Agumaster 将爬虫取股票名称代号子系统分出来成agumaster_crawler, 两系统通过RabbitMq连接
agumaster_crawler系统负责启动爬虫取得数据,之后便往队列中推送.
agumaster_crawler系统中pom.xml关于RabbitMq的依赖是:
<!-- RabbitMq -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
agumaster_crawler系统中application.properties文件里对于RabbitMq的设置是:
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
之后,就可以把Sender类写出来:
package com.heyang.agumasterCrawler; import org.springframework.amqp.core.AmqpTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component; @Component
public class Sender {
@Autowired
private AmqpTemplate mqTlt; public void send(String msg) {
this.mqTlt.convertAndSend("stockQueue",msg);
}
}
具体使用Sender类的JUnit测试函数:
@SpringBootTest
class AgumasterCrawlerApplicationTests {
@Autowired
private Sender sender; @Test
void contextLoads() throws Exception {
BaseCrawler crawler=new FenghuangCrawler();
List<Stock> stockList=crawler.getStockList();
ObjectMapper mapper = new ObjectMapper(); for(Stock s:stockList) {
String str=mapper.writeValueAsString(s);
this.sender.send(str);
}
}
}
发送给完毕后,RabbitMq队列的情况:
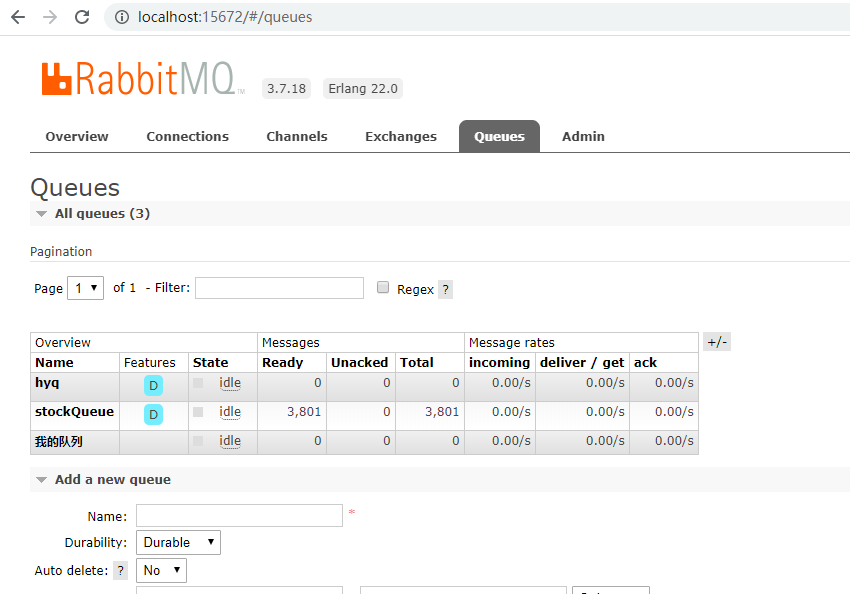
三千八百零一支股票都送到了.
而原有Agumaster系统中,也要添加RabbitMq的依赖,
<!-- RabbitMq -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
这个和上面的是一样的.
之后就可以写接收类了:
package com.ufo.hy.agumaster.mq; import org.springframework.amqp.rabbit.annotation.RabbitHandler;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component; /**
* Used to receive stock code/names
* @author Heyang
*
*/
@Component
@RabbitListener(queues="stockQueue")
public class Receiver {
@RabbitHandler
public void QueueReceive(String receivedMsg) {
System.out.println(receivedMsg);
}
}
这个类在工程Agumaster启动后便会去队列里取得消息回来,下面是部分它取得的消息:
{"id":2790,"code":"600538","name":"国发股份","utime":null,"src":null,"ctime":null}
{"id":2791,"code":"002367","name":"康力电梯","utime":null,"src":null,"ctime":null}
{"id":2792,"code":"600410","name":"华胜天成","utime":null,"src":null,"ctime":null}
{"id":2793,"code":"601007","name":"金陵饭店","utime":null,"src":null,"ctime":null}
{"id":2794,"code":"603955","name":"大千生态","utime":null,"src":null,"ctime":null}
{"id":2795,"code":"300227","name":"光韵达","utime":null,"src":null,"ctime":null}
{"id":2796,"code":"603195","name":"公牛集团","utime":null,"src":null,"ctime":null}
{"id":2797,"code":"000726","name":"鲁 泰A","utime":null,"src":null,"ctime":null}
{"id":2798,"code":"002013","name":"中航机电","utime":null,"src":null,"ctime":null}
{"id":2799,"code":"002868","name":"绿康生化","utime":null,"src":null,"ctime":null}
{"id":2800,"code":"002558","name":"巨人网络","utime":null,"src":null,"ctime":null}
{"id":2801,"code":"002391","name":"长青股份","utime":null,"src":null,"ctime":null}
{"id":2802,"code":"300010","name":"立思辰","utime":null,"src":null,"ctime":null}
{"id":2803,"code":"000902","name":"新洋丰","utime":null,"src":null,"ctime":null}
{"id":2804,"code":"601965","name":"中国汽研","utime":null,"src":null,"ctime":null}
{"id":2805,"code":"300171","name":"东富龙","utime":null,"src":null,"ctime":null}
{"id":2806,"code":"300406","name":"九强生物","utime":null,"src":null,"ctime":null}
{"id":2807,"code":"600857","name":"宁波中百","utime":null,"src":null,"ctime":null}
{"id":2808,"code":"002463","name":"沪电股份","utime":null,"src":null,"ctime":null}
{"id":2809,"code":"002560","name":"通达股份","utime":null,"src":null,"ctime":null}
....
这样做,就用消息系统完成了系统的部分解耦.
--2020年5月9日--
Agumaster 将爬虫取股票名称代号子系统分出来成agumaster_crawler, 两系统通过RabbitMq连接的更多相关文章
- chrome 浏览器的预提取资源机制导致的一个请求发送两次的问题以及ClientAbortException异常
调查一个 pdf 打印报错: ExceptionConverter: org.apache.catalina.connector.ClientAbortException: java.net.Sock ...
- #在FLAT模式下,需要设置flat子网,VM的IP从这个设置的子网中抓取,这时flat_injected需要设置为True,系统才能自动获得IP,如果flat
#在FLAT模式下,需要设置flat子网,VM的IP从这个设置的子网中抓取,这时flat_injected需要设置为True,系统才能自动获得IP,如果flat子网和主机网络是同一网络,网络管理员要注 ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- Python 爬取美女图片,分目录多级存储
最近有个需求:下载https://mm.meiji2.com/网站的图片. 所以简单研究了一下爬虫. 在此整理一下结果,一为自己记录,二给后人一些方向. 爬取结果如图: 整体研究周期 2-3 天, ...
- Python爬取信息管理系统计算学分绩点
试手登录了下我们学校的研究生信息管理系统,自动计算学分绩点 # -*- coding:utf-8 -*- import urllib import urllib2 import re import c ...
- 爬虫如何发现更多的url呢,怎么动态收集新的url连接
大家在做爬虫采集数据的时候很多都会遇到增量采集的问题,有些时候是通过过滤url来进行的,有些是通过爬取网页后再进行分析判断, 以上这些过程也许大部分做爬虫的都会这么做,各位有没有想过, 除了以上的常用 ...
- POJ 1182食物链(分集合以及加权两种解法) 种类并查集的经典
题目链接:http://icpc.njust.edu.cn/Problem/Pku/1182/ 题意:给出动物之间的关系,有几种询问方式,问是真话还是假话. 定义三种偏移关系: x->y 偏移量 ...
- 求取水仙花数 && 将整数分解成质因数
[程序3] 题目:打印出所有的"水仙花数",所谓"水仙花数"是指一个三位数,其各位数字立方和等于该数本身.例如: 153是一个"水仙花数", ...
- Python 爬虫:把廖雪峰教程转换成 PDF 电子书
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天尝试写一个爬虫,将廖雪峰老师的 ...
随机推荐
- GitLab 配置模板
GitLab 配置模板 GitLab 使用模板和参数生成配置文件. 一般来说,我们会通过 gitlab.rb 文件修改配置,例如 Nginx 相关配置. gitlab.rb 只能使用特定的几个 Ngi ...
- 漫画 | 到底是什么让IT人如此苦逼???
写在最后 漫画是有点夸张,不过多少还是有点现实开发过程的影子! 老板很乐观,核心就是三个月上线,至于怎么办那是底下人的事. 产品很无奈,心里盘算着,万万不可在他这一环节耽误了进度,时间这么赶,先出个壳 ...
- 简直骚操作,ThreadLocal还能当缓存用
背景说明 有朋友问我一个关于接口优化的问题,他的优化点很清晰,由于接口中调用了内部很多的 service 去组成了一个完成的业务功能.每个 service 中的逻辑都是独立的,这样就导致了很多查询是重 ...
- Flutter 容器(6) - FractionallySizedBox
FractionallySizedBox 用法与SizedBox类似,只不过FractionallySizedBox的宽高是百分比大小,widthFactor,heightFactor参数就是相对于父 ...
- Android 使用AS编译出错:Error: Duplicate resources
原因在于drawable目录下有重复的文件名!!! 修改其中的一个文件名或者删除其中一张图(或者xml文件)就可以啦~
- ms14-064漏洞复现
本博客最先发布于我的个人博客,如果方便,烦请移步恰醋的小屋查看,谢谢您! 这是我在实验室学习渗透测试的第五个漏洞复现,一个多小时便完成了.学长给的要求只需完成查看靶机信息.在指定位置创建文件夹两项操作 ...
- N叉树的前后序遍历和最大深度
package NTree; import java.util.ArrayList; import java.util.List; /** * N叉树的前后序遍历和最大深度 */ public cla ...
- 蓝牙bluez命令
记录一下自己平时调试蓝牙的命令,后续学习到再添加 sdptool命令: sdptool add SP - 添加SPP: sdptool add --channel=1 DID SP DUN LA ...
- 图数据库对比:Neo4j vs Nebula Graph vs HugeGraph
本文系腾讯云安全团队李航宇.邓昶博撰写 图数据库在挖掘黑灰团伙以及建立安全知识图谱等安全领域有着天然的优势.为了能更好的服务业务,选择一款高效并且贴合业务发展的图数据库就变得尤为关键.本文挑选了几款业 ...
- SPFA算法详解
前置知识:Bellman-Ford算法 前排提示:SPFA算法非常容易被卡出翔.所以如果不是图中有负权边,尽量使用Dijkstra!(Dijkstra算法不能能处理负权边,但SPFA能) 前排提示*2 ...