MySQL-字段约束条件
1.无符号、零填充
1.unsigned:用在生成表的过程中,表示不取负数,只取正数和0,负数会直接报错,eg:id int unsigned。
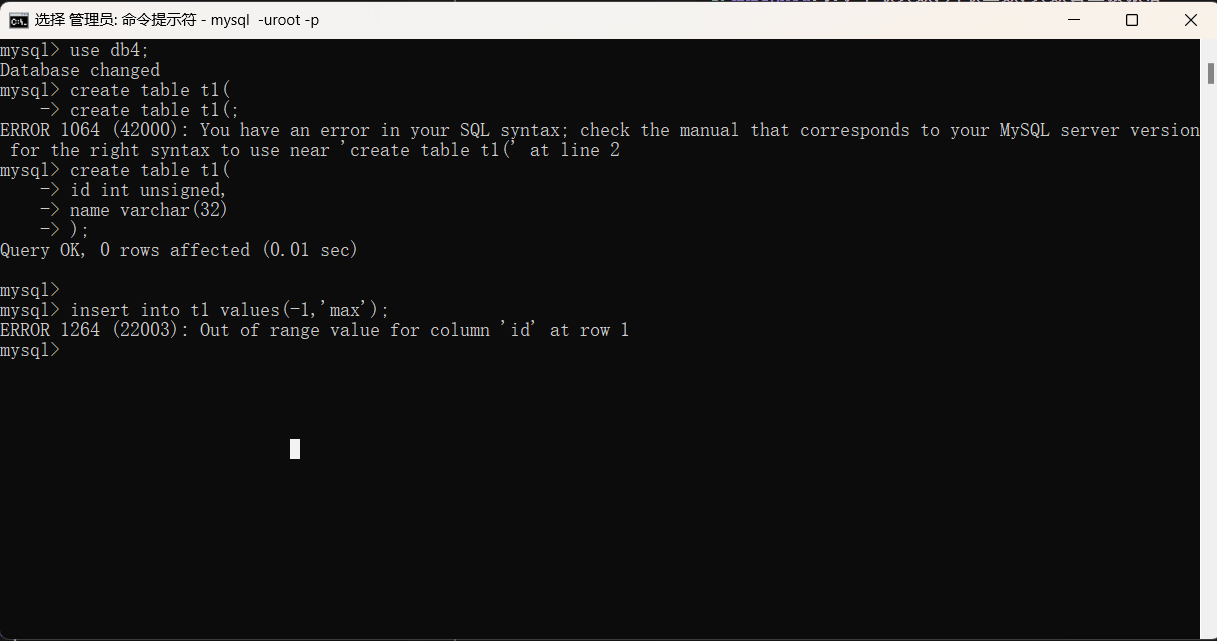
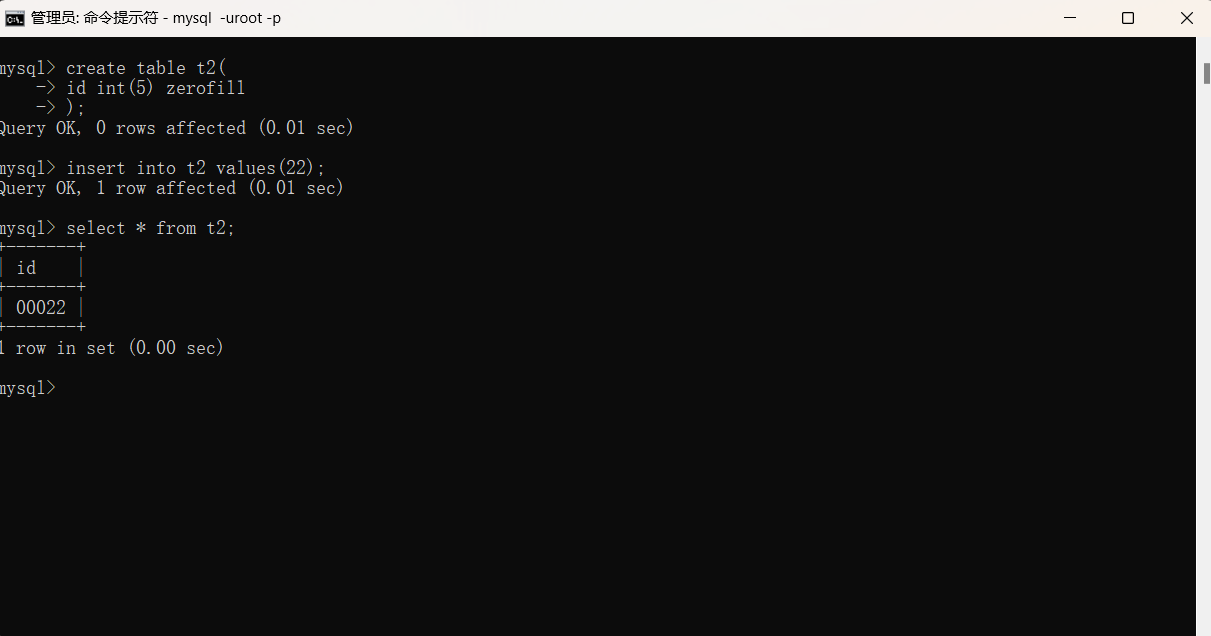
2.zerofill:用在生成表的过程中,跟在整形2后面,表示不足几位会在数字前自动填充0,凑够括号内的位数。eg:id int(5) zerofill。无符号和零填充可以共同使用。
2.非空
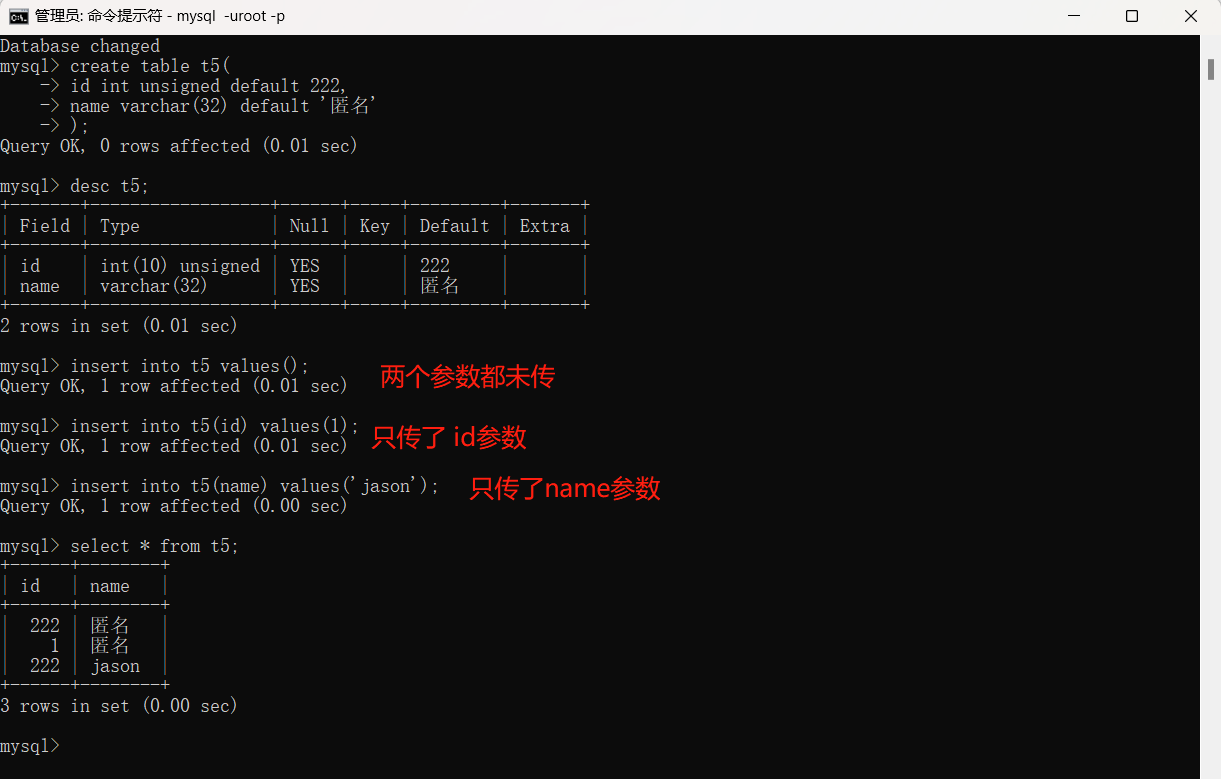
1.我们在创建表的过程中,可以只对部分字段名进行传值,方法为在insert into 表名(字段名) values(数据值)表名后的括号中写入要传值的字段名即可。
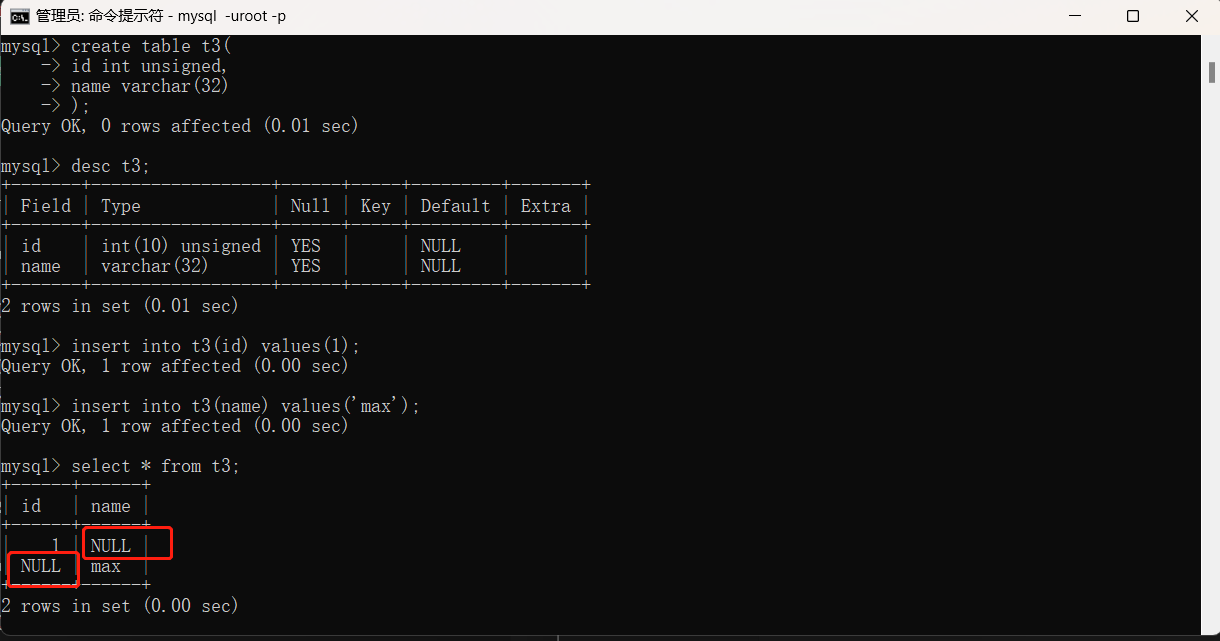
我们发现可以只对括号中写入的字段名传值,未写入的字段名可以不传值,所有字段类型不加约束条件的情况下默认都可以为空。因此不传值的数据在表格中会变成NULL,类似python中的None。
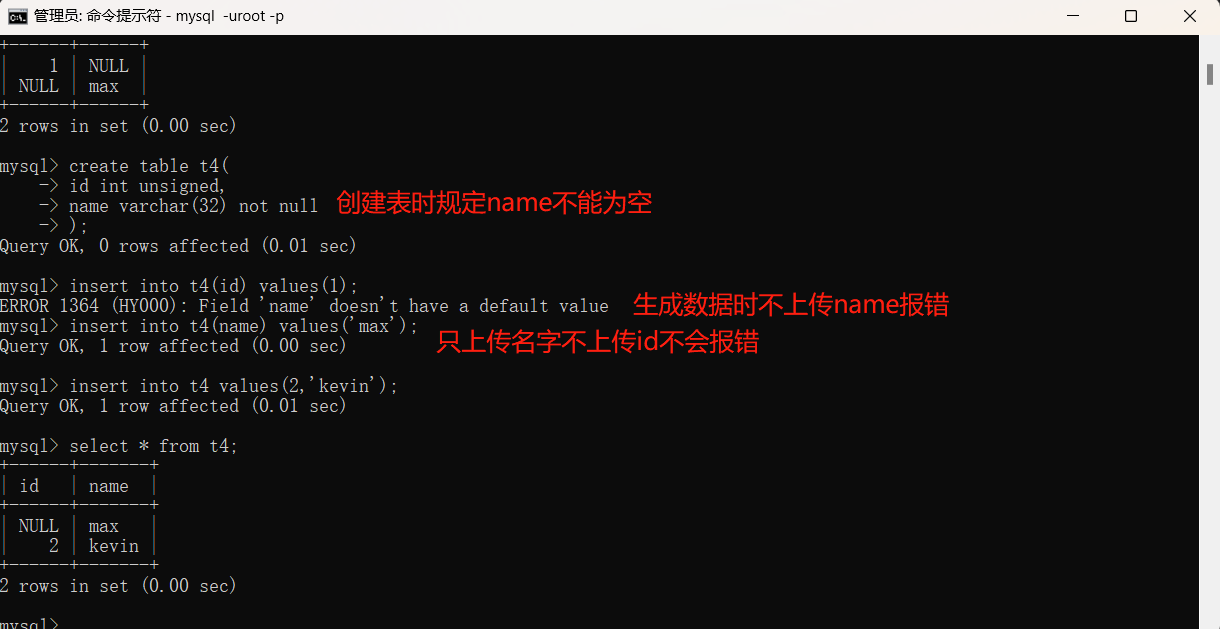
2.如果表中有的数据不能为空必须要上传,可以在生成表的过程中在字段类型后面加上 not null,之后如果该字段未上传数据则会报错。
3.默认值
1.在生成表格过程中如果某个字段结果确定,我们可以采用默认值,类似函数中的默认参数。如果用户不上传这个参数,生成的数据按默认的数据为准,如果上传则以上传的结果为准。设置默认值只需要在字段类型后面加上: default 默认数据值 即可。
4.唯一值
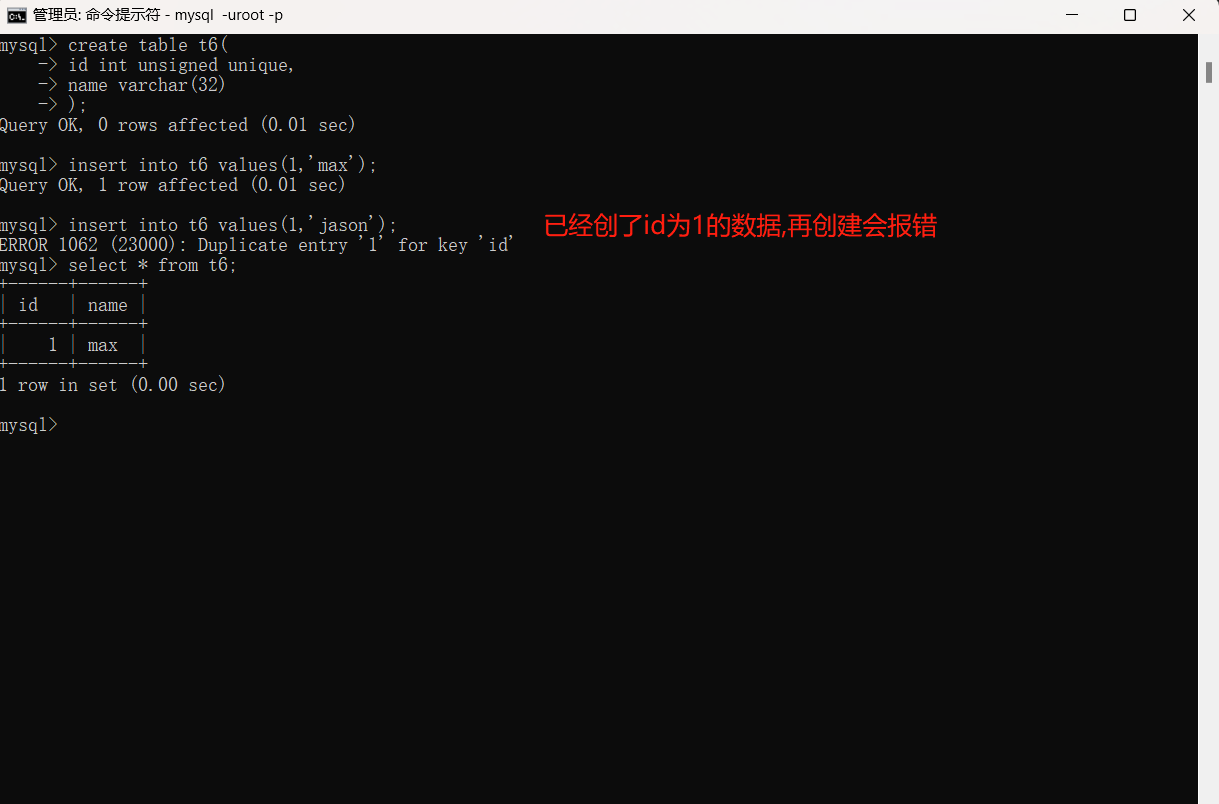
1.单列为一:在创建数据的过程中有的数据需要保持唯一,例如派出所的名单系统名字可以重复,但是身份证号必须是唯一的。为了实现这种效果,我们只需要在字段类型后面加上unique即可,代表该字段不可重复。
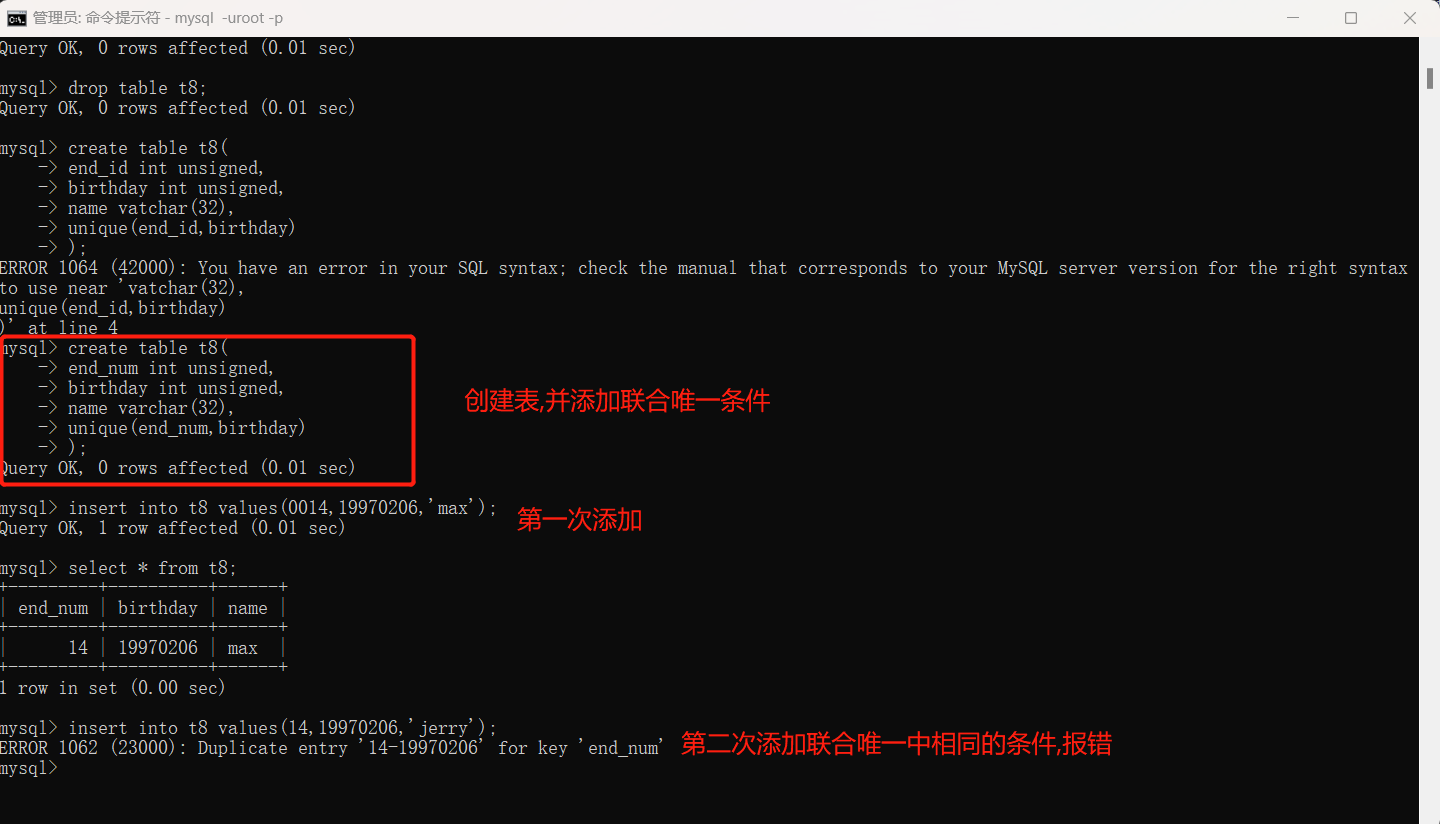
2.联合唯一:创建数据时有几个条件不能同时相同,比如身份证后四位不能和出生年月相同,而这个筛选在mysql中可以实现,只需要在创建表的过程中在最后一行加入unique(),括号中写入联合唯一的字段名即可。
5.主键
1.主键语法结构为:primary key,跟在字段类型后面,相当于not null + unique(非空且唯一)。eg:身份证号,员工号。
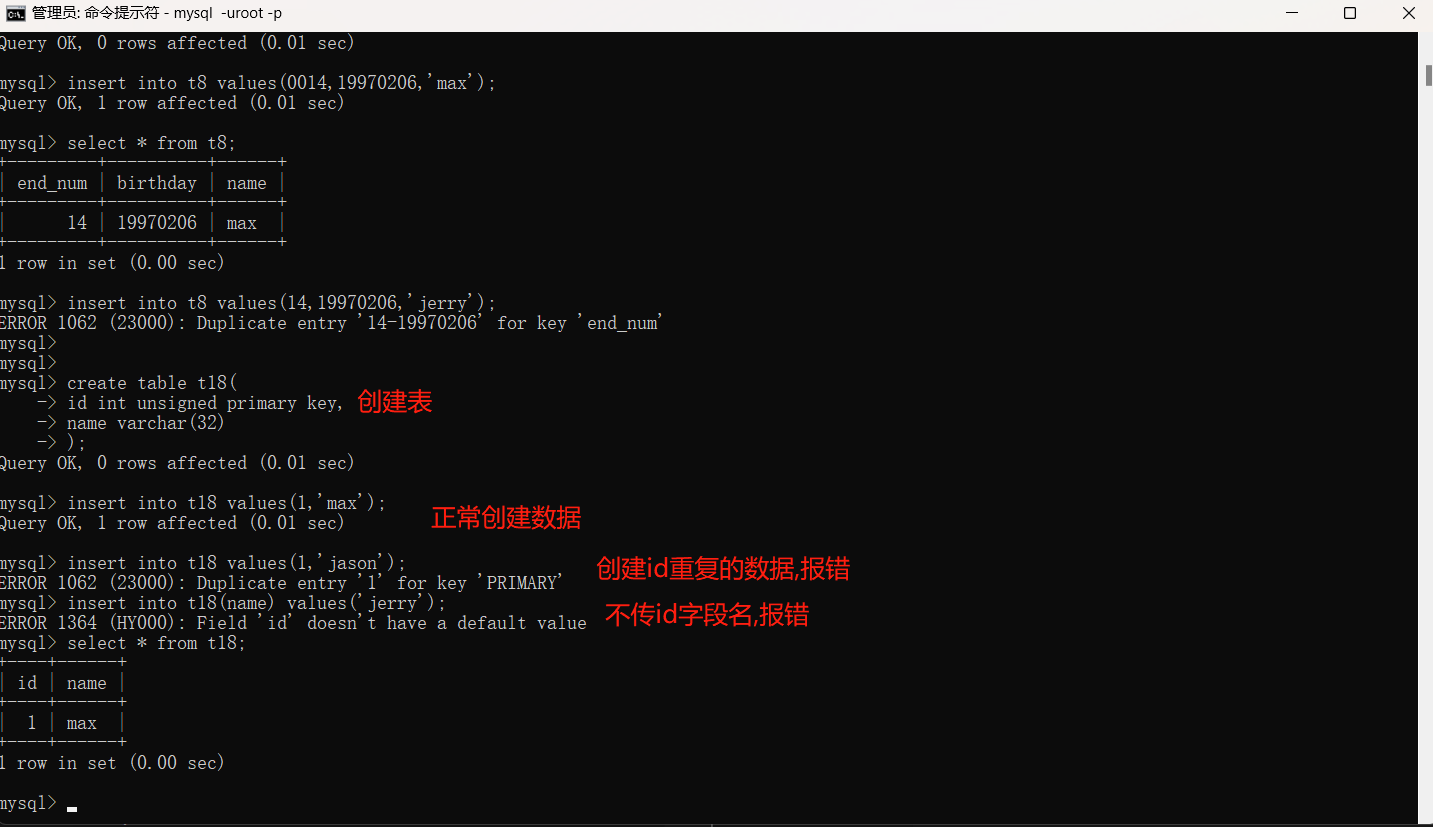
2.主键是组织数据的重要条件,并且可以加快数据的查询速度,InnoDB存储引擎规定了所有的表必须有且只有一个主键。
2.1当表中没有主键也没有其他非空且唯一的字段情况下,InnoDB会采用一个隐藏的字段作为表的主键,隐藏意味着无法使用,基于该表的数据查询也只能一行行查找,速度很慢。
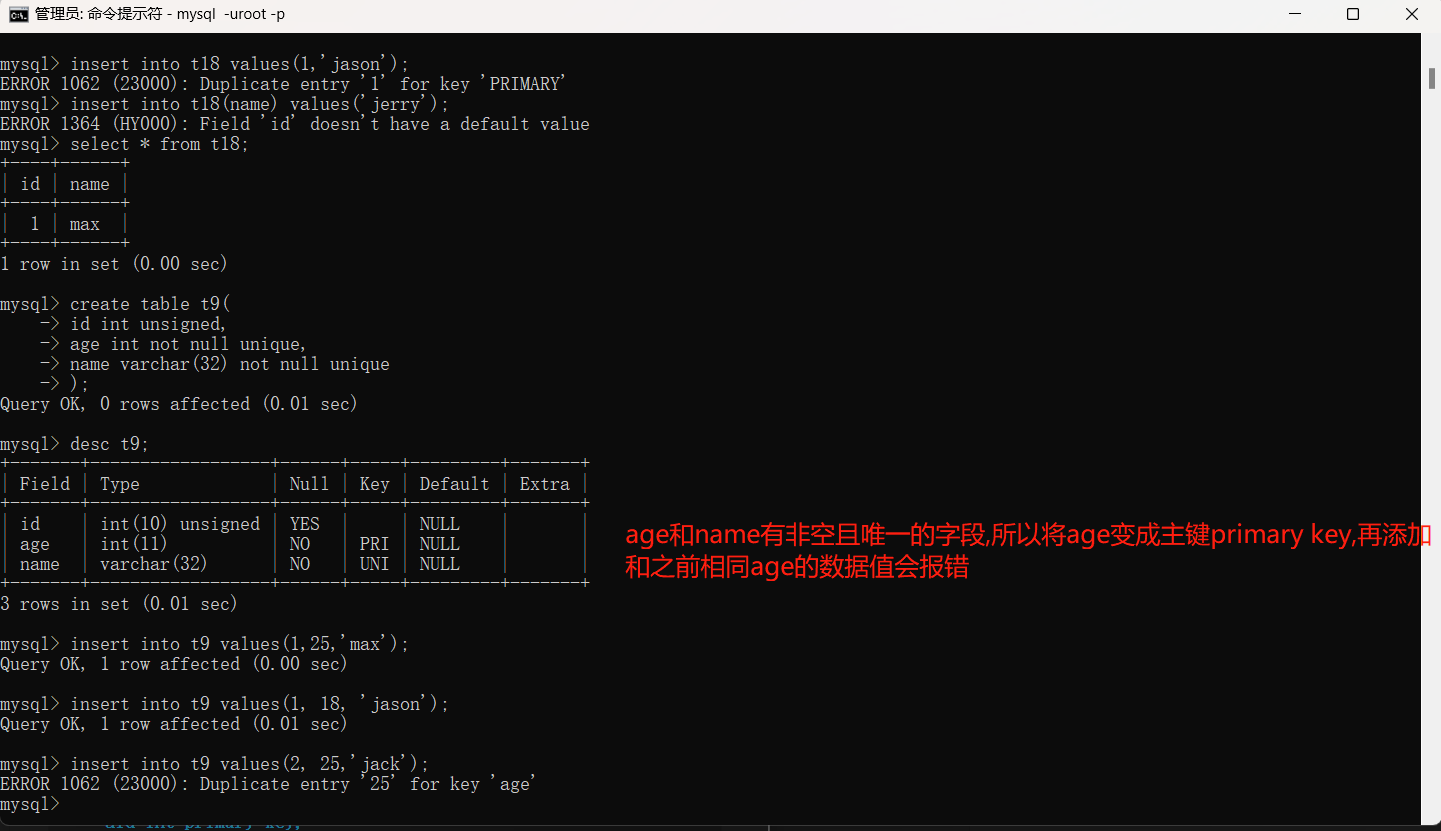
2.2当表中没有主键但是有其他非空且唯一的字段,那么会从上往下将第一个非空且唯一的字段自动升级成为主键。可以看到字典名age的Key也变成的主键的缩写PRI。
"""
我们在创建表的时候应该有一个字段用来标识数据的唯一性,并且该字段通常情况下就是id字段,我们也可以根据项目具体情况命名成为'pid','sid'等。
"""
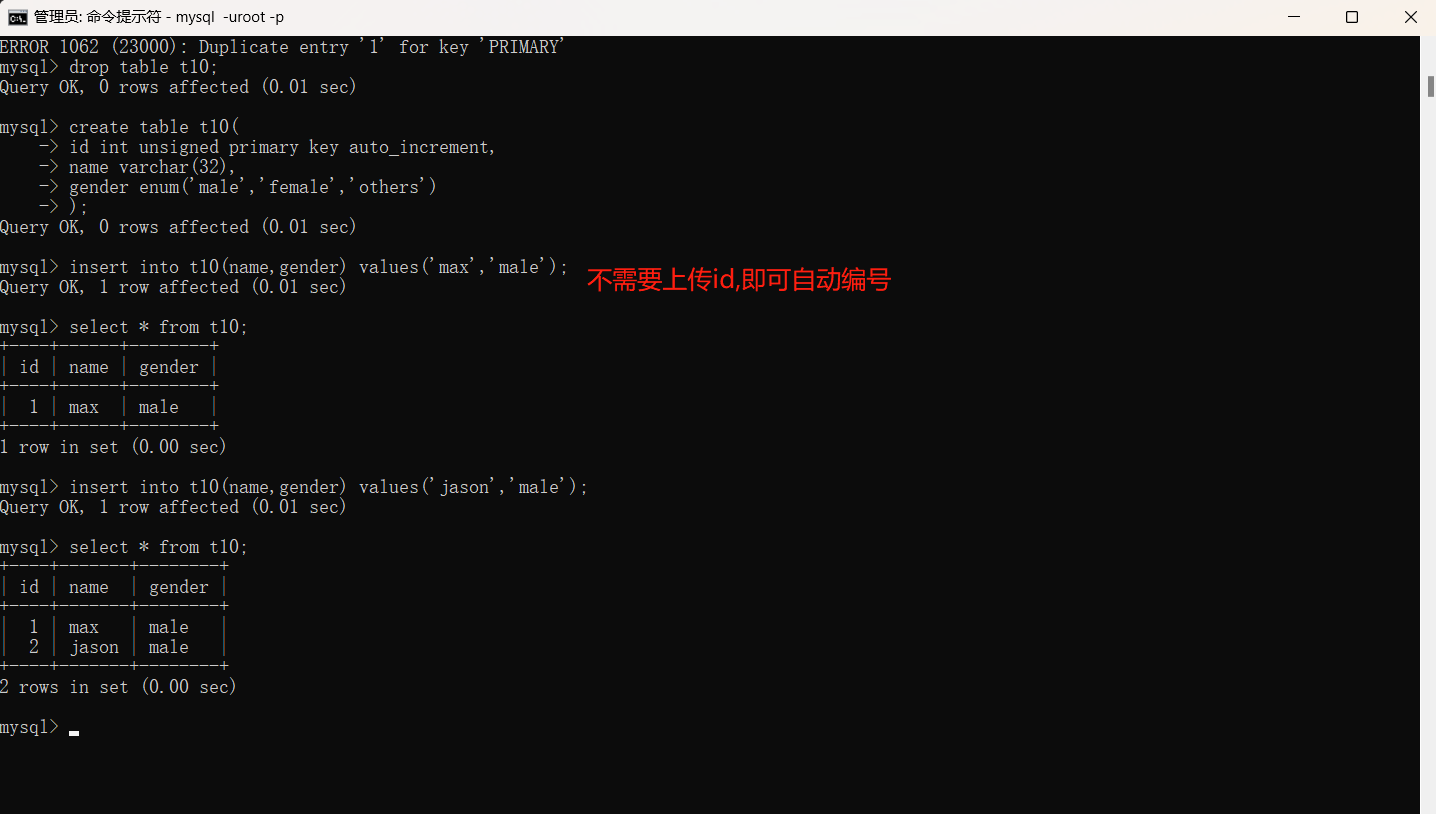
6.自增
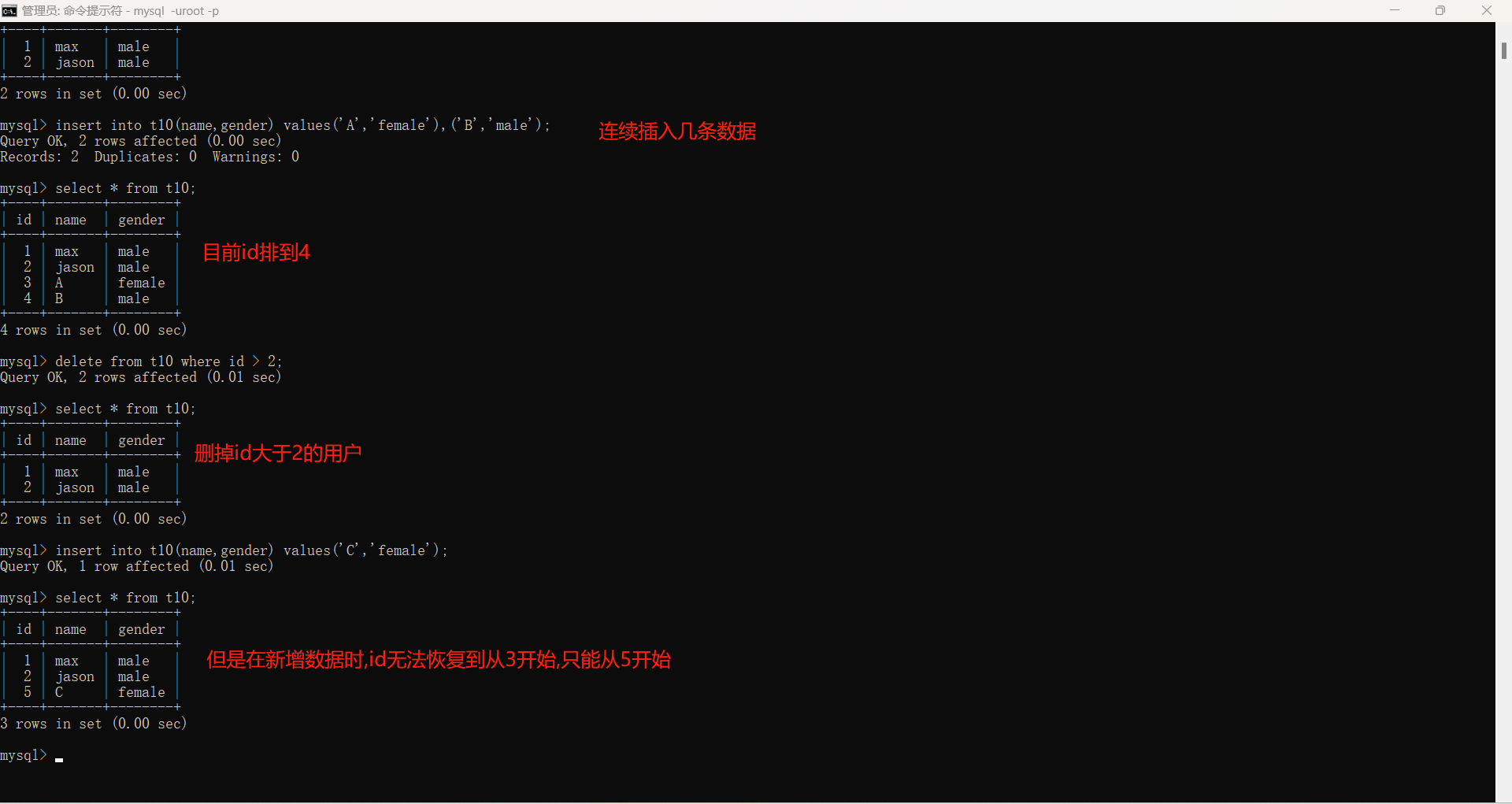
1.当我们使用id或其他字段来给数据编号时,每次都要上传id,并且如果时间间隔较长,我们会忘记上次编号到多少。所以我们在创建表的时候直接在主键后面加上:auto_increment,即可自动编号。每次上传的时候不用上传被自增修饰的字段。
"""
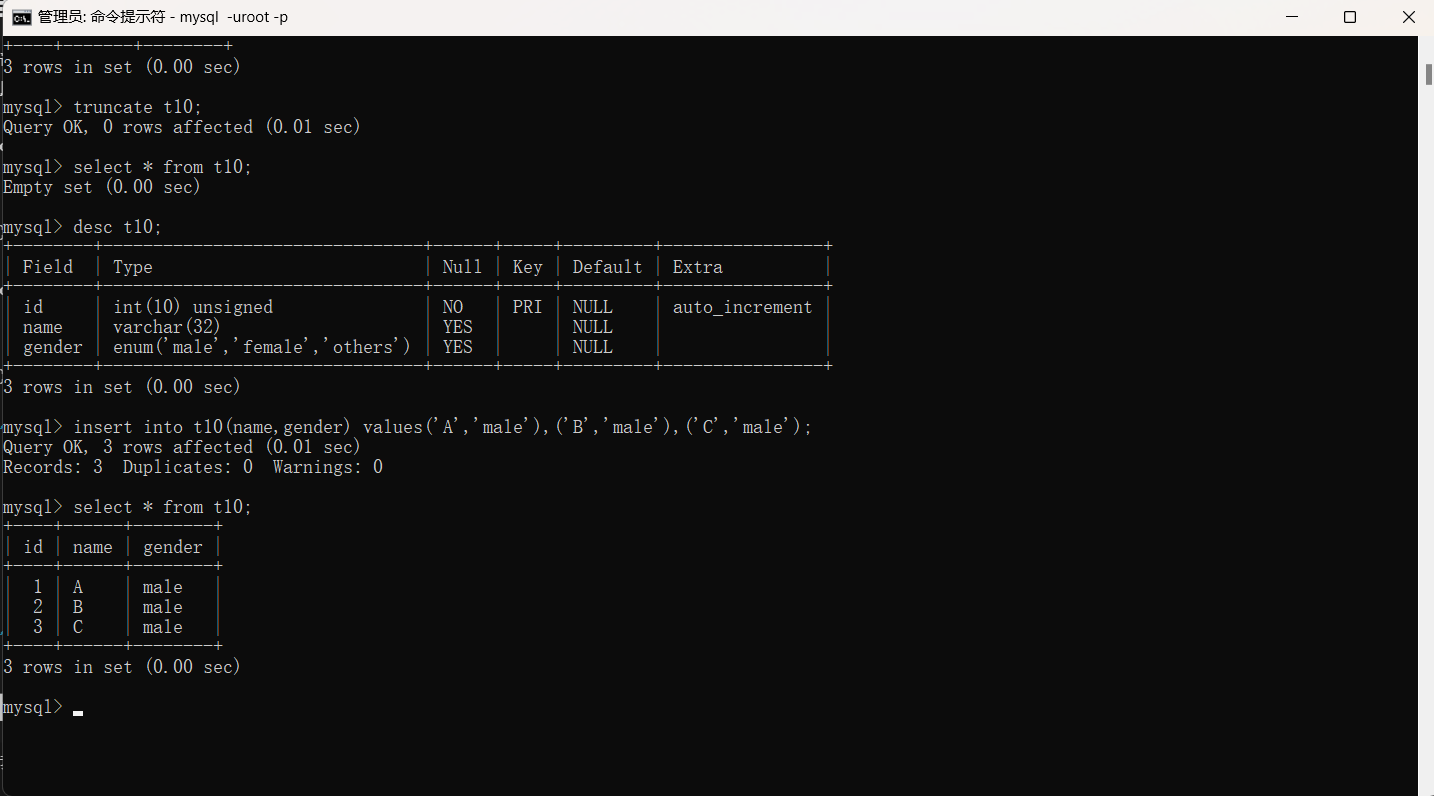
但是子层不会因为删除了数据而回退,永远会增长。如果想要重置某张表的主键值,需要使用truncate 表名来清空数据并重置主键。
"""
7.外键
1.我们在制作一张员工表时,一班表上体现的信息需要有:
id name age dep_name(部门) dep_desc
但是我们在使用这张表的过程中会发现以下问题:
1.语义不明确,不知道主体是员工还是部门。
2.因为部门比较有限,新增大量员工时会重复输入部门,浪费内存空间,造成空间冗余。
3.如果员工绑定的部门需要更换名字或其他属性时,工作量很大并且很麻烦。
2.鉴于上述缺点,我们将表一分为二,分成员工表(id name age),和部门表(id dep_name dep_desc)。上述问题得到解决,但是员工和部门没有了关系,因此我们需要在员工表里增加一个字段dep_id,将部门的id填入员工表中的dep_id字段,就时的不同表之间产生了联系。因此得出概念外键字段:用于表示数据与数据之间关系的字段。dep_id就是外键字段。
"""
外键字段:用于表示数据与数据之间关系的字段。
"""
员工表
| id | name | age | dep_id(外键字段) |
|---|---|---|---|
| 1 | jason | 18 | 1 |
| 2 | max | 25 | 2 |
| 3 | jerry | 27 | 2 |
| 4 | jack | 38 | 1 |
部门表
| id | dep_name | dep_desc |
|---|---|---|
| 1 | 领导班子 | 领导员工 |
| 2 | 法务部 | 处理法务纠纷 |
| 3 | 财务部 | 管钱 |
8.关系的判断
1.关系有多种:一对多,多对多,一对一,没有关系
"""
关系判断可以用'换位思考原则'
"""
9.一对多关系
1.首先站在员工表的角度来考虑:一个员工能否对应多个部门?不行;再站在部门表的角度来说:一个部门可以对应多个员工。该种关系称为一对多关系,部门是一,员工是多。
2.结论:一个可以一个不可以,该种关系就是一对多。针对'一对多'的关系,外键字段放在'多'的一方。
10.外键字段的建立
小技巧:先定义出含有普通字段的表,之后再考虑外键字段的添加。
首先我们用代码写出两个表以及它们在数据库层面的关系。
员工表:
create table emp(
id int unsigned primary key auto_increment,
name varchar(32),
age int,
dep_id int unsigned,
foreign key(dep_id) references dep(id)
);
部门表:
create table dep(
id int unsigned primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(32)
);
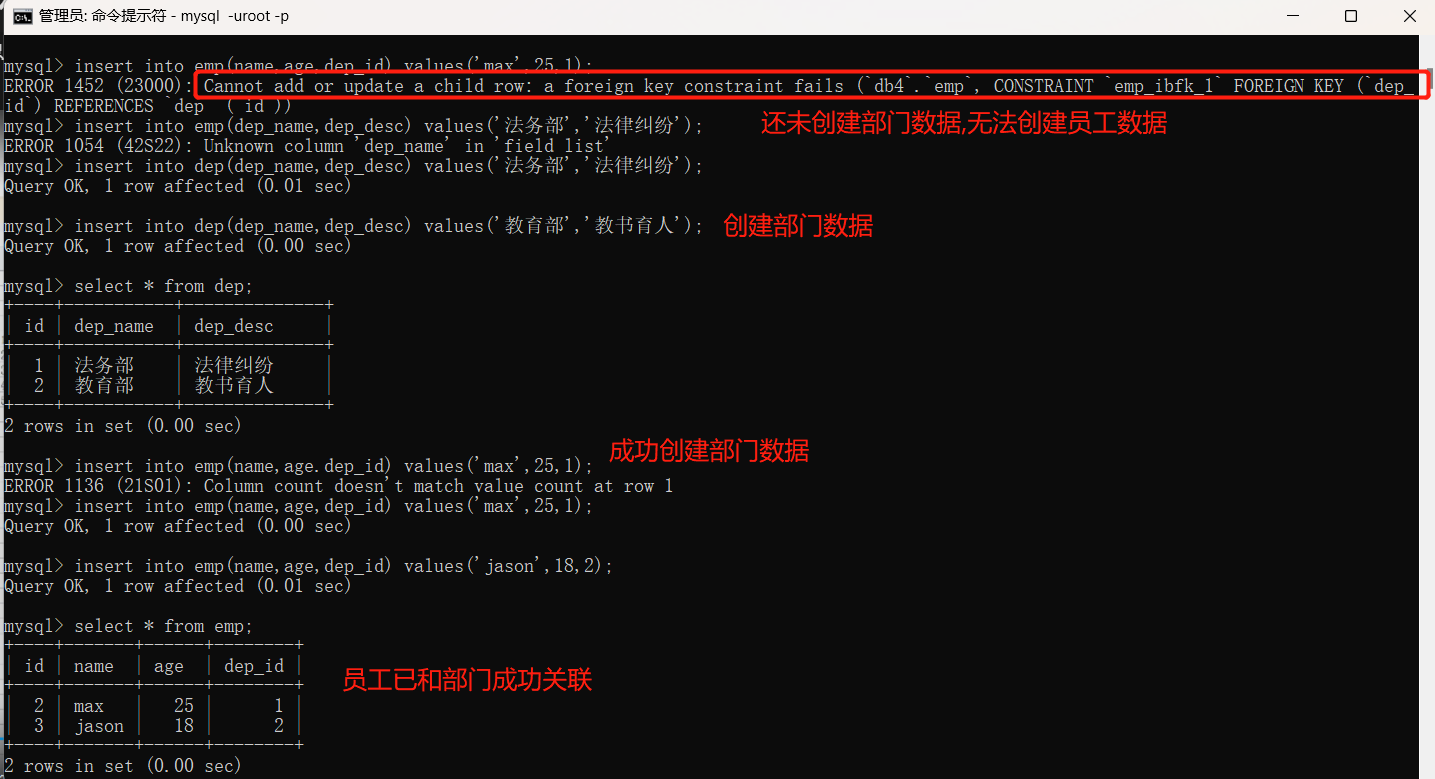
1.创建表的时候应该先创建被关联表。
2.录入表数据的时候一定要先录入被关联表。
3.修改数据时候外键字段无法修改和删除。
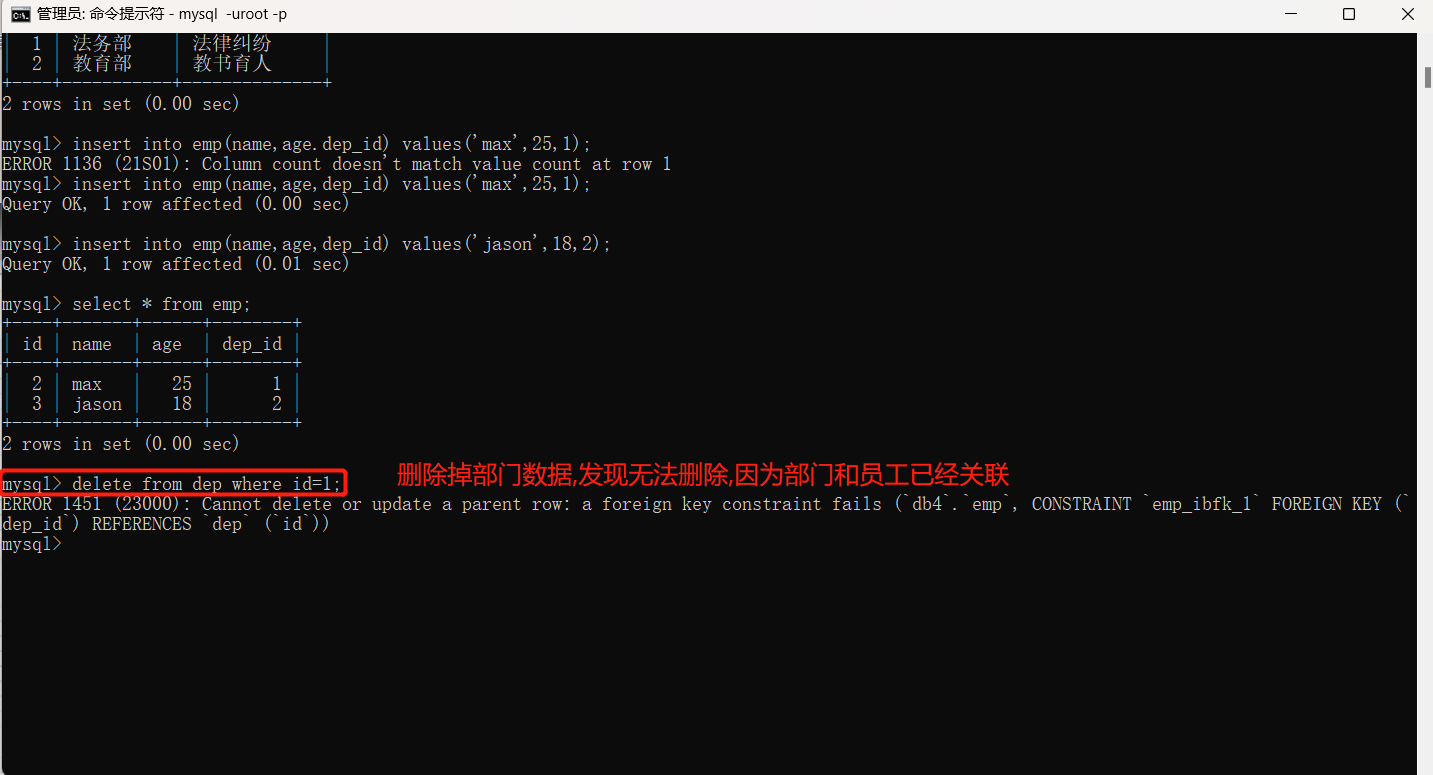
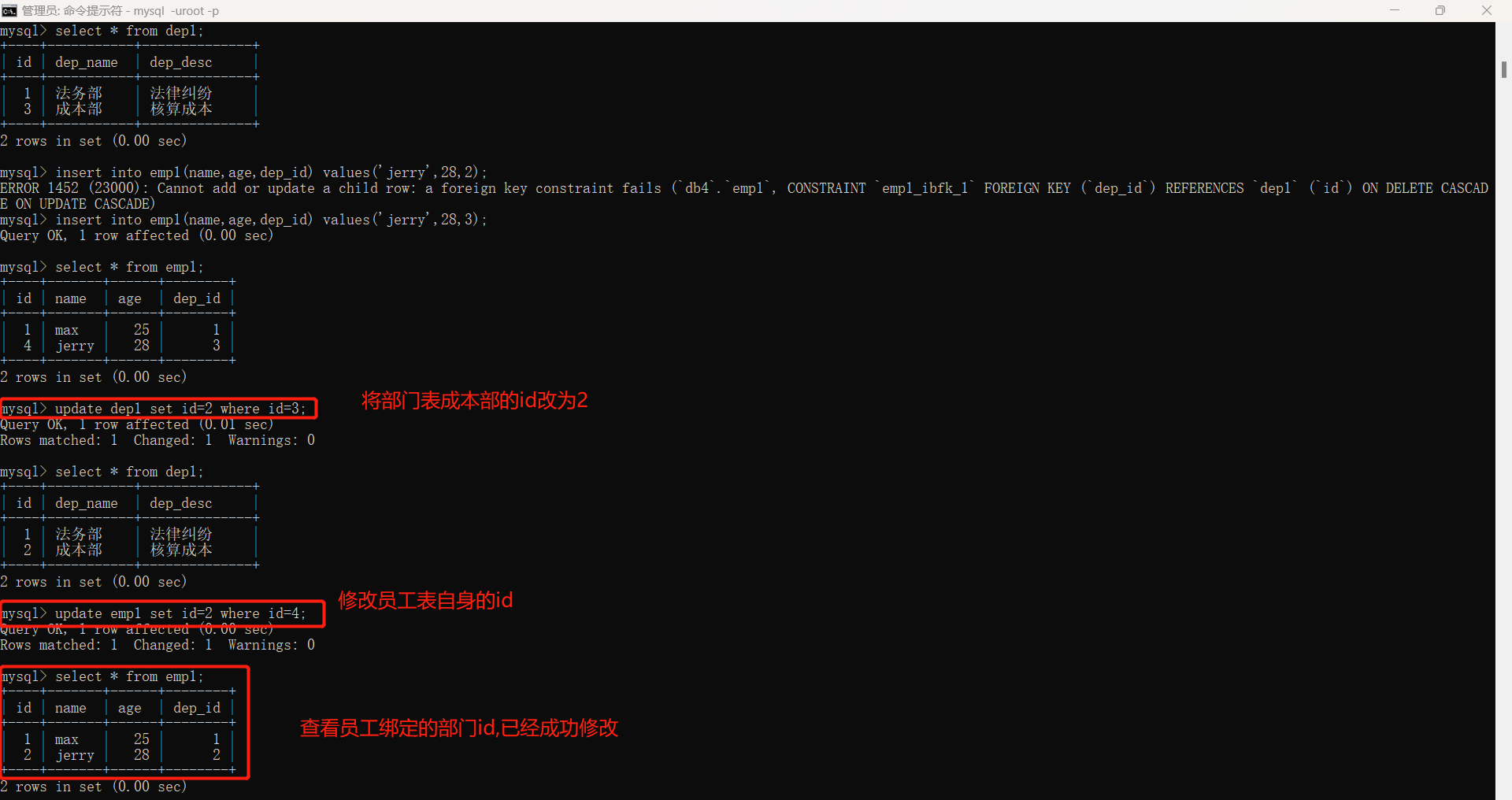
针对不能删除和修改的缺点,对上述代码进行以下修改,添加以下代码时被关联的一方修改关联的一方也可以正常修改。
create table emp1(
id int unsigned primary key auto_increment,
name varchar(32),
age int unsigned,
dep_id int unsigned,
foreign key(dep_id) references dep1(id)
on update cascade
on delete cascade
);
create table dep1(
id int unsigned primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(32)
);
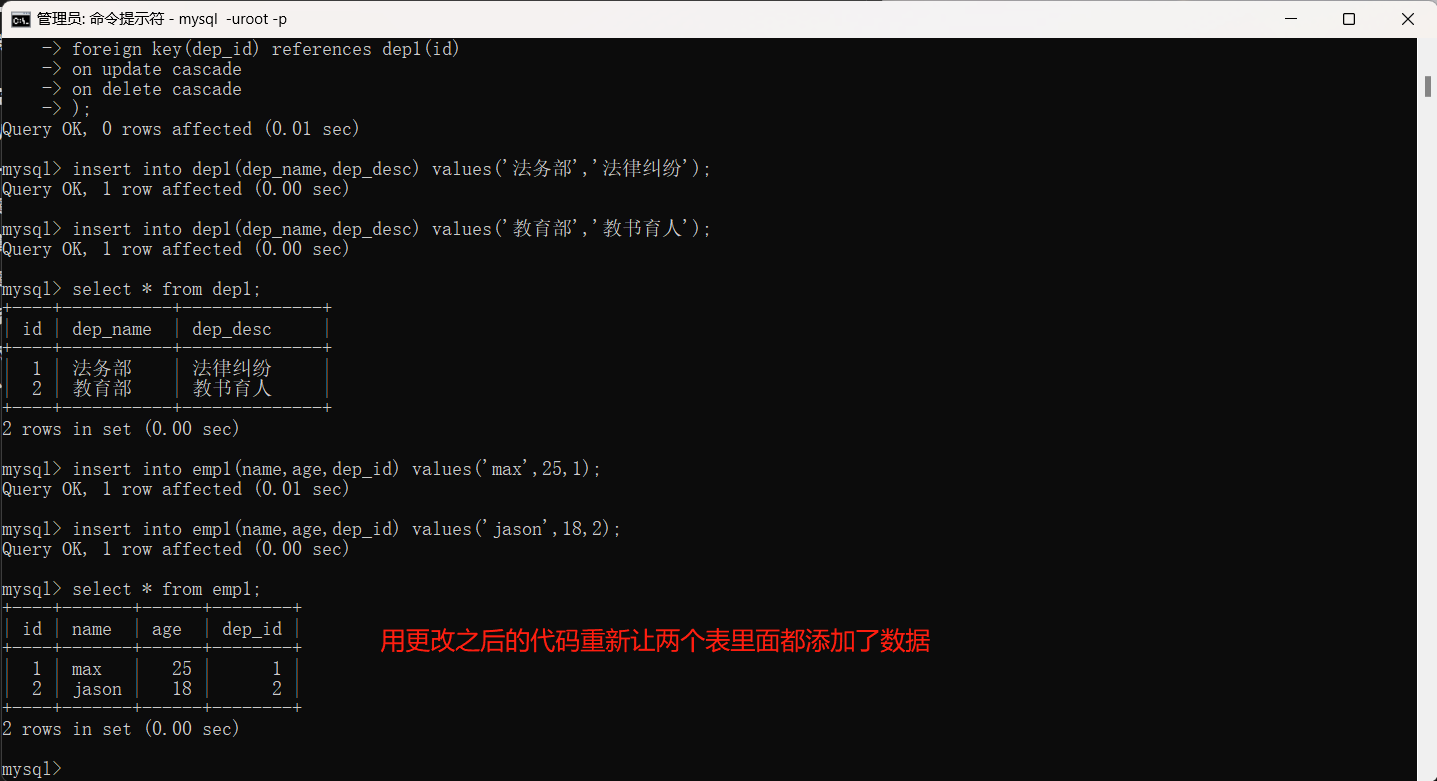
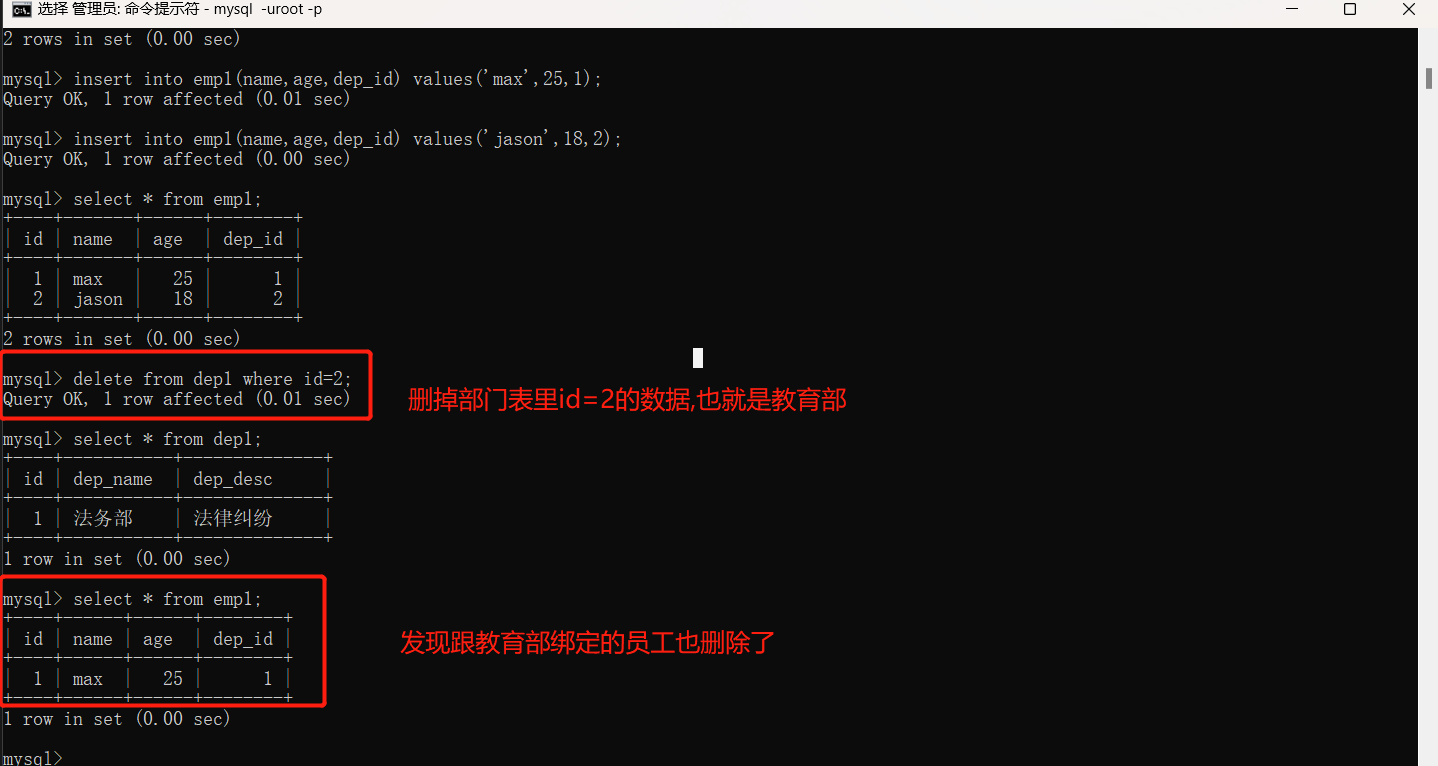
"""
上述我们发现部门数据删除之后,和删除部门绑定的员工数据也删除了,所以外键还是有一定缺陷。外键其实是强耦合,不符合解耦合的特性,所以很多时候,实际项目中当表较多的情况,我们可能不会使用外键 而是使用代码建立逻辑层面的关系。
"""
11.多对多关系
刚才研究了一对多的关系,但是日常生活中也有很多多对多的关系,例如书籍合作者,一本书的作者可以是好几位作家,一位作家也可以撰写多本书籍。所以书籍表和作者表是多对多的关系。
书籍表
| id | title | price |
|---|---|---|
| 1 | 书籍1 | 50 |
| 2 | 书籍2 | 60 |
| 3 | 书籍3 | 70 |
作者表
| id | name | 电话 |
|---|---|---|
| 1 | 作者1 | 111 |
| 2 | 作者2 | 222 |
| 3 | 作者3 | 333 |
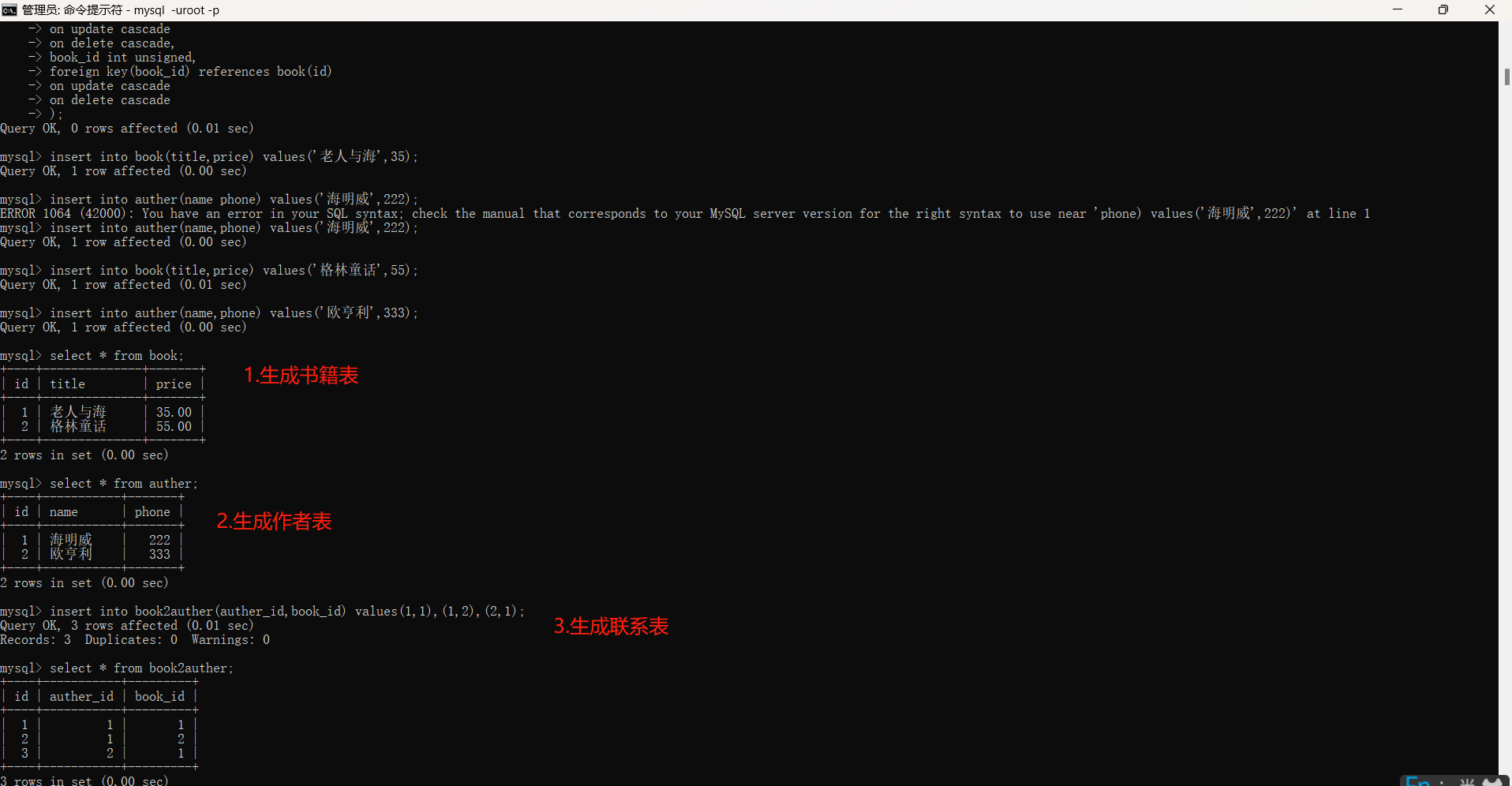
'''针对多对多关系,我们需要建立第三张表'''
create table book(
id int unsigned primary key auto_increment,
title varchar(32),
price float(5,2)
);
create table auther(
id int unsigned primary key auto_increment,
name varchar(32),
phone bigint unsigned
);
create table book2auther(
id int unsigned key auto_increment,
auther_id int unsigned,
foreign key(auther_id) references auther(id)
on update cascade
on delete cascade,
book_id int unsigned,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
);
"""
传值时候先传学生和老师的表,再添加第三个表,第三个表就是用来添加多对多关系的。
"""
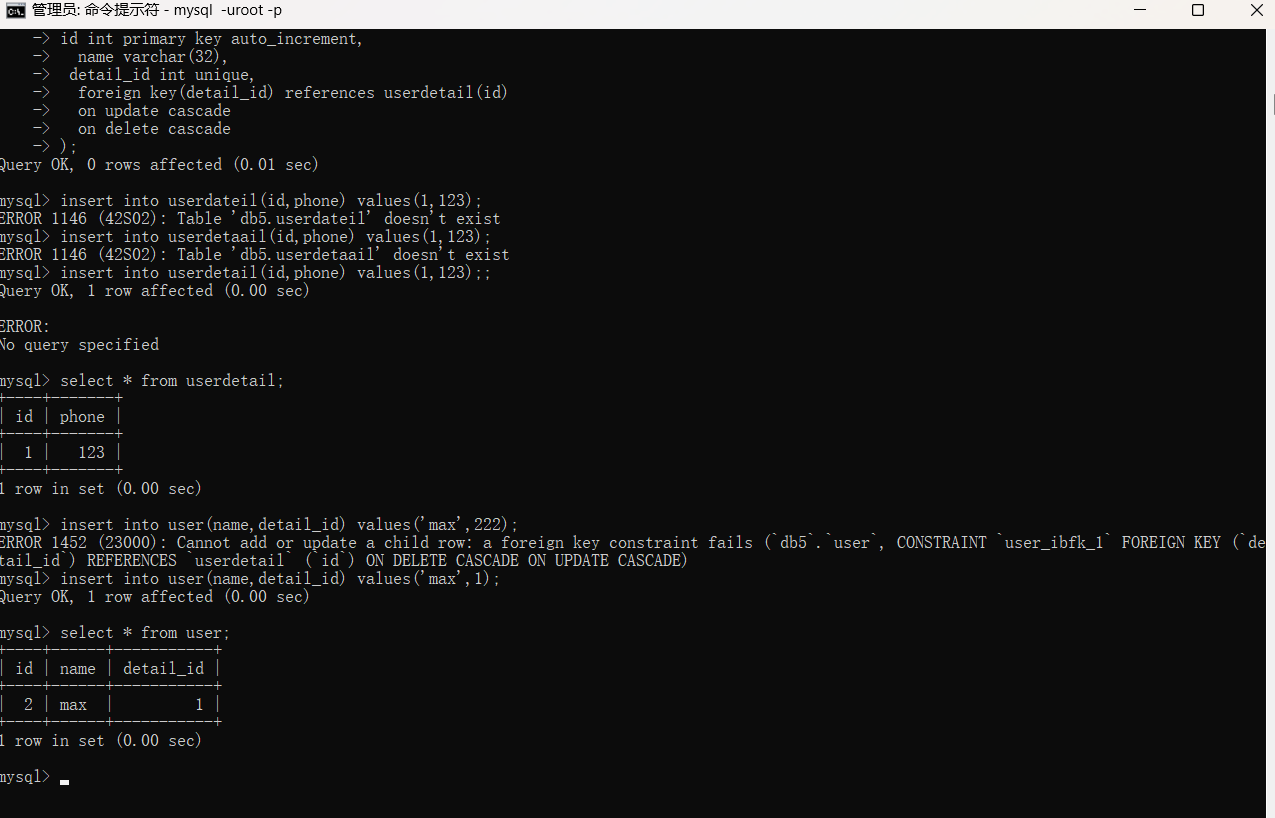
12.一对一关系
联系的双方为用户表和用户详情表,用户表和用户详情表的关系是一对一的关系。针对一对一的关系,外键字段在任何一方都可以,但是推荐使用放在查询频率较高的表里。
create table user(
id int unsigned primary key auto_increment,
name varchar(32),
detail_id int unsigned unique,
foreign key(detail_id) references userdetail(id)
on update cascade
on delete cascade
);
create table userdetail(
id int unsigned primary key auto_increment,
phone bigint unsigned
);
作业练习
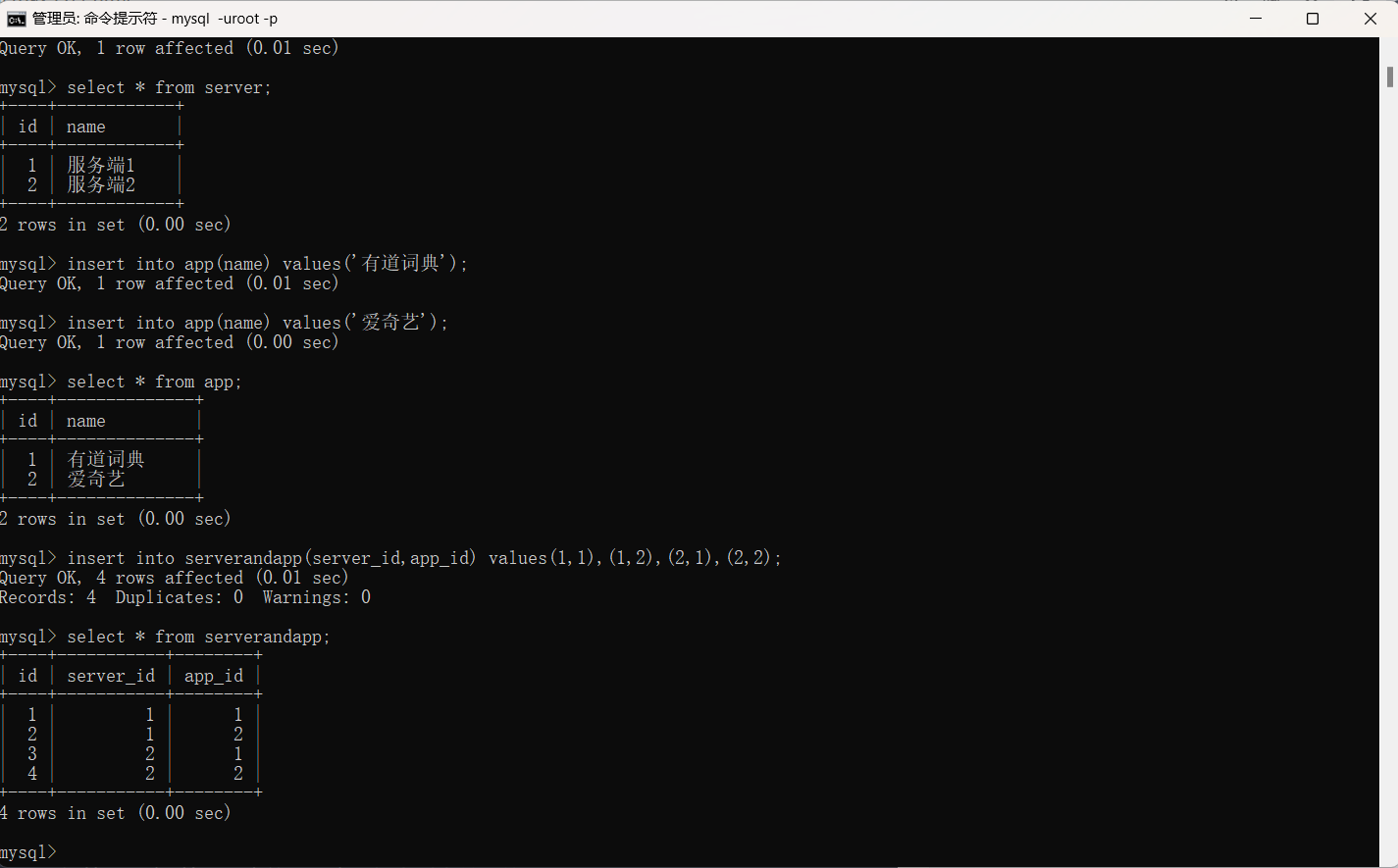
服务器表与应用程序表(多对多)
create table server(
id int unsigned primary key auto_increment,
name varchar(32)
);
create table app(
id int unsigned primary key auto_increment,
name varchar(32)
);
create table serverandapp(
id int unsigned primary key auto_increment,
server_id int unsigned,
foreign key(server_id) references server(id)
on update cascade
on delete cascade,
app_id int unsigned,
foreign key(app_id) references app(id)
on update cascade
on delete cascade
);
课程表与班级表(多对多)
create table course(
id int unsigned primary key auto_increment,
name varchar(32)
);
create table class(
id int unsigned primary key auto_increment,
name varchar(32)
);
create table courseandclass(
id int unsigned primary key auto_increment,
course_id int unsigned,
foreign key(course_id) references course(id)
on update cascade
on delete cascade,
class_id int unsigned,
foreign key(class_id) references class(id)
on update cascade
on delete cascade
);
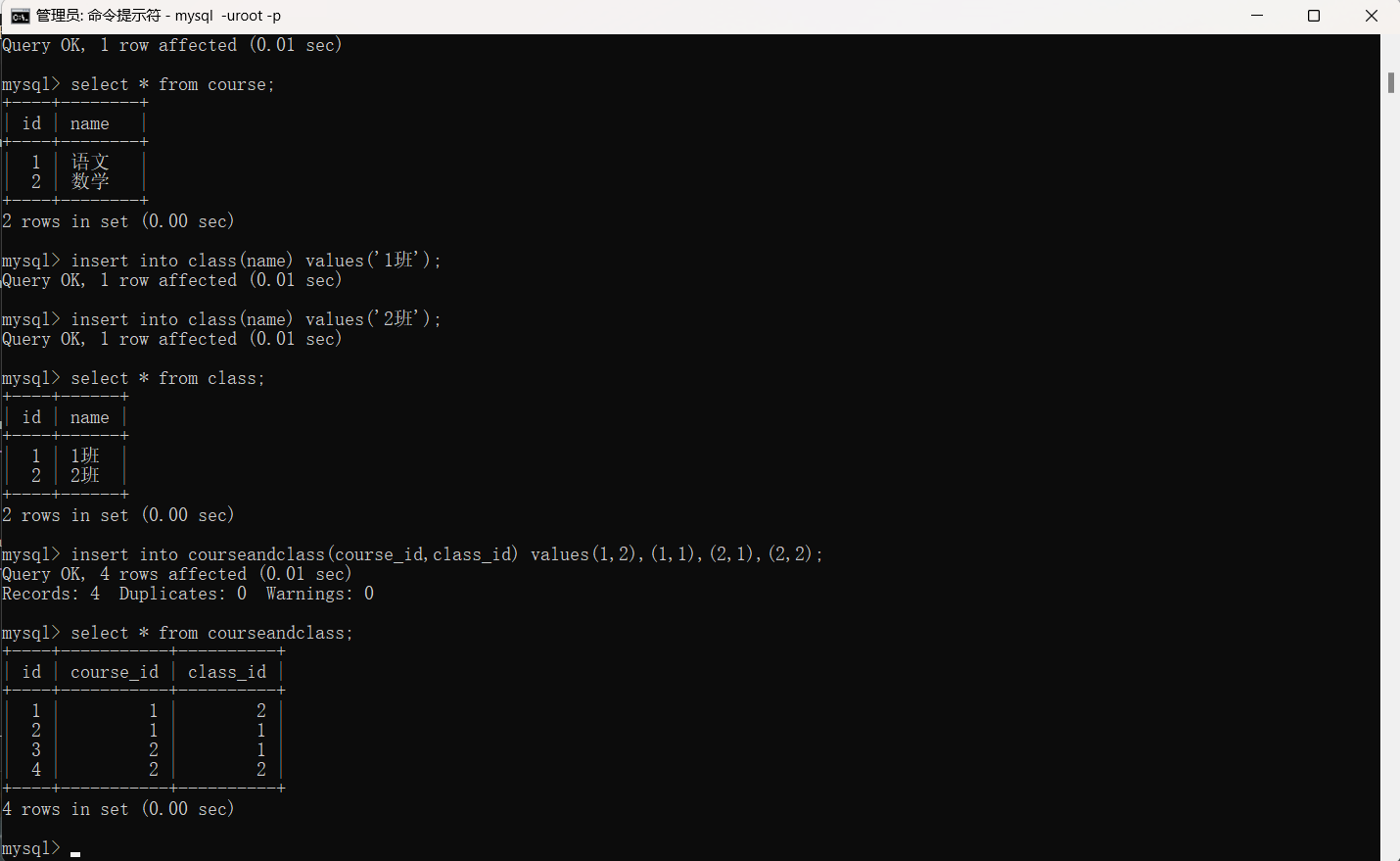
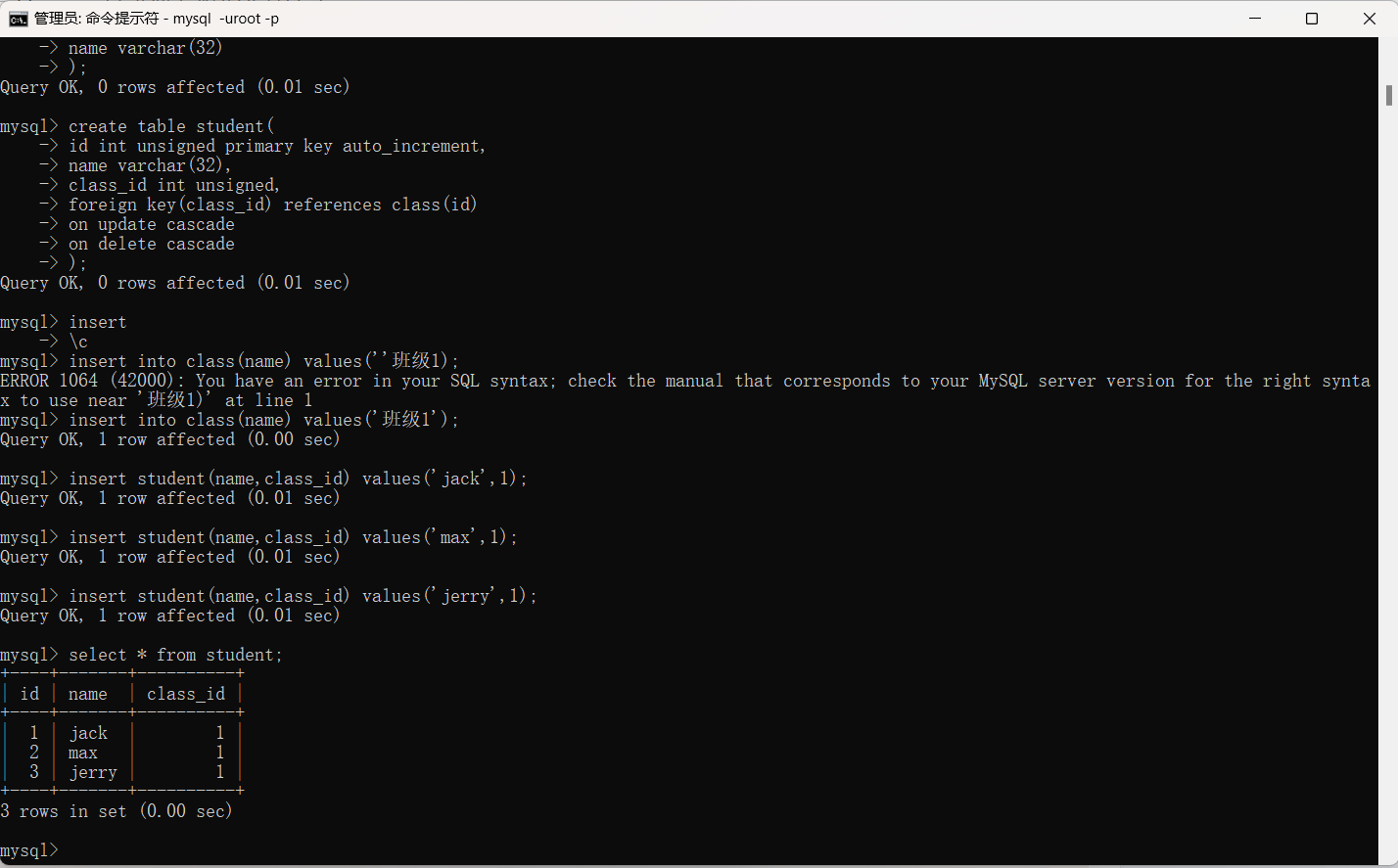
学生表与班级表(一对多)
create table class(
id int unsigned primary key auto_increment,
name varchar(32)
);
create table student(
id int unsigned primary key auto_increment,
name varchar(32),
class_id int unsigned,
foreign key(class_id) references class(id)
on update cascade
on delete cascade
);
MySQL-字段约束条件的更多相关文章
- MySQL字段约束条件、字段类型、存储引擎、配置文件
字符编码与配置文件 # 查看MySQL默认字符编码 \s ''' 如果是5.X系列 显示的编码有很多种 Latin1 gbk 如果是8.X系列 显示的统一是utf8mb4 utf8mb4是utf8优化 ...
- 字符编码,存储引擎,MySQL字段类型,MySQL字段约束条件
字符编码 查看MySQL默认编码命令:\s """ 如果是5.X系列 显示的编码有多种 latin1 gbk 如果是8.X系列 显示的统一是utf8mb4 utf8mb4 ...
- MySQL字段类型与操作
MYSQL字段类型与操作 字符编码与配置文件 操作 代码 功能 查看 \s 查看数据库基本信息(用户.字符编码) 配置(配置文件层面) my-default.ini windows下MySQL默认的配 ...
- MySQL字段之集合(set)枚举(enum)
MySQL字段之集合(set)枚举(enum) (2008-12-23 13:51:23) 标签:it 分类:MySQL 集合 SET mysql> create table jihe(f1 ...
- mysql字段varchar区分大小写utf8_bin、utf8_general_ci编码区别
mysql字段varchar区分大小写utf8_bin.utf8_general_ci编码区别 在mysql中存在着各种utf8编码格式:utf8_bin将字符串中的每一个字符用二进制数据存储,区分大 ...
- MySQL字段联合去重sql
MySQL字段联合去重sql 例如数据 id,name1,name2 1 a x 2 a y 3 b x 4 a y 5 a x 联合去重name1,name2的结果为 id,name1,name2 ...
- mysql字段默认值不生效的问题解决(上)
在项目中使用mybatis做为持久层框架,mysql数据库.项目上线前,DBA要求我们将每张数据库表中的字段都设置默认值和not null.之前项目中有一些insert语句是将表中所有字段都列出来,然 ...
- MySQL字段属性NUll的注意点
MySQL字段属性应该尽量设置为NOT NULL 除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL.这看起来好像有点争议,请往下看. 空值("&quo ...
- Mysql字段类型与合理选择
字段类型 数值 MySQL 的数值数据类型可以大致划分为两个类别,一个是整数,另一个是浮点数或小数.许多不同的子类型对这些类别中的每一个都是可用的,每个子类型支持不同大小的数据,并且 MySQL 允许 ...
- (转)MySQL字段类型详解
MySQL字段类型详解 原文:http://www.cnblogs.com/100thMountain/p/4692842.html MySQL支持大量的列类型,它可以被分为3类:数字类型.日期和时间 ...
随机推荐
- Flask框架:运用Ajax轮询动态绘图
Ajax是异步JavaScript和XML可用于前后端交互,在之前<Flask 框架:运用Ajax实现数据交互>简单实现了前后端交互,本章将通过Ajax轮询获取后端的数据,前台使用echa ...
- TensorFlow深度学习!构建神经网络预测股票价格!⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 TensorFlow 实战系列:https://www.showmeai ...
- ANSYS安装教程
ANSYS 16.0 WIN10 64位安装步骤:1.使用"百度网盘客户端"下载ANSYS 16.0软件安装包到电脑磁盘里全英文名称文件夹内,安装前先断开网络,然后找到ANSYS. ...
- 结合RocketMQ 源码,带你了解并发编程的三大神器
摘要:本文结合 RocketMQ 源码,分享并发编程三大神器的相关知识点. 本文分享自华为云社区<读 RocketMQ 源码,学习并发编程三大神器>,作者:勇哥java实战分享. 这篇文章 ...
- Linux 常用命令(持续更新)
Linux常用命令介绍(备查) *所有的命名都可以用 命令 --help/man 命令 查看使用说明 1.pwd 显示当前路径 2.dir 和 ls用法一样 都是列出当前路径下的文件(不包括隐藏文件) ...
- 进击的K8S:Kubernetes基础概念
Kubernetes简介 Kubernetes简称K8S(因为k和s中间有8个字母),是一个开源的容器集群管理平台,基于Go语言编写. 使用K8S,将简化分布式系统上的容器应用部署,使得开发人员可以专 ...
- day37-文件上传和下载
文件上传下载 1.基本介绍 在Web应用中,文件上传和下载是非常常见的功能 如果是传输大文件一般用专门的工具或者插件 文件上传和下载需要用到两个包:commons-fileupload.jar和com ...
- 软件开发架构、构架趋势、OSI七层协议
目录 软件开发架构 构架总结 网络编程前戏 OSI七层协议简介 OSI七层协议值之物理连接层 OSI七层协议之数据链层 网络相关专业名词 OSI七层协议之网络层 IP协议: IP地址特征: IP地址分 ...
- 【ASP.NET Core】MVC操作方法如何绑定Stream类型的参数
咱们都知道,MVC在输入/输出中都需要模型绑定.因为HTTP请求发送的都是文本,为了使其能变成各种.NET 类型,于是在填充参数值之前需 ModelBinder 的参与,以将文本转换为 .NET 类型 ...
- python 实现RSA公钥加密,私钥解密
from Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5 from Cryp ...