Elasticsearch分页解决方案
一、命令的方式做分页
1、常见的分页方式:from+size
elasticsearch默认采用的分页方式是from+size的形式,但是在深度分页的情况下,这种使用方式的效率是非常低的,比如from=5000,size=10,es需要在各个分片上匹配排序并得到5000*10条有效数据,然后在结果集中取最后10条数据返回。除了会遇到效率上的问题,还有一个无法解决的问题是es目前支持最大的skip值是max_result_window默认为10000,也就是说当from+size > max_result_window时,es将返回错误。
解决方案:
问题描述:比如当客户线上的es数据出现问题,当分页到几百页的时候,es无法返回数据,此时为了恢复正常使用,我们可以采用紧急规避的方式,就是将max_result_window的值调至50000。
- curl -XPUT "127.0.0.1:9200/custm/_settings" -d
- '{
- "index" : {
- "max_result_window" : 50000
- }
- }'
对于上面这种解决方案只是暂时解决问题,当es的使用越来越多时,数据量越来越大,深度分页的场景越来越复杂时,可以使用另一种分页方式scroll。
2、scroll方式
为了满足深度分页的场景,es提供了scroll的方式进行分页读取。原理上是对某次查询生成一个游标scroll_id,后续的查询只需要根据这个游标去取数据,知道结果集中返回的hits字段为空,就表示遍历结束。Scroll的作用不是用于实时查询数据,因为它会对es做多次请求,不肯能做到实时查询。它的主要作用是用来查询大量数据或全部数据。
使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id。根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于有跳页的情景
使用curl进行深度分页读取过程如下:
1、 先获取第一个scroll_id,url参数包括/index/type和scroll,scroll字段指定了scroll_id的有效生存时间,过期后会被es自动清理。
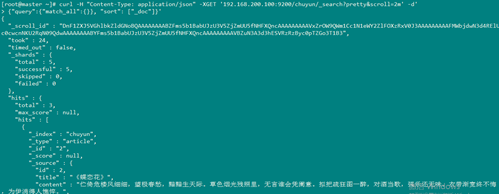
- [root@master ~]# curl -H "Content-Type: application/json" -XGET '192.168.200.100:9200/chuyun/_search?pretty&scroll=2m' -d'
- {"query":{"match_all":{}}, "sort": ["_doc"]}'
2、在遍历时候,拿到上一次遍历中的_scroll_id,然后带scroll参数,重复上一次的遍历步骤,直到返回的数据为空,表示遍历完成。
每次都要传参数scroll,刷新搜索结果的缓存时间,另外不需要指定index和type(不要把缓存的时时间设置太长,占用内存)后续查询:
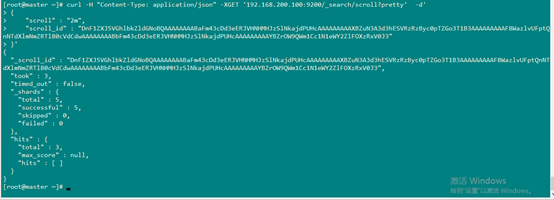
- curl -H "Content-Type: application/json" -XGET '192.168.200.100:9200/_search/scroll?pretty' -d'
- {
- "scroll" : "2m",
- "scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAABWFm43cDd3eERJVHNHMHJzSlNkajdPUHcAAAAAAAAAVxZuN3A3d3hESVRzRzByc0pTZGo3T1B3AAAAAAAAAFsWazlvUFptQnNTdXlmNmZRTl80cVdCdwAAAAAAAABVFm43cDd3eERJVHNHMHJzSlNkajdPUHcAAAAAAAAAWhZrOW9QWm1Cc1N1eWY2ZlFOXzRxV0J3"
- }'
3、scroll的删除
删除所有scroll_id
- curl -XDELETE 192.168.200.100:9200/_search/scroll/_all

指定scroll_id删除:
- curl -XDELETE 192.168.200.100:9200/_search/scroll -d
- '{"scroll_id" : ["cXVlcnlBbmRGZXRjaDsxOzg3OTA4NDpTQzRmWWkwQ1Q1bUlwMjc0WmdIX2ZnOzA7"]}'
3、 search_after 的方式
- 使用search_after必须要设置from=0。
- 这里我使用_id作为唯一值排序。
- 我们在返回的最后一条数据里拿到sort属性的值传入到search_after。
数据:

scroll的方式,官方不建议用于实时的请求(一般用于数据导出),因为每一个scroll_id不仅会占用大量的资源,而且会生成历史快照,对于数据的变更不会反映到快照上。而search_after分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时再分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。但是需要注意,因为每一页的数据依赖于上一页的最后一条数据,所以没法跳页请求。
为了找到每一页最后一条数据,每个文档那个必须有一个全局唯一值,官方推荐使用_uuid作为全局唯一值,当然在业务上的id也可以。
例如:在下面实例中我先根据id做倒序排列:
- curl -H "Content-Type: application/json" -XGET '192.168.200.100:9200/chuyun/_search?pretty' -d'
- {
- "size": 2,
- "from": 0,
- "sort": [
- {
- "_id": {
- "order": "desc"
- }
- }
- ]
- }'
结果:
- [root@master ~]# curl -H "Content-Type: application/json" -XGET '192.168.200.100:9200/chuyun/_search?pretty' -d'
- > {
- > "size": 2,
- > "from": 0,
- > "sort": [
- > {
- > "_id": {
- > "order": "desc"
- > }
- > }
- > ]
- > }'
- {
- "took" : 7,
- "timed_out" : false,
- "_shards" : {
- "total" : 5,
- "successful" : 5,
- "skipped" : 0,
- "failed" : 0
- },
- "hits" : {
- "total" : 3,
- "max_score" : null,
- "hits" : [
- {
- "_index" : "chuyun",
- "_type" : "article",
- "_id" : "3",
- "_score" : null,
- "_source" : {
- "id" : 3,
- "title" : "《青玉案·元夕》",
- "content" : "东风夜放花千树,更吹落,星如雨。宝马雕车香满路。凤箫声动,玉壶光转,一夜鱼龙舞。蛾儿雪柳黄金缕,笑语盈盈暗香去。众里寻他千百度,蓦然回首,那人却在,灯火阑珊处。",
- "viewCount" : 786,
- "createTime" : 1557471088252,
- "updateTime" : 1557471088252
- },
- "sort" : [
- "3"
- ]
- },
- {
- "_index" : "chuyun",
- "_type" : "article",
- "_id" : "2",
- "_score" : null,
- "_source" : {
- "id" : 2,
- "title" : "《蝶恋花》",
- "content" : "伫倚危楼风细细,望极春愁,黯黯生天际。草色烟光残照里,无言谁会凭阑意。拟把疏狂图一醉,对酒当歌,强乐还无味。衣带渐宽终不悔,为伊消得人憔悴。",
- "viewCount" : null,
- "createTime" : 1557471087998,
- "updateTime" : 1557471087998
- },
- "sort" : [
- "2"
- ]
- }
- ]
- }
- }
使用sort返回的值搜索下一页:
- curl -H "Content-Type: application/json" -XGET '192.168.200.100:9200/chuyun/_search?pretty' -d'
- {
- "size": 2,
- "from": 0,
- "search_after": [
- 2
- ],
- "sort": [
- {
- "_id": {
- "order": "desc"
- }
- }
- ]
- }'
结果:
- [root@master ~]# curl -H "Content-Type: application/json" -XGET '192.168.200.100:9200/chuyun/_search?pretty' -d'
- > {
- > "size": 2,
- > "from": 0,
- > "search_after": [
- > 2
- > ],
- > "sort": [
- > {
- > "_id": {
- > "order": "desc"
- > }
- > }
- > ]
- > }'
- {
- "took" : 12,
- "timed_out" : false,
- "_shards" : {
- "total" : 5,
- "successful" : 5,
- "skipped" : 0,
- "failed" : 0
- },
- "hits" : {
- "total" : 3,
- "max_score" : null,
- "hits" : [
- {
- "_index" : "chuyun",
- "_type" : "article",
- "_id" : "1",
- "_score" : null,
- "_source" : {
- "id" : 1,
- "title" : "《蝶恋花》",
- "content" : "槛菊愁烟兰泣露,罗幕轻寒,燕子双飞去。明月不谙离恨苦,斜光到晓穿朱户。昨夜西风凋碧树,独上高楼,望尽天涯路。欲寄彩笺兼尺素,山长水阔知何处?",
- "viewCount" : 678,
- "createTime" : 1557471087754,
- "updateTime" : 1557471087754
- },
- "sort" : [
- "1"
- ]
- }
- ]
- }
- }
二、java api做elasticsearch分页
按照一般的查询流程,比如我想查找前10条数据:
1、 客户端请求发给某个节点
2、 节点转发给各个分片,查询每个分片上的前10条数据
3、 结果返回给节点,整合数据,提取前10条
4、 返回给请求客户端
然而当我想查询第10条到20条的时候,就需要用到分页查询。
工具类:
- **
- * 构建elasticsrarch client
- */
- public class LowClientUtil {
- private static TransportClient client;
- public TransportClient CreateClient() throws Exception {
- // 先构建client
- System.out.println("11111111111");
- Settings settings=Settings.builder()
- .put("cluster.name","elasticsearch1")
- .put("client.transport.ignore_cluster_name", true) //如果集群名不对,也能连接
- .build();
- //创建Client
- TransportClient client = new PreBuiltTransportClient(settings)
- .addTransportAddress(
- new TransportAddress(
- InetAddress.getByName(
- "192.168.200.100"),
- 9300));
- return client;
- }
- }
准备数据:
- /**
- * 准备数据
- * @throws Exception
- */
- public static void createDocument100() throws Exception {
- for (int i = 1; i <= 100; i++) {
- try {
- HashMap<String, Object> map = new HashMap<>();
- map.put("title", "第" + i + "本书");
- map.put("author", "作者" + i);
- map.put("id", i);
- map.put("message", i + "是英国物理学家斯蒂芬·霍金创作的科学著作,首次出版于1988年。全书");
- IndexResponse response = client.prepareIndex("blog2", "article")
- .setSource(map)
- .get();
- // 索引名称
- String _index = response.getIndex();
- // 类型
- String _type = response.getType();
- // 文档ID
- String _id = response.getId();
- // 版本
- long _version = response.getVersion();
- // 返回的操作状态
- RestStatus status = response.status();
- System.out.println("索引名称:" + _index +
- " " + "类型 :" + _type + " 文档ID:" + _id +
- " 版本 :" + _version + " 返回的操作状态:" + status );
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
浅分页:from_size
原理:就比如查询前20条数据,然后截断前10条,只返回10-20条。
- /**
- * from-size
- searchRequestBuilder 的 setFrom【从0开始】 和 setSize【查询多少条记录】方法实现
- * */
- public static void sortPages(){
- // 搜索数据
- SearchRequestBuilder searchRequestBuilder = client.prepareSearch("blog2").setTypes("article")
- .setQuery(QueryBuilders.matchAllQuery());//默认每页10条记录
- final long totalHits = searchRequestBuilder.get().getHits().getTotalHits();//总条数
- final int pageDocument = 10 ;//每页显示多少条
- final long totalPage = totalHits / pageDocument;//总共分多少页
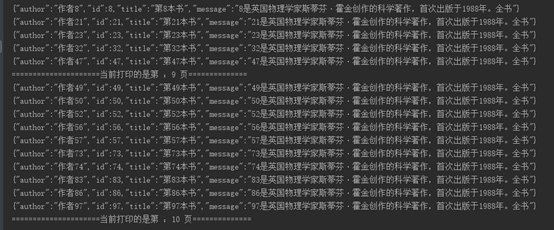
- for(int i=1;i<=totalPage;i++){
- System.out.println("=====================当前打印的是第 :"+i+" 页==============");
- //setFrom():从第几条开始检索,默认是0。
- //setSize():查询多少条文档。
- searchRequestBuilder.setFrom(i*pageDocument).setSize(pageDocument);
- SearchResponse searchResponse = searchRequestBuilder.get();
- SearchHits hits = searchResponse.getHits();
- Iterator<SearchHit> iterator = hits.iterator();
- while (iterator.hasNext()) {
- SearchHit searchHit = iterator.next(); // 每个查询对象
- System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
- }
- }
- }
使用scroll深分页:
对于上面介绍的浅分页(from-size),当Elasticsearch响应请求时,它必须确定docs的顺序,排列响应结果。
如果请求的页数较少(假设每页20个docs), Elasticsearch不会有什么问题,但是如果页数较大时,比如请求第20页,Elasticsearch不得不取出第1页到第20页的所有docs,再去除第1页到第19页的docs,得到第20页的docs。
解决的方式就是使用scroll,scroll就是维护了当前索引段的一份快照信息--缓存(这个快照信息是你执行这个scroll查询时的快照)在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。但是它相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
可以把 scroll 分为初始化和遍历两步:
1、初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照;
2、遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果
- public static void scrollPages(){
- //获取Client对象,设置索引名称,搜索类型(SearchType.SCAN)[5.4移除,对于java代码,直接返回index顺序,不对结果排序],搜索数量,发送请求
- SearchResponse searchResponse = client
- .prepareSearch("blog2")
- .setSearchType(SearchType.DEFAULT)//执行检索的类别
- .setSize(10).setScroll(new TimeValue(1000)).execute()
- .actionGet();//注意:首次搜索并不包含数据
- //获取总数量
- long totalCount=searchResponse.getHits().getTotalHits();
- int page=(int)totalCount/(10);//计算总页数
- System.out.println("总页数: ================="+page+"=============");
- for (int i = 1; i <= page; i++) {
- System.out.println("=========================页数:"+i+"==================");
- searchResponse = client
- .prepareSearchScroll(searchResponse.getScrollId())//再次发送请求,并使用上次搜索结果的ScrollId
- .setScroll(new TimeValue(1000)).execute()
- .actionGet();
- SearchHits hits = searchResponse.getHits();
- for(SearchHit searchHit : hits){
- System.out.println(searchHit.getSourceAsString());// 获取字符串格式打印
- }
- }
- }
Elasticsearch分页解决方案的更多相关文章
- 重构MVC多条件分页解决方案
重构MVC多条件+分页解决方案 为支持MVC的验证,无刷新查询,EF,以及让代码可读性更强一点,所以就重构了下原来的解决方案. 这里就简单讲下使用方法吧: Model: 继承PagerBase: S ...
- JS(vue iview)分页解决方案
JS(vue iview)分页解决方案 一.解决思路 使用分页组件 使用组件API使组件自动生成页面数量 调用组件on-change事件的返回值page 将交互获得的数组存在一个数组list中 通过p ...
- elasticsearch 分页查询实现方案——Top K+归并排序
elasticsearch 分页查询实现方案 1. from+size 实现分页 from表示从第几行开始,size表示查询多少条文档.from默认为0,size默认为10,注意:size的大小不能超 ...
- 使用elasticsearch分页时报max_result_window is too large的错误解决方案
使用elasticsearch进行深度分页查询时的size-from大于10000的时候,会提示一个max_result_window is too large的错误. 官方推荐是scroll查询返回 ...
- ElasticSearch 深度分页解决方案 {"index":{"number_of_replicas":0}}
常见深度分页方式 from+size es 默认采用的分页方式是 from+ size 的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如 from = 5000, size=10, es ...
- ElasticSearch 深度分页解决方案
常见深度分页方式 from+size 另一种分页方式 scroll scroll + scan search_after 的方式 es 库 scroll search 的实现 常见深度分页方式 fro ...
- Elasticsearch 分页坑之---评分一致导致数错乱
面试:你懂什么是分布式系统吗?Redis分布式锁都不会?>>> 1.背景介绍 最近搞es搜索,match查询默认按照评分排序,发现有一部分数据评分一致,一开始也没注意,客户端调用 ...
- 重构MVC多条件+分页解决方案
为支持MVC的验证,无刷新查询,EF,以及让代码可读性更强一点,所以就重构了下原来的解决方案. 这里就简单讲下使用方法吧: Model: 继承PagerBase: 1 public class Sea ...
- Elasticsearch——分页查询From&Size VS scroll
Elasticsearch中数据都存储在分片中,当执行搜索时每个分片独立搜索后,数据再经过整合返回.那么,如果要实现分页查询该怎么办呢? 更多内容参考Elasticsearch资料汇总 按照一般的查询 ...
随机推荐
- PyQt(Python+Qt)学习随笔:QTableView的gridStyle属性
老猿Python博文目录 老猿Python博客地址 概述 gridStyle属性用于控制视图数据网格的样式,此属性只有在showGrid属性为True时才有作用. gridStyle属性取值含义 gr ...
- Python基础知识学习随笔
Python学习随笔:PyCharm的错误检测使用及调整配置减少错误数量 Python学习随笔:获取当前主机名和用户名的方法 博客地址:https://blog.csdn.net/LaoYuanPyt ...
- 孪生网络入门(下) Siamese Net分类服装MNIST数据集(pytorch)
主题列表:juejin, github, smartblue, cyanosis, channing-cyan, fancy, hydrogen, condensed-night-purple, gr ...
- 半夜删你代码队 Day1冲刺
一.团队信息 1.团队项目:Midnight聊天室 2.团队名称:半夜删你代码队 3.队员信息: 职务 项目经理 主开发团队 测试人员 姓名 陈惠霖 周楚池 侯晓龙 余金龙 胡兆禧 林涛 二.Alph ...
- 题解 CF1428G Lucky Numbers (Easy Version and Hard Version)
这题没有压行就成 \(\texttt{Hard Version}\) 最短代码解了( 要知道这题那么 \(sb\) 就不啃 \(D\) 和 \(E\) 了. \(\texttt{Solution}\) ...
- AcWing 324. 贿赂FIPA
题目链接 大型补档计划 \(f[i][j]\) 表示第 \(i\) 个国家,获得 \(j\) 个国家支持,用的最少花费 \(f[i][0] = 0\) \(f[i][sz[i]] = w[i]\) 对 ...
- 苹果M1芯片各种不支持,但居然可以刷朋友圈!你会买单吗?
上个月和大家一起分享过,最新的苹果M1芯片上支持的各种开源软件.什么?还没读过?赶紧点这里:一文解读苹果 M1 芯片电脑上的开源软件. 现在已经过去了半个月,想必有不少的同学都已经入手了最新的苹果M1 ...
- shell--检查apache是否启动脚本
#首先我们需要检查apache是否以启动,这里我们用到的说nmap命令,Linux默认情况下是没有安装nmap命令的. #那么我们需要安装下nmap,安装的命令很简单:yum -y install n ...
- 移动端 FileReader文件上传
一.file上传文件 <input type="file" multiple> multiple 设置多选 通过change事件监听是否上传文件 files 属性获 ...
- 被 Pandas read_csv 坑了
被 Pandas read_csv 坑了 -- 不怕前路坎坷,只怕从一开始就走错了方向 Pandas 是python的一个数据分析包,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的 ...