理解 Word2Vec 之 Skip-Gram 模型
理解 Word2Vec 之 Skip-Gram 模型 天雨粟 模型师傅 / 果粉 https://zhuanlan.zhihu.com/p/27234078 508 人赞同了该文章 注明:我发现知乎有 ...
- 通俗理解word2vec
https://www.jianshu.com/p/471d9bfbd72f 独热编码 独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有 ...
- 通俗理解word2vec的训练过程
https://www.leiphone.com/news/201706/eV8j3Nu8SMqGBnQB.html https://blog.csdn.net/dn_mug/article/deta ...
- 一步一步理解word2Vec
一.概述 关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术.词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的 ...
- 深入理解Word2Vec
Word2Vec Tutorial - The Skip-Gram Model,Skip-Gram模型的实现原理:http://mccormickml.com/2016/04/19/word2vec- ...
- 对word2vec的理解及资料整理
对word2vec的理解及资料整理 无他,在网上看到好多对word2vec的介绍,当然也有写的比较认真的,但是自己学习过程中还是看了好多才明白,这里按照自己整理梳理一下资料,形成提纲以便学习. 介绍较 ...
- (转)word2vec前世今生
word2vec 前世今生 2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注.首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效 ...
- 深度学习word2vec笔记之算法篇
深度学习word2vec笔记之算法篇 声明: 本文转自推酷中的一篇博文http://www.tuicool.com/articles/fmuyamf,若有错误望海涵 前言 在看word2vec的资料 ...
- word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
随机推荐
- JavaSwing+Mysql实现简单的登录界面+用户是否存在验证
原生Java+mysql登录验证 client login.java 功能:实现登录页面,与服务端传来的数据验证 package LoginRegister; import java.awt.Cont ...
- 关于idea 在创建maven 骨架较慢问题解决
在设置中->maven>runner>VM Options 粘贴 -DarchetypeCatalog=internal 其中 -D archetype:原型,典型的意思 ( ...
- 分类模型的F1-score、Precision和Recall 计算过程
分类模型的F1分值.Precision和Recall 计算过程 引入 通常,我们在评价classifier的性能时使用的是accuracy 考虑在多类分类的背景下 accuracy = (分类正确的样 ...
- three.js 着色器材质之glsl内置函数
郭先生发现在开始学习three.js着色器材质时,我们经常会无从下手,辛苦写下的着色器,也会因莫名的报错而手足无措.原因是着色器材质它涉及到另一种语言–GLSL,只有懂了这个语言,我们才能更好的写出着 ...
- 用 Python 下载抖音无水印视频
说起抖音,大家或多或少应该都接触过,如果大家在上面下载过视频,一定知道我们下载的视频是带有水印的,那么我们有什么方式下载不带水印的视频呢?其实用 Python 就可以做到,下面我们来看一下. 很多人学 ...
- 排查Mysql突然变慢的一次过程
排查Mysql突然变慢的一次过程 上周客户说系统突然变得很慢,而且时不时的蹦出一个 404 和 500,弄得真的是很没面子,而恰巧出问题的时候正在深圳出差,所以一直没有时间 看问题,一直到今天,才算是 ...
- 构造函数原型constructor
对象原型(__proto__)和构造函数原型对象(prototype)里面都有一个属性constructor,constructor我们称为构造函数,因为它指向的是构造函数本身. constructo ...
- Quartz.Net的基础使用方法,多任务执行
接着上面单任务执行的代码做一下简单的扩展 主要看下面这段代码,这是Quartz多任务调度的方法,主要就是围绕这个方法去扩展: // // 摘要: // Schedule all of the give ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
- 太厉害了,阿里大牛居然把Git,GitHub总结的这么全面,撸源码去
“版本控制系统”( Version Control System, vcs)是程序代码管理软件的通称,是用来保存程序文件的修改记录以及历史版本,以便日后查看或是使用.Vcs已经有数十年的发展历史,最早 ...