最新小样本学习综述 A Survey on Few-Shot Learning | 四大模型Multitask Learning、Embedding Learning、External Memory…
相关阅读:
A Survey on Few-Shot Learning | Introduction and Overview
A Survey of Few-Shot Learing | Data
原文链接: 小样本学习与智能前沿
给定少数样本的\(D_{train}\),仅使用简单模型(例如线性分类器)就可以选择较小的H (假设空间)[92,94]。 但是,现实世界中的问题通常很复杂,并且不能由小H的假设h很好地表示[45]。 因此,在FSL中最好使用足够大的H,这使得标准的机器学习模型不可行。
本节中的FSL方法通过根据E中的先验知识将H约束到较小的假设空间H 来进行学习(图2(b))。
这样,经验风险最小化器将更加可靠,并降低过度拟合的风险。
根据所使用的先验知识,可以将属于该类别的方法进一步分为四种类型(表4)。

下面我们会分别介绍这四种类型
01 Multitask Learning
在存在多个相关任务的情况下,多任务学习[23,161]通过利用任务通用信息和特定于任务的信息同时学习这些任务。 因此,它们自然可以用于FSL。 在这里,我们介绍了在FSL中使用多任务学习的一些实例。
我们获得了与C有关的任务\(T_1\),……,\(T_C\),其中一些样本很少,而每个任务的样本数很多。每个任务\(T_c\)都有一个数据集\(D_c = \left\{D^c_{train},D^c_{test}\right\}\),其中前者是训练集,后者是测试集。 在这些C任务中,我们将few-shot任务作为目标任务,其余作为源任务。 多任务学习从\(D^c_{train}\)学习\(T_c\)的参数\(θ_c\).
由于这些任务是联合学习的,因此为任务\(T_c\)学习的\(h_c\)的参数\(θ_c\)受其他任务的约束。 根据任务参数的约束方式,我们将该策略中的方法划分为(i)参数共享; (ii)参数绑定[45]。
01.1 Parameter Sharing
该策略直接在任务之间共享一些参数(图5)。在[160]中,两个任务网络共享通用信息的前几层,并学习不同的最终层以处理不同的输出。在[61]中,法律文本上的两个自然语言处理任务被一起解决:收费预测和法律属性预测。单个嵌入功能用于对犯罪案件描述进行编码,然后将其馈送到特定于任务的嵌入功能和分类器。在[95]中,首先从源任务中训练变型自动编码器,然后将其克隆到目标任务。为了捕获通用信息,两个变体自动编码器中的某些层是共享的,同时允许两个任务都具有一些特定于任务的层。目标任务只能更新其特定于任务的层,而源任务可以同时更新共享和特定于任务的层。在[12]中,首先通过学习针对源任务和目标任务的单独的嵌入函数,将原始样本和生成的样本都映射到特定于任务的空间,然后通过共享的可变自动编码器进行嵌入。

01.2 Parameter Tying.
这种策略要求不同任务的参数\((θ_c's)\)相似(图6)[45]。
一种流行的方法是对\((θ_c's)\)进行正则化。
在[151]中,\(θ_c's\)的所有成对差异都受到了惩罚。 在[85]中,有一个CNN用于源任务,另一个用于目标任务。 这两个CNN的层使用一些特殊设计的正则化术语对齐。

02 Embedding Learning
嵌入学习[63,122]将每个样本\(x_i∈X⊆R_d\)嵌入到低维\(z_i∈Z⊆R_m\),这样相似的样本会紧密靠近,而异类的样本则更容易区分。
然后,在这个较低维的Z中,可以构造一个较小的假设空间H,随后需要较少的训练样本。嵌入功能主要是从先验知识中学到的,并且可以额外使用\(D_{train}\)的任务特定信息。
嵌入学习具有以下关键组成部分:
(i)将测试样本\(x_{test}∈D_{test}\)嵌入Z的函数f,
(ii)将训练样本\(x_i∈D_{train}\)嵌入Z的函数g
(iii)相似性函数\(s(· ,·)\)来测量\(f(x_{test})\)和Z中的\(g(x_i)\)之间的相似度。
根据该类的嵌入\(g(x_i)\)与Z中的\(f(x_{test})\)最相似, 将测试样本\(x_{test}\)分配给\(x_i\)类。尽管可以为\(x_i\)和\(x_{test}\)使用通用的嵌入函数,但是使用两个单独的嵌入函数可以获得更好的准确性[14,138]。表5总结了现有的嵌入学习方法。
根据嵌入函数f和g的参数是否随任务而变化,我们将这些FSL方法归类为(i)特定于任务的嵌入模型; (ii)不变任务(即一般)嵌入模型; (iii)混合嵌入模型,可同时编码特定于任务的信息和不变于任务的信息。

02.1 Task-Specific Embedding Model.
Task-specific embedding methods 通过仅使用来自该任务的信息为每个任务量身定制嵌入函数。例如:给定任务\(T_c\)的few-shot数据\(D^c_{train}\),\(D^c_{train}\)中样本之间的所有成对排名都被枚举为样本对[130], 训练样本的数量因此增加,并且即使仅使用特定于任务的信息也可以学习嵌入函数。
02.2 Task-Invariant Embedding Model.
任务不变的嵌入方法从包含足够样本且具有各种输出的大规模数据集中学习通用嵌入函数,然后将其直接用于新的few-shot \(D_{train}\),而无需重新训练(图7)。 第一个FSL嵌入模型[36]使用内核嵌入样本。 最近,卷积孪生网络[20]学会了更复杂的嵌入[70,150]。

尽管任务不变式嵌入不会使用few-shot \(D_{train}\)的嵌入模型更新参数,但该类别中的许多方法[121、126、138]都会在训练嵌入模型的时候模拟few-shot场景。 假设我们有训练集{Dc},每个训练集都有N个类别。 在每个Dc中,仅从N个类别中采样U个类别进行训练。 嵌入模型通过最大化剩下的N-U个类别的性能来进行优化。 因此,学习到的模型对于few-shot 任务具有较好的泛化性。
一个早期的尝试[127]从{Dc}中学习了一个线性嵌入。 最近,一个更加复杂的task-invariant 嵌入模型通过meta-learning 方法学习得出。
(1) Matching Nets[138] and its variants[4,8,24]
Matching Nets 为训练样本\(x_i\)和测试样本\(x_{test]\)元学习了不同的嵌入函数(f and g)。The residual LSTM(resLSTM)[4] 为f和g提出了更好的设计。Matching Nets的一个主动学习变体[8] 添加了一个样本选择步骤,用来标记最好的无标签样本以此来增强\(D_{train}\). Matching Nets也扩展到了Set-to-Set匹配[24],这在标记样本的多个部分时很有用。
(2)Prototypical Networks (ProtoNet) [121] and its variants [100, 108, 141]
ProtoNet[121]只比较\(f(x_{test})\)和类训练集中的类原形。对类n,其原型由如下公式计算得出:
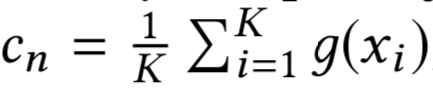
这种方法可以使得结果更稳定且减少计算损失。使用原型的思想被引入到Matching Nets中[141]. ProtoNet的半监督变体在学习过程中通过soft-assignment来分配未标记的样本以增强Dtrain [108]。
(3)Other methods.
例子包括Attentive Recurrent Comparators(ARC)[119],它使用LSTM引起关注[9],将\(x_{test}\)的不同区域与原型\(c_n\)进行比较,然后将比较结果作为中间嵌入。 此外,它使用双向LSTM(biLSTM)嵌入所有比较作为最终嵌入。[84,115]中使用图神经网络(GNN)来利用来自本地邻居的信息。 在few-shot的强化学习应用程序中(如在连续控制和视觉导航中),时间信息很重要。 简单神经注意力学习者(SNAIL)[91]是一个具有交错的时间卷积层和注意力层的嵌入网络。 时间卷积层聚合来自过去时间步长的信息,而注意层选择性地关注与当前输入相关的特定时间步长。
02.3 Hybrid Embedding Model.
尽管可以将task-invariant的嵌入方法以较低的计算成本应用于新任务,但是它们没有利用当前任务的特定知识。 当任务特性是Dtrain仅提供一些示例的原因(例如,学习稀有案例)时,仅应用task-invariant的嵌入函数可能不适合。 为了缓解这个问题,混合嵌入模型(Hybrid)通过Dtrain中的特定于任务的信息来适应从先验知识中学到的通用任务不变式嵌入模型。这是通过学习将Dtrain中提取的信息作为输入并返回一个嵌入来作为f(·)的参数(图8)。

Learnet [14]通过结合Dtrain的特定信息来改进任务不变卷积孪生网络[70]。 它从多个元训练集中学习一个元学习器,并将每个训练示例\(x_i∈D_{train}\)映射到学习器的参数(卷积孪生网络)。 这样,\(f(·)\)的参数随给定的\(x_i\)改变,从而导致混合嵌入。
[13] 在Learnet上进行了改进,将学习器的分类层替换为ridge回归,从而可以有效地以封闭形式获取参数。 以下两项工作[100,162]将Dtrain作为一个整体来输出\(f(·)\)的任务特定参数。 任务相关的自适应量度(TADAM)[100]将类原型平均化到任务嵌入中,并使用元学习函数将其映射到ProtoNet参数。 动态条件卷积网络(DCCN)[162]使用一组固定的滤波器,并使用Dtrain学习组合系数。
03 Learning with External Memory
使用外部存储器[49、89、124、145]学习从\(D_{train}\)中提取知识,并将其存储在外部存储器中(图9)。 然后,每个新样本\(x_{test}\)由从内存中提取的内容的加权平均值表示。 这限制了\(x_{test}\)由内存中的内容表示,因此实质上减小了H的大小。

FSL中通常使用键值存储器[89]。 令存储器为\(M∈R^{b×m}\),其b个存储插槽\(M(i)∈R^m\)中的每一个都由键值对\(M(i)=(M_{key}(i),M_{value}(i))\)组成。 首先通过嵌入函数f嵌入测试样本\(x_{test}\)。 但是,与嵌入方法不同,\(f(x_{test})\)不能直接用作\(x_{test}\)的表示形式。 相反,它仅用于基于\(f(x_{test})\)与每个键\(M_{key}(i)\)之间的相似度\(s(f(x_{test}),M_{key}(i))\)查询最相似的内存插槽。 提取最相似的内存插槽(\(M_{value}(i)\))的值并将其组合起来,以表示\(x_{test}\)。 然后将其用作简单分类器(例如softmax函数)的输入以进行预测。 由于操纵M的成本很高,因此M通常尺寸较小。 当M未满时,可以将新样本写入空闲的存储插槽。 当M已满时,必须决定要更换的内存插槽。 表6介绍了带有外部存储器的方法的特性。

由于每个\(x_{test}\)表示为从内存中提取的值的加权平均值,因此内存中键值对的质量非常重要。 根据存储器的功能,该类别中的FSL方法可以细分为两种类型。
03.1 Refining Representations.
下列方法将\(D_{train}\)小心地放入内存中,以便存储的键值对可以更准确地表示\(x_{test}\)。 记忆增强神经网络(MANN)[114]元学习嵌入f,并将相同类别的样本映射到相同值。 然后,同一类的样本一起在内存中优化它们的类表示。 在ProtoNet [121]中,可以将此类表示形式视为精致的类原型。
surprise-based 存储模块[104]仅在其不能很好地表示\(x_i\)时更新M。因此,使用该\(x_i\)更新M使得M更具表达性,并且还降低了计算成本。抽象存储器[149]使用两个存储器。一种从包含大型机器注释数据集的固定存储器中提取相关的键值对,另一种则对提取的值进行精炼并提取出最有用的信息,以进行few-shot(图像)分类。这个想法在[164]中扩展到了few-shot视频分类。
沿着这条思路,一些方法特别注意保护内存中的few-shot类。请注意,few-shot类很小,因此保留在M中的机会较小。M中的每个few-shot样本也可以很容易地用更丰富类中的样本替换。为了减轻这个问题,提出了lifelong memory(终生记忆)[65]。与以前的存储器[104、114、149、164]会擦除任务中的存储器内容不同,终身存储器会在存储器已满时擦除“最旧”的存储器值,然后将所有存储器插槽的使用期限重置为零。对于新样本,当返回的\(M_{value}(i)\)值与其实际输出匹配时,它将与当前\(M_{key}\)(i)合并,而不是写入新的内存插槽,因此,所有类都更有可能被占用相同数量的内存插槽,并保护了稀有类,最近,这种终身内存适用于学习单词表示[125]。
但是,即使使用了终生记忆,仍然可以忘记稀有样品。每次更新后,终生内存会将所选\(M(i)\)的使用期限重置为零,并将其他非空内存插槽的使用期限增加一。当内存已满且返回值错误时,将替换最早的内存插槽。由于稀有类别的样本很少更新其\(M(i)\),因此它们被擦除的可能性更高。
03.2 Refining Parameters.
回想一下,Learnet [14]及其变体(第4.2.3节)从\(D_{train}\)映射信息,以参数化新\(x_{test}\)的嵌入函数\(g(·)\)。 可以使用存储器来完善此参数。 元网络(MetaNet)[96]使用从多个数据集元学习的“慢”权重和作为\(D_{train}\)特定任务的嵌入的“快速”权重,对分类模型进行参数化。 如[97]所示,通过学习修改每个神经元而不是完整的参数,可以降低MetaNet的计算成本。 MN-Net [22]使用内存来完善在Matching Nets中学习的嵌入,如Learnet一样,其输出用于对CNN进行参数化。
04 Generative Modeling
生成建模方法借助先验知识(图10)从观测到的\(x_i\)估计概率分布\(p(x)\)。\(p(x)\)的估计通常涉及\(p(x | y)\)和\(p(y)\)的估计。 此类中的方法可以处理许多任务,例如生成[34、76、107、109],识别[34、35、47、76、113、129、159],重构[47]和图像翻转[107] ]。

在生成建模中,假定观察到的\(x\)是从由\(θ\)参数化的某些分布\(p(x;θ)\)得出的。 通常,存在一个潜在变量\(z〜p(z;γ)\),因此\(x〜∫p(x | z;θ)p(z;γ)dz\)。 从其他数据集获悉的先验分布\(p(z;γ)\)带来了对FSL至关重要的先验知识。通过将提供的训练集\(D_{train}\)与此\(p(z;γ)\)结合,约束了后验概率分布。 换句话说,将H约束为更小的H ̃。
根据潜在变量\(z\)表示的内容,我们将这些FSL生成建模方法分为三种类型。
04.1 Decomposable Components.
可分解成分。
尽管在FSL问题中缺少具有监督信息的样本,但它们可能与其他任务的样本共享一些较小的可分解组件。例如,考虑仅使用提供的几张面部照片识别一个人。尽管可能很难找到相似的面孔,但可以轻松找到眼睛,鼻子或嘴巴相似的照片。使用大量样本,可以轻松了解这些可分解组件的模型。然后,仅需要找到这些可分解组件的正确组合,并确定该组合属于哪个目标类。由于可分解成分是由人类选择的,因此这种策略更具可解释性。 Bayesian One-Shot [35]使用生成模型来捕获可分解组件(即对象的形状和外观)与目标类别(即要识别的对象)之间的交互。贝叶斯程序学习(BPL)[76]通过将字符分为类型,标记以及其他模板,部分和原语来对字符进行建模。为了产生一个新的角色,需要搜索一个包含这些成分的大组合空间。在[76]中,仅通过考虑可能的最高组合就可以降低这种推理成本。在自然语言处理中,最近的工作[64]建立了跨度而不是完整的解析树的模型,并通过训练跨度的单个分类器来使语法分离的域之间的解析器适应。
04.2 Groupwise Shared Prior.
分组共享优先。
通常,相似的任务具有相似的先验概率,并且可以在FSL中使用。 例如,考虑“橙色猫”,“豹”和“孟加拉虎”的三级分类,这三个物种相似,但孟加拉虎濒临灭绝,而橙色猫和豹则丰富,因此,人们可以学习一种 来自“橙色猫”的先验概率,以及“豹”,并以此作为few-shot类级“孟加拉虎”的先决条件。
在[113]中,一组数据集{\(D_c\)}通过无监督学习被分组为一个层次结构。 每个组中的数据集一起学习类级先验概率。 对于一个新的few-shot类,首先找到该新类所属的组,然后根据从按组共享的先验概率中提取的先验类对它进行建模。 在[129]中,[113]中的特征学习步骤通过使用深度玻尔兹曼机[112]得到进一步改进。
04.3 Parameters of Inference Networks.
推理网络的参数。
为了找到最佳的θ,必须最大化后验:
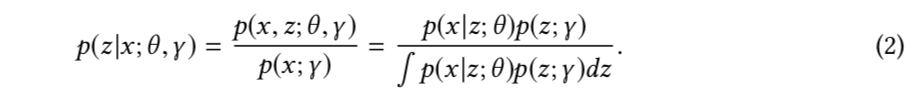
由于分母中的积分,所以难于求解(2)。 从数据中学习到的变化分布\(q(z;δ)\)通常用于近似\(p(z | x;θ,γ)\)。 最近,这个\(q(z;δ)\)是通过使用推理网络进行摊销的变量推理来近似的[158]。 尽管z不再具有语义含义,但是这些深度模型学习到的强大表示形式可以带来更好的性能。 一旦学习,推理网络就可以直接应用于新任务,这将更加高效并且需要更少的人类知识。 由于推理网络具有大量参数,因此通常使用一些辅助大规模数据集对其进行训练。 许多经典的推理网络都适用于FSL问题。例如,在[34,57,109]中使用变分自编码器(VAE)[68],在[107]中使用自回归模型[135],在[159]中使用生成对抗网络(GAN)[46], 并在[47]中提出了VAE和GAN的组合。
05 Discussion and Summary
当存在相似的任务或辅助任务时,可以使用多任务学习来约束few-shot任务的H。 但是,请注意,需要共同训练所有任务。 因此,当一个新的few-shot任务到达时,整个多任务模型必须再次训练,这可能既昂贵又缓慢。 此外,D和\(D_c\)的大小不应具有可比性,否则,多次执行的任务可能会被具有许多样本的任务淹没。
当存在一个包含足够的各种类别样本的大规模数据集时,可以使用嵌入学习方法。 这些方法将样本映射到良好的嵌入空间,在其中可以很好地分离来自不同类别的样本,因此需要较小的H ̃。 但是,当few-shot任务与其他任务没有密切关系时,它们可能无法很好地工作。 此外,更多有关如何混合任务的不变和特定于任务的信息的探索是有帮助的。
当有可用的内存网络时,可以通过在内存的基础上训练一个简单的模型(例如,分类器)将其轻松用于FSL。 通过使用精心设计的更新规则,可以有选择地保护内存插槽。 该策略的弱点在于,它会导致额外的空间和计算成本,随着内存大小的增加而增加。 因此,当前的外部存储器具有有限的大小。
最后,当除了FSL之外还想要执行诸如生成和重构之类的任务时,可以使用生成模型。 他们从其他数据集中学习了先验概率\(p(z;γ)\),这将H减小为更小的H ̃。 学习的生成模型也可以用于生成样本以进行数据扩充。 但是,生成建模方法具有较高的推理成本,比确定性模型更难于推导。
Recommended references
[13] L. Bertinetto, J. F. Henriques, P. Torr, and A. Vedaldi. 2019. Meta-learning with differentiable closed-form solvers. In International Conference on Learning Representations.
[14] L. Bertinetto, J. F. Henriques, J. Valmadre, P. Torr, and A. Vedaldi. 2016. Learning feed-forward one-shot learners. In Advances in Neural Information Processing Systems. 523–531.
[35] L. Fei-Fei, R. Fergus, and P. Perona. 2006. One-shot learning of object categories. IEEE Transactions on Pattern Analysis
and Machine Intelligence 28, 4 (2006), 594–611.
[47] J. Gordon, J. Bronskill, M. Bauer, S. Nowozin, and R. Turner. 2019. Meta-learning probabilistic inference for prediction.
In International Conference on Learning Representations.
[65] Ł. Kaiser, O. Nachum, A. Roy, and S. Bengio. 2017. Learning to remember rare events. In International Conference on
Learning Representations.
[89] A. Miller, A. Fisch, J. Dodge, A.-H. Karimi, A. Bordes, and J. Weston. 2016. Key-value memory networks for directly reading documents. In Conference on Empirical Methods in Natural Language Processing. 1400–1409.
[91] N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel. 2018. A simple neural attentive meta-learner. In International Conference on Learning Representations.
[96] T. Munkhdalai and H. Yu. 2017. Meta networks. In International Conference on Machine Learning. 2554–2563.
[97] T. Munkhdalai, X. Yuan, S. Mehri, and A. Trischler. 2018. Rapid adaptation with conditionally shifted neurons. In
International Conference on Machine Learning. 3661–3670.
[113] R. Salakhutdinov, J. Tenenbaum, and A. Torralba. 2012. One-shot learning with a hierarchical nonparametric Bayesian model. In ICML Workshop on Unsupervised and Transfer Learning. 195–206.
[114] A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap. 2016. Meta-learning with memory-augmented neural networks. In International Conference on Machine Learning. 1842–1850.
[158] C. Zhang, J. Butepage, H. Kjellstrom, and S. Mandt. 2019. Advances in variational inference. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 8 (2019), 2008–2026.
[164] L. Zhu and Y. Yang. 2018. Compound memory networks for few-shot video classification. In European Conference on Computer Vision. 751–766.
最新小样本学习综述 A Survey on Few-Shot Learning | 四大模型Multitask Learning、Embedding Learning、External Memory…的更多相关文章
- Generalizing from a Few Examples: A Survey on Few-Shot Learning 小样本学习最新综述 | 三大数据增强方法
目录 原文链接:小样本学习与智能前沿 01 Transforming Samples from Dtrain 02 Transforming Samples from a Weakly Labeled ...
- 小样本学习最新综述 A Survey on Few-shot Learning | Introduction and Overview
目录 01 Introduction Bridging this gap between AI and humans is an important direction. FSL can also h ...
- Generalizing from a Few Examples: A Survey on Few-Shot Learning(从几个例子总结经验:少样本学习综述)
摘要:人工智能在数据密集型应用中取得了成功,但它缺乏从有限的示例中学习的能力.为了解决这一问题,提出了少镜头学习(FSL).利用先验知识,可以快速地从有限监督经验的新任务中归纳出来.为了全面了解FSL ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 最新java学习路线:含阶段性java视频教程完整版
最新java学习路线:带阶段性java视频教程版本 第一阶段:Java基础 学习目标: 掌握基本语法.面向对象.常用类.正则.集合.Io流.多线程.Nio.网络编程.JDK新特性.函数式编程 知识点细 ...
- ACE学习综述(1)
1. ACE学习综述 1.1. ACE项目的优点 可以跨平台使用,基本上可以实现一次编写,多平台运行. ACE本身不仅仅是一个简单的网络框架,对于网络框架涉及到的进程管理.线程管理等系统本身相关的内容 ...
- 【最新发布】最新Python学习路线,值得收藏
随着AI的发展,Python的薪资也在逐年增加,但是很多初学者会盲目乱学,连正确的学习路线都不清楚,踩很多坑,为此经过我多年开发经验以及对目前行业发展形式总结出一套最新python学习路线,帮助大家正 ...
- 小样本学习Few-shot learning
One-shot learning Zero-shot learning Multi-shot learning Sparse Fine-grained Fine-tune 背景:CVPR 2018收 ...
- 小样本元学习综述:A Concise Review of Recent Few-shot Meta-learning Methods
原文链接 小样本学习与智能前沿 . 在这个公众号后台回复'CRR-FMM',即可获得电子资源. 1 Introduction In this short communication, we prese ...
随机推荐
- uniApp 列表
普通列表 例图: 代码片段: <template> <view class="teacher"> <view class="teacher- ...
- Java入门(7)
Java入门经典(第7版) 作者:罗格斯·卡登海德 对象抛出异常,以指出发生了异常,这些异常可以被其他对象或虚拟机捕获. 其他异常使用5个新的关键字在程序运行时进行处理:try,catch,final ...
- 释放至强平台 AI 加速潜能 汇医慧影打造全周期 AI 医学影像解决方案
基于英特尔架构实现软硬协同加速,显著提升新冠肺炎.乳腺癌等疾病的检测和筛查效率,并帮助医疗科研平台预防"维度灾难"问题 <PAGE 1 LEFT COLUMN: CUSTOM ...
- post和get、PostMapping、GetMapping和RequestMapping
PostMapping.GetMapping和RequestMapping PostMapping和GetMapping封装了method="",限制了method,更加规范化. ...
- PyCharm离线安装PyQt5_tools(QtDesigner)
目录 下载所需的whl包 安装whl 配置PyCharm 测试 下载所需的whl包 打开链接 PyPI,依此搜索 python_dotenv,PyQt5_sip,PyQt5,pyqt5_tools:基 ...
- binary hacks读数笔记(readelf命令)
可以用readelf命令来查看elf文件内容,跟objdump相比,这个命令更详细. 1. readelf -h SimpleSection.o ELF Header: Magic: 7f 45 4c ...
- python实现二叉树递归遍历与非递归遍历
一.中序遍历 前中后序三种遍历方法对于左右结点的遍历顺序都是一样的(先左后右),唯一不同的就是根节点的出现位置.对于中序遍历来说,根结点的遍历位置在中间. 所以中序遍历的顺序:左中右 1.1 递归实现 ...
- App与小程序对接
背景: 商品详情页,点击分享,分享到微信好友,点开链接App拉起小程序. 用户在小程序浏览完成,跳转至原App购买商品. 功能点: 实现APP与小程序互调. 前提: 已对接好友盟ShareSDK(需要 ...
- JS之DOM(一)
一.DOM简介 什么是DOM?简单地说,DOM是是针对HTML和XML文档的一个API,一套对文档的内容进行抽象和概念化的方法. 学习过ORM的同学可能知道ORM是将数据库中的表映射到类,建立一个表和 ...
- Linux 笔记1
linux netstat -an | grep 8081 查看端口进程 window netstat -ano|findstr "1433" taskkill -pid ** - ...