Prometheus-Alertmanager告警对接到企业微信
之前写过将Prometheus的监控告警信息通过Alertmanager推送到钉钉群。
最近转移了阵地,需要将Prometheus监控告警信息推送到企业微信群,经过两天的摸索,以及查了网上的一些资料,总结了此文,避免后面的同学走弯路。
Alertmanager将告警信息推送到微信群,主要涉及到如下几方面的配置:
- 企业微信后台的配置,包括新建告警部门和应用;
- Alertmanager的主配置文件配置和告警模板配置;
- Prometheus主配置文件的配置以及告警规则的配置;
下面就这三点分别进行介绍
1、企业微信后台配置
这里就不得不啰嗦几句,[互联]网大了,什么鸟都有,天下文章一大抄,管它对于不对,先转到自己博客再说。真正能够自己验证,能够理解其告警策略和原理的能有几人?
1.1 企业ID获取
首先访问企业微信官网:https://work.weixin.qq.com/
注册一个企业,当前是谁都可以注册,没有任何限制,也不需要企业认证,注册即可。
注册完成之后,登录后台管理,在【我的企业】这里,先拿到后面用到的第一个配置:企业ID

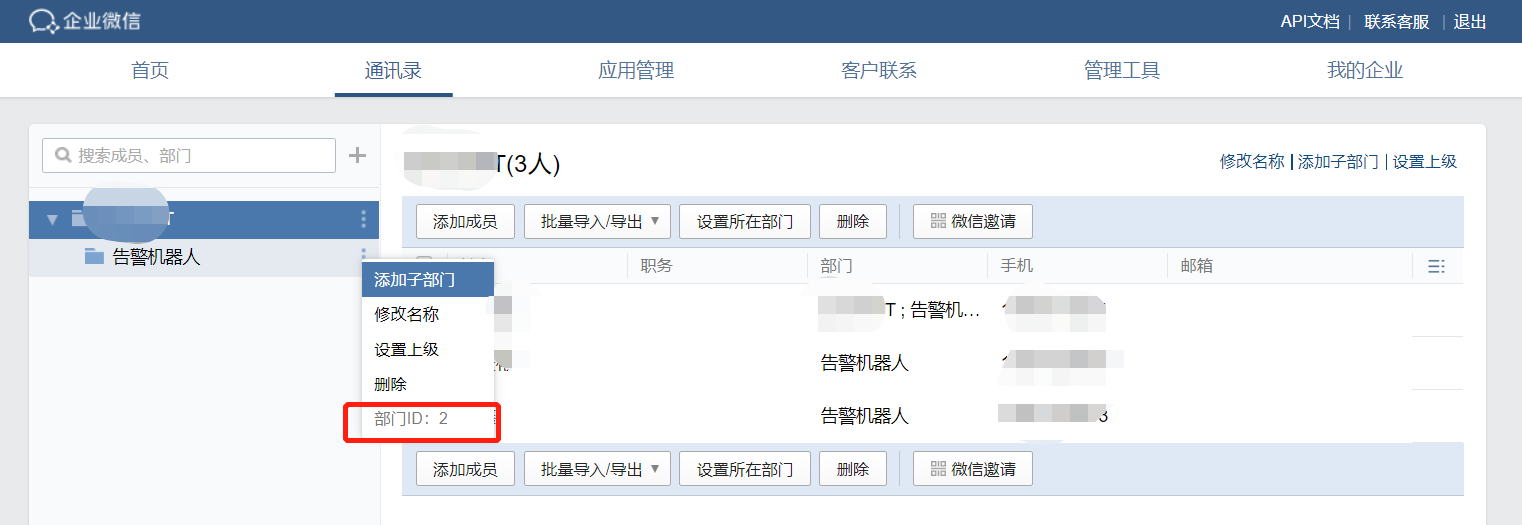
1.2 部门ID获取
然后在通讯录中,添加一个子部门,用于接收告警信息,后面把人加到该部门,这个人就能接收到告警信息了。

获得我们配置告警的第二个参数:部门ID 2
1.3 告警AgentId和Secret获取
告警AgentId和Secret获取是需要在企业微信后台,【应用管理】中,自建应用才能够获得的。这里网上介绍的非常多,都只是说了这一步骤,而忽略了其他几个重要的步骤。


最后点击创建应用,可以看到我们刚才创建好的应用Prometheus。
点击这个应用,可以看到我们想要的AgentId和Secret
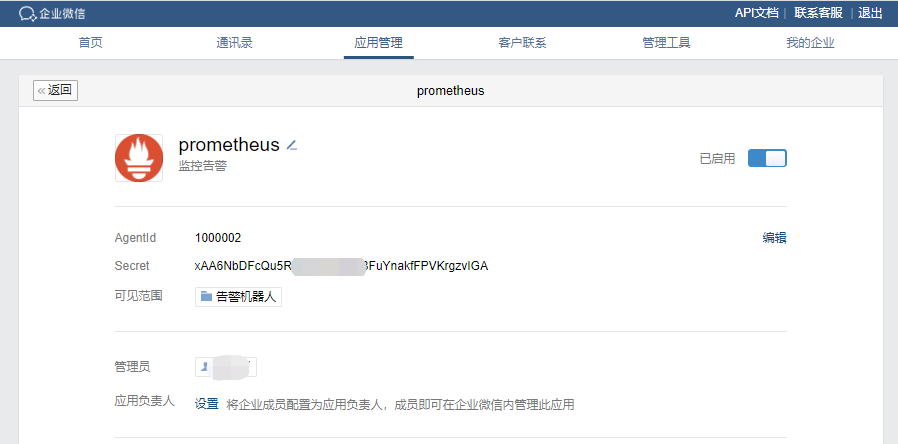
以上步骤完成后,我们就得到了配置Alertmanager的所有信息,包括:企业ID,AgentId,Secret和接收告警的部门id
下面我们来配置Alertmanager服务
2、Alertmanager服务配置
2.1 主配置文件
# 主配置文件信息如下:
cat /opt/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m # 每1分钟检测一次是否恢复
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_corp_id: 'bbbbbbbbbbbbbbbb' # 企业微信中企业ID
wechat_api_secret: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 企业微信中,应用的Secret templates:
- '/opt/alertmanager/template/*.tmpl' route:
receiver: 'wechat'
group_by: ['env','instance','type','group','job','alertname']
group_wait: 10s # 初次发送告警延时
group_interval: 10s # 距离第一次发送告警,等待多久再次发送告警
repeat_interval: 5m # 告警重发时间 receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '2' # 企业微信中创建的接收告警的部门【告警机器人】的部门ID
agent_id: '1000002' # 企业微信中创建的应用的ID
api_secret: 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 企业微信中,应用的Secret
2.2 告警模板
# cat /opt/alertmanager/template/wechat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 异常恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
2.3 Prometheus集成
下面配置prometheus告警规则
主配置文件:prometheus.yml中加入:
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/node_status.yml"
然后配置告警规则文件:node_status.yml
# cat rules/node_status.yml [root@cn-prom prometheus-server]# cat rules/node_status.yml
groups:
- name: 实例存活告警规则
rules:
- alert: 实例存活告警
expr: up{job="prometheus"} == 0 or up{job="Linux-host"} == 0
for: 1m
labels:
user: prometheus
severity: Disaster
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "Instance {{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
value: "{{ $value }}" - name: 内存告警规则
rules:
- alert: "内存使用率告警"
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 75
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器: {{$labels.alertname}} 内存报警"
description: "{{ $labels.alertname }} 内存资源利用率大于75%!(当前值: {{ $value }}%)"
value: "{{ $value }}" - name: CPU报警规则
rules:
- alert: CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 70
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器: {{$labels.alertname}} CPU报警"
description: "服务器: CPU使用超过70%!(当前值: {{ $value }}%)"
value: "{{ $value }}" - name: 磁盘报警规则
rules:
- alert: 磁盘使用率告警
expr: (node_filesystem_size_bytes - node_filesystem_avail_bytes) / node_filesystem_size_bytes * 100 > 80
for: 1m
labels:
user: prometheus
severity: warning
annotations:
summary: "服务器: {{$labels.alertname}} 磁盘报警"
description: "服务器:{{$labels.alertname}},磁盘设备: 使用超过80%!(挂载点: {{ $labels.mountpoint }} 当前值: {{ $value }}%)"
value: "{{ $value }}"
至此,企业Prometheus对接企业微信告警完毕,出现故障你就能看到如下告警信息和恢复信息了
========= 监控报警 =========
告警状态:firing
告警级别:Disaster
告警类型:实例存活告警
故障主机: 10.137.10.211:9100
告警主题: Instance 10.137.10.211:9100 is down
告警详情: Instance 10.137.10.211:9100 of job Linux-host has been down for more than 1 minutes.;
触发阀值:0
故障时间: 2020-09-21 10:21:08
========= = end = ========= ========= 异常恢复 =========
告警类型:实例存活告警
告警状态:resolved
告警主题: Instance 10.137.10.211:9100 is down
告警详情: Instance 10.137.10.211:9100 of job Linux-host has been down for more than 1 minutes.;
故障时间: 2020-09-21 10:21:08
恢复时间: 2020-09-21 10:26:23
实例信息: 10.137.10.211:9100
========= = end = =========
以上,请测试验证,如有描述不清楚的地方,欢迎留言交流。
Prometheus-Alertmanager告警对接到企业微信的更多相关文章
- Prometheus+alertmanager告警配置-2
prometheus 告警 prometheus 通过alertmanager进行告警 实现监控告警的步骤: 在prometheus中定义告警规则rule_files alertmanager配置告警 ...
- Prometheus(五):Prometheus+Alertmanager 配置企业微信报警
此处默认已安装Prometheus服务,服务地址:192.168.56.200 一.设置企业微信 1.1.企业微信注册(已有企业微信账号请跳过) 企业微信注册地址:https://work.weix ...
- prometheus 通过企业微信接收告警
准备工作 step 1: 访问网站 注册企业微信账号(不需要企业认证). step 2: 访问apps 创建第三方应用,点击创建应用按钮 -> 填写应用信息: prometheus 配置: # ...
- Prometheus 企业微信报警/inhibit抑制 /静默(二)
创建企业微信应用 注册企业微信:访问https://work.weixin.qq.com/,注册企业,随便填,不需要认证 创建应用 创建告警配置 vim /usr/local/prometheus-2 ...
- Prometheus + Alertmanager 实现企微告警
上一篇:二进制安装Prometheus 下面准备在监控的流程中呈现到告警到企微 查看企业ID,用于后续配置文件 四.安装Alertmanager1.准备安装的包 --选择上面链接给的Linux的ta ...
- Prometheus alertmanager邮件发送+grafana告警展示
前言 前面一篇博客,我已经介绍了prometheus如何监控mysql. 这一篇我来介绍如何通过alertmanger进行告警邮件发送(微信或钉钉类似,因为需要企业帐户,我就不试了),以及如何通过gr ...
- [k8s]prometheus+alertmanager二进制安装实现简单邮件告警
本次任务是用alertmanaer发一个报警邮件 本次环境采用二进制普罗组件 本次准备监控一个节点的内存,当使用率大于2%时候(测试),发邮件报警. k8s集群使用普罗官方文档 环境准备 下载二进制h ...
- Prometheus学习笔记(6)Alertmanager告警
目录 一.Alertmanager简介 二.Alertmanager部署 三.Alertmanager配置 四.自定义告警规则和发送 五.自定义告警模板 一.Alertmanager简介 Promet ...
- jmx_prometheus_javaagent+prometheus+alertmanager+grafana完成容器化java监控告警(二)
一.拓扑图 二.收集数据 2.1前期准备 创建共享目录,即为了各节点都创建该目录,有两个文件,做数据共享 /home/target/prom-jvm-demo 1.下载文件 jmx_prometheu ...
随机推荐
- 原生js实现 vue的数据双向绑定
原生js实现一个简单的vue的数据双向绑定 vue是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时 ...
- gorm demo
package main import ( "fmt" "github.com/jinzhu/gorm" _ "github.com/jinzhu/g ...
- Robot Framework(5)——自动化示例
上篇介绍了一些selenium2在robot framework中的一些关键字,这一篇主要来记录一下实际应用 一.安装并导入Selenium2Library 安装的工作一开始已经完成,可以用pip l ...
- 封装Vue Element的upload上传组件
本来昨天就想分享封装的这个upload组件,结果刚写了两句话,就被边上的同事给偷窥上了,于是在我全神贯注地写分享的时候他就神不知鬼不觉地突然移动到我身边,腆着脸问我在干啥呢.卧槽你妈,当场就把我吓了一 ...
- 超级码力编程赛带着6万奖金和1200件T恤向你跑来了~
炎炎夏日,总是感觉很疲劳,提不起一点精神怎么办?是时候参加一场比赛来唤醒你的激情了!阿里云超级码力在线编程大赛震撼携手全国数百所高校震撼来袭. 它来了,它来了,它带着60000现金和1200件T恤向你 ...
- LeetCode 94 | 基础题,如何不用递归中序遍历二叉树?
今天是LeetCode专题第60篇文章,我们一起来看的是LeetCode的94题,二叉树的中序遍历. 这道题的官方难度是Medium,点赞3304,反对只有140,通过率有63.2%,在Medium的 ...
- activemq的搭建
说在前面的话: 本节主要介绍activemq的介绍以及activemq的安装,希望可以给迷惑中的读者带来一丝灵感,activemq的安装是基于linux环境下的 准备的环境: 一台安装jdk的linu ...
- rabbitmq用户权限
none:无法登录控制台 不能访问 management plugin,通常就是普通的生产者和消费者. management:普通管理者. 仅可登陆管理控制台(启用management plugin的 ...
- JS开发必须知道的41个技巧
JS是前端的核心,但有些使用技巧你还不一定知道:本文梳理了JS的41个技巧,帮助大家提高JS的使用技巧: Array 1.数组交集 普通数组 const arr1 = [, , , , , ,],ar ...
- Android,java,php开发最基本的知识,mysql sqlite数据库的增删改查代理,sql语句
作者:程序员小冰,CSDN博客:http://blog.csdn.net/qq_21376985转载请说明出处. 下面是代码: 增加:insert into 数据表(字段1,字段2,字段3) valu ...