Deep Learning Specialization 笔记
1. numpy中的几种矩阵相乘:
# x1: axn, x2:nxbnp.dot(x1, x2): axn * nxbnp.outer(x1, x2): nx1*1xn # 实质为: np.ravel(x1)*np.ravel(x2)np.multiply(x1, x2): [[x1[0][0]*x2[0][0], x1[0][1]*x2[0][1], ...]
2. Bugs' hometown
Many software bugs in deep learning come from having matrix/vector dimensions that don't fit. If you can keep your matrix/vector dimensions straight you will go a long way toward eliminating many bugs.
3. Common steps for pre-processing a new dataset are:
- Figure out the dimensions and shapes of the problem (m_train, m_test, num_px, ...)
- Reshape the datasets such that each example is now a vector of size (num_px \* num_px \* 3, 1)
- "Standardize" the data
4. Unstructured data:
Unstructured data is a generic label for describing data that is not contained in a database or some other type of data structure . Unstructured data can be textual or non-textual. Textual unstructured data is generated in media like email messages, PowerPoint presentations, Word documents, collaboration software and instant messages. Non-textual unstructured data is generated in media like JPEG images, MP3 audio files and Flash video files
5. Chapter of Activation Function:
Choice of activation function:
- If output is either 0 or 1 -- sigmoid for the output layer and the other units on ReLU.
- Except for the output layer, tanh does better than sigmoid.
- ReLU ---level up--> leaky ReLU.
Why are ReLU and leaky ReLU often superior to sigmoid and tanh?
-- The derivatives of the former ones is much bigger than 0, so the learning would be much faster.
A linear hidden layer is more or less useless, yet the activation function is a exception.
6. Regularization:
Initially, \(J(w, b) = \frac{1}{m} * \sum_{i=1}^{m}{L({\hat{Y}^(i), y^{(i)}}) + \frac{\lambda}{2*m}||w||_2^2}\)
L2 regularization: \(\frac{\lambda}{2*m}\sum_{j=1}^{n_x}||w_j||^2 = \frac{\lambda}{2*m}||w||_2\)
One aspect that tanh is better thatn sigmoid(in terms of regularization) -- When x is very close to 0, the derivative of tanh(x) is almost linear, while that of the sigmoid(x) is alomst 0.
Dropout:
Method: Make certain values of weights be zeros randomly, just like -- W= np.multiply(W, C), where C is a 0-1 array.
Matters need attention: Don't use dropout in test procedure -- Time costly, result randomly.
Work principle:
Intuition: Can't rely on any one feature, so have to spread out weights(shrinking weights).
Besides, you can set different rates of "Dropout", like lower ones on more complex layer, which are called "key prop".
- Data augmentation:
Do some operation on your data images, such as flipping, rotation, zooming, etc, without changing their labels, in order to prevent from over-fitting on some aspects, such as the direction of faces, the size of cats.
- Early stopping.
7. Solution to "gradient vanishing or exploding":
Set WL = np.random.randn(shape) * np.sqrt(\(\frac{2}{n^{[L-1]}}\)) if activation_function == "ReLU"
else: np.random.randn(shape) * np.sqrt(\(\frac{1}{n^{[L-1]}}\)) or np.sqrt(\(\sqrt{\frac{2}{n^{[L-1]}+n^{[L]}}}\))(Xavier initialization)
8. Gradient Checking:
for i in range(len(\(\theta\))):
to check if (d\(\theta_{approx}[i] = \frac{J(\theta_1, \theta_2, ..., \theta_i+\epsilon, ...) - J(\theta_1, \theta_2, ..., \theta_i-\epsilon, ...)}{2\epsilon}\)) ?= \(d\theta[i] = \frac{\partial{J}}{\partial{\theta_i}}\)
<==> \(d\theta_{approx} ?= d\theta\)
<==> \(\frac{||d\theta_{approx} - d\theta||_2}{||d\theta_{approx}||_2+||d\theta||_2}\) in an accent range: \(10^{-7}\) is great, and \(10^{-3}\) is wrong.
Tips:
- Only to debug, instead of training.
- If algorithm fails grad check, look at components(\(db^{[L]}, dw^{[L]}\)) to try to identify bug.
- Remember regularization.
- Doesn't work together with dropout.
- Run at random initialization; perhaps again after some training.
9. Exponentially weighted averages:
Definition: let \(V_{t} = {\beta}V_{t-1} + (1 - \beta)\theta_t\) (_V_s are the averages, and the _\(\theta\)_s are the initial discrete data).
and \(V_{t} = \frac{V_{t}}{1 - {\beta}^t}\) (To correct initial bias).
Usage: when it comes to this situation: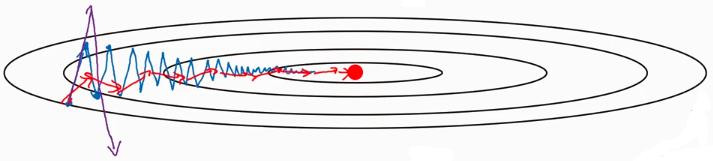
Since the average of the distance vertical movement is almost zeros, you can use EWA to average it, prevent it from divergence.
On iteration t:
Compute dW on the current mini-batch
\(v_{dW} = {\beta}v_{dW} + (1 - \beta)dW\)
\(v_{db} = {\beta}v_{db} + (1 - \beta)db\)
\(W = W - {\alpha}v_{dW}, b = b - {\alpha}v_{db}\)
Hyperparameters: \(\alpha\), \({\beta}(=0.9)\)
Deep Learning Specialization 笔记的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- 【deep learning学习笔记】注释yusugomori的DA代码 --- dA.h
DA就是“Denoising Autoencoders”的缩写.继续给yusugomori做注释,边注释边学习.看了一些DA的材料,基本上都在前面“转载”了.学习中间总有个疑问:DA和RBM到底啥区别 ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记
Spectral Norm Regularization for Improving the Generalizability of Deep Learning论文笔记 2018年12月03日 00: ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
https://blog.csdn.net/zouxy09/article/details/9993371 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一 ...
- [置顶]
Deep Learning 学习笔记
一.文章来由 好久没写原创博客了,一直处于学习新知识的阶段.来新加坡也有一个星期,搞定签证.入学等杂事之后,今天上午与导师确定了接下来的研究任务,我平时基本也是把博客当作联机版的云笔记~~如果有写的不 ...
随机推荐
- C++ unordered_map/unordered_set 自定义键类型
1. unordered_map 和 unordered_set template < class Key, // unordered_map::key_type class T, // uno ...
- Arduino 上手实战呼吸灯
前言 这篇稿子比以往的时候来的稍晚了一些,望fans们见谅,那即便如此,最终还是姗姗来迟了,公司新一轮战略性部署,被拖出去孵化新产品,开拓新市场去了,手头精力没有那么多了,另外产品一茬接一茬.韭菜一波 ...
- 4. Tomcat调优
1, 调内存 JVM 2, 调网络处理框架 普通io/nio,netty https://segmentfault.com/a/1190000008873688 https://ww ...
- 判断2个list中是否有相同的数据(相交)Collections.disjoint
https://blog.csdn.net/yang_niuxxx/article/details/85092490 private void initData() { for (int i = 0; ...
- mysql本地中127.0.0.1连接不上数据库怎么办
首先在本地使用Navicat for MySQL建立一个bai数据库.在dreamweaver中建立一个PHP格式的网页,方便链接测试.测试发du现,如果zhi无法使用localhost链接mysql ...
- 在 WebAssembly 中实现回调的方式
本文将介绍在 C++ 中实现 js 回调的几种方式. 在使用 wasm 的过程中, 避免不了要从 C++ 回调 js 的函数来实现异步交互. 官网文档 https://emscripten.org/d ...
- Spring Boot 系列总结
Spring Boot 系列总结 1.SpringBoot自动装配 1.1 Spring装配方式 1.2 Spring @Enable 模块驱动 1.3 Spring 条件装配 2.自动装配正文 2. ...
- ajax 用fom提交
$.ajax({ type : "POST", url : "${ctx}/credit/LoanauditCtrl/qwe.do?hetong="+heton ...
- ehCache 配置
package com.jy.modules.cms; import java.io.Serializable; import net.sf.ehcache.Cache; import net.sf. ...
- docker(7)docker-compose容器集群编排
前言 实际工作中我们部署一个应用,一般不仅仅只有一个容器,可能会涉及到多个,比如用到数据库,中间件MQ,web前端和后端服务,等多个容器. 我们如果一个个去启动应用,当项目非常多时,就很难记住了,所有 ...