AQI分析
A Q I 分 析
1、背景信息
AOI( Air Quality Index),指空气质量指数,用来衡量空气清洁或污染的程度。值越小,表示空气质量越好。近年来,因为环境问题,空气质量也越来越受到人们的重视。我们期望能够运用数据分析的相关技术,对全国城市空气质量进行研究与分析,希望能够解决如下疑问:
- 哪些城市的空气质量较好/较差?
- 空气质量在地理位置分布上,是否具有一定的规律性?
- 城市的空气质量与是否临海是否有关?
- 空气质量主要受哪些因素影响?
- 全国城市空气质量普遍处于何种水平?
现在获取了2015年空气质量指数集。该数据集包含全国主要城市的相关数据以及空气质量指数。
|
City |
AQI |
Precipitation |
GDP |
|
城市 |
空气质量指数 |
降水量 |
城市生产总值 |
|
Longitude |
Latitude |
Altitude |
Population Density |
|
经度 |
纬度 |
海拔高度 |
人口密集度 |
|
Temperature |
Coastal |
Incineration (10,000ton) |
Green Coverage Rate |
|
温度 |
是否临海 |
焚烧量/10000吨 |
绿化率 |
2、数据分析流程
在进行数据分析之前,我们需要清楚数据分析的基本流程。

3、读取数据
导入需要的库并初始化一些设置。
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import seaborn as sns
- import warnings
- sns.set(style="darkgrid") plt.rcParams["font.family"]="simHei" #用于解决中文显示不了的问题
- plt.rcParams["axes.unicode_minus"]=False
- warnings.filterwarnings("ignore")
加载数据集
4、数据清洗
4.1 缺失值
对于缺失值的处理 。可以使用如下方式:
- 删除缺失值
- 仅适用于缺失数量很少的情况
- 填充缺失值
- 数值变量
- 均值填充
- 中值填充
- 类别变量
- 众数填充
- 单独作为一个类别
- 其他
- 数值变量
- 删除缺失值
先用info()或innull()查看缺失值。
再用skew()查看偏度信息,再画个图看看,注意distplot()不支持有空值数据绘制,所以必须先用dropna()将空值剔除。
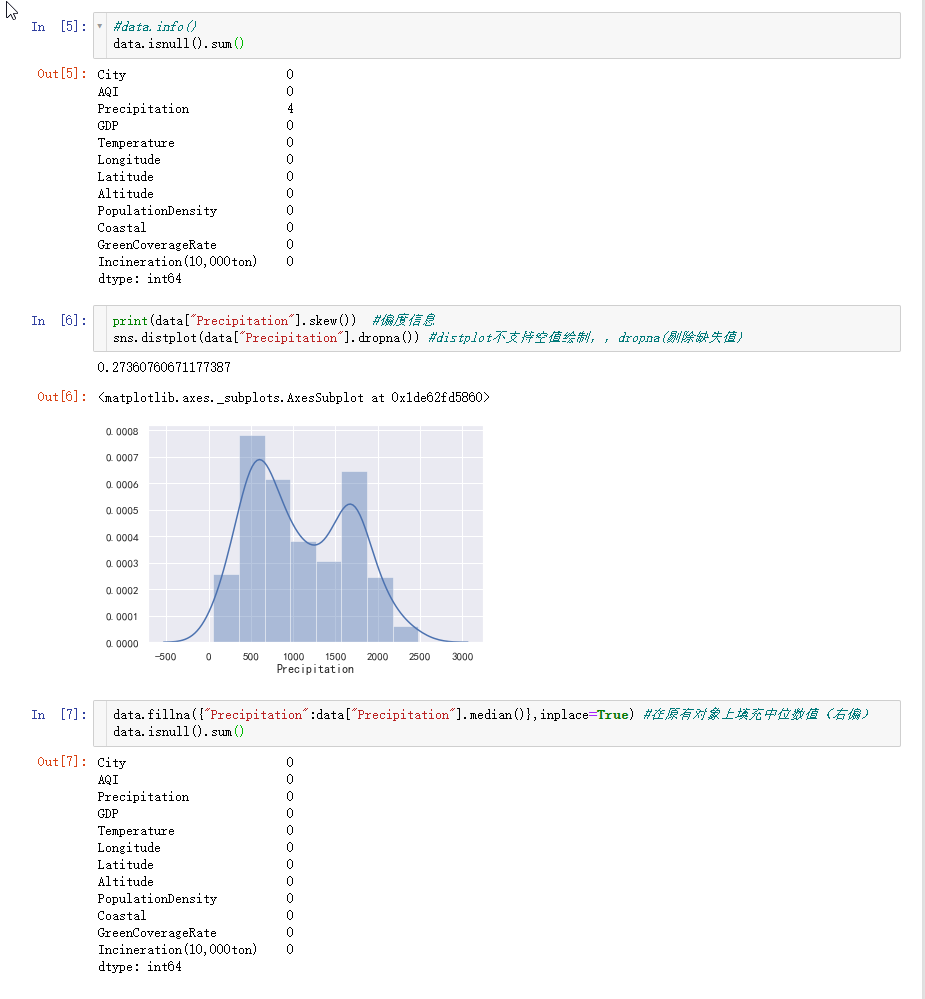
可以看出,我们的原始数据有点右偏,因为缺失值只有4个,缺失数量很少,可以直接删除,,但我们这次用了中位数来填充。
4.2 异常值
异常值如何发现?我们有这几种方法:
- describe()
- 箱线图
- 3σ方式
- 其他相关异常检测算法
describe():
调用dataframe对象的describe方法,会显示数据的统计信息,让自己了解下数据

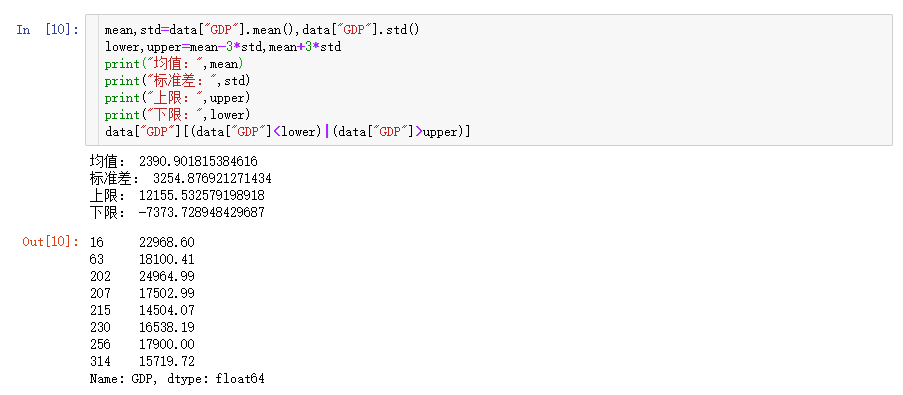
可以看出GDP、Latitude、PopulationDensity的最大值与较大四分位数的差距异常巨大,存在右偏现象,即存在许多极大的异常值
3σ
3σ即3倍标准差,根据正态分布的特性,我们可以将3σ之外的数据视为异常值。以GDP为例,画出GDP的偏度分布情况:
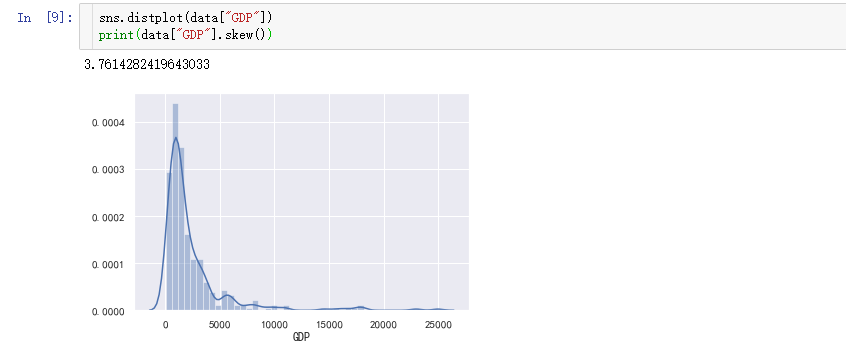
该数据出现严重右偏分布,也就是说存在很多极大的异常值,通过3σ法获取这些异常值:
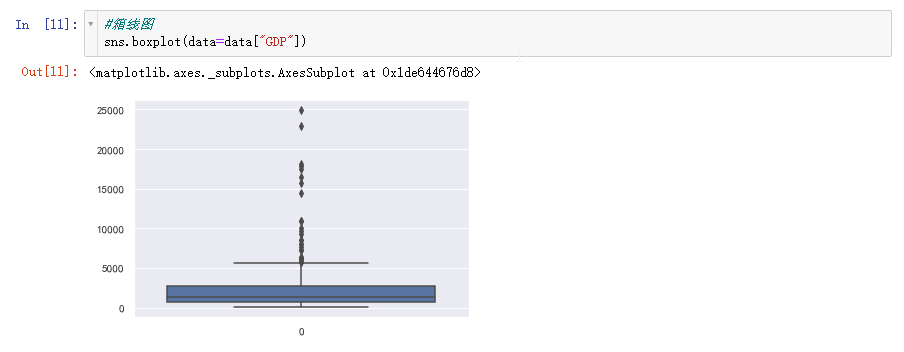
箱线图
通过箱线图我们可以很直观的看见存在很多极大的异常值,怎么判断的呢?
箱线图异常值的判断依据:
Q1、Q2、Q3分别表示1/4分位数、2/4分位数、3/4分位数,IQR=Q3-Q1
若数据小于Q1-1.5IQR或大于Q3+1.5IQR则为异常值。
找到异常怎么处理,通常有以下几种方式:
- 删除异常值(不常用)
- 视为缺失值处理
- 对数转换(适用于右偏,建模)
- 临界值替换
- 分箱法离散化处理(分成不同区间映射成离散值)
以对数转换为例。
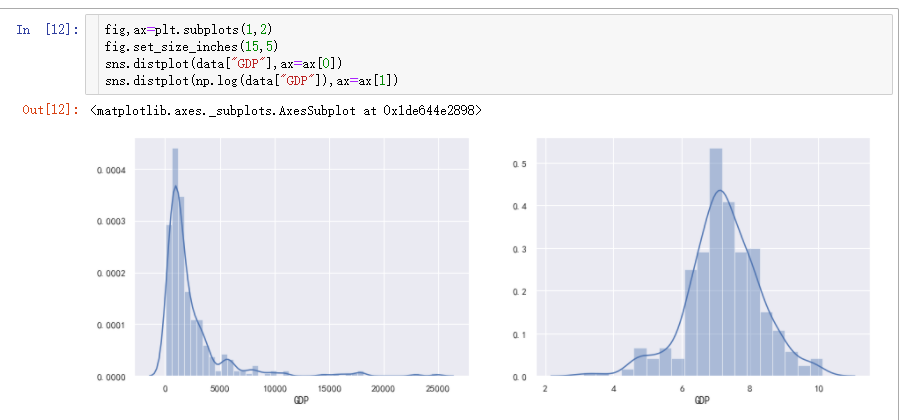
对数转换适用于存在较大异常值的数据,即适用于右偏分布,不适用于左偏分布。
4.3 重复值
重复值的处理很简单,使用duplicated查询重复值,参数keep有三个值:"first"、False、"last".分别表示显示第一条、所有、最后一天重复的记录。
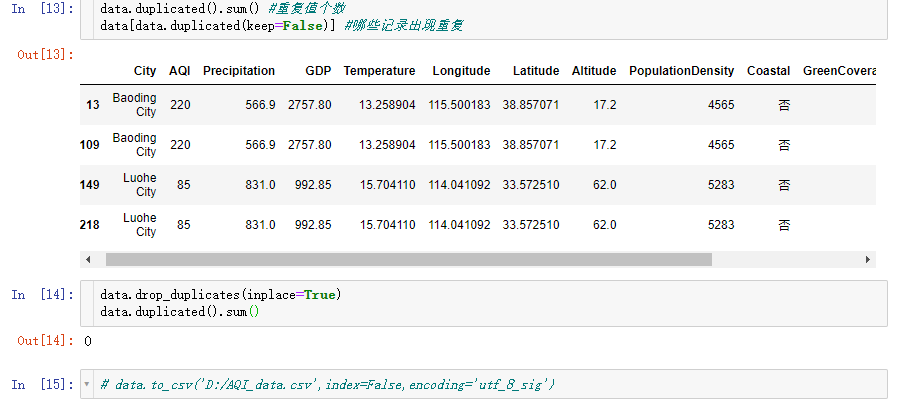
清洗完的数据可以直接导出。
5 数据分析
空气质量的好坏有时候决定人的去留,择校、就业、定居、旅游等等。
首先来看最好和最坏的几个城市
5.1 空气质量最好&最坏的几个城市
空气最好的5个城市
先按AQI排序,默认升序,取前5条记录;x轴上的城市名称需要旋转45°,这样便于查看。

上图可以看出,空气质量好的前5个城市:1.韶关市,2.南平市,3.梅州市,4.基隆市(台湾省),5.三明市。全是南方城市。
空气最差的5个城市
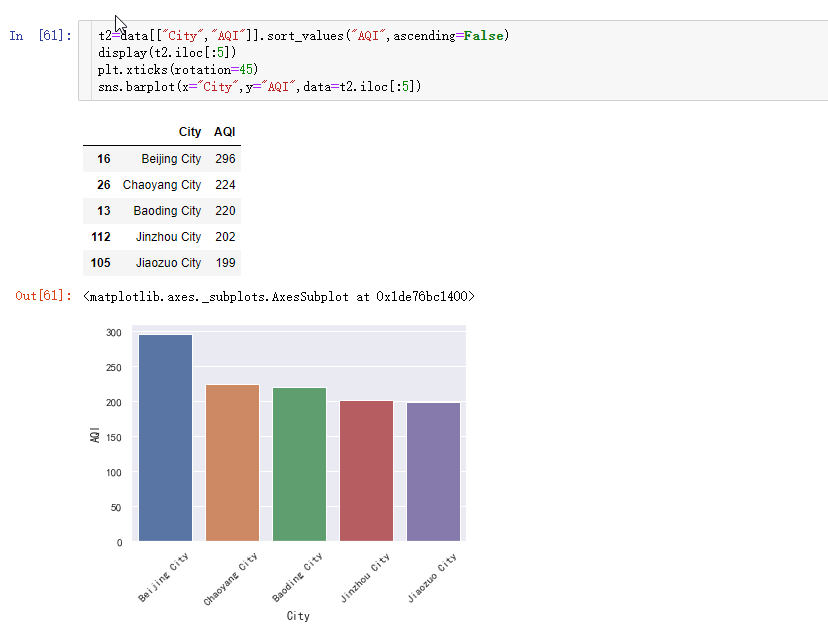
上图可以看出,空气质量最差的前5个城市: 1.北京市,2.朝阳市,3.保定市,4.锦州市,5.焦作市。全是北方城市。
5.2 全国部分城市的空气质量
5.2.1 空气质量等级划分:
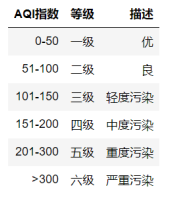
首先我们需要定义一个函数,写一些if语句,通过AQI的值来判断空气质量等级,
这里需要用apply函数:申请调用我们自建的函数,返回值就是自建函数返回值。
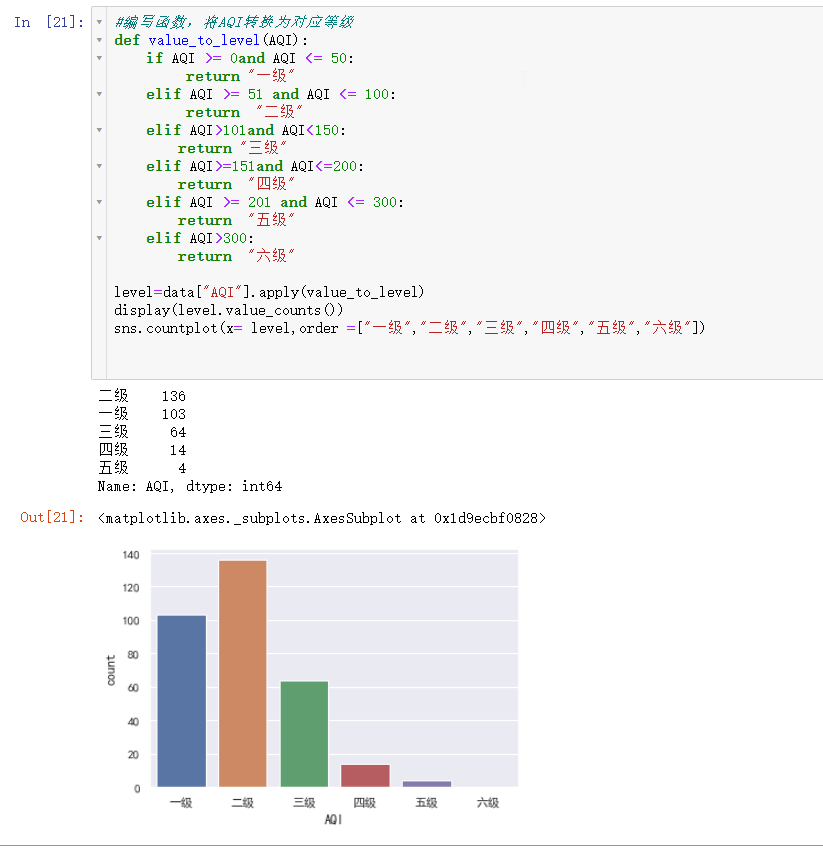
从图中可以看出,我国主要城市的空气质量主要以一级和二级为主,三级占一部分,其他占少数。
5.2.2 空气质量指数分布情况
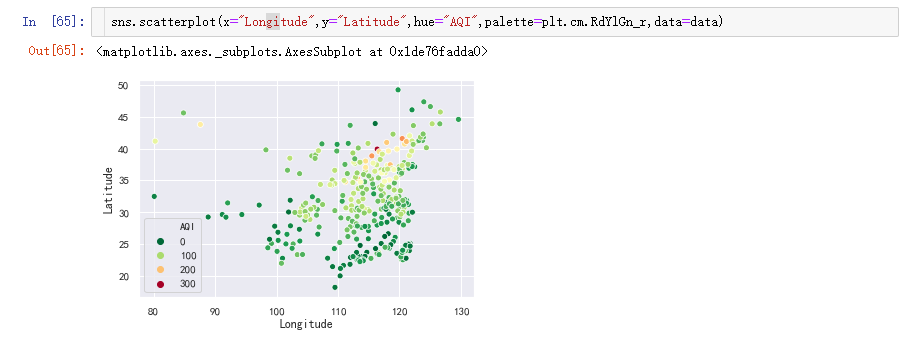
调用scatterplot()绘制散点图,以AQI区分,参数palette是调色,这里是绿色到红色。
从图中可以看出,从地理位置上来讲,空气质量南方城市优于北方城市,西部城市优于东部城市。
5.3 城市的空气质量与是否临海是否有关?
先来看看此数据中临海与内陆城市的数量:
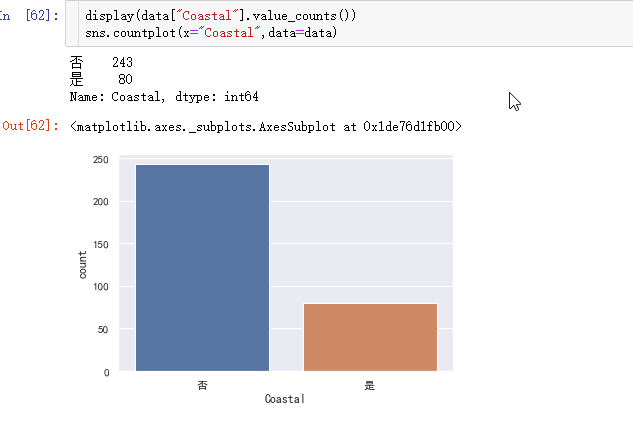
内陆城市数量远大于临海城市,这没什么悬念,我们再来看下散点分布情况:
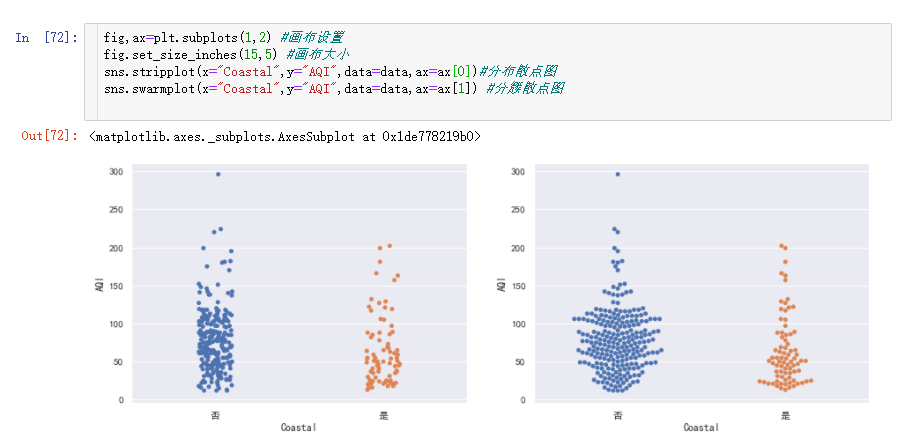
从图中可以大概看出临海城市空气质量由于内陆。但是我们还是要靠数据说话,分组计算空气质量的均值:
要用到groupby()分组函数
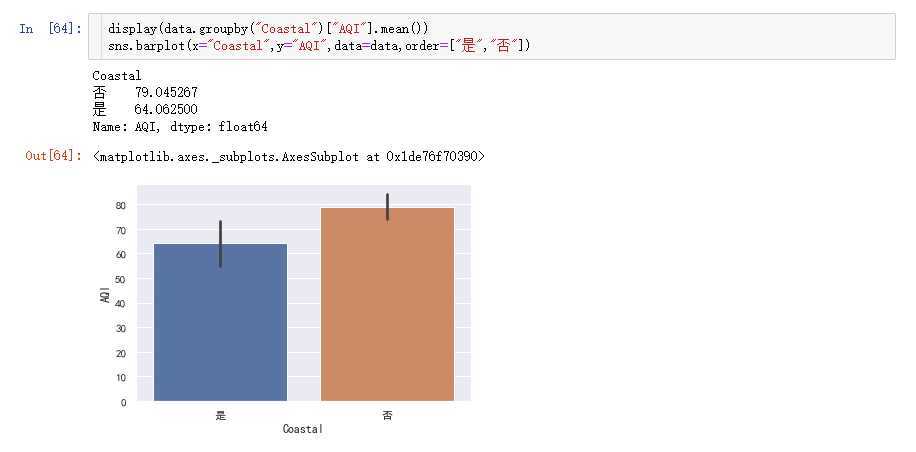
临海79,内陆64。但是信息太少,我们再画个箱线图和小提琴图,来了解更多信息。
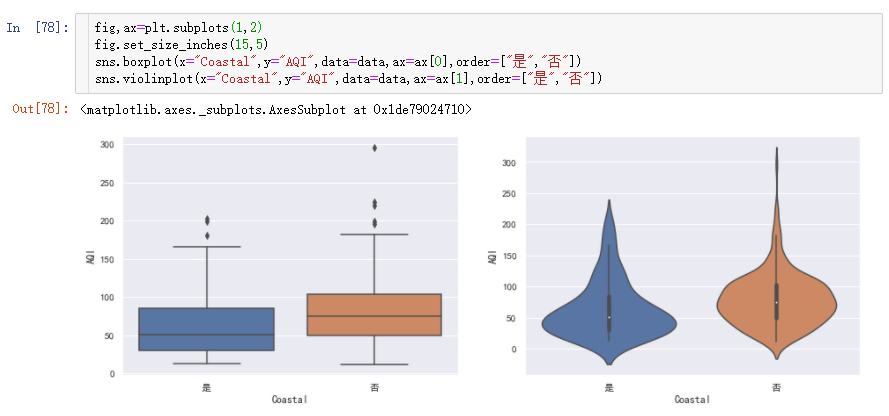
从箱线图可看出,临海城市的AQI的四分位值,最大值都比内陆城市低,所以临海城市空气质量相对于内陆城市要好。但是箱线图对于数据分布密度不明显。
所以,绘制小提琴图,既能展示箱线图信息,又能呈现分布的密度。
我们还可以将小提琴图和分簇散点图结合在一起看:
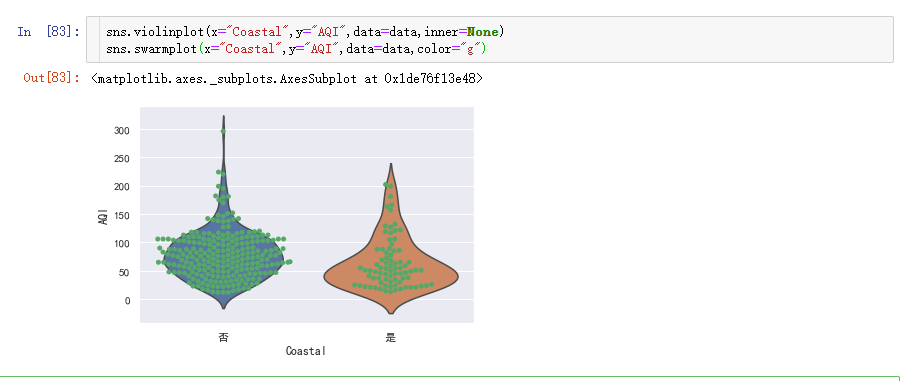
inner=None表示把“琴弦”去除。
到这里我们能得出临海城市空气质量普遍好于内陆吗?
显然是不能的,我们的数据只有几百条,只是一个样本,并不能代表总体,这是样本与总体的差异性。
那怎么得到一个可靠的结论呢? 我们需要对样本做差异检验:
对两样本做t 检验,来查看临海城市与内陆城市的均值差异是否显著。在进行两样本检验时,我们需要知道两样本的方差是否一致才能进行后面的 t 检验

先导入相关库,定义变量,stats.levene()方差齐性检验。返回两个值:第一个是统计量不要看,,看第二个p值为0.77,说明接受原假设,方差是齐性的(原假设:两样本方差相等,备择假设:方差不等),可以进行下一步了。
进行t检验时,两样本的方差是否相等,对结果有影响!ttest_ind():两独立样本t检验,返回结果的p值只有0.007,很小,拒绝原假设(两样本不相等)。
从统计量为负数可以看出,inland是大于coastal的。怎么算呢?在stats中提供的两独立样本t检验是双边检验(=或≠),而现在我们要的是大于小于的关系(单边检验),所以需要计算p值:stats.t.sf(),sf=1-cdf,cdf为累计分布函数,sf为残存函数,自由度df。p值0.99666,说明coastal越小。
到此为止,我们有超过99%的几率可以认为空气质量临海城市普遍优于内陆。

5.4 空气质量主要受哪些因素影响?
- 人口密度大是否对导致空气质量低呢?
- 绿化率高是否能提高空气质量呢?
先用pairplot()画一个散点图矩阵,取3列数据
对于不同变量的绘制散点图,同变量的绘制直方图,只表示数量。从上图并不能明显地看出变量之间的相关性, 我们需要通过计算相关系数来了解。

DataFrame对象提供了计算相关系数的方法,直接data.corr()即可 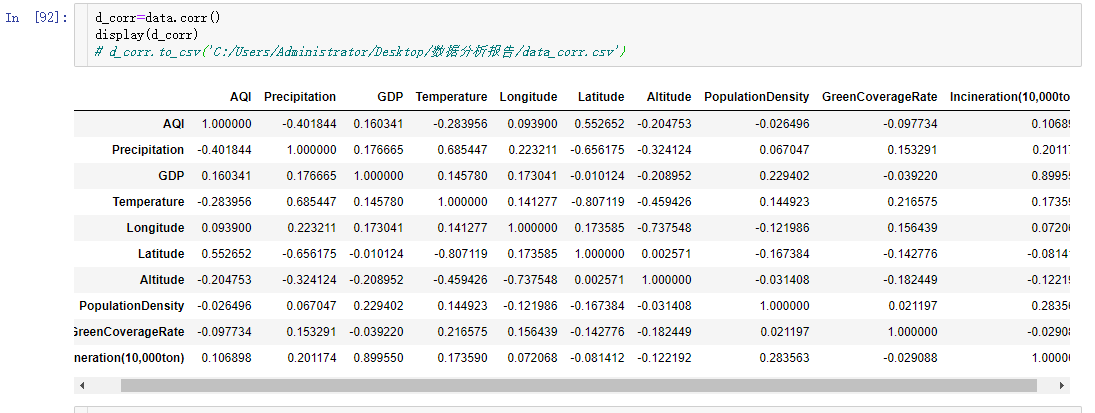
再将数据可视化,更清晰的呈现数据:
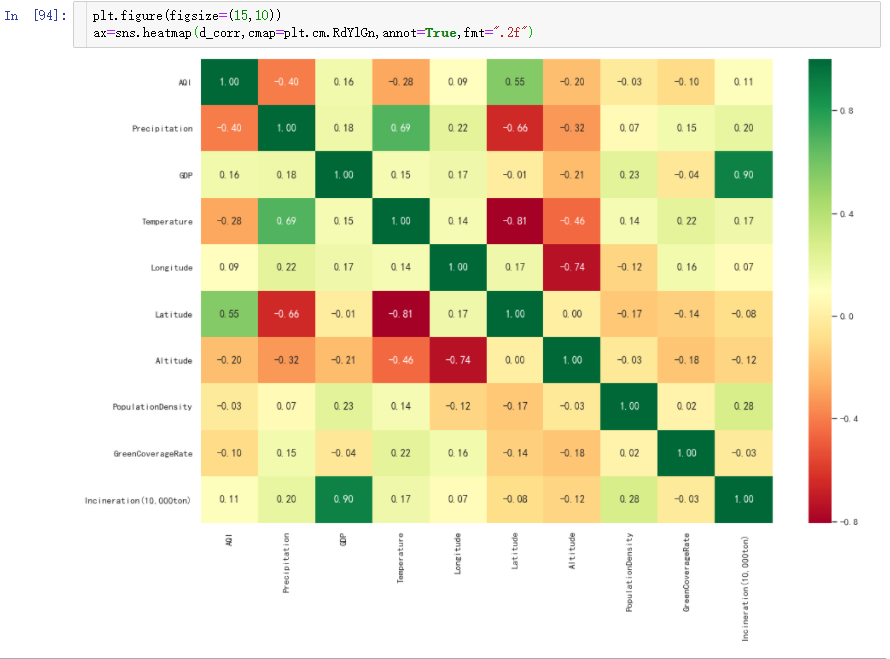
结果统计
从结果中可知,空气质量指数主要受降雨量(-0.40) 与纬度(0.55) 影响。
- 降雨量越多,空气质量越好。
- 纬度越低,空气质量越好。
此外,我们还能够发现其他一些明显的细节:
- GDP (城市生产总值)与Incineration (焚烧量)正相关(0.90) 。
- Temperature (温度)与Precipitation (降雨量) 正相关(0.69) 。
- Temperature (温度)与Latitude (纬度)负相关(-0.81)。
- Longitude (经度) 与Altitude (海拔) 负相关(-0.74) 。
- Latitude (纬度)与Precipitation (降雨量)负相关(-0.66) 。
- Temperature (温度)与Altitude (海拔)负相关(-0.46) 。
- Altitude (海拔)与Precipitation (降雨量)负相关(-0.32) 。
5.5全国城市空气质量普遍处于何种水平?
据说2015年全国所有城市的空气质量指数均值在71左右,真的假的?
为了验证这是否正确,我们先来看看均值:

75?大于71了,说明消息是假的?
当然还不能这么说,因为,它俩不对等,一个是总体均值,一个是样本均值,所以需要验证一下它们是否相等。我们可以用单样本t经验(ttest_lsamp),置信度为95%。
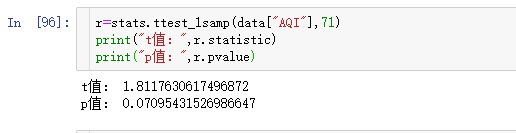
p值大于0.05,所以无法拒绝原假设,维持原假设,即维持2015年全国所有城市的空气质量指数均值在71左右。
调用函数stats.t.interval()得出置信区间。

这样我们就计算出2015年全国所有城市平均空气质量指数95%的可能在70.63~80.04之间。
6 总结
1.空气质量总体分布上来说,南方城市优于北方城市,西部城市优于东部城市。
2.临海城市的空质量整体上好于内陆城市。
3.是否临海,降雨量与纬度对空气质量指数的影响较大。
4.我国城市平均空气质量指数有95%的可能性在(70.63 - 80.04)这个区间内。
7 PPT展示


AQI分析的更多相关文章
- IOS计划 分析
1.基本介绍 IOS苹果公司iPhone.iPod touch和iPad操作系统和其他设备的发展. 2.知识点 1.IOS系统 iPhone OS(现在所谓的iOS)这是iPhone, iPod to ...
- python爬虫之静态网页——全国空气质量指数(AQI)爬取
首先爬取地址:http://www.air-level.com/ 利用的python库,最近最流行的requests,BeautifulSoup. requests:用于下载html Beautifu ...
- PM2.5环境检测系统的设计与分析
PM2.5环境检测系统的设计与分析 摘要: 大气颗粒物污染对人类健康和生态环境造成了很大的影响,这让人们逐渐重视起对细颗粒物PM2.5检测技术的研究.本文阐述了PM2.5浓度检测的五种方法,在对上 ...
- 如何用 Python 和 API 收集与分析网络数据?
摘自 https://www.jianshu.com/p/d52020f0c247 本文以一款阿里云市场历史天气查询产品为例,为你逐步介绍如何用 Python 调用 API 收集.分析与可视化数据.希 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- alias导致virtualenv异常的分析和解法
title: alias导致virtualenv异常的分析和解法 toc: true comments: true date: 2016-06-27 23:40:56 tags: [OS X, ZSH ...
- 火焰图分析openresty性能瓶颈
注:本文操作基于CentOS 系统 准备工作 用wget从https://sourceware.org/systemtap/ftp/releases/下载最新版的systemtap.tar.gz压缩包 ...
- 一起来玩echarts系列(一)------箱线图的分析与绘制
一.箱线图 Box-plot 箱线图一般被用作显示数据分散情况.具体是计算一组数据的中位数.25%分位数.75%分位数.上边界.下边界,来将数据从大到小排列,直观展示数据整体的分布情况. 大部分正常数 ...
- 应用工具 .NET Portability Analyzer 分析迁移dotnet core
大多数开发人员更喜欢一次性编写好业务逻辑代码,以后再重用这些代码.与构建不同的应用以面向多个平台相比,这种方法更加容易.如果您创建与 .NET Core 兼容的.NET 标准库,那么现在比以往任何时候 ...
随机推荐
- Qt数据库 QSqlTableModel实例操作(转)
本文介绍的是Qt数据库 QSqlTableModel实例操作,详细操作请先来看内容.与上篇内容衔接着,不顾本文也有关于上篇内容的链接. Qt数据库 QSqlTableModel实例操作是本文所介绍的内 ...
- “随手记”开发记录day14
今天继续昨天没有完成的增加“修改”功能.对于已经添加的记账记录,长按可以进行修改和删除的操作. 但是今天并没有完成……
- Devops 原始思想 所要实现的目标
解释: DevOps(Development和Operations的组合词)是一组过程.方法与系统的统称,用于促进开发(应用程序/软件工程).技术运营和质量保障(QA)部门之间的沟通.协作与整合. 它 ...
- Faiss流程与原理分析
1.Faiss简介 Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库.它包含多种搜索任意大 ...
- object detection 总结
1.基础 自己对于YOLOV1,2,3都比较熟悉. RCNN也比较熟悉.这个是自己目前掌握的基础2.第一步 看一下2019年的井喷的anchor free的网络3.第二步 看一下以往,引用多的网路4. ...
- Web组件的三种关联关系
Web应用程序如此强大的原因之一是它们能彼此链接和聚合信息资源.Web组件之间存在三种关联关系: ● 请求转发 ● URL重定向 ● 包含 存在以上关联关系的Web组件可以是JSP或Servle ...
- 存储系列之 从ext2到ext3、ext4 的变化与区别
引言:ext3 和 ext4 对 ext2 进行了增强,但是其核心设计并没有发生变化.所以建议先查看上上篇的<存储系列之 Linux ext2 概述 >,有了ext2的基础,看这篇就是so ...
- 【CF1174D】 Ehab and the Expected XOR Problem - 构造
题面 Given two integers \(n\) and \(x\), construct an array that satisfies the following conditions: · ...
- C++开发时字符编码的选择
最近看了很多有关字符编码的讨论帖子, 自己也做了很多尝试, 针对linux和windows上字符编码的选择做了个简单整理, 在此做个记录 首先是基础编码知识, 下面我列出的4个编码方式或字符集是我们应 ...
- 蒲公英 · JELLY技术周刊 Vol.18 关于 React 那些设计
蒲公英 · JELLY技术周刊 Vol.18 自 2011 年,Facebook 第一次在 News Feed 上采用了 React 框架,十年来 React 生态中很多好用的功能和工具在诸多设计思想 ...