【LeetCode字符串#05】基于个人理解的KMP算法图解,以及应用到strStr()函数实现
KMP算法(用于实现 strStr())
strStr()函数是用来在一个字符串中搜索是否存在另一个字符串的函数,其匹配字符串方式为KMP算法
KMP算法基础理论
假设有如下两个字符串
文本串 aabaabaaf
模式串 aabaaf
我们希望在文本串中匹配出模式串
Intro
暴力法
使用两层for循环逐个匹配,当匹配不上时,模式串整体后移一位,继续逐个匹配

从代码实现的复杂度来看,这种做法最坏的情况复杂度是O(m*n),即:文本串长度 * 模式串长度
下面来看看KMP是怎么做的
KMP
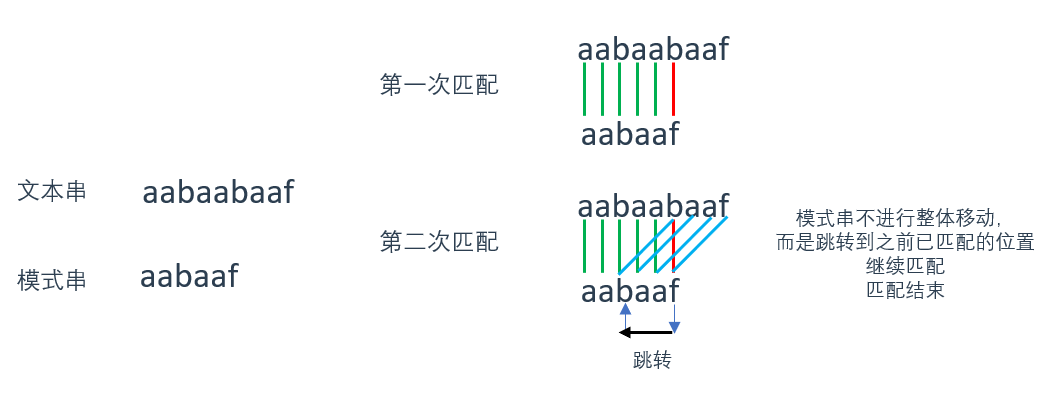
使用KMP算法,当遇到不匹配值 f 时,当前指针会跳转到 b 处继续匹配
看到这里肯定有疑问:为什么知道要跳转到 b 处继续匹配?
因为KMP算法中使用到了 前缀表
前缀表
上面的讨论中
"当出现不匹配的值跳转到b处继续匹配"
这件事情用具体的理论来表述是:
当出现不匹配值 f 时,f 的前面的子串是 aabaa ,该子串的后缀是 aa
根据KMP算法,我们要找到子串 aabaa 前缀与后缀相同的位置
显然这个位置就是 b 所在之处,因此从这里开始继续匹配
也就是说:"当出现不匹配值时,我们要看不匹配值前面的子串,找出该子串最长相等前后缀是多少"
下面对以上出现的新名词做解释
什么是前/后缀?
举个例子
aabaaf
|___|
即:
a
aa
aab
aaba
aabaa
如上面,前缀是包含首字母,不包含尾字母的所有子串
aabaaf
|___|
即:
f
af
aaf
baaf
abaaf
而后缀是只包含尾字母,不包含首字母的所有子串
如何求最长相等前后缀?
以aabaaf为例
aabaaf
a 0(理论上a没有前后缀,所以为0)
aa 1(前缀a,后缀a,因此是1)
aab 0(a、b不等,为0)
aaba 1
aabaa 2
aabaaf 0
前缀表在哪?
这里得到了一个序列(从上到下):[0, 1, 0, 1, 2, 0]
那么这个就是所谓的前缀表
使用前缀表
根据上面的讨论,我们得到了模式串的前缀表
aabaaf
010120
那么如何使用前缀表进行匹配?

我们在子串 aabaa 的 后缀aa 的后面遇到了不匹配值,那么我们就要从子串 aabaa 的 前缀aa 的后面(b处)继续往后匹配。
说白了就是:
子串aabaa(不匹配值前面的子串)它的最长相等前后缀的长度就是我们要继续匹配的位置
最长相等前后缀在前缀表中记录为2,那么我们就要跳到字符串中2的位置
012345
aabaaf
010120
↑
也就是b的位置(即,前缀的后面)
这里用于存放前缀表的数组一般称为next数组,如何去求,后面再说
KMP算法实现
前缀表的实现需要依赖next数组,因此我们需要构建它
构造next数组
构造next数组其实就是计算模式串s,前缀表的过程。 主要有如下三步:
- 初始化
- 处理前后缀不相同的情况
- 处理前后缀相同的情况
初始化
定义两个指针 i 和 j ,j 指向前缀末尾位置(不匹配值的前一个位置),i 指向后缀末尾位置。
从判断前后缀是否相同的角度解释
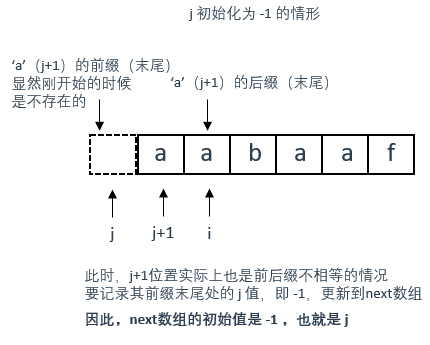
从初始化的角度解释
初始化值如下:
int j = -1;
next[0] = j;
其实 j 也不一定初始化为 - 1
例如之前的前后缀示例中,我们的初始化值为0
这里是为了让next数组中的元素统一为:0,-1,1,才将 j 初始化为 -1 的
next[i] 表示 i(包括i)之前最长相等的前后缀长度(详见上面的解释,其实就是 j )
同理,next[j+1]表示 j+1(包括j+1)之前最长相等的前后缀长度
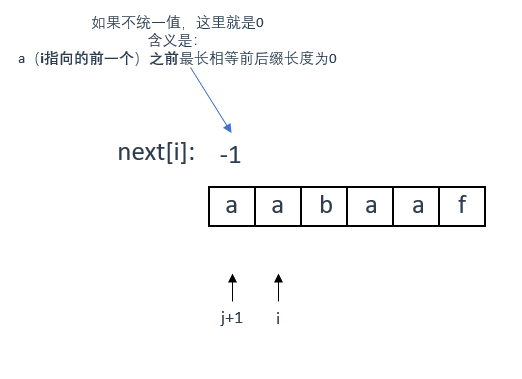
详见之前的求最长相等前后缀示例,对照来看
规定好指针的定义后,现在要开始遍历判断前后缀的情况了
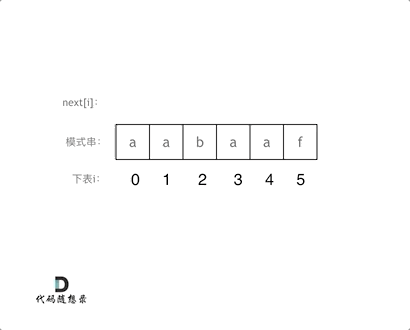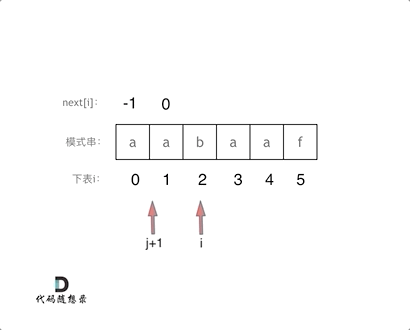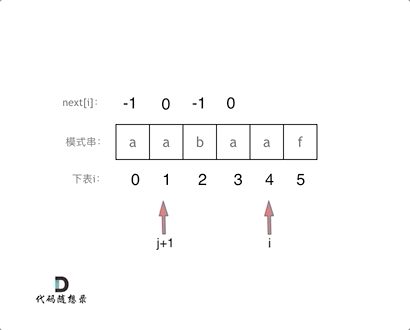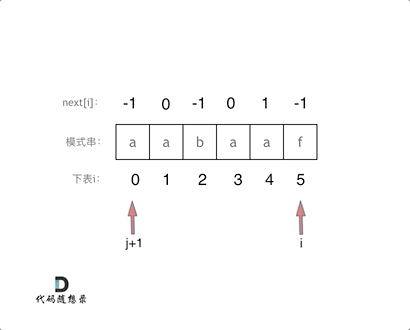
判断前后缀是否相同(j初始化为-1)
这里我先画一个图来模拟整个过程
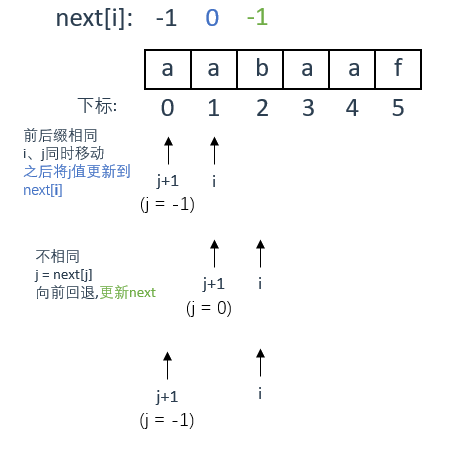
刚开始的时候,j+1指向 a ,i 指向 a
前后缀相等
此时 s[j+1] = s[i] ,前后缀相等。
故两个指针同时后移一位(但具体过程是 j 先 ++,然后再到for循环的 i++),更新 j 的值到next[i](注意是i)
代码如下:
//如果找到匹配值,j++(也就是把j+1往后移),并保存匹配值的位置(j值)到next数组
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j;
要明确一点: next数组(前缀表的具体实现)用来寻找前后缀相等时 j (指向前缀末尾位置)的位置 ,其存放的是
图示角度解释
因为这里 j 初始化为-1,所以从图中来看,next保存的是当前位置(j+1指向)的前一个位置,这也和前缀的定义是相符的,即不包含j+1指向位置的元素
(实在不理解就当成是初始化就行,j+1指向的'a'前面没有子串,也就没有前缀,所以给个初始值-1)
代码角度解释
虽然当满足 s[j+1] = s[i] 时,立刻进行 j++,但此时外层for循环并没有结束,我们仍可以通过 i 找到 j++之前的 j 值指向的位置,并将当前更新后 j 值保存到 next数组中(对应图示中的行为)
注意,这里next数组中存的是 j 的值,不是 j+1的值
j 值才是前缀末尾位置,而 j+1只是遍历当前模式串使用的一个指针
通过next数组我们可以找到最近一次满足 s[j+1] = s[i] 条件时,指针j+1的位置
前后缀不相等
第二轮,j+1指向 a ,i 指向 b
此时 s[j+1] != s[i] ,前后缀不相等,那么指针 j+1要向前回退
怎么回退呢?根据之前理论部分的讨论,遇到不匹配的值,要看当前 j+1 的前一位在next数组中对应的值,使用该值作为回退的依据,对应到图中就是让 j 等于next中当前位置(j+1指向的)前一位的值(也就是next[j])
简单来说,就是从next数组中找到上次前后缀相等时指针 j+1指向的位置
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 向前回退
}
注意这里是要循环去回退,因为可能要回退多次,所以不能用 if
并且还要注意加上条件,判断是否已经退到头了(j >= 0)
代码构造next数组的逻辑流程动画如下:
整体代码:
void getNext(int* next, const string& s){
//初始化j和next数组
int j = -1;
next[0] = j;
//开始遍历模式串
for(int i = 1; i < s.size(); i++) { // 注意i从1开始
//如果没找到匹配值,使用next数组回退
while (j >= 0 && s[i] != s[j + 1]) { // 前后缀不相同了
j = next[j]; // 不断地从next数组中找上次前后缀相等时指针 j+1指向的位置
}
//如果找到匹配值,j++(也就是把j+1往后移),并保存匹配值的位置(j值)到next数组
if (s[i] == s[j + 1]) { // 找到相同的前后缀
j++;
}
next[i] = j; // 将j(前缀的长度)赋给next[i]
}
}
总结
实际上这样捋一遍可能还是有点乱,我认为原因之一是初始化的问题
即:为了将 next数组中的值统一成[-1,0,1]这三种,在初始化时将 j 初始化为-1
但是只要记住一下几点应该还是能够想明白的:
1、两个指针 i 和 j 的定义
j 指向的是前缀末尾位置(不匹配值的前一个位置)
i 指向的是后缀末尾位置
2、遵循"循环不变量"原则
在KMP算法中,循环不变量指的是:每当我们遇到不匹配的值时,总是去找其前一个值所在位置下标在next数组中对应的记录值,然后由此回退到上次前后缀相等(s[i] == s[j + 1])的位置
3、next数组存的是什么
next数组存放的是最后一次前后缀相等的位置
实现 strStr()
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1: 输入: haystack = "hello", needle = "ll" 输出: 2
示例 2: 输入: haystack = "aaaaa", needle = "bba" 输出: -1
说明: 当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
思路
利用上面介绍的KMP算法
先求出needle 字符串(即 模式串)的next数组
然后还是用双指针去遍历haystack 字符串(即 文本串)和needle 字符串
如果值匹配,两个指针同时向后移动,不匹配则通过next数组返回上次匹配的位置,继续比较
步骤如下:
1、实现getNext函数用于计算模式串前缀表
2、创建一个数组作为next数组(长度与模式串相等)
3、定义指针 j (规则要与计算next数组是保持一致,之前是-1,这里也要是-1)
4、从0开始遍历文本串
- 不匹配的就去next里找位置回退
- 匹配的,令 j 和 i 指针继续往下走(j后移就相当于j+1后移)
5、当 j 来到模式串的末尾,搜索结束,此时需要返回
- 文本串指针i遍历到的当前位置减去模式串的长度(从0开始数的)再加1就可以得到文本串中出现模式串第一个字符的位置
代码
明确两个指针分别遍历的是谁
j 指针负责模式串;
i 指针负责文本串;
class Solution {
public:
//先定义计算next数组的函数
void getNext(int* next, string& s){
//初始化j和next数组
int j = -1;
next[0] = j;
//开始遍历模式串
for(int i = 1; i < s.size(); ++i){//注意i从1开始
//如果没找到匹配值,使用next数组回退
while(j >= 0 && s[j + 1] != s[i]){
j = next[j];//不断地从next数组中找上次前后缀相等时指针 j+1指向的位置
}
//如果找到匹配值,j++(也就是把j+1往后移),并保存匹配值的位置(j值)到next数组
if(s[j + 1] == s[i]){
j++;
}
next[i] = j;//因为j已经++,利用i来把更新后的j值存到++之前下标对应的next中的位置
}
}
//使用next函数计算needle的前缀表
int strStr(string haystack, string needle) {
//判断needle是否为空
if(needle.size() == 0){
return 0;
}
//定义一个数组作为next数组,长度与模式串相等
int next[needle.size()];
//计算needle的next数组
getNext(next, needle);
//定义指针j,因为我们计算next数组时j初始化为-1,这里也保持一致
int j = -1;
//开始遍历文本串
for(int i = 0; i < haystack.size(); ++i){
//判断是否匹配的代码与getNext中一致
while(j >= 0 && haystack[i] != needle[j + 1]){//不匹配时,从next数组找回退位置
j = next[j];
}
if(haystack[i] == needle[j + 1]){//匹配,i、j同时后移
j++;
}
//判断一下是否匹配结束
//因为j是用来遍历模式串的,如果j到达模式串尾部,那么说明文本串中出现了模式串,结束
if(j == needle.size() - 1){
//用文本串指针i遍历到的当前位置减去模式串的长度(从0开始数的)再加1就可以得到文本串中出现模式串第一个字符的位置
return (i - needle.size() + 1);
}
}
return -1;
}
};
看不明白请关闭网页,并骂一句2023.2.12 16:34分的我是傻逼,这都说不明白
【LeetCode字符串#05】基于个人理解的KMP算法图解,以及应用到strStr()函数实现的更多相关文章
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- 常用算法3 - 字符串查找/模式匹配算法(BF & KMP算法)
相信我们都有在linux下查找文本内容的经历,比如当我们使用vim查找文本文件中的某个字或者某段话时,Linux很快做出反应并给出相应结果,特别方便快捷! 那么,我们有木有想过linux是如何在浩如烟 ...
- 字符串模式匹配算法1 - BF和KMP算法
在字符串S中定位/查找某个子字符串P的操作,通常称为字符串的模式匹配,其中P称为模式串.模式匹配有多种算法,这里先总结一下BF算法和KMP算法. 注意:本文在讨论字符位置/指针/下标时,全部使用C语法 ...
- 字符串与模式匹配(一)——KMP算法
源码:kmp.cpp // KMP.cpp : Defines the entry point for the console application. // #include "stdaf ...
- KMP算法图解
字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD" ...
- 扩展的KMP算法图解
扩展的KMP算法,可以在Ο(n + m)的时间复杂度内计算出模板串与文本串的每一个后缀的最长公共前缀,即LCP(T[i:n],P). KMP算法所解决的单模板字符串匹配问题,求得的匹配点是LCP = ...
- KMP算法简明扼要的理解
KMP算法也算是相当经典,但是对于初学者来说确实有点绕,大学时候弄明白过后来几年不看又忘记了,然后再弄明白过了两年又忘记了,好在之前理解到了关键点,看了一遍马上又能理解上来.关于这个算法的详解网上文章 ...
- KMP算法的理解
---恢复内容开始--- 在看数据结构的串的讲解的时候,讲到了KMP算法——一个经典的字符串匹配的算法,具体背景自行百度之,是一个很牛的图灵奖得主和他的学生提出的. 一开始看算法的时候很困惑,但是算法 ...
- KMP算法最浅显理解——一看就明确
说明 KMP算法看懂了认为特别简单,思路非常easy,看不懂之前.查各种资料,看的稀里糊涂.即使网上最简单的解释,依旧看的稀里糊涂. 我花了半天时间,争取用最短的篇幅大致搞明确这玩意究竟是啥. 这里不 ...
- KMP算法最浅显理解——一看就明白
https://blog.csdn.net/starstar1992/article/details/54913261 说明 KMP算法看懂了觉得特别简单,思路很简单,看不懂之前,查各种资料,看的稀里 ...
随机推荐
- pagehelper使用有误导致sql多了一个limit
接口测试报告中发现时不时有一个接口报错,但再跑一次又没有这个报错了.报错信息是sql异常,sql中有两个limit.查看后台代码和XXmapper.xml,发现确实只有一个limit.一开始开发以为是 ...
- 更换K8S证书可用期
帮助文档:https://zealous-cricket-cfa.notion.site/kubeadm-k8s-24611be9607c4b3193012de58860535e 解决: 1.安装GO ...
- MySQL数据库:7、SQL常用查询语句
Python基础之MySQL数据库 目录 Python基础之MySQL数据库 一.SQL语句常用查询方法 前期数据准备 1.基本查询 2.编写SQL语句的小技巧 3.查询之where筛选 3.1.功能 ...
- C#调用WPS转换文档到PDF的的实现代码。
1.WPS安装,最好用这个版本别的版本不清楚,安装Pro Plus2016版本. https://ep.wps.cn/product/wps-office-download.html 2.添加相关的引 ...
- BFS和DFS学习笔记
1 算法介绍 1.1 BFS Breadth First Search(广度优先搜索),将相邻的节点一层层查找,找到最多的 以上图为例,首先确定一个根节点,然后依次在剩下的节点中找已找出的节点的相邻节 ...
- .net6+wpf制作指定局域网ip无法上网的arp欺诈工具
摘一段来自网上的arp欺诈解释:ARP欺骗(ARP spoofing),又称ARP毒化(ARP poisoning,网络上多译为ARP病毒)或ARP攻击,是针对以太网地址解析协议(ARP)的一种攻击技 ...
- 06.python闭包
python闭包 什么样的函数是 闭包函数 ? 满足以下条件: 闭:外层函数嵌套了一个内层函数. 包:内层函数调用外层函数命名空间内的名字. 举例如下: def out_func(): # 外层函数 ...
- 《HTTP权威指南》– 3.HTTP方法和状态码
常见HTTP方法: 常用HTTP方法 描述 是否包含主体 GET 从服务器获取一份文档 否 HEAD 只从服务器获取文档的首部 否 POST 向服务器发送需要处理的数据 是 PUT 将请求的主体部分存 ...
- MySQL视图-触发器
目录 一:视图 1.什么是视图? 2.为什么要用视图? 3.如何使用视图 4.反复拼接的繁琐(引入视图的作用) 5.解决方法 二:视图的应用 1.创建视图的格式: 2.查询视图层 3.查询Navica ...
- [编程基础] C#自定义类调用窗体控件
如果自定义类需要调用窗体控件,首先需要将窗体控件的可见级别(Modifiers)设为public.如下图所示: 然后在Form1类下定义静态变量form1,并初始化. class Form1: For ...