深入学习OpenCV文档扫描及OCR识别(文档扫描,图像矫正,透视变换,OCR识别)
如果需要处理的原图及代码,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice
下面准备学习如何对文档扫描摆正及其OCR识别的案例,主要想法是对一张不规则的文档进行矫正,然后通过tesseract进行OCR文字识别,最后返回结果。下面进入正文:
现代生活中,手机像素比较高,所以大家拍这些照片都很随意,随便拍,比如下面的照片,如发票,文本等等:


对于这些图像矫正的问题,在图像处理领域还真的很多,比如文本的矫正,车牌的矫正,身份证的矫正等等。这些都是因为拍摄者拍照随意,这就要求我们通过后期的图像处理技术将图片还原好,才能进行下一步处理,比如数字分割,数字识别,字母识别,文字识别等等。
上面的问题,我们在日常生活中遇到的可不少,因为拍摄时拍的不好,导致拍出来的图片歪歪扭扭的,很不自然,那么我们如何将图片矫正过来呢?
总的来说,要进行图像矫正,至少需要以下几步:
- 1,文档的轮廓提取技术
- 2,原始与变换坐标的计算
- 3,通过透视变换获取目标区域
本文通过两个案例,一个是菜单矫正及OCR识别;另一个是答题卡矫正及OCR识别。
1,如何扫描菜单并获取菜单内容
下面以菜单为例,慢慢剖析如何实现图像矫正,并获取菜单内容。

上面的斜着的菜单,如何扫描到如右图所示的照片呢?其实步骤有以下几步:
- 1,探测边缘
- 2,提取菜单矩阵轮廓四点进行透视变换
- 3,应用一个透视的转换去获取一个文档的自顶向下的正图
知道步骤后,我们开始做吧!
1.1,文档轮廓提取
我们拿到图像之后,首先进行边缘检测,其中预处理包括对噪音进行高斯模糊,然后进行边缘检测(这里采用了Canny算子提取特征),下面我们可以看一下边缘检测的代码与结果:
代码:
def edge_detection(img_path):
# 读取输入
img = cv2.imread(img_path)
# 坐标也会相同变换
ratio = img.shape[0] / 500.0
orig = img.copy() image = resize(orig, height=500)
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blur, 75, 200)
show(edged)
效果如下:

我们从上图可以看到,已经将菜单的所有轮廓都检测出来了,而我们其实只需要最外面的轮廓,下面我们通过过滤得到最边缘的轮廓即可。
代码如下:
def edge_detection(img_path):
# ********* 预处理 ****************
# 读取输入
img = cv2.imread(img_path)
# 坐标也会相同变换
ratio = img.shape[0] / 500.0
orig = img.copy() image = resize(orig, height=500)
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blur, 75, 200) # ************* 轮廓检测 ****************
# 轮廓检测
contours, hierarchy = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = sorted(contours, key=cv2.contourArea, reverse=True)[:5] # 遍历轮廓
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True)
# c表示输入的点集,epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
approx = cv2.approxPolyDP(c, 0.02*peri, True) # 4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break res = cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
show(res)
效果如下:

如果说对轮廓排序后,不进行近似的话,我们直接取最大的轮廓,效果图如下:

1.2,透视变换(摆正图像)
当获取到图片的最外轮廓后,接下来,我们需要摆正图像,在摆正图形之前,我们需要先学习透视变换。
1.2.1,cv2.getPerspectiveTransform()
透视变换(Perspective Transformation)是将成像投影到一个新的视平面(Viewing Plane),也称作投影映射(Projective mapping),如下图所示,通过透视变换ABC变换到A'B'C'。
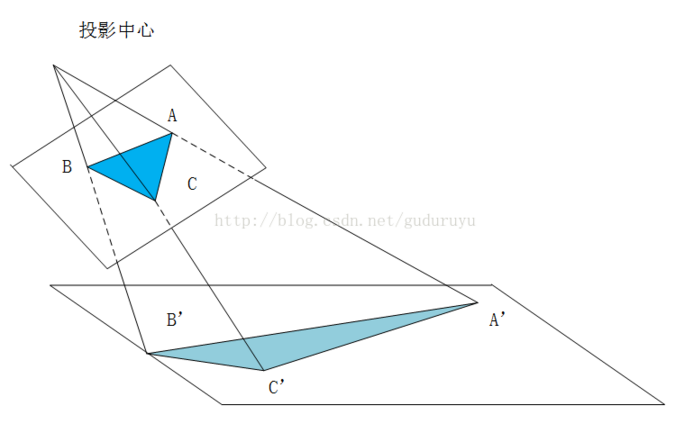
cv2.getPerspectiveTransform() 获取投射变换后的H矩阵。
cv2.getPerspectiveTransform() 函数的opencv 源码如下:
def getPerspectiveTransform(src, dst, solveMethod=None): # real signature unknown; restored from __doc__
"""
getPerspectiveTransform(src, dst[, solveMethod]) -> retval
. @brief Calculates a perspective transform from four pairs of the corresponding points.
.
. The function calculates the \f$3 \times 3\f$ matrix of a perspective transform so that:
.
. \f[\begin{bmatrix} t_i x'_i \\ t_i y'_i \\ t_i \end{bmatrix} = \texttt{map_matrix} \cdot \begin{bmatrix} x_i \\ y_i \\ 1 \end{bmatrix}\f]
.
. where
.
. \f[dst(i)=(x'_i,y'_i), src(i)=(x_i, y_i), i=0,1,2,3\f]
.
. @param src Coordinates of quadrangle vertices in the source image.
. @param dst Coordinates of the corresponding quadrangle vertices in the destination image.
. @param solveMethod method passed to cv::solve (#DecompTypes)
.
. @sa findHomography, warpPerspective, perspectiveTransform
"""
pass
参数说明:
- rect(即函数中src)表示待测矩阵的左上,右上,右下,左下四点坐标
- transform_axes(即函数中dst)表示变换后四个角的坐标,即目标图像中矩阵的坐标
返回值由原图像中矩阵到目标图像矩阵变换的矩阵,得到矩阵接下来则通过矩阵来获得变换后的图像,下面我们学习第二个函数。
1.2.2,cv2.warpPerspective()
cv2.warpPerspective() 根据H获得变换后的图像。
opencv源码如下:
def warpPerspective(src, M, dsize, dst=None, flags=None, borderMode=None, borderValue=None): # real signature unknown; restored from __doc__
"""
warpPerspective(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) -> dst
. @brief Applies a perspective transformation to an image.
.
. The function warpPerspective transforms the source image using the specified matrix:
.
. \f[\texttt{dst} (x,y) = \texttt{src} \left ( \frac{M_{11} x + M_{12} y + M_{13}}{M_{31} x + M_{32} y + M_{33}} ,
. \frac{M_{21} x + M_{22} y + M_{23}}{M_{31} x + M_{32} y + M_{33}} \right )\f]
.
. when the flag #WARP_INVERSE_MAP is set. Otherwise, the transformation is first inverted with invert
. and then put in the formula above instead of M. The function cannot operate in-place.
.
. @param src input image.
. @param dst output image that has the size dsize and the same type as src .
. @param M \f$3\times 3\f$ transformation matrix.
. @param dsize size of the output image.
. @param flags combination of interpolation methods (#INTER_LINEAR or #INTER_NEAREST) and the
. optional flag #WARP_INVERSE_MAP, that sets M as the inverse transformation (
. \f$\texttt{dst}\rightarrow\texttt{src}\f$ ).
. @param borderMode pixel extrapolation method (#BORDER_CONSTANT or #BORDER_REPLICATE).
. @param borderValue value used in case of a constant border; by default, it equals 0.
.
. @sa warpAffine, resize, remap, getRectSubPix, perspectiveTransform
"""
pass
参数说明:
- src 表示输入的灰度图像
- M 表示变换矩阵
- dsize 表示目标图像的shape,(width, height)表示变换后的图像大小
- flags:插值方式,interpolation方法INTER_LINEAR或者INTER_NEAREST
- borderMode:边界补偿方式,BORDER_CONSTANT or BORDER_REPLCATE
- borderValue:边界补偿大小,常值,默认为0
1.2.3 cv2.perspectiveTransform()
cv2.perspectiveTransform() 和 cv2.warpPerspective()大致作用相同,但是区别在于 cv2.warpPerspective()适用于图像,而cv2.perspectiveTransform() 适用于一组点。
cv2.perspectiveTransform() 的opencv源码如下:
def perspectiveTransform(src, m, dst=None): # real signature unknown; restored from __doc__
"""
perspectiveTransform(src, m[, dst]) -> dst
. @brief Performs the perspective matrix transformation of vectors.
.
. The function cv::perspectiveTransform transforms every element of src by
. treating it as a 2D or 3D vector, in the following way:
. \f[(x, y, z) \rightarrow (x'/w, y'/w, z'/w)\f]
. where
. \f[(x', y', z', w') = \texttt{mat} \cdot \begin{bmatrix} x & y & z & 1 \end{bmatrix}\f]
. and
. \f[w = \fork{w'}{if \(w' \ne 0\)}{\infty}{otherwise}\f]
.
. Here a 3D vector transformation is shown. In case of a 2D vector
. transformation, the z component is omitted.
.
. @note The function transforms a sparse set of 2D or 3D vectors. If you
. want to transform an image using perspective transformation, use
. warpPerspective . If you have an inverse problem, that is, you want to
. compute the most probable perspective transformation out of several
. pairs of corresponding points, you can use getPerspectiveTransform or
. findHomography .
. @param src input two-channel or three-channel floating-point array; each
. element is a 2D/3D vector to be transformed.
. @param dst output array of the same size and type as src.
. @param m 3x3 or 4x4 floating-point transformation matrix.
. @sa transform, warpPerspective, getPerspectiveTransform, findHomography
"""
pass
参数含义:
- src:输入的二通道或三通道的图像
- m:变换矩阵
- 返回结果为相同size的图像
1.2.4 摆正图像
将图像框出来后,我们计算出变换前后的四个点的坐标,然后得到最终的变换结果。
代码如下:
def order_points(pts):
# 一共四个坐标点
rect = np.zeros((4, 2), dtype='float32') # 按顺序找到对应的坐标0123 分别是左上,右上,右下,左下
# 计算左上,由下
# numpy.argmax(array, axis) 用于返回一个numpy数组中最大值的索引值
s = pts.sum(axis=1) # [2815.2 1224. 2555.712 3902.112]
print(s)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)] # 计算右上和左
# np.diff() 沿着指定轴计算第N维的离散差值 后者-前者
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect # 透视变换
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect # 计算输入的w和h的值
widthA = np.sqrt(((br[0] - bl[0])**2) + ((br[1] - bl[1])**2))
widthB = np.sqrt(((tr[0] - tl[0])**2) + ((tr[1] - tl[1])**2))
maxWidth = max(int(widthA), int(widthB)) heightA = np.sqrt(((tr[0] - br[0])**2) + ((tr[1] - br[1])**2))
heightB = np.sqrt(((tl[0] - bl[0])**2) + ((tl[1] - bl[1])**2))
maxHeight = max(int(heightA), int(heightB)) # 变化后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]],
dtype='float32') # 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight)) # 返回变换后的结果
return warped # 对透视变换结果进行处理
def get_image_processingResult():
img_path = 'images/receipt.jpg'
orig, ratio, screenCnt = edge_detection(img_path)
# screenCnt 为四个顶点的坐标值,但是我们这里需要将图像还原,即乘以以前的比率
# 透视变换 这里我们需要将变换后的点还原到原始坐标里面
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio)
# 二值处理
gray = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY)[1] thresh_resize = resize(thresh, height = 400)
show(thresh_resize)
效果如下:

1.2.5 其他图片矫正实践
这里图片原图都可以去我的GitHub里面去拿(地址:https://github.com/LeBron-Jian/ComputerVisionPractice)。
对于下面这张图:

我们使用透视变换抠出来效果如下:

这个图使用和之前的代码就可以,不用修改任何东西就可以拿到其目标区域。
下面看这张图:

其实和上面图类似,不过这里我们依次看一下其图像处理过程,毕竟和上面两张图完全不是一个类型了。
首先是 Canny算子得到的结果:

其实拿到全轮廓后,我们就直接获取最外面的轮廓即可。
我自己更改了一下,效果一样,但是还是贴上代码:
def edge_detection(img_path):
# ********* 预处理 ****************
# 读取输入
img = cv2.imread(img_path)
# 坐标也会相同变换
ratio = img.shape[0] / 500.0
orig = img.copy() image = resize(orig, height=500)
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blur, 75, 200)
# show(edged)
# ************* 轮廓检测 ****************
# 轮廓检测
contours, hierarchy = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
#cnts = sorted(contours, key=cv2.contourArea, reverse=True)[:5] max_area = 0
myscreenCnt = []
for i in contours:
temp = cv2.contourArea(i)
if max_area < temp:
myscreenCnt = i # res = cv2.drawContours(image, myscreenCnt, -1, (0, 255, 0), 2)
# show(res)
return orig, ratio, screenCnt
最后我们不对发票做任何处理,看原图效果:

部分代码如下:
# 对透视变换结果进行处理
def get_image_processingResult():
img_path = 'images/fapiao.jpg'
orig, ratio, screenCnt = edge_detection(img_path)
# screenCnt 为四个顶点的坐标值,但是我们这里需要将图像还原,即乘以以前的比率
# 透视变换 这里我们需要将变换后的点还原到原始坐标里面
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio) thresh_resize = resize(warped, height = 400)
show(thresh_resize)
return thresh
下面再看一个例子:

首先,它得到的Canny结果如下:

我们需要对它进行一些小小的处理。
我做了一些尝试,如果直接对膨胀后的图像,进行外接矩形,那么效果如下:

代码如下:
x, y, w, h = cv2.boundingRect(myscreenCnt)
res = cv2.rectangle(image, (x,y), (x+w,y+h), (0, 255, 0), 2)
show(res)
所以对轮廓取近似,效果稍微好点:
# 计算轮廓近似
peri = cv2.arcLength(myscreenCnt, True)
# c表示输入的点集,epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
approx = cv2.approxPolyDP(myscreenCnt, 0.015*peri, True)
res = cv2.drawContours(image, [approx], -1, (0, 255, 0), 2)
show(res)
效果如下:

因为这个是不规整图形,所以无法进行四个角的转换,需要更多角,这里不再继续尝试。
1.3,OCR识别
这里回到我们的菜单来,我们已经得到了扫描后的结果,下面我们进行OCR文字识别。
这里使用tesseract进行识别,不懂的可以参考我之前的博客(包括安装tesseract,和通过tesseract训练自己的字库):
深入学习使用ocr算法识别图片中文字的方法
深入学习Tesseract-ocr识别中文并训练字库的方法
配置好tesseract之后(这里不再show过程,因为我已经有了),我们通过其进行文字识别。
1.3.1 通过Python使用tesseract的坑
如果直接使用Python进行OCR识别的话,会出现下面问题:
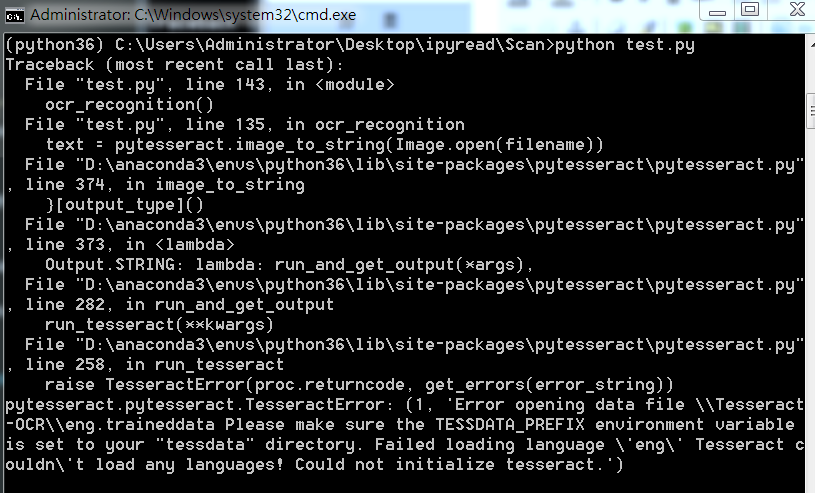
这里因为anaconda下载的 pytesseract 默认运行的tesseract.exe 是默认文件夹,所以有问题,我们改一下。
注意,找到安装地址,我们会发现有两个文件夹,我们进入上面文件夹即可

进入之后如下,我们打开 pytesseract.py。
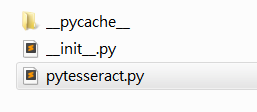
注意这里的地址:
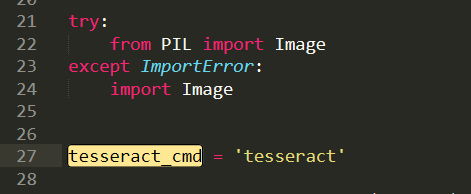
我们需要修改为我们安装的地址,即使我们之前设置了全局变量,但是Python还是不care的。
这里注意地址的话,我们通过 / 即可,不要 \,避免windows出现问题。
1.3.2 OCR识别
安装好一切之后,就可以识别了,我们这里有两种方法,一种是直接在人家的环境下运行,一种是在Python中通过安装pytesseract 库运行,效果都一样。
代码如下:
from PIL import Image
import pytesseract
import cv2
import os preprocess = 'blur' #thresh image = cv2.imread('scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] if preprocess == "blur":
gray = cv2.medianBlur(gray, 3) filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray) text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename) cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
使用Python运行,效果如下:
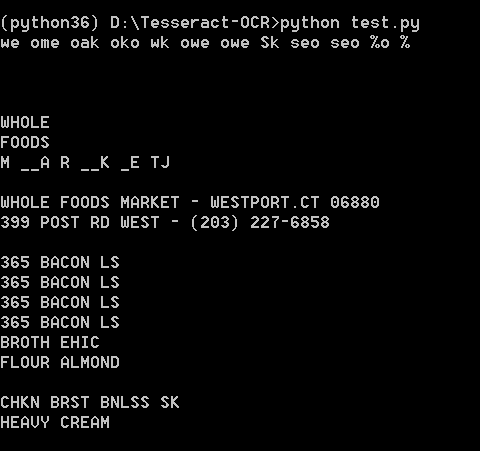
直接在tesseract.exe运行:

效果如下:

可能识别效果不是很好。不过不重要,因为图片也比较模糊,不是那么工整的。
1.4,完整代码
当然也可以去我的GitHub直接去下载。
代码如下:
import cv2
import numpy as np
from PIL import Image
import pytesseract def show(image):
cv2.imshow('image', image)
cv2.waitKey(0)
cv2.destroyAllWindows() def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w*r), height)
else:
r = width / float(w)
dim = (width, int(h*r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized def edge_detection(img_path):
# ********* 预处理 ****************
# 读取输入
img = cv2.imread(img_path)
# 坐标也会相同变换
ratio = img.shape[0] / 500.0
orig = img.copy() image = resize(orig, height=500)
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(blur, 75, 200) # ************* 轮廓检测 ****************
# 轮廓检测
contours, hierarchy = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
cnts = sorted(contours, key=cv2.contourArea, reverse=True)[:5] # 遍历轮廓
for c in cnts:
# 计算轮廓近似
peri = cv2.arcLength(c, True)
# c表示输入的点集,epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
approx = cv2.approxPolyDP(c, 0.02*peri, True) # 4个点的时候就拿出来
if len(approx) == 4:
screenCnt = approx
break # res = cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
# res = cv2.drawContours(image, cnts[0], -1, (0, 255, 0), 2)
# show(orig)
return orig, ratio, screenCnt def order_points(pts):
# 一共四个坐标点
rect = np.zeros((4, 2), dtype='float32') # 按顺序找到对应的坐标0123 分别是左上,右上,右下,左下
# 计算左上,由下
# numpy.argmax(array, axis) 用于返回一个numpy数组中最大值的索引值
s = pts.sum(axis=1) # [2815.2 1224. 2555.712 3902.112]
print(s)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)] # 计算右上和左
# np.diff() 沿着指定轴计算第N维的离散差值 后者-前者
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect # 透视变换
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect # 计算输入的w和h的值
widthA = np.sqrt(((br[0] - bl[0])**2) + ((br[1] - bl[1])**2))
widthB = np.sqrt(((tr[0] - tl[0])**2) + ((tr[1] - tl[1])**2))
maxWidth = max(int(widthA), int(widthB)) heightA = np.sqrt(((tr[0] - br[0])**2) + ((tr[1] - br[1])**2))
heightB = np.sqrt(((tl[0] - bl[0])**2) + ((tl[1] - bl[1])**2))
maxHeight = max(int(heightA), int(heightB)) # 变化后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]],
dtype='float32') # 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight)) # 返回变换后的结果
return warped # 对透视变换结果进行处理
def get_image_processingResult():
img_path = 'images/receipt.jpg'
orig, ratio, screenCnt = edge_detection(img_path)
# screenCnt 为四个顶点的坐标值,但是我们这里需要将图像还原,即乘以以前的比率
# 透视变换 这里我们需要将变换后的点还原到原始坐标里面
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio)
# 二值处理
gray = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
thresh = cv2.threshold(gray, 100, 255, cv2.THRESH_BINARY)[1] cv2.imwrite('scan.jpg', thresh) thresh_resize = resize(thresh, height = 400)
# show(thresh_resize)
return thresh def ocr_recognition(filename='tes.jpg'):
img = Image.open(filename)
text = pytesseract.image_to_string(img)
print(text) if __name__ == '__main__':
# 获取矫正之后的图片
# get_image_processingResult()
# 进行OCR文字识别
ocr_recognition()
2,如何扫描答题卡并识别
答题卡识别判卷,大家应该都不陌生。那么它需要做什么呢?肯定是将我们在答题卡上画圈圈的地方识别出来。
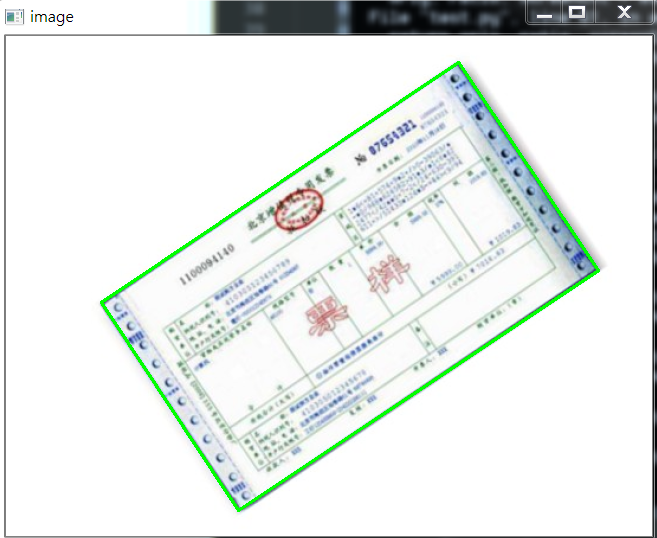
这是答题卡样子(原图请去我GitHub上拿:https://github.com/LeBron-Jian/ComputerVisionPractice):

我们肯定是需要分为两步走,第一步就是和上面处理类似,拿到答题卡的最终透视变换结果,使得图片中的答题卡可以凸显出来。第二步就是根据正确答案和答题卡的答案来判断正确率。
2.1 扫描答题卡及透视变换
这里我们对答题卡进行透视变换,因为之前已经详细的学习了这一部分,这里不再赘述,只是简单记录一下流程和图像处理效果,并展示代码。
下面详细的总结处理步骤:
- 1,图像灰度化
- 2,高斯滤波处理
- 3,使用Canny算子找到图片边缘信息
- 4,寻找轮廓
- 5,找到最外层轮廓,并确定四个坐标点
- 6,根据四个坐标位置计算出变换后的四个角位置
- 7,获取变换矩阵H,得到最终变换结果
下面直接使用上面代码进行跑,首先展示Canny效果:

当Canny效果不错的时候,我们拿到图像的轮廓进行筛选,找到最外面的轮廓,如下图所示:

最后通过透视变换,获得答题卡的区域,如下图所示:

2.2 根据正确答案和图卡判断正确率
这里我们拿到上面得到的答题卡图像,然后进行操作,获取到涂的位置,然后和正确答案比较,最后获得正确率。
这里分为以下几个步骤:
- 1,对图像进行二值化,将涂了颜色的地方变为白色
- 2,对轮廓进行筛选,找到正确答案的轮廓
- 3,对轮廓从上到下进行排序
- 4,计算颜色最大值的位置和Nonezeros的值
- 5,结合正确答案计算正确率
- 6,将正确答案打印在图像上
下面开始实践:
首先对图像进行二值化,如下图所示:

如果对二值化后的图直接进行画轮廓,如下:

所以不能直接处理,这里我们需要做细微处理,然后拿到图像如下:

这样就可以获得其涂的轮廓,如下所示:

然后筛选出我们需要的涂了答题卡的位置,效果如下:

然后通过这五个坐标点,确定答题卡的位置,如下图所示:

然后根据真实答案和图中答案对比结果,我们将最终结果与圈出来答案展示在图上,如下:

此项目到此结束。
2.3 部分代码展示
完整代码可以去我的GitHub上拿(地址:https://github.com/LeBron-Jian/ComputerVisionPractice)
代码如下:
import cv2
import numpy as np
from PIL import Image
import pytesseract def show(image):
cv2.imshow('image', image)
cv2.waitKey(0)
cv2.destroyAllWindows() def sorted_contours(cnt, model='left-to-right'):
if model == 'top-to-bottom':
cnt = sorted(cnt, key=lambda x:cv2.boundingRect(x)[1]) elif model == 'left-to-right':
cnt = sorted(cnt, key=lambda x:cv2.boundingRect(x)[0]) return cnt # 正确答案
ANSWER_KEY = {0:1, 1:4, 2:0, 3:3, 4:1} def answersheet_comparison(filename='finalanswersheet.jpg'):
'''
对变换后的图像进行操作(wraped),构造mask
根据有无填涂的特性,进行位置的计算
'''
img = cv2.imread(filename)
# print(img.shape) # 156*194
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 对图像进行二值化操作
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV | cv2.THRESH_OTSU)[1]
# show(thresh) # 对图像进行细微处理
kernele = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(3, 3))
erode = cv2.erode(thresh, kernele)
kerneld = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, ksize=(3, 3))
dilate = cv2.dilate(erode, kerneld)
# show(dilate) # 对图像进行轮廓检测
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0]
# res = cv2.drawContours(img.copy(), cnts, -1, (0, 255, 0), 2)
# # show(res) questionCnts = []
for c in cnts:
(x, y, w, h) = cv2.boundingRect(c)
arc = w/float(h) # 根据实际情况找出合适的轮廓
if w > 8 and h > 8 and arc >= 0.7 and arc <= 1.3:
questionCnts.append(c) # print(len(questionCnts)) # 这里总共圈出五个轮廓 分别为五个位置的轮廓
# 第四步,将轮廓进行从上到下的排序
questionCnts = sorted_contours(questionCnts, model='top-to-bottom') correct = 0
all_length = len(questionCnts)
for i in range(len(questionCnts)):
x, y, w, h = cv2.boundingRect(questionCnts[i])
answer = round((x-32)/float(100)*5)
print(ANSWER_KEY[i])
if answer == ANSWER_KEY[i]:
correct += 1
img = cv2.drawContours(img, questionCnts[i], -1, 0, 2) score = float(correct)/float(all_length)
print(correct, all_length, score) cv2.putText(img, 'correct_score:%s'%score, (10, 15), cv2.FONT_HERSHEY_SIMPLEX,
0.4, 0.3)
show(img) if __name__ == '__main__':
answersheet_comparison()
参考文献:https://www.pyimagesearch.com/2014/09/01/build-kick-ass-mobile-document-scanner-just-5-minutes/
https://blog.csdn.net/weixin_30666753/article/details/99054383
https://www.cnblogs.com/my-love-is-python/archive/2004/01/13/10439224.html
深入学习OpenCV文档扫描及OCR识别(文档扫描,图像矫正,透视变换,OCR识别)的更多相关文章
- 学习排序算法(一):单文档方法 Pointwise
学习排序算法(一):单文档方法 Pointwise 1. 基本思想 这样的方法主要是将搜索结果的文档变为特征向量,然后将排序问题转化成了机器学习中的常规的分类问题,并且是个多类分类问题. 2. 方法流 ...
- Python学习 :常用模块(四)----- 配置文档
常用模块(四) 八.configparser 模块 官方介绍:A configuration file consists of sections, lead by a "[section]& ...
- 对OCR文字识别软件的扫描选项怎么设置
说到OCR文字识别软件,越来越多的人选择使用ABBYY FineReader识别和转换文档,然而并不是每个人都知道转换质量取决于源图像的质量和所选的扫描选项,今天就给大家普及一下这方面的知识. ABB ...
- [学习opencv]高斯、中值、均值、双边滤波
http://www.cnblogs.com/tiandsp/archive/2013/04/20/3031862.html [学习opencv]高斯.中值.均值.双边滤波 四种经典滤波算法,在ope ...
- 【从零学习openCV】IOS7下的人脸检測
前言: 人脸检測与识别一直是计算机视觉领域一大热门研究方向,并且也从安全监控等工业级的应用扩展到了手机移动端的app,总之随着人脸识别技术获得突破,其应用前景和市场价值都是不可估量的,眼下在学习ope ...
- 【从零学习openCV】IOS7根据人脸检测
前言: 人脸检測与识别一直是计算机视觉领域一大热门研究方向,并且也从安全监控等工业级的应用扩展到了手机移动端的app.总之随着人脸识别技术获得突破,其应用前景和市场价值都是不可估量的,眼下在学习ope ...
- 学习OpenCV研究报告指出系列(二)源代码被编译并配有实例project
下载并安装CMake3.0.1 要自己编译OpenCV2.4.9的源代码.首先.必须下载编译工具,使用的比較多的编译工具是CMake. 以下摘录一段关于CMake的介绍: CMake是一个 ...
- 学习opencv之路(一)
先看一下<学习opencv> 找几个demo 学会相机标定 我做的是单目相机的标定.
- [纯小白学习OpenCV系列]官方例程00:世界观与方法论
2015-11-11 ----------------------------------------------------------------------------------- 其实,写博 ...
- 《学习OpenCV》中求给定点位置公式
假设有10个三维的点,使用数组存放它们有四种常见的形式: ①一个二维数组,数组的类型是CV32FC1,有n行,3列(n×3) ②类似①,也可以用一个3行n列(3×n)的二维数组 ③④用一个n行1列(n ...
随机推荐
- 题解【[USACO18FEB]New Barns 】
浅谈一下对于这题做完之后的感受(不看题解也是敲不出来啊qwq--) 题意翻译 Farmer John注意到他的奶牛们如果被关得太紧就容易吵架,所以他想开放一些新的牛棚来分散她们. 每当FJ建造一个新牛 ...
- 启动你的Android应用:运行设备模拟器和调试代码(第3部分)
下载all source for Test Proj: Test.zip - 306 KB 文章指出 本文包含了我即将出版的新书<启动Android应用程序>中的第三章. 在我完成这本书之 ...
- shell-变量的数值运算let内置命令
1. let命令的用法 格式: let 赋值表达式 [注]let赋值表达式功能等同于:((赋值表达式)) 范例1:给自变量i加8 [root@1-241 scripts]# i=2 [root@1- ...
- 手工实现docker的vxlan
前几天了解了一下docker overlay的原理,然后一直想验证一下自己的理解是否正确,今天模仿docker手工搭建了一个overlay网络.先上拓扑图,其实和上次画的基本一样.我下面提到的另一台机 ...
- 2014年 实验五 Internet与网络工具的使用
实验五 Internet与网络工具的使用 [实验目的] ⑴.FTP服务器的架设和客户端的使用. ⑵.使用云盘和云笔记应用 ⑶.运用QQ的远程协助功能. (4).默认安装foxmail软件,进行邮件 ...
- 用Pycharm创建指定的Django版本
最近在学习胡阳老师(the5fire)的<Django企业级开发实战>,想要使用pycharm创建django项目时,在使用virtualenv创建虚拟环境后,在pycharm内,无论如何 ...
- spring boot:swagger3文档展示分页和分栏的列表数据(swagger 3.0.0 / spring boot 2.3.3)
一,什么情况下需要展示分页和分栏的数据的文档? 分页时,页面上展示的是同一类型的列表的数据,如图: 分栏时,每行都是一个列表,而且展示的数据类型也可能不同 这也是两种常用的数据返回形式 说明:刘宏缔的 ...
- docker的常用操作之三:网络配置
一, docker安装后容器使用哪些网络类型? 在宿主机执行如下命令: [root@localhost liuhongdi]# docker network ls NETWORK ID NAME DR ...
- ffmpeg实现视频转gif及gif缩放(ffmpeg4.2.2)
一,为什么选择ffmpeg处理gif? 1,ffmpeg可以从视频中截取gif 2,ffmpeg在缩放gif时出错的机率较低, 而imagemagick在缩放gif时容易出错 我们在后面的例子中可以看 ...
- ansible通过yum/dnf模块给受控机安装软件(ansible2.9.5)
一,使用yum/dnf模块要注意的地方: 使用dnf软件安装/卸载时,需要有root权限, 所以要使用become参数 说明:刘宏缔的架构森林是一个专注架构的博客,地址:https://www.cnb ...