【DL论文精读笔记】Image Segmentation Using Deep Learning: A Survey 图像分割综述
深度学习图像分割综述
Image Segmentation Using Deep Learning: A Survey
原文连接:https://arxiv.org/pdf/2001.05566.pdf
Abstract
图像分割应用包括场景理解、医学图像分析、机器人感知、视频监控、增强现实和图像压缩。本文涵盖了语义和实例分割的开创性工作,包括全卷积像素标记网络(FCN)、编码器-解码器结构,多尺度和基于金字塔的方法、循环网络、视觉注意力模型、生成模型。
1. 引言
图像分割又分为两种,语义分割和实例分割。 语义分割:具有语义标签的像素分类。对所有像素进行像素级别的标记。包括一组类别(如人、车、树、天空)。同图像中同一类的物体进行分割。(同一类一种颜色)。 实例分割:单个对象的分割。通过检测和划定图像中每个感兴趣的目标,进一步拓展了语义分割的范围。(每个目标一种颜色)
本文广泛涵盖了上百种基于深度学习的分割方法。包括:训练集、网络架构选择、损失函数、训练策略以及这些的主要贡献。技术分类主要有以下这些:
Fully convolutional networks
Convolutional models with graphical models
Encoder-decoder based models
Multi-scale and pyramid network based models
R-CNN based models (for instance segmentation)
Dilated convolutional models and DeepLab family
Recurrent neural network based models
Attention-based models
Generative models and adversarial training
Convolutional models with active contour models
Other models
文章结构:
第二节:目前流行的深度神经网络架构
第三节:基于深度学习的分割模型
第四节:图像分割数据集以及特点
第五节:基于深度学习的分割模型评估指标
第六节:主要挑战以及未来方向
第七节:总结
2. 深度神经网络架构综述
2.1 卷积神经网络(CNNS)
CNNs主要包括三个类型的层:i) 卷积层 ii) 非线性层 iii) 池化层。各层单元相互连接。通过堆叠各层形成多分辨率金字塔,较高的层从不断增加宽度的感受野中学习特征。优点是参数量明显少于全连接网络。一些著名的架构:AlexNet、VGGNet、ResNet、GoogleNet、MobileNet、DenseNet
2.2 循环神经网络和长短期记忆网络
RNNs被广泛用于处理序列数据,如语音、文本、视频和时间序列,其中任何特定时间/位置的数据都取决于以前遇到的数据。在每个时间戳,模型收集当前时间Xi的输入和前一步hi-1的隐藏状态,并输出一个目标值和一个新的隐藏状态。 RNNs在处理长序列时通常会出现问题,因为它们不能捕捉许多现实世界应用中的长期依赖关系(尽管它们在这方面没有表现出理论上的限制),并且经常遭受梯度消失或爆炸问题。然而,一种叫做长短时记忆(LSTM)的RNNs被设计来避免这些问题。
2.3 编码器-解码器和自动编码模型
编码器-解码器模型是通过二阶段网络将数据点从输入域映射到输出域的一系列模型。 编码器:将输入压缩为潜在空间表示(latent-space representation) 解码器:预测潜在空间表示的输出 潜在空间表示:本质上就是特征表示,能够捕获潜在的语义信息 这些模型通过最小化重建损失L, 该损失是测量ground-truth输出y和后续重构ŷ之间的距离。
2.4 生成对抗网络
3. 基于深度学习的图像分割模型
通过架构将模型进行以下分类:
3.1 全卷积网络(FCN)
Long等人首次提出用全卷积网络进行语义分割。修改现有CNN架构,如VGG16和GoogleNet,将全连接替换成卷积,输出空间分割图而不是分类分数。论文:1411.4038.pdf (arxiv.org)
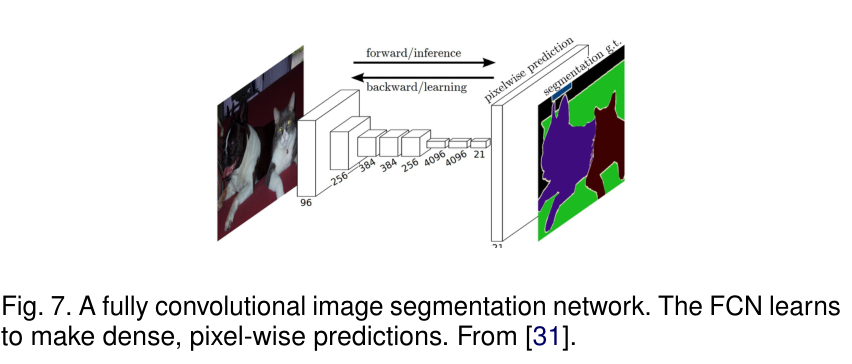
通过使用跳跃连接,对模型深层的特征图进行上采样,与浅层的特征图融合。结合了深层的语义信息和浅层的轮廓信息,以产生精确的分割。该模型在PASCAL VOC、NYUDv2和SIFT Flow上进行了测试,实现sota。
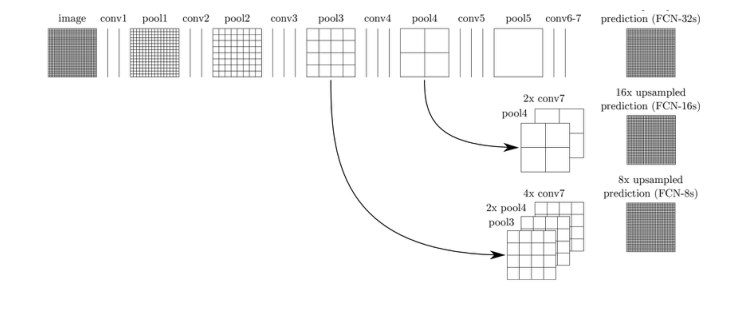
存在的不足:1)不能进行实时推理,2)不能有效考虑全局上下文信息,3)不容易转为3D图像。 改进工作:ParseNet模型解决 了第 2)个问题。
3.2 Convolutional Models With Graphical Models
为了克服深度卷积神经网络的定位缺陷。Chen提出了卷积神经网络+条件随机场(CNN+CRF)的语义分割算法。他们的模型能够以更高的准确率定位分割边界。这就是DeepLab的V1版本。论文:https://arxiv.org/pdf/1412.7062v3.pdf
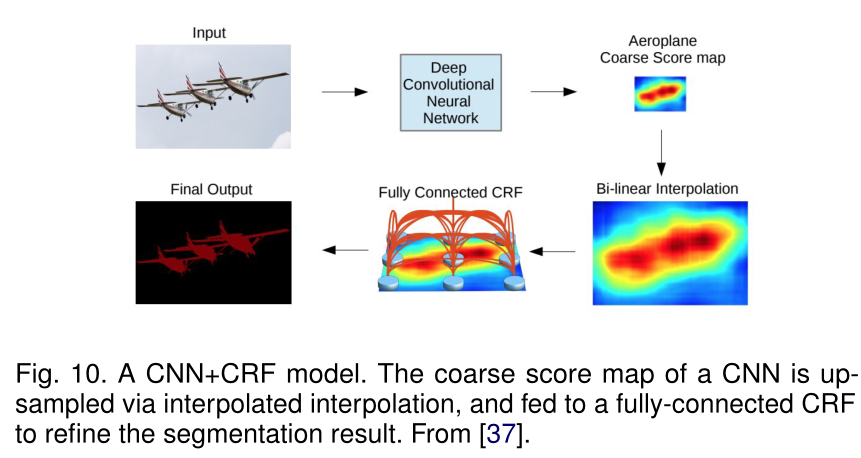
Schwing和Urtasun提出了一种用于图像分割的全连接深度结构化网络。他们提出了一种联合训练cnn和全连接CRF进行语义图像分割的方法。 其它相关工作:Lin提出基于上下文的深度CRFs算法进行语义分割。他们探索了一种“patch-patch” 和 “patch-background"的上下文,通过上下文信息来改进语义分割。 Liu又提出Parsing Network,丰富的信息融入到马尔科夫随机场(MRF)中。论文:1509.02634.pdf (arxiv.org)
3.3 基于编码器-解码器的模型
3.3.1 Encoder-Decoder Models for General Segmentation
Noh等人发表了基于反卷积的语义分割早期论文。他们的模型DeconvNet由两部分组成:一个是VGG16的编码器,另一个是将特征向量作为输入并生成像素级概率图的反卷积网络。反卷积网络由反卷积层和unpooling层组成,通过对像素级别的标签进行识别,并预测分割掩码。论文地址:http://t.csdn.cn/QUTPG
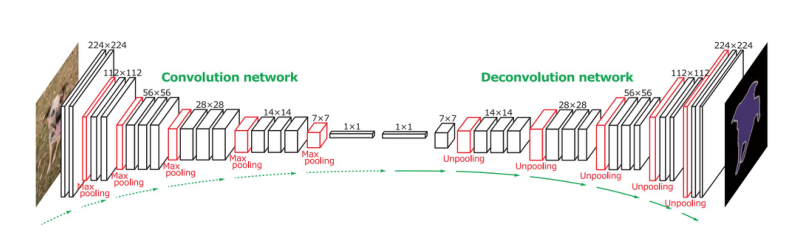
反卷积:(2条消息) 抽丝剥茧,带你理解转置卷积(反卷积)_史丹利复合田的博客-CSDN博客
Badrinaraynan等人提出SegNet,与DeconvNet类似,创新点是解码器对低分辨率的输入特征图进行上采样的方式。在对应编码器的最大池化步骤中,使用计算出的池化指数来进行非线性上采样。消除了学习上采样的需要。然后将稀疏上采样图与filter进行卷积,产生出密集特征图。作者还提出了贝叶斯版本的SegNet。
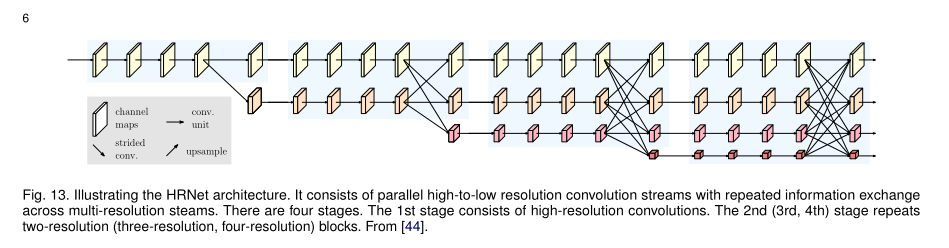
近期流行的模型:HRNet,通过并行连接高低分辨率的卷积流,在不同分辨率间反复交换信息,在编码过程中保持高分辨率特征。还有SDN、Linknet、W-Net以及用于RGB-D室内语义分割的具有门控融合的局部敏感反卷积网络。论文地址:1902.09212.pdf (arxiv.org)
编码器-解码器模型缺点:图像细密纹理信息的损失,可以通过保持高分辨率表征去解决,如HRNet。
FCN、DeconvNet、SegNet总结:
图像分割1(FCN/DeconvNet/SegNet) - 知乎 (zhihu.com)
3.3.2 Encoder-Decoder Models for Medical and Biomedical
Image Segmentation
U-Net 与 V-Net是两个著名的模型,受到FCN和编码器-解码器模型启发,最初用于医学图像分割。
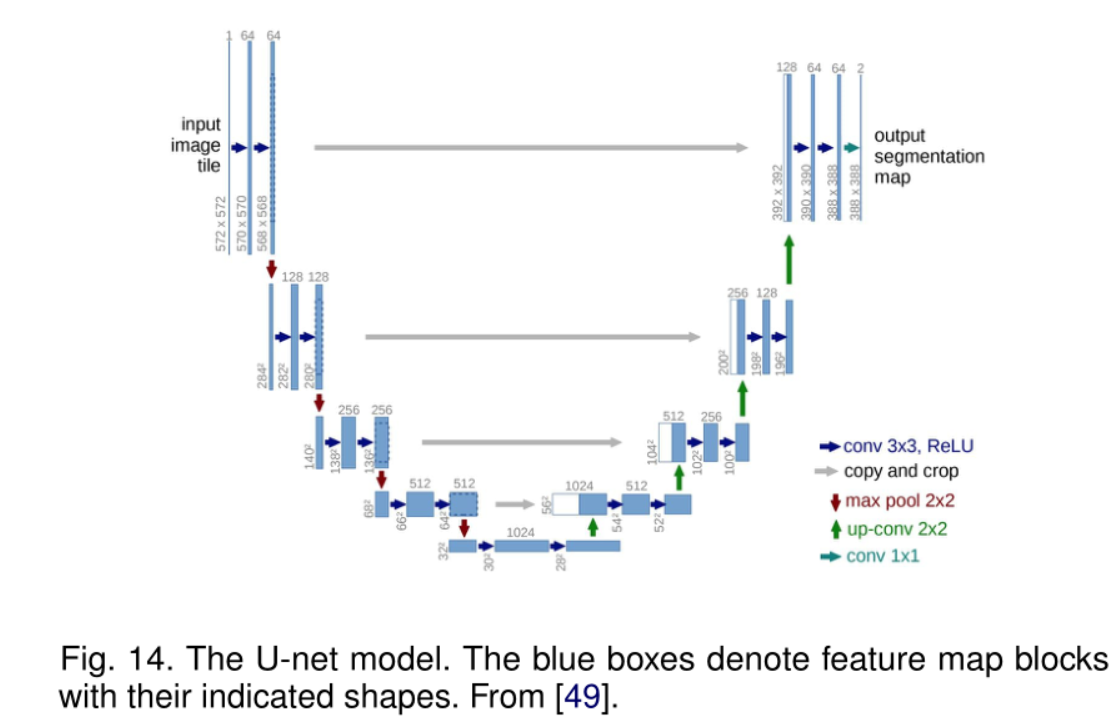
U-Net
U-Net包括左边的收缩路径(contracting path)用于捕获上下文和右边的对称扩张路径(symmetric expanding path)用于精确定位。该架构通过3x3卷积来提取特征,上采样或扩张部分使用up-conv 或者 反卷积,以减少特征图数量同时增加其维度。
下采样部分的特征图复制到上采样部分,减少模式信息的丢失。最后用1x1卷积处理特征图以生成对每个像素分类的分割图。

V-Net
V-Net提供了一个三维图像分割方法,它采用端到端的训练方式,在训练时使用了一个基于Dice coefficient的新的目标函数来优化训练。它可以很好地处理前景和背景体素数量之间存在严重不平衡的情况。为了处理可用于训练的数据有限的情况,它使用了随机非线性转换和直方图匹配来增强数据。

3.4 基于多尺度和特征金字塔的模型
特征金字塔(FPN)是多尺度分析的重要模型之一,当初主要是用于目标检测,后来被应用于分割。为了合并高分辨率和低分辨率的特征,FPN由自底向上,自顶向下的横向连接组成。连接而成的特征图经过3x3的卷积核处理,最后自顶向下的每个阶段都生成一个预测来检测目标。对于图像分割,作者采用两个MLP来生成掩膜。
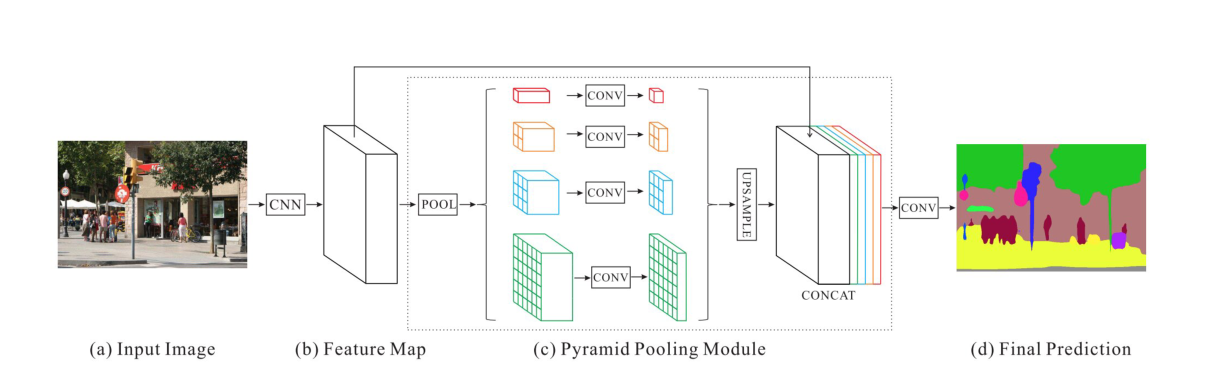
PSPN
Zhao提出了金字塔场景解析网络(PSPN),是一个用于更好学习场景全局上下文表示的多尺度网络。提出了pyramid pooling模块来区分不同尺度的模式信息。
基于拉普拉斯金字塔的多分辨率重建架构
Ghiasi和Fowlkes开发了一种基于拉普拉斯金字塔的多分辨率重建架构,该架构使用来自高分辨率特征图的跳跃连接和乘法门控来连续细化从低分辨率特征图重建的分割边界。他们表明,尽管卷积特征图的表观空间分辨率较低,但高维特征表示包含显著的亚像素定位信息。
其它模型
还有其它的模型将多尺度分析用于分割任务。比如DM-Net、CCN、APC-Net、MSCI、salient object segmentation。
3.5 基于R-CNN的模型(用于实例分割)
一些RCNN的改进模型被用于解决实例分割问题。同时执行目标检测和语义分割的任务。
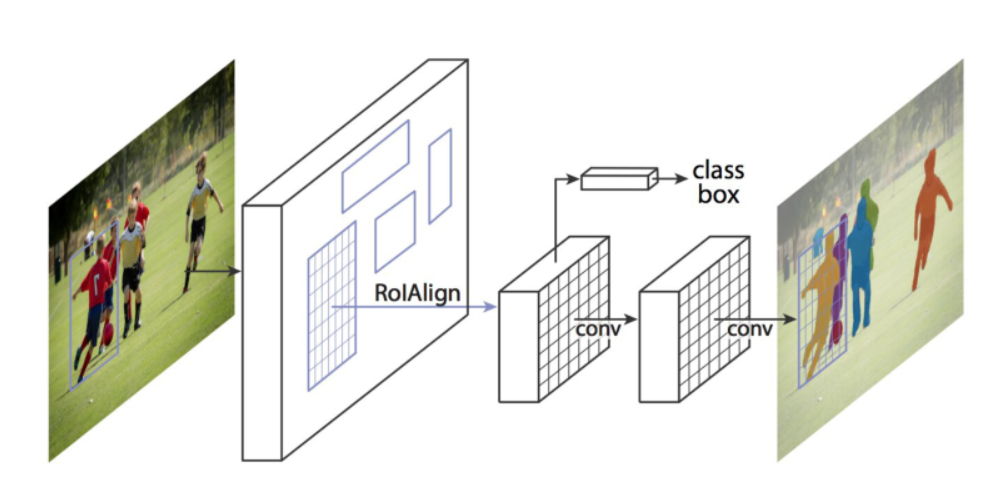
Mask R-CNN
何凯明团队提出Mask R-CNN进行目标实例分割。该模型进行高效目标检测的同时还能生成高质量的实例分割掩码。Mask R-CNN本质上是一个更快的RCNN,有3个输出分支,第一个计算边界框坐标,第二个计算相关类,第三个计算二进制Mask来分割对象。掩模R-CNN损失函数组合了边界框坐标、预测类和分割掩模的损失,并联合训练它们。论文地址:https://arxiv.org/pdf/1703.06870.pdf
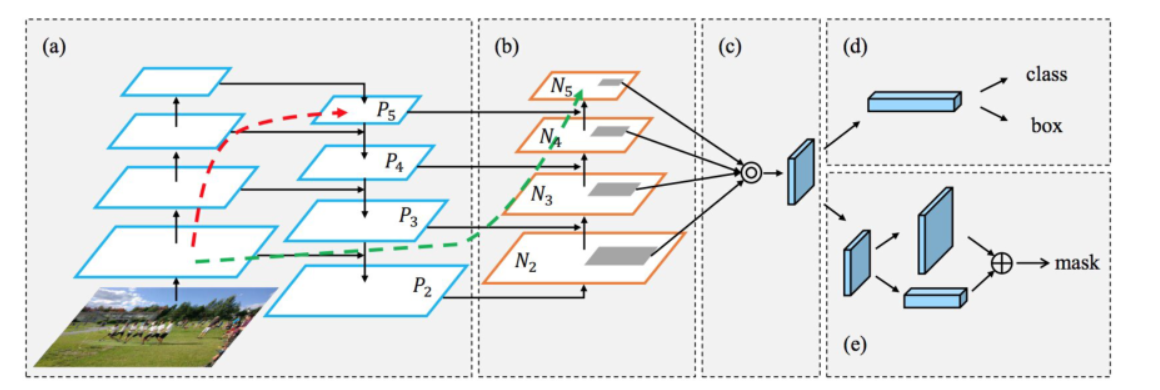
PANet
腾讯优图提出的实例分割框架。使用FPN架构具有新的增强自底向上路径,以此提高底层特征的传播。
multi-task network
Dai等人开发了一个用于实例分割的多任务网络,该网络由三个网络组成,分别用于区分实例、估计掩码、对目标进行分类。这三个网络形成联级结构,并且设计为共享卷积特征。
Hu等人提出了一种新的部分监督学习范式(partially-supervised training paradigm)以及新的权重迁移函数( weight transfer function)。使其能够在大的类别上进行实例分割训练,这些都有标注框,但是只有一小部分有分割标注。
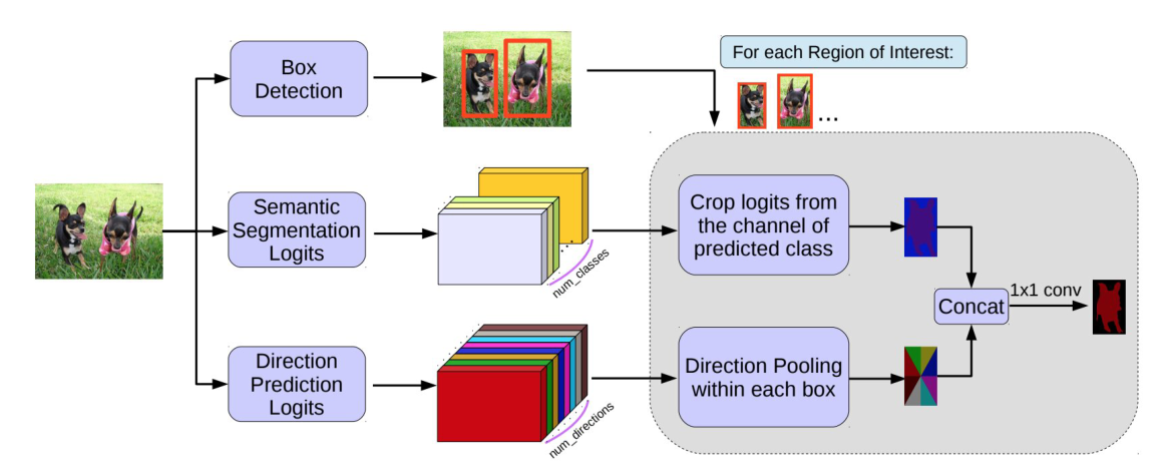
MaskLab
基于Faster R-CNN模型,通过语义和方向特征来改进目标检测。输出检测框、语义分割和方向预测。
其它模型
另外还有其它基于R-CNN的模型,如R-FCN、DeepMask、PolarMask、boundary-aware instance segmentation、CenterMask。值得注意的是,还有另外一个有前景的研究方向,那就是 solve the instance segmentation problem by learning grouping cues for bottom-up segmentation 。(不知道怎么翻译)比如Deep Wastershed Transform, real-time instance segmentation 、Semantic Instance Segmentation via Deep Metric Learning
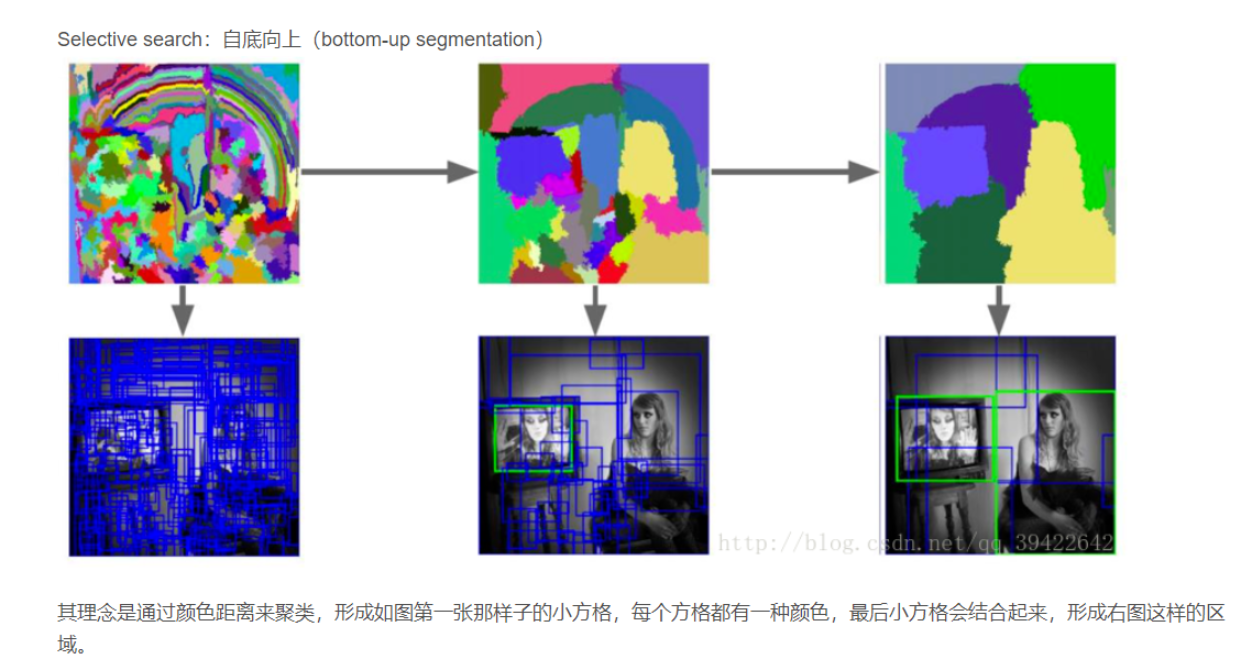
3.6 膨胀卷积和DeepLab系列
膨胀卷积模型(Dilated Convolutional Models)
膨胀卷积(又叫空洞卷积),可以在不增加计算成本的情况下扩大感受野。http://t.csdn.cn/TNtYg
普通卷积与膨胀卷积:
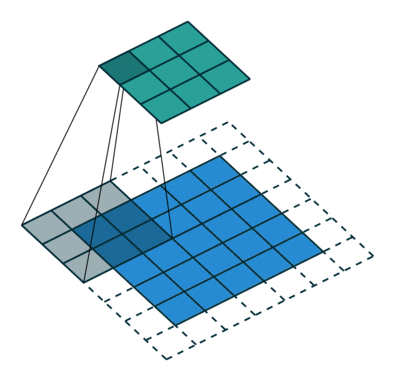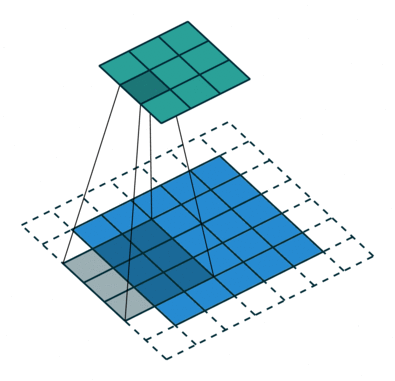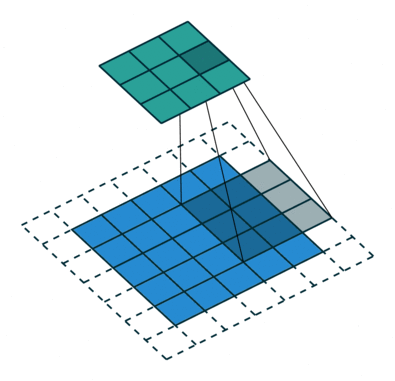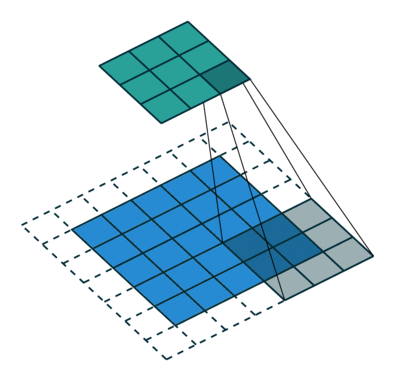
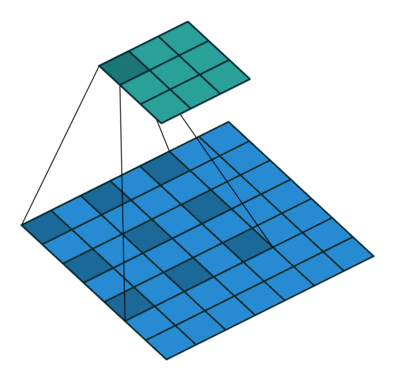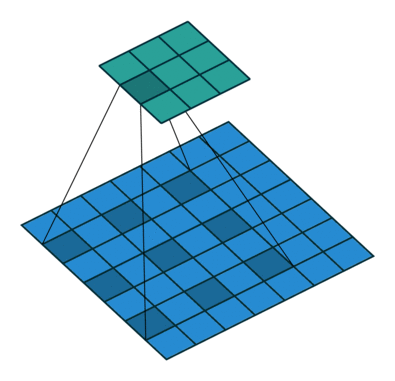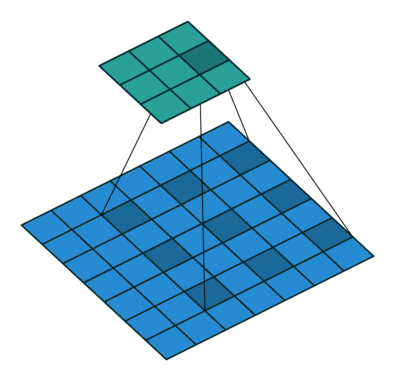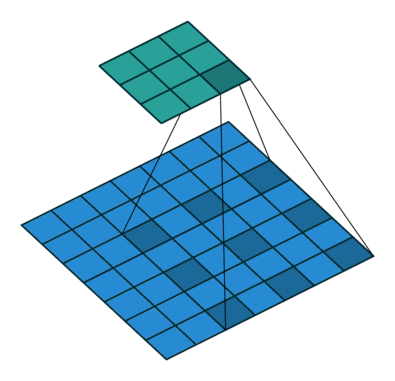
膨胀卷积在实时分割领域中非常流行。许多模型都采用了该技术,比如DeepLab系列,multi-scale context aggregation,dense upsampling convolution and hybrid dilatedconvolution (DUC-HDC),densely connected Atrous Spatial Pyramid Pooling (DenseASPP), efficient neural network (ENet)
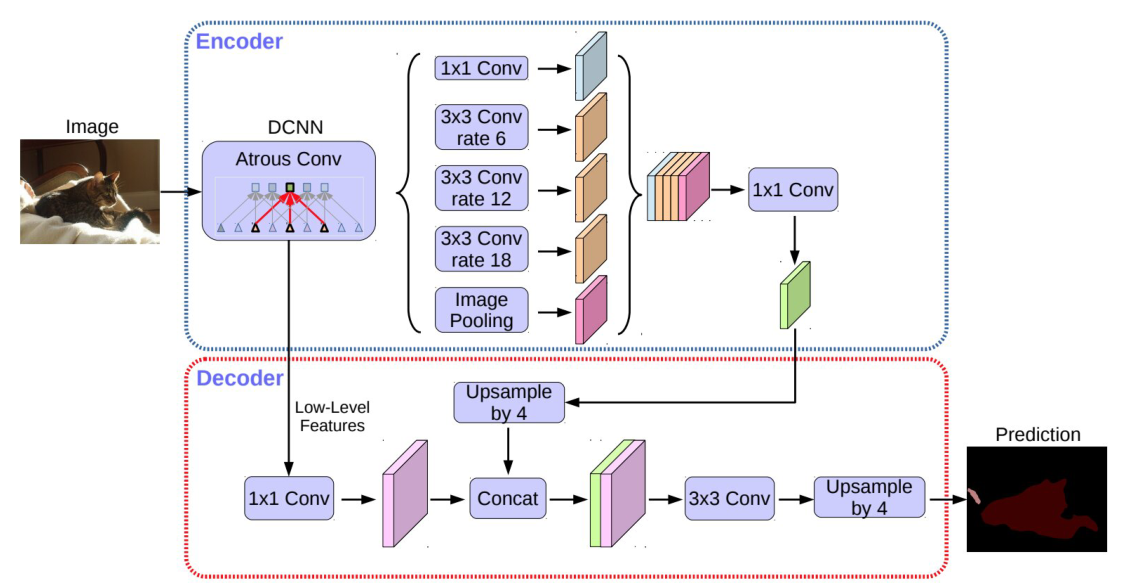
DeepLab系列
DeepLabv1和DeepLabv2是最流行的图像分割算法之一。v2具有三个关键特点:
1)使用膨胀卷积解决网络中分辨率低的问题(由最大池化和stride引起)
2)Atrous Spatial Pyramid Pooling(ASPP)模块,以多尺度获取目标和图像的上下文。
3)结合深度神经网络和概率图模型,改进目标边界定位。
随后提出了DeepLabv3,结合了膨胀卷积的级联和并行模块,并行卷积模块在ASPP模块中进行分组?1x1的卷积和批归一化引入到ASPP中,最后由1x1卷积处理,生成每个像素的最终输出。
2018年,又提出了DeepLabv3+模型,使用编码器-解码器结构。
3.7 基于循环神经网络的模型
ReSeg 基于ReNet模型进行改进,将ReNet层堆叠在预训练的VGG-16卷积层上,提供相关全局信息。经过VGG-16的通用局部特征提取后,进行上采样,恢复最终预测原始图像的分辨率。
3.8 基于注意力的模型
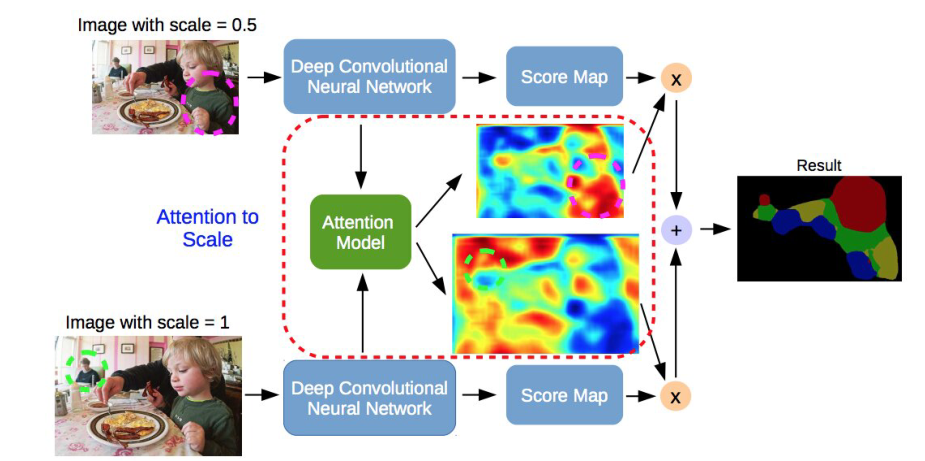
Attention to Scale
Chen等人出了一种注意力机制,该机制学习在每个像素位置对多尺度特征进行软加权。他们采用了强大的语义分割模型,并将其与多尺度图像和注意力模型联合训练。注意力机制优于平均池和最大池,它使模型能够评估不同位置和尺度上特征的重要性。
RAN
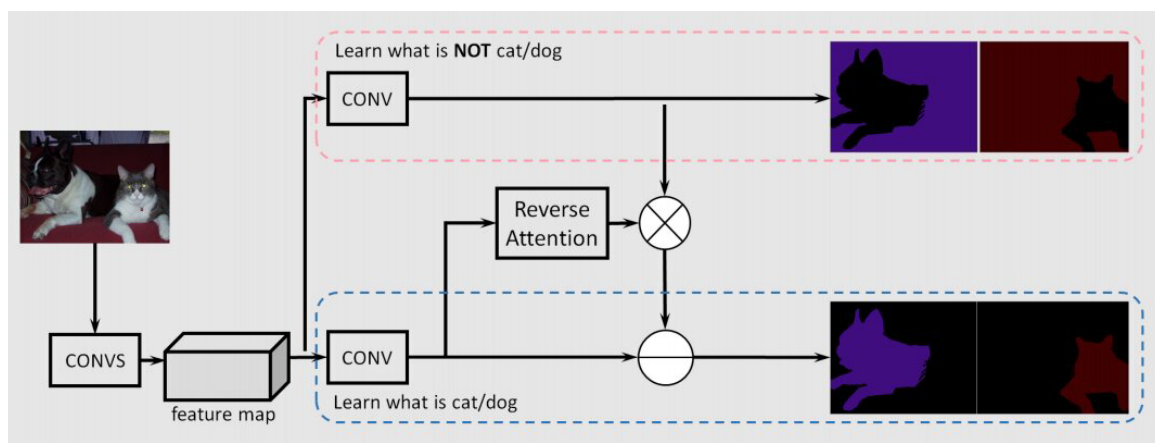
与训练卷积分类器以学习标记对象的代表性语义特征的其他工作不同,Huang等人提出了一种使用反向注意力机制的语义分割方法。他们的反向注意力网络(RAN)架构训练模型以捕捉相反的概念(与目标类不相关的特征)。RAN是同时执行直接和反向注意力学习过程的三分支网络。
PAN
Li等人开发了用于语义分割的金字塔注意力网络(Pyramid Attention Network)。该模型利用了语义分割中全局上下文信息的影响。他们将注意力机制和空间金字塔相结合,为像素标记提取精确的密集特征,而不是复杂的扩张卷积和人工设计的解码器网络。论文地址:1805.10180.pdf (arxiv.org)(yolov4采用了该结构)
Dual attention network
Fu等人提出场景分割的双注意网络,它可以基于自我注意机制捕获丰富的上下文依赖。具体来说,他们在膨胀的全连接卷积网络上附加了两种类型的注意力模块,该网络分别在空间和通道维度上建模语义相关性。位置注意力模块通过所有位置的特征加强和,来选择性地聚集每个位置的特征。论文地址:[1809.02983] Dual Attention Network for Scene Segmentation (arxiv.org) CVPR2019
others
还有其它工作对用于语义分割的注意力机制进行探索,如OCNet、EMANet、CCNet、DFN等
3.9 生成模型和对抗训练
Semantic segmentation using adversarial networks
Luc等人提出了一种用于语义分割的对抗性训练方法。他们训练了一个卷 积语义分割网络(图31),以及一个对抗性网络。该对抗网络将ground- truth分割图与分割网络生成的图分开来。他们表明,对抗性训练方法提高 了Stanford Background和PASCAL VOC 2012数据集的准确性。
Semi supervised semantic segmentation using generative adversarial network
Souly等人提出了使用GAN的半弱监督语义分割。它由一个生成器网络组 成,为多类分类器提供额外的训练示例,在GAN框架中充当鉴别器,该分 类器从K个可能的类中分配样本一个标签y,或将其标记为假样本(额外 类)。
Adversarial Learning for Semi-Supervised Semantic Segmentation
在另一项工作中,Hung等人开发了使用对抗性网络的半监督语义分割框 架。他们设计了一个FCN鉴别器,考虑到空间分辨率,将预测的概率图与 ground truth分割分布区分开来。该模型所考虑的损失函数包含三个项: 基于分割基础真值的交叉熵损失、鉴别器网络的对抗性损失和基于置信图 的半监督损失;鉴别器的输出。
Segan
薛提出了一种用于医学图像分割的多尺度L1损失对抗网络。他们使用FCN作为分割器来生成分割标签图,并提出了一种具有多尺度L1损失函数的新型对抗性评估网络,以迫使评估和分割器学习捕捉像素之间的长距离和短距离空间关系的全局和局部特征。
others
其它基于对抗性训练的分割模型,如使用GAN的细胞图像分割(Cell image segmentation using generative adversarial networks, transfer learning, and augmentations),以及目标的不可见部分的分割和生成。(Segan: Segmenting and generating the invisible)
3.10 CNN Models With Active Contour Models
FCNs与主动轮廓模型(ACMs)之间的协同作用的探索最近引起了研究的兴趣。一种方法是制定受ACM原理启发的新的损失函数。例如,受全球能量公式的启发,Chen等人提出了一个监督损失层,该层在FCN训练过程中包含了预测掩模的面积和大小信息,并解决了心脏MRI中的心室分割问题。 另一种方法最初试图仅仅将ACM作为FCN输出的后处理器,并且一些努力尝试通过预训练FCN来进行适度的共同学习。自然图像语义分割的一个例子是Le等人的工作[108],其中级别集的acm被实现为rnn。鲁普雷希特等人的深度活动轮廓[109]。对于医学图像分割,哈塔米扎德等人[110]提出了一个集成的深度活动损伤分割(DALS)模型,该模型训练FCN主干来预测一种新的、局部参数化的水平集能量函数的参数函数。在另一项相关的努力中,马科斯等人提出了深度结构化活动轮廓(DSAC),它将acm和预先训练过的FCNs结合在一个结构化预测框架中,用于在空中图像中构建实例分割(尽管是手动初始化)。对于同样的应用程序,Cheng等人[112]提出了深度主动射线网络(DarNet),它与DSAC相似,但基于极坐标的显式ACM公式不同,以防止轮廓自交。Hatamizadeh等人最近引入了一种真正的端到端反向传播、可训练的、完全集成的FCN-ACM组合,被称为深度卷积活动轮廓(DCAC)。
3.11 其它模型
除了上述模型之外,还有几种其他流行的DL架构用于分割,例如:上下文编码网络(EncNet),其使用基本特征提取器,并将特征映射馈送到上下文编码模块。RefineNet,这是一个多路径细化网络,它明确利用下采样过程中的所有可用信息,以使用长距离残差连接实现高分辨率预测。Seednet,它引入了一种具有深度强化学习的自动种子生成技术,该技术学习解决交互式分割问题。”对象上下文表示”(OCR),它在地面真实情况的监督下学习对象区域,并计算对象区域表示,以及每个像素和每个对象区域之间的关系,并使用对象上下文表示来增加表示像素。然而,其他模型包括BoxSup、Graph卷积网络、Wide ResNet、Exfuse(增强低级和高级特征融合)、前馈网络、测地视频分割的显著性感知模型、双图像分割(DIS)、FoveaNet(透视感知场景解析)、梯形密度网、,双边分割网络(BiSeNet)、场景分析语义预测指南(SPGNet)、门控形状CNN、自适应上下文网络(AC-Net)、动态结构化语义传播网络(DSSPN)、符号图推理(SGR)、级联网、尺度自适应卷积(SAC)、统一感知分析(UperNet),通过再训练和自训练进行分割,密集连接的神经架构搜索,分层多尺度关注。
泛光分割也是另一个日益流行的有趣的分割问题,在这个方向上已经有几个有趣的工作,包括泛光特征金字塔网络、泛光分割注意力引导网络、无缝场景分割、全景深度实验室、统一全景分割网络,有效的全景分割。
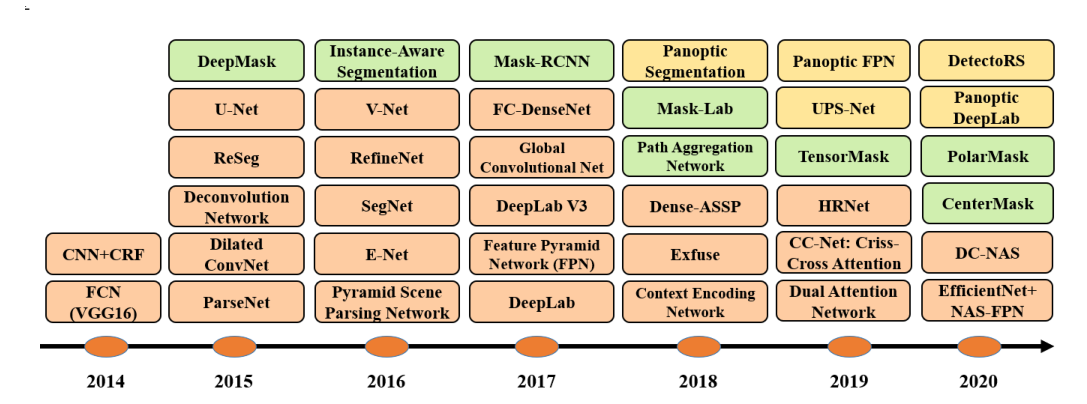
该图说明了自2014年以来流行的基于DL的语义分割作品以及实例分割作品的时间线。鉴于过去几年中开发的大量作品,我们只展示了一些最具代表性的作品。
4.图像分割数据集
4.1 2D 数据集
PASCAL Visual Object Classes (VOC)
PASCAL Context
Microsoft Common Objects in Context (MS COCO)
Cityscapes
ADE20K / MIT Scene Parsing (SceneParse150)
SiftFlow
Stanford background
Berkeley Segmentation Dataset (BSD)
Youtube-Objects
KITTI
Semantic Boundaries Dataset (SBD), PASCAL Part , SYNTHIA , and Adobe’sPortrait Segmentation
4.2 2.5D 数据集
随着可负担得起的距离扫描仪的使用,RGB-D图像在研究和工业应用中都变得流行。以下RGB-D数据集是一些最流行的数据集
NYU-D V2
SUN-3D
SUN RGB-D
UW RGB-D Object Dataset
ScanNet
4.3 3D数据集
Stanford 2D-3D
ShapeNet Core
Sydney Urban Objects Dataset
5 模型性能
5.1 分割模型评估指标
Pixel accuracy:
只是找到正确分类的像素比率除以像素总数。 对于 K + 1 类(K个前景类和背景)其中 P_i是类别 i 的像素被预测为属于类别j 的像素数。
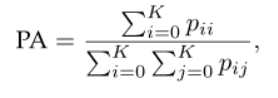
Mean Pixel Accuracy (MPA)2:
是PA的扩展版本,其中以每个类的方式计算正确像素的比率,然后在类的总数上求平均值
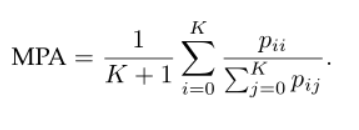
Intersection over Union (IoU):
是语义分割中最常用的指标之一。它定义为预测的分割图和 ground truth 之间的交集面积,除以预测的分割图和地面实况之间的并集面积
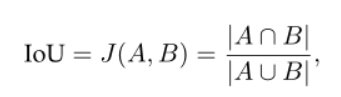
其中A和B分别表示 ground truth 和预测的分割图。 取值范围是0到1。
Mean-IoU:
是另一种流行的指标,定义为所有类别的平均IoU。 它被广泛用于现代分割算法的评估。
Precision / Recall / F1 score
评估许多经典图像分割模型准确性的流行指标。可以为每个类别以及总类定义精度和召回率。
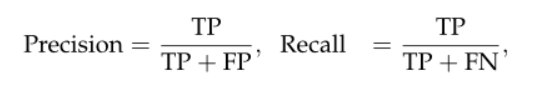
其中TP表示真阳性分数,FP表示假阳性分数,FN表示假阴性分数。 通常,我们会对精度和召回率的组合版本感兴趣。 这种流行的度量称为F1分数,其定义为精确度和查全率的调和平均值。
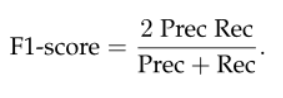
Dice coefficient
是另一种用于图像分割的流行指标,可以将其定义为预测图和真实图的重叠区域的两倍,再除以两个图像中像素的总数。 Dice系数与IoU非常相似。

5.2 基于深度学习模型的量化性能
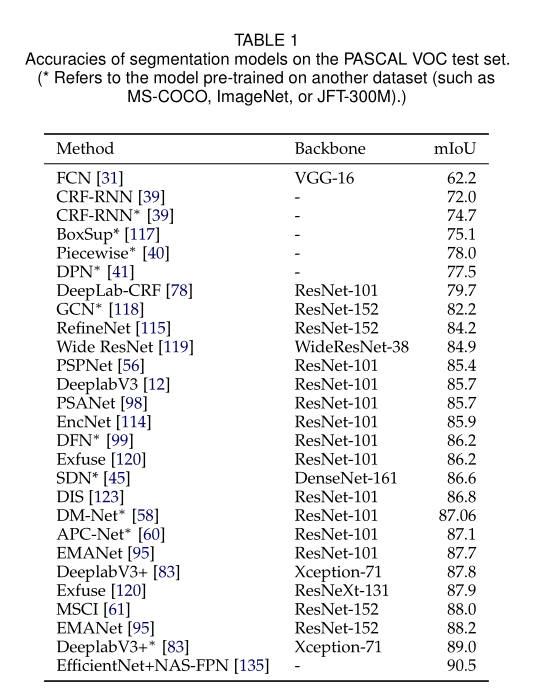
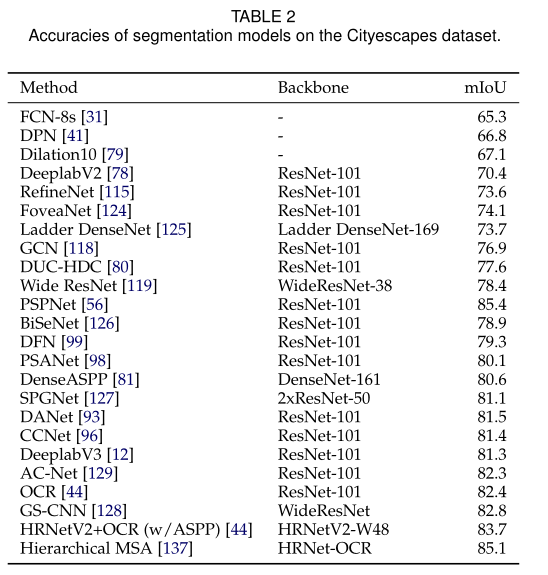
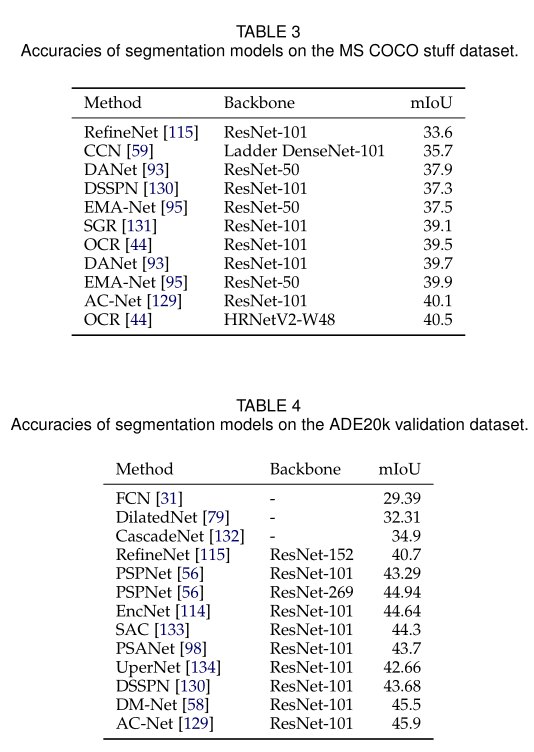
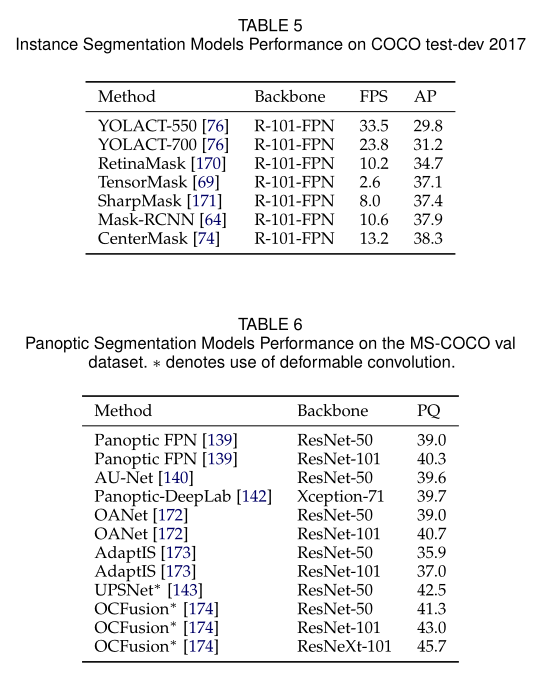
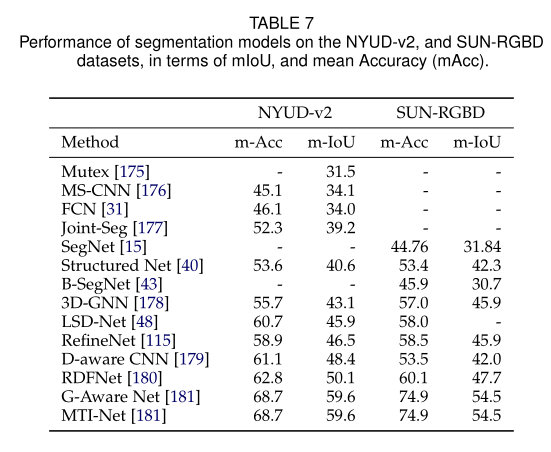
下表总结了几种基于DL的杰出分割模型在不同数据集上的性能。
6 机遇与挑战
更多具有挑战性的数据集
可解释的深度模型
弱监督和无监督学习
各种实用的实时模型
内存高效的模型
3D点云分割
应用场景
7 总结
我们调查了 100 多种基于深度学习模型的最新图像分割算法,它们在各种图像分割任务和基准测试中取得了令人印象深刻的性能,分为十类,例如:CNN 和 FCN、RNN、R-CNN、dilated CNN、attention 基于模型、生成模型和对抗模型等。 我们总结了这些模型在一些流行基准上的定量性能分析,例如 PASCAL VOC、MS COCO、Cityscapes 和 ADE20k 数据集。 最后,我们讨论了未来几年可以追求的图像分割的一些开放挑战和潜在研究方向。
【DL论文精读笔记】Image Segmentation Using Deep Learning: A Survey 图像分割综述的更多相关文章
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 【论文笔记】DeepOrigin: End-to-End Deep Learning for Detection of New Malware Families
DeepOrigin: End-to-End Deep Learning for Detection of New Malware Families 标签(空格分隔): 论文 论文基本信息 会议: I ...
- Review of Semantic Segmentation with Deep Learning
In this post, I review the literature on semantic segmentation. Most research on semantic segmentati ...
- 个性探测综述阅读笔记——Recent trends in deep learning based personality detection
目录 abstract 1. introduction 1.1 个性衡量方法 1.2 应用前景 1.3 伦理道德 2. Related works 3. Baseline methods 3.1 文本 ...
- 论文阅读 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
14 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS link:https://scholar.google.com.hk/sc ...
- [转]综述论文翻译:A Review on Deep Learning Techniques Applied to Semantic Segmentation
近期主要在学习语义分割相关方法,计划将arXiv上的这篇综述好好翻译下,目前已完成了一部分,但仅仅是尊重原文的直译,后续将继续完成剩余的部分,并对文中提及的多个方法给出自己的理解. _论文地址:htt ...
- 综述论文翻译:A Review on Deep Learning Techniques Applied to Semantic Segmentation
近期主要在学习语义分割相关方法,计划将arXiv上的这篇综述好好翻译下,目前已完成了一部分,但仅仅是尊重原文的直译,后续将继续完成剩余的部分,并对文中提及的多个方法给出自己的理解. 论文地址:http ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 【深度学习 论文篇 02-1 】YOLOv1论文精读
原论文链接:https://gitee.com/shaoxuxu/DeepLearning_PaperNotes/blob/master/YOLOv1.pdf 笔记版论文链接:https://gite ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
随机推荐
- 【读书笔记】C#高级编程 第二十章 诊断
(一)诊断概述 名称空间System.Diagnostics提供了用于跟踪.事件日志.性能测量以及代码协定的类.System.Diagnostics.Contracts名称空间中的类可以定义前提条件. ...
- 从零开始搭建gitea代码管理平台
Gitea,一款极易搭建的Git自助服务.如其名,Git with a cup of tea.跨平台的开源服务,支持Linux.Windows.macOS和ARM平台.配置要求低,甚至可以运行在树莓派 ...
- 使用 Spring Boot Admin 监控应用状态
程序员优雅哥 SpringBoot 2.7 实战基础 - 11 - 使用 Spring Boot Admin 监控应用状态 1 Spring Boot Actuator Spring Boot Act ...
- Windows Server体验之管理
安装了只有命令行界面的Windows Server之后怎么去管理,对于传统的Windows管理员来说确实是比较棘手的.因为没有了图形化的管理界面,需要更多的去依赖Powershell或者cmd命令去做 ...
- Visual Studio 2022 Community 不完全攻略
0. 前言 建议结合视频阅读哦 Visual Studio 2022 Community 不完全攻略 有问题或者意见欢迎评论 ! 1. 下载&安装 Visual Studio Communit ...
- kali安装vscode(deb包)
如果在虚拟机下安装,则你可以在主机下载,然后复制到具有可读可写的文件夹,比如root用户的话就在/root下面 打开终端,切换到软件终端,输入安装命令dpkg -i code...按table键自动补 ...
- .NET 反向代理 YARP 通过编码方式配置域名转发
前面介绍了 YARP 通过配置文件的方式配置代理转发(传送门),而众所周知,微软的一贯作风就是能通过配置文件做的事情,通过编码的方式也能实现!YARP 也不例外,废话不多说,直接上代码! 首先,参照官 ...
- Beats:Beats在Kibana中的集中管理
我们可以通过在命令行中对我们的Beats进行管理,比如我们可以启动metric几个模块,我们可以通过如下的命令来执行: ./metricbeat modules enable apache mysql ...
- Prometheus高可用部署
Prometheus的本地存储给Prometheus带来了简单高效的使用体验,可以让Promthues在单节点的情况下满足大部分用户的监控需求.但是本地存储也同时限制了Prometheus的可扩展性, ...
- Tubian0.43,完善对QQ微信的支持
Sourceforge.net下载:https://sourceforge.net/projects/tubian/ 123网盘下载: https://www.123pan.com/s/XjkKVv- ...